
Certification: Oracle Certified Expert, Oracle Database 12c: RAC and Grid Infrastructure Administration
Certification Full Name: Oracle Certified Expert, Oracle Database 12c: RAC and Grid Infrastructure Administration
Certification Provider: Oracle
Exam Code: 1z0-068
Exam Name: Oracle Database 12c: RAC and Grid Infrastructure Administration
Product Screenshots
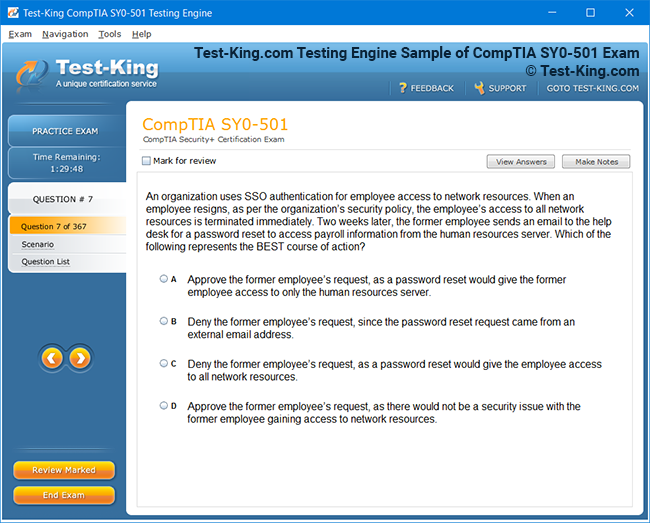
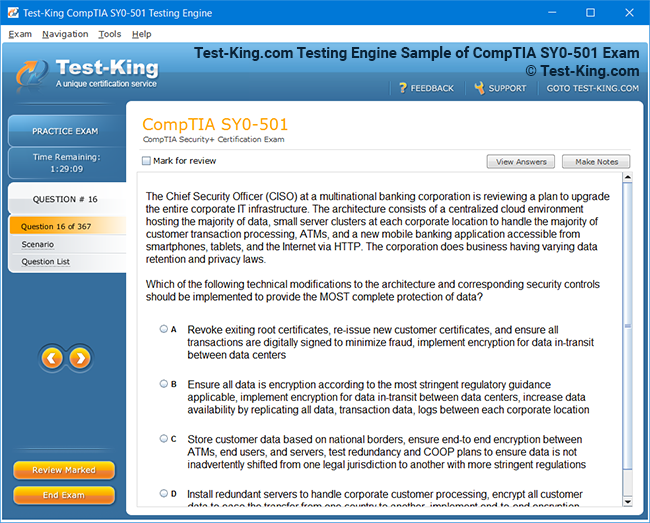
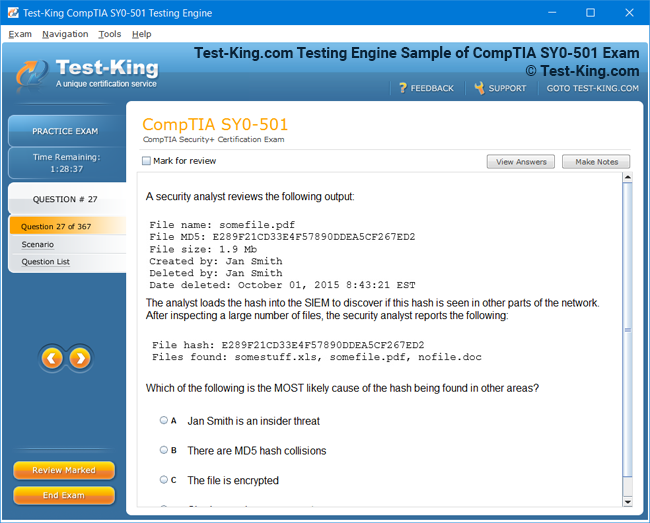
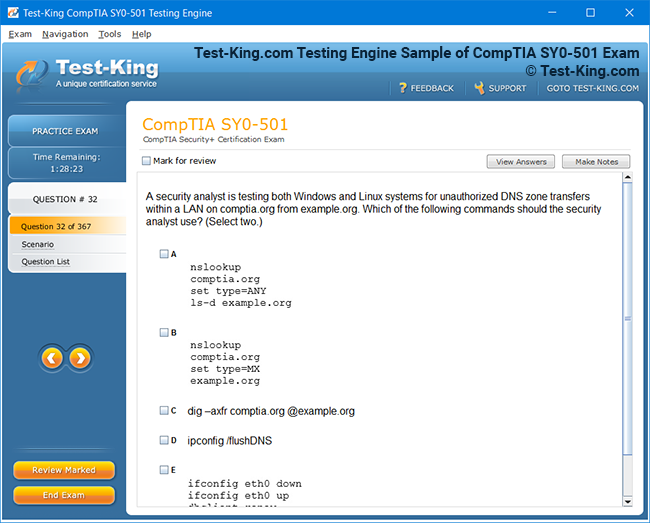
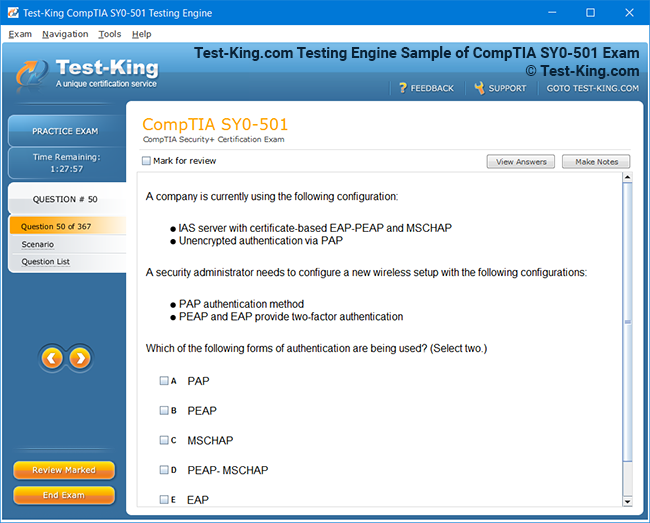
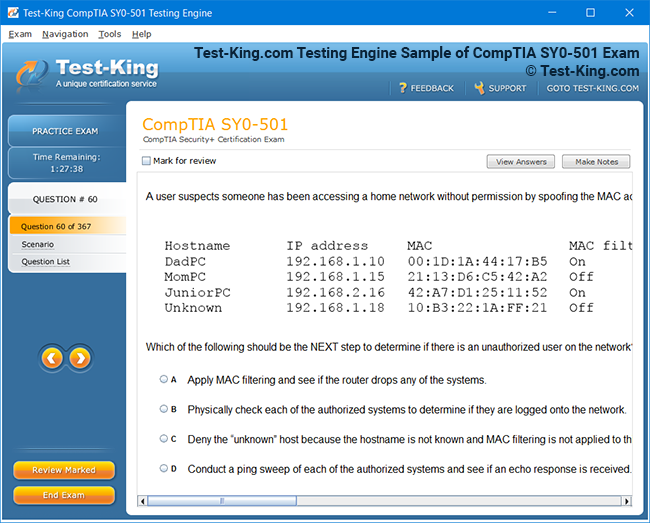
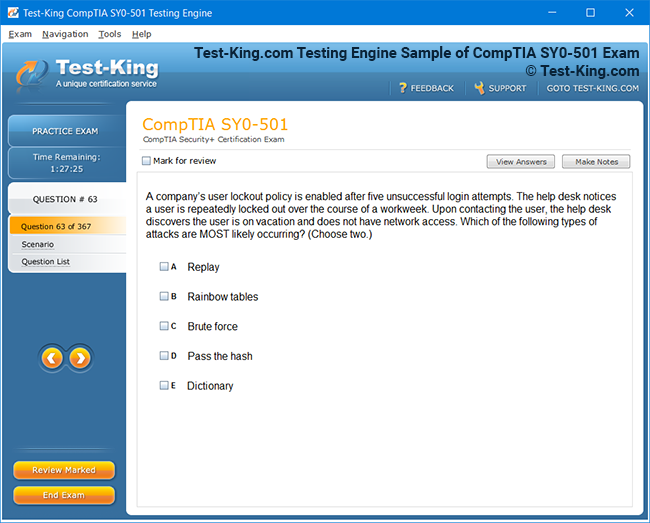
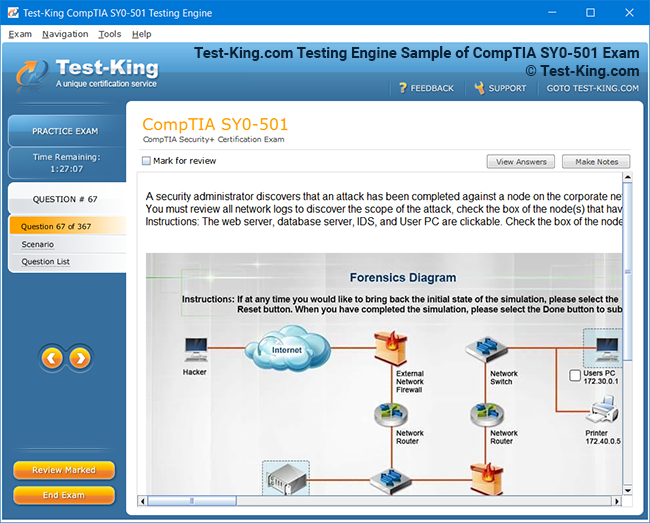
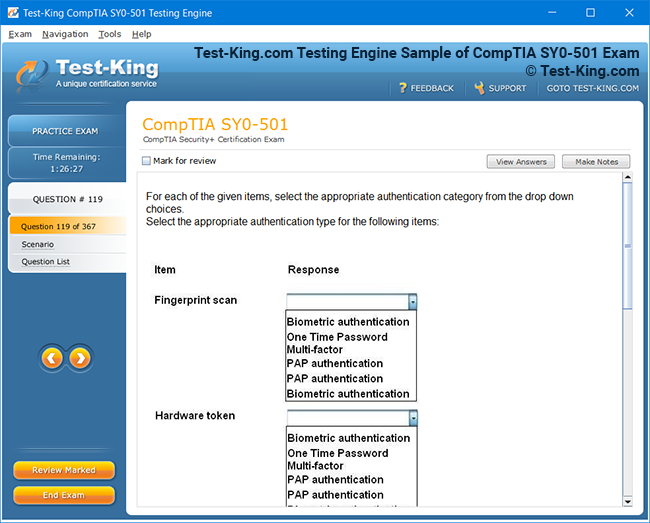
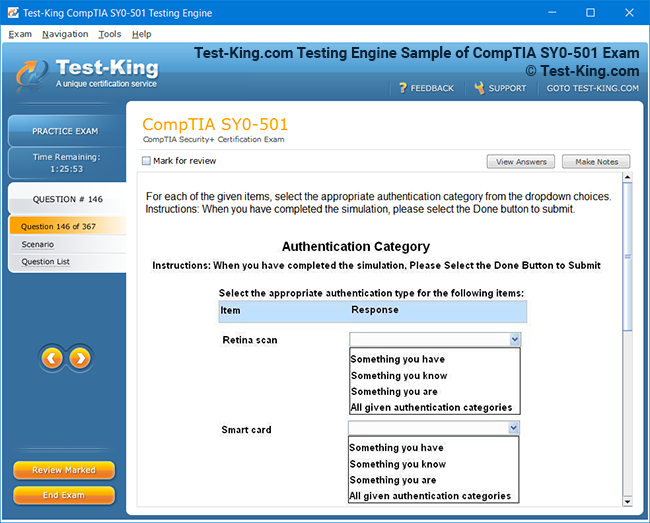
Certification Prerequisites
- Oracle Certified Expert, Oracle Real Application Clusters 11g and Grid Infrastructure Administrator
- OR
- Oracle Database 10g Real Applications Clusters Administrator Certified Expert
- OR
- Oracle Database 11g Administrator Certified Professional
- OR
- Oracle Database 12c Administrator Certified Professional
Oracle Certified Expert, Oracle Database 12c: RAC and Grid Infrastructure Administration Understanding the Core Architecture Foundations of Certificate
Oracle Real Application Clusters offers a paradigm that transcends conventional database configurations, allowing multiple instances to access a single database simultaneously while ensuring data consistency and high availability. The design philosophy behind Oracle RAC centers on the principles of redundancy, scalability, and fault tolerance, making it an indispensable tool for organizations that demand continuous access to critical data resources. Grid Infrastructure underpins this framework, orchestrating resources such as clusterware, Automatic Storage Management, and inter-node communication mechanisms to create a coherent and resilient ecosystem.
Introduction to Oracle RAC and Grid Infrastructure
Understanding the interplay between RAC and Grid Infrastructure requires an appreciation of the intricate mechanisms that govern cluster management, interconnectivity, and shared storage. At its essence, Grid Infrastructure encompasses Clusterware components responsible for node membership, resource monitoring, and failover procedures, along with ASM which streamlines storage management across the cluster. This architecture is designed not only to enhance performance but also to mitigate risks associated with hardware failures, network latency, or data corruption.
Clusterware: The Heartbeat of Oracle RAC
Clusterware serves as the foundation of a RAC environment, providing critical services that maintain cluster integrity. Its responsibilities include tracking node membership, managing cluster resources, and coordinating node failover in the event of a disruption. The cluster interconnect, a dedicated high-speed network, facilitates communication between nodes, enabling synchronous data updates and ensuring that all instances operate cohesively.
In addition to inter-node communication, clusterware manages voting disks and Oracle Cluster Registry files that play pivotal roles in cluster coordination. The voting disk is instrumental in determining node eligibility and avoiding split-brain scenarios, whereas the Oracle Cluster Registry maintains metadata about cluster configuration and resource allocation. Misconfigurations in these components can lead to instability, underscoring the necessity for meticulous planning and monitoring.
Clusterware employs specialized background processes that monitor node health and resource availability. For instance, eviction processes detect unresponsive nodes and coordinate the removal of such nodes from the cluster, allowing remaining instances to continue processing transactions seamlessly. This orchestration reduces downtime and safeguards data integrity, reflecting the robustness of Oracle RAC’s fault-tolerant design.
Automatic Storage Management: Simplifying Database Storage
Automatic Storage Management revolutionizes the way Oracle databases handle storage by abstracting the underlying file system and providing a virtualized storage layer optimized for database workloads. ASM eliminates the need for manual storage provisioning, stripe and mirror configuration, and complex disk management, offering instead a self-tuning and resilient storage solution.
Within a RAC environment, ASM enables multiple instances to access shared storage without contention, distributing I/O across available disks to improve performance. The system leverages concepts such as disk groups, failure groups, and rebalance operations to maintain data availability and optimize storage efficiency. Failure groups ensure that mirrored copies of data reside on separate physical devices, reducing the risk of data loss in case of hardware failure.
Rebalancing is a continuous process within ASM that redistributes data evenly when storage devices are added or removed, or when the capacity of existing devices changes. This feature maintains optimal performance and ensures that no single disk becomes a bottleneck. Administrators can monitor rebalancing progress and performance metrics through dedicated tools, which provide insights into I/O patterns, disk utilization, and potential hotspots.
Node Architecture and Interconnectivity
A critical aspect of RAC administration involves understanding the architecture of individual nodes and their interconnectivity within the cluster. Each node runs an instance of the Oracle database, consisting of background processes such as database writer, log writer, and process monitor. These instances interact with shared storage managed by ASM, while clusterware ensures synchronized communication between nodes.
The interconnect is a low-latency, high-bandwidth network that allows nodes to exchange heartbeat signals, cache fusion messages, and global enqueue information. Cache fusion, a core RAC mechanism, enables instances to directly transfer data blocks in memory rather than writing them to disk, which significantly reduces latency and enhances transaction throughput. Without proper interconnect configuration, instances may experience delays, leading to potential contention and performance degradation.
Administrators must carefully plan network topology to minimize latency and ensure redundancy. Multiple interconnect paths are often deployed to avoid single points of failure, and network performance monitoring is essential to detect congestion or packet loss. Additionally, understanding the role of private and public interfaces helps in isolating cluster traffic from client connections, enhancing both security and efficiency.
Database Administration and Instance Management
Managing Oracle RAC instances requires knowledge of both the shared database environment and node-specific configurations. Each instance maintains its own memory structures, including the System Global Area and Program Global Area, while relying on clusterware to coordinate access to shared resources. Tasks such as instance startup, shutdown, and patching must be carefully orchestrated to avoid disrupting the availability of other nodes.
Backup and recovery strategies in RAC environments differ from single-instance databases due to the presence of multiple nodes and shared storage. Administrators use tools and procedures that accommodate concurrent access, ensuring that backups are consistent and recoverable. Techniques such as RMAN with RAC-aware configurations facilitate reliable backups, while Flashback Database offers point-in-time recovery options that minimize downtime and data loss.
Monitoring is another critical component of RAC administration. Oracle Enterprise Manager and other diagnostic tools provide comprehensive insights into instance performance, session activity, and resource utilization. Effective monitoring helps identify bottlenecks, detect abnormal behaviors, and preemptively address issues before they escalate into significant problems.
High Availability and Failover Mechanisms
High availability is one of the principal reasons organizations adopt Oracle RAC and Grid Infrastructure. The cluster’s design ensures that if a node fails, remaining instances continue processing without disruption, maintaining service continuity. Failover mechanisms, coordinated by clusterware, relocate resources such as database services, virtual IP addresses, and storage mounts to surviving nodes.
Service-level management allows administrators to define policies for workload distribution, failover priorities, and connection load balancing. This approach not only improves availability but also optimizes resource utilization by directing client requests to the most appropriate node based on current workload and instance capacity.
In addition to node-level failover, RAC supports transaction recovery, ensuring that in-flight transactions are either completed or rolled back according to the ACID principles. This capability prevents data corruption and maintains consistency across instances, even in the face of abrupt node failures.
Patching and Upgrades in RAC Environments
Patching and upgrading a RAC database and its Grid Infrastructure require a careful approach to maintain availability. Oracle provides rolling patch mechanisms that allow updates to be applied to one node at a time while others continue servicing requests. This strategy minimizes downtime and allows organizations to maintain continuous operations during maintenance windows.
Administrators must follow a structured sequence when applying patches, including verifying prerequisites, backing up critical data, and coordinating with application teams. Understanding dependencies between clusterware, ASM, and individual database instances is crucial to avoid inconsistencies or service interruptions.
Testing patches in a pre-production environment is highly recommended to identify potential conflicts, performance regressions, or configuration issues. Detailed documentation and change management procedures further ensure that upgrades are executed reliably and predictably.
Performance Tuning and Optimization
Optimizing performance in a RAC environment involves both instance-level and cluster-level considerations. Instance-level tuning focuses on memory allocation, background process configuration, and database parameter adjustments, while cluster-level tuning addresses interconnect performance, cache fusion efficiency, and workload distribution.
Resource contention is a common challenge in RAC databases, particularly when multiple instances access frequently updated data blocks. Administrators leverage tools such as Automatic Workload Repository and Active Session History to analyze wait events, identify hotspots, and adjust parameters accordingly. Strategies like service-based workload balancing and partitioned application design help reduce contention and improve throughput.
Disk I/O optimization also plays a critical role. ASM’s dynamic rebalancing and striping reduce the likelihood of bottlenecks, but administrators must still monitor latency, queue lengths, and disk utilization to ensure consistent performance. Network monitoring complements these efforts by detecting interconnect congestion, packet loss, or suboptimal routing that may impede cluster efficiency.
Security and Compliance Considerations
Securing an Oracle RAC environment involves multiple layers, including authentication, authorization, and data encryption. Database administrators implement role-based access controls, audit policies, and network security measures to protect sensitive information. ASM and shared storage configurations must also adhere to best practices to prevent unauthorized access or accidental data exposure.
Compliance with regulatory standards such as GDPR or HIPAA necessitates careful monitoring of data access, retention policies, and backup procedures. Auditing tools and reporting mechanisms provide visibility into user activity, configuration changes, and system events, facilitating both internal reviews and external audits.
Network segmentation, use of encrypted communication channels, and adherence to least-privilege principles further strengthen the security posture of RAC environments. Administrators are encouraged to conduct periodic security assessments, penetration testing, and vulnerability scans to identify potential weaknesses and mitigate risks proactively.
Troubleshooting Common Issues
Despite meticulous planning, RAC environments can encounter issues ranging from instance crashes to performance degradation. Effective troubleshooting involves a methodical approach, starting with log analysis, instance health checks, and monitoring of interconnect traffic. Identifying the root cause often requires correlating events across nodes, as problems in one instance can propagate throughout the cluster.
Common challenges include blocked sessions due to global enqueue waits, ASM disk unavailability, and network latency affecting cache fusion. Administrators address these problems by examining wait events, verifying configuration parameters, and ensuring proper functioning of cluster resources. Understanding Oracle’s diagnostic tools and interpreting trace files is essential for timely problem resolution.
Knowledge of failover behaviors, rollback segments, and recovery procedures also contributes to effective troubleshooting. In many cases, proactive monitoring and early detection prevent minor anomalies from escalating into significant outages, underscoring the importance of vigilance and systematic administration.
Understanding RAC Services and Workload Management
RAC services provide a framework for grouping database workloads, enabling administrators to manage resource allocation, connection load balancing, and failover policies. Each service can be associated with specific nodes or instances, facilitating fine-grained control over workload distribution.
Clients connect to these services rather than individual instances, allowing the cluster to redirect requests dynamically based on node availability, resource utilization, or failover conditions. This abstraction simplifies application configurations and enhances resilience, as service-level failover ensures that users remain connected even if an instance becomes unavailable.
Resource management policies dictate priorities for CPU, memory, and I/O allocation, allowing critical workloads to receive preferential treatment. This approach improves response times, reduces contention, and aligns resource utilization with business priorities.
Preparing for the Oracle 12c RAC and Grid Infrastructure Exam
A deep understanding of RAC architecture, ASM, clusterware, failover mechanisms, and performance optimization forms the backbone of effective exam preparation. Candidates must familiarize themselves with practical scenarios, such as configuring voting disks, creating disk groups, managing interconnects, and troubleshooting common issues.
Hands-on experience is invaluable, as it allows aspirants to translate theoretical knowledge into real-world problem-solving. Simulated environments, guided labs, and comprehensive study guides contribute to mastery of complex topics, while regular practice reinforces concepts such as cache fusion, service-level management, and instance coordination.
Time management and systematic revision play a critical role in exam readiness. Breaking down study objectives into manageable modules, reviewing configuration steps, and analyzing past practice questions help solidify understanding and build confidence. Integrating conceptual learning with practical exercises ensures that candidates are well-prepared to tackle both scenario-based and theoretical questions.
Preparing the Environment for Installation
Installing Oracle RAC and Grid Infrastructure demands meticulous preparation of both hardware and software layers. Administrators must ensure that each node meets system prerequisites, including sufficient memory, storage, and processing capability to sustain multiple database instances concurrently. The operating system should be configured with proper kernel parameters, resource limits, and network settings to accommodate cluster interconnect traffic and high availability operations.
A thorough inventory of the hardware, including the number of CPUs, memory allocation, and storage architecture, is essential to avoid bottlenecks once the RAC database is operational. Shared storage, whether through ASM-managed disks or a SAN, must be correctly provisioned, accessible from all nodes, and configured to allow simultaneous read and write operations. Misalignment in these preparatory steps can result in installation failures or degraded cluster performance.
Networking plays a critical role in cluster stability. A dual network configuration is recommended, with one network dedicated to public client access and another to private interconnect traffic. The interconnect must be low-latency, high-bandwidth, and resilient to failures. Administrators often employ multiple network paths and redundant switches to ensure continuous communication between nodes, as the loss of interconnect connectivity can lead to cluster evictions or split-brain scenarios.
Installing Grid Infrastructure
Grid Infrastructure forms the backbone of the RAC environment and must be installed prior to the database software. The installation process begins with a thorough review of prerequisites, including operating system packages, disk accessibility, and network validation. Oracle’s installer verifies node connectivity, disk accessibility, and other critical parameters, providing administrators with an opportunity to correct configuration issues before proceeding.
During installation, clusterware components are deployed, including the Oracle Cluster Registry and voting disks. The Oracle Cluster Registry maintains cluster metadata, such as node membership, resource allocation, and configuration details. Voting disks are crucial for quorum determination, ensuring that the cluster can accurately adjudicate node membership and avoid split-brain conditions. Proper placement of these files on reliable, shared storage is essential for cluster stability.
The installer also configures ASM for use as the default storage management system. Administrators define disk groups, select redundancy levels, and verify that all nodes can access the disks. ASM automatically stripes and mirrors data across available disks, distributing I/O evenly and providing fault tolerance. Installation validation includes checks for cluster interconnect performance, disk accessibility, and node status, ensuring that the environment is ready for database creation.
Creating and Configuring Disk Groups
Disk groups in ASM provide a logical layer of abstraction over physical storage devices. Creating disk groups involves selecting disks, defining redundancy levels, and assigning names that reflect their purpose or usage. Failure groups within disk groups ensure that mirrored copies of data reside on separate devices, mitigating the risk of data loss due to hardware failures.
Once created, disk groups are available for database storage, including data files, redo logs, and temporary files. Administrators can extend disk groups dynamically by adding new disks, and ASM rebalances data automatically to maintain even distribution. This process improves performance and reduces hotspots, allowing the RAC environment to scale efficiently as storage requirements grow.
Monitoring disk group performance is vital to maintaining consistent I/O throughput. Tools and views provide insights into disk utilization, rebalance progress, and any contention issues. Proactive monitoring ensures that administrators can address potential problems before they impact database availability or performance.
Installing Oracle RAC Database Software
Following Grid Infrastructure deployment, the RAC database software is installed on all nodes. Each node must have identical binaries, ensuring consistency across the cluster. The installer validates node connectivity, interconnect status, and shared storage access, preventing common installation pitfalls.
During installation, administrators select options such as Oracle home directories, languages, and network configuration. Cluster-aware components are installed to support RAC operations, including background processes for inter-node communication, cache fusion, and instance coordination. Once installed, the software is verified for readiness to create a clustered database.
Post-installation tasks include environment variable configuration, user privilege verification, and validation of network interfaces. Ensuring that all prerequisites are met at this stage reduces the likelihood of errors during database creation and subsequent administration.
Creating a RAC Database
Creating a RAC database involves orchestrating multiple instances to operate on shared storage while maintaining synchronized access to data. Administrators define database names, storage locations, character sets, and memory parameters. ASM disk groups serve as storage for data files, redo logs, and control files, simplifying storage management and ensuring high availability.
Instances are associated with specific nodes, and services are defined to facilitate workload distribution and failover. Services abstract application connections from individual instances, allowing the cluster to manage client requests dynamically. This approach optimizes resource utilization and improves resilience, as connections are automatically redirected in case of node failures.
Database creation tools validate configuration parameters, check disk accessibility, and verify node communication. Successful creation results in a fully operational RAC database, ready for administration, backup, and performance tuning. Administrators often perform post-creation checks to confirm instance availability, ASM integration, and service registration.
Configuring Network Services and Load Balancing
Effective workload management in RAC environments relies on properly configured network services. Services represent logical groupings of database workloads and provide mechanisms for connection load balancing and failover. Administrators define service parameters, such as preferred instances, failover priorities, and resource allocation policies.
Clients connect to services rather than individual instances, allowing the cluster to dynamically distribute connections based on node availability and current workload. Load balancing reduces contention, optimizes response times, and ensures that resources are utilized efficiently. Failover policies ensure that connections remain available even when instances fail or nodes are taken offline for maintenance.
Network configuration includes assigning virtual IP addresses to each node, ensuring that clients can reach the database regardless of the physical node currently servicing a request. Proper DNS and network routing configurations further enhance availability and reduce the risk of connectivity issues.
Applying Patches and Updates
Maintaining a RAC environment requires regular application of patches and updates to both the Grid Infrastructure and database software. Oracle provides rolling patch capabilities that allow administrators to update one node at a time while others continue processing requests, minimizing downtime.
Patch application involves several steps, including verification of prerequisites, backup of critical data, and coordination with other nodes to ensure uninterrupted service. Administrators must understand dependencies between clusterware, ASM, and database instances to avoid inconsistencies. Testing patches in a controlled environment helps identify potential conflicts and ensures smooth deployment.
Documentation of patch procedures, version tracking, and rollback plans are essential components of patch management. Detailed records help administrators maintain compliance, support troubleshooting, and facilitate future upgrades.
Managing ASM Disk Groups Post-Installation
After the RAC database is operational, ASM disk groups require ongoing management to maintain performance and availability. Administrators monitor disk usage, rebalance operations, and failure group status. Adding new disks or resizing existing disk groups triggers automatic rebalancing, redistributing data to maintain optimal performance.
Regular monitoring helps identify slow disks, hotspots, or potential failure points. Administrators can move data between disk groups, adjust redundancy levels, or rebalance storage to accommodate changing workloads. Understanding ASM metadata, disk group attributes, and allocation strategies is essential for effective management and long-term stability.
Configuring Services for Workload Segmentation
Services allow administrators to partition workloads according to business priorities, application requirements, or resource needs. Each service can be associated with specific nodes, enabling administrators to direct critical transactions to preferred instances while distributing less critical workloads elsewhere.
Service-level management supports failover, ensuring that connections are automatically redirected to available nodes if an instance becomes unavailable. Workload balancing across services reduces contention, improves response times, and enhances overall cluster efficiency. Administrators monitor service performance and adjust parameters as workloads evolve to maintain optimal resource utilization.
Setting Up Monitoring and Alerts
Monitoring RAC environments is essential for early detection of performance issues, hardware failures, or configuration anomalies. Tools provide metrics on instance activity, session statistics, I/O throughput, network latency, and ASM performance. Alerts can be configured to notify administrators of threshold breaches, node evictions, or disk failures.
Proactive monitoring helps administrators identify potential problems before they affect availability or performance. Log analysis, performance metrics, and diagnostic reports provide insights into cluster health, enabling timely intervention. Monitoring strategies often include a combination of automated alerts, periodic manual checks, and trend analysis to anticipate future resource needs.
Troubleshooting Installation and Configuration Issues
Despite careful planning, installation and configuration of RAC and Grid Infrastructure may encounter issues. Common challenges include failed cluster verification checks, disk access errors, network connectivity problems, and misconfigured services. Troubleshooting involves systematic analysis of logs, validation of network connectivity, verification of disk accessibility, and review of configuration parameters.
Understanding the sequence of installation steps, clusterware behavior, and ASM operations is critical to resolving issues efficiently. Administrators often use diagnostic tools to assess node status, service registration, and interconnect performance. Experience and familiarity with Oracle’s recommended practices greatly enhance the ability to troubleshoot and rectify problems quickly.
Ensuring High Availability from the Start
Proper installation and configuration lay the foundation for high availability in RAC environments. Clusterware, ASM, and services must be set up to support failover, load balancing, and resource management. Each component interacts to maintain service continuity, detect failures, and recover gracefully.
High availability planning includes redundancy in network paths, disk group configurations, and node deployment. Virtual IPs, service failover policies, and rolling patch capabilities contribute to resilience, allowing the cluster to continue operations even when individual components encounter issues.
Practical Tips for a Smooth Installation
Successful installation of RAC and Grid Infrastructure requires meticulous attention to detail. Administrators are advised to document all steps, validate configurations at each stage, and ensure that prerequisites are met. Using pre-created scripts for common tasks, verifying disk accessibility, and confirming network interconnectivity helps prevent common pitfalls.
Testing node communication, service registration, and ASM operations immediately after installation ensures that the cluster functions as expected. Regular reviews of logs, alerts, and configuration files contribute to a stable environment and reduce the likelihood of unexpected downtime.
Understanding Backup Strategies in RAC Environments
Backup strategies for Oracle RAC environments are more intricate than single-instance databases due to the presence of multiple nodes and shared storage. Administrators must account for concurrent access, inter-node communication, and consistency across all instances. Backups are crucial not only for disaster recovery but also for mitigating risks arising from human error, hardware failure, or corruption of data files.
A comprehensive backup strategy often involves a combination of full, incremental, and archived redo log backups. Full backups capture the entire database, providing a baseline for recovery, while incremental backups save only the changes since the last full or incremental backup. This approach optimizes storage usage and reduces backup time while maintaining recoverability. Archivelogs allow administrators to restore transactions up to a specific point in time, preserving transactional integrity.
In RAC environments, each instance contributes to the generation of redo logs and temporary files. Coordinating backups to ensure consistency requires tools that are aware of cluster configurations. Administrators often use centralized scripts or automated backup solutions that orchestrate backups across nodes, ensuring that all relevant files are captured simultaneously.
Implementing RMAN for RAC Databases
Recovery Manager (RMAN) is the preferred tool for performing backups and recovery in RAC databases. It understands the cluster architecture and ensures that backups account for multiple instances and shared storage. RMAN allows administrators to perform full, incremental, and differential backups, manage archived redo logs, and maintain catalog metadata that simplifies recovery operations.
RMAN configurations include defining retention policies, backup destinations, and channels for parallel backup execution. Parallelism is particularly valuable in RAC environments, as it allows multiple instances to write backup data concurrently, reducing overall backup time. Administrators can also use RMAN to validate backups, ensuring that they are complete, accessible, and consistent before relying on them for recovery.
Automation of RMAN scripts is crucial for maintaining regular backup schedules. Scheduling tools and monitoring alerts can notify administrators of failures, skipped backups, or other anomalies, allowing for prompt intervention. Integration with storage management solutions, such as ASM, further streamlines the process, as RMAN can directly write to disk groups, bypassing the need for intermediate file systems.
Performing Recovery in RAC Databases
Recovery operations in RAC databases require a precise understanding of the cluster environment and instance interactions. Point-in-time recovery, instance recovery, and media recovery are among the common operations performed to restore data integrity. Point-in-time recovery uses archived redo logs and backups to restore the database to a specific timestamp, often required after human errors or logical corruption.
Instance recovery occurs automatically when a node fails. Surviving instances use redo logs and undo segments to bring the affected instance’s state back in sync with the rest of the cluster. This process minimizes downtime and ensures that transactions are neither lost nor duplicated. Media recovery addresses disk or storage failures and relies on backups to restore corrupted or missing files. Coordination across nodes is critical to ensure consistency and prevent conflicts during recovery operations.
Administrators must be familiar with RAC-specific considerations, such as managing ASM disk groups, cluster services, and interconnect communication during recovery. Understanding how redo logs propagate between instances and how cache fusion operates enables administrators to troubleshoot recovery anomalies efficiently.
Managing Flashback and Point-in-Time Recovery
Oracle RAC supports Flashback Database technology, allowing administrators to revert the database to a previous state without traditional restore operations. Flashback operations rely on undo tablespaces and specialized logs that track changes at a granular level. This capability is invaluable for correcting human errors, recovering from logical corruption, or testing changes in a non-disruptive manner.
Point-in-time recovery complements flashback functionality by providing recovery from backups to a specific timestamp. Administrators must carefully identify the appropriate restore point, verify the availability of backups and redo logs, and coordinate recovery across all instances. Flashback and point-in-time recovery techniques enhance data protection strategies and reduce the risk of prolonged downtime.
Monitoring flashback logs, undo tablespace usage, and ASM disk groups ensures that sufficient resources are available for these operations. Administrators may also establish retention policies to control storage consumption while maintaining the ability to revert to previous states when necessary.
Advanced Administrative Tasks: Resource Management
Resource management in RAC environments is crucial for balancing workloads across multiple instances and ensuring optimal performance. Oracle provides tools for defining resource plans, prioritizing workloads, and controlling resource allocation at the service level. Administrators can assign specific CPU, memory, and I/O limits to critical workloads, preventing resource contention and ensuring that high-priority operations receive sufficient attention.
Service-level resource management allows workloads to be dynamically shifted between instances based on current utilization and availability. This flexibility enhances performance, reduces response times, and ensures that cluster resources are used efficiently. Administrators monitor resource consumption using performance views, workload statistics, and diagnostic tools to identify bottlenecks or misconfigurations.
Dynamic resource allocation is particularly useful in environments with fluctuating workloads. By continuously adjusting resource allocation, RAC maintains service levels and avoids performance degradation during peak usage. Resource management policies also support failover scenarios, ensuring that workloads are automatically reassigned when a node becomes unavailable.
Automating Administrative Tasks
Automation reduces human error, enhances consistency, and allows administrators to focus on higher-level strategic tasks. Commonly automated tasks in RAC environments include database startup and shutdown, backups, statistics gathering, and performance monitoring. Automation scripts, scheduled jobs, and Oracle Enterprise Manager facilitate these operations across multiple nodes simultaneously.
For example, coordinated startup scripts ensure that all instances start in the correct sequence, validate cluster health, and register services. Shutdown procedures can be automated to gracefully close connections, flush redo logs, and stop instances without risking data corruption. Automated monitoring scripts detect anomalies in performance metrics, network interconnect latency, or disk usage, triggering alerts and remediation actions.
Integration with ASM further enables administrators to automate storage management tasks, such as adding new disks, rebalancing data, or resizing disk groups. Automation ensures that these operations occur without manual intervention while maintaining performance and availability.
Monitoring Performance and Diagnosing Issues
Monitoring is essential for maintaining stability and performance in RAC environments. Administrators analyze metrics related to CPU usage, memory allocation, I/O throughput, session activity, and interconnect latency. Oracle provides several tools for performance monitoring, including dynamic performance views, workload history repositories, and diagnostic logs.
Identifying and diagnosing issues requires understanding the interactions between instances, shared storage, and the interconnect. For example, global enqueue waits may indicate contention for frequently accessed data blocks, while excessive redo log activity may suggest inefficient transaction processing. Administrators investigate these patterns, adjust parameters, or redistribute workloads to mitigate performance degradation.
Proactive monitoring is critical for preventing minor issues from escalating into outages. Alerts can be configured for key thresholds, such as disk usage, session wait times, or cluster interconnect errors. Trend analysis over time allows administrators to anticipate resource requirements and plan capacity upgrades.
Security and Compliance Administration
Security administration in RAC environments encompasses authentication, authorization, auditing, and network security. Administrators define roles and privileges, enforce password policies, and implement encryption for sensitive data. Cluster-wide considerations include securing ASM disk groups, protecting interconnect communication, and maintaining service-level access controls.
Auditing and logging are critical for compliance with regulatory frameworks. Administrators track configuration changes, user activity, and service modifications, generating reports for internal review or external audits. Regular security assessments, vulnerability scanning, and penetration testing help identify and mitigate potential risks before they compromise the cluster environment.
Network segmentation and use of virtual IPs further enhance security by isolating interconnect traffic from public access. This reduces exposure to potential attacks and ensures that communication between nodes remains secure and reliable.
Troubleshooting Advanced Issues
Advanced troubleshooting in RAC environments requires an understanding of complex interactions between nodes, instances, and shared resources. Common issues include interconnect congestion, cache fusion conflicts, instance crashes, or ASM disk failures. Administrators diagnose problems by analyzing logs, monitoring wait events, and examining instance coordination.
For example, slow query performance may result from global cache contention or inefficient service placement. Corrective actions could include redistributing workloads, adjusting memory allocation, or tuning interconnect parameters. Node failures are investigated by reviewing clusterware logs, evaluating node status, and assessing voting disk health.
Understanding the sequence of operations in recovery, failover, and resource management helps administrators resolve issues efficiently. Familiarity with Oracle diagnostic tools and best practices allows timely identification and resolution of complex problems, minimizing disruption to end users.
Optimizing Workload Distribution
Optimizing workload distribution in RAC environments involves service-level management, resource allocation, and load balancing. Services abstract workloads from individual instances, allowing dynamic distribution based on node availability, session counts, or CPU utilization. Administrators define service preferences, failover priorities, and resource plans to ensure critical workloads receive adequate resources.
Load balancing reduces contention and improves response times by redirecting requests to underutilized instances. Dynamic adjustments account for fluctuating workloads, maintaining performance during peak activity periods. Monitoring service performance and adjusting parameters ensures that workloads are consistently aligned with business priorities.
Workload optimization also includes identifying long-running queries, analyzing session patterns, and tuning memory or I/O configurations. By understanding the interplay between cache fusion, interconnect traffic, and instance memory, administrators can make informed adjustments that enhance throughput and minimize latency.
Using Diagnostic Tools Effectively
Oracle provides a range of diagnostic tools that facilitate advanced administration and troubleshooting. Performance views, alert logs, and trace files offer insights into instance behavior, interconnect efficiency, and ASM performance. Administrators use these tools to detect anomalies, identify root causes, and implement corrective actions.
Tools such as Automatic Workload Repository and Active Session History provide historical data for trend analysis, helping administrators anticipate future resource needs. Understanding the structure of logs, the meaning of wait events, and the correlation between metrics across nodes is essential for effective problem-solving in RAC environments.
Proper use of diagnostic tools reduces mean time to resolution for complex issues, improves resource utilization, and enhances overall stability. Regular review of logs and proactive analysis prevent small anomalies from escalating into major outages.
Implementing Maintenance Tasks
Maintenance tasks in RAC environments include patching, instance tuning, disk group rebalancing, and service optimization. Rolling patch application allows administrators to update one node at a time while others continue servicing workloads, minimizing downtime. ASM disk groups are monitored and rebalanced as needed to maintain optimal distribution and performance.
Instance tuning involves adjusting memory allocation, process parameters, and configuration settings based on observed workloads. Services are evaluated for failover behavior, resource allocation, and response times. Regular maintenance ensures the RAC environment remains stable, performant, and resilient to hardware or software failures.
Automation, monitoring, and careful planning are key to executing maintenance tasks efficiently. Administrators document procedures, verify configurations, and test updates in controlled environments to reduce the risk of disruption.
Understanding Performance Tuning in RAC Environments
Performance tuning in Oracle RAC and Grid Infrastructure involves harmonizing multiple instances, shared storage, and interconnect networks to achieve maximal throughput and minimal latency. Unlike single-instance databases, RAC environments require administrators to consider inter-node communication, cache coherency, and service-level workload distribution. The goal is not only to accelerate query execution but also to ensure equitable resource utilization across the cluster.
Effective tuning begins with a comprehensive analysis of system metrics. CPU usage, memory allocation, I/O throughput, session wait times, and interconnect latency provide a foundational understanding of performance bottlenecks. Administrators examine these metrics to identify hotspots, whether caused by cache contention, uneven workload distribution, or inefficient disk access. Understanding the interplay between ASM disk groups, redo log allocation, and inter-node message passing is vital for resolving performance anomalies.
Tuning efforts often require iterative adjustments. Memory structures, such as the System Global Area, Program Global Area, and buffer caches, can be resized to optimize caching and reduce physical I/O. Similarly, initialization parameters governing parallel execution, block sizes, and redo log management are modified based on observed workload patterns. These adjustments must consider the distributed nature of RAC, ensuring that changes benefit the cluster holistically rather than only individual instances.
Cache Fusion and Global Cache Management
A core mechanism of RAC performance is cache fusion, which enables direct transfer of data blocks between instances without intermediate disk writes. This approach reduces latency and enhances transaction throughput by allowing instances to share in-memory copies of data efficiently. Administrators monitor global cache activity to ensure minimal contention and maximal utilization.
Global cache management requires careful consideration of frequently accessed data blocks. Hot blocks, subject to repeated modifications, can create contention if accessed simultaneously by multiple instances. Techniques such as partitioning, workload segregation, and service-level routing help distribute load, reducing the likelihood of global enqueue waits. Administrators also adjust interconnect settings and network quality of service to maintain low-latency communication between nodes.
Understanding the types of waits encountered in cache fusion operations is critical for effective tuning. For example, global cache blocks may encounter cr requests, dr requests, or interconnect-induced delays. Recognizing these patterns and correlating them with workload characteristics allows administrators to implement targeted solutions that improve cluster performance.
Memory Management and Tuning
Memory management is a pivotal aspect of RAC optimization. Each instance maintains its own memory structures, but these must work in concert with cluster-wide considerations. System Global Area sizing, buffer cache allocation, shared pool tuning, and Program Global Area adjustments are all essential to achieving balanced performance.
Automatic Memory Management and Automatic Shared Memory Management provide dynamic adjustment capabilities, allowing memory structures to grow or shrink based on observed workload patterns. Administrators monitor memory usage, track wait events, and adjust parameters as needed to avoid contention, paging, or swapping. Special attention is paid to interconnect-related memory allocations, as insufficient buffers can cause delays in cache fusion operations.
Monitoring memory metrics over time helps identify trends and anticipate future requirements. For example, rapid growth in session-related memory usage may indicate inefficient SQL execution or excessive parsing. Adjusting memory allocation or optimizing queries mitigates these effects, ensuring sustained cluster performance.
Optimizing Disk I/O with ASM
Automatic Storage Management plays a critical role in RAC performance, as all instances access shared storage for data files, redo logs, and temporary files. Optimizing disk I/O involves proper disk group configuration, rebalancing, and monitoring of I/O statistics to prevent bottlenecks.
Administrators must consider striping, mirroring, and failure group allocation to achieve both high performance and fault tolerance. ASM dynamically rebalances data across available disks, but careful planning ensures that high-intensity workloads do not overload specific disks. Understanding disk latency, queue depths, and throughput metrics informs decisions about adding new disks, modifying disk groups, or adjusting redundancy levels.
Temporary tablespaces and redo log placement are also critical for I/O optimization. Locating redo logs on high-speed disks and separating temporary file storage from data files reduce contention and enhance throughput. Monitoring I/O wait events provides insights into bottlenecks, enabling targeted adjustments.
SQL Tuning and Execution Plan Analysis
SQL tuning in RAC environments requires understanding both query structure and the implications of distributed execution. Queries executed across multiple instances may experience global cache contention or interconnect-induced delays. Administrators analyze execution plans to identify inefficiencies such as full table scans, Cartesian joins, or excessive context switching.
Optimizing SQL involves rewriting queries, creating appropriate indexes, partitioning large tables, and leveraging parallel execution. Partitioned tables reduce contention for hot blocks and improve response times by localizing I/O operations. Parallel execution distributes workloads across instances, enhancing throughput while utilizing available CPU resources effectively.
Execution plan monitoring tools provide insight into the actual runtime behavior of queries, highlighting bottlenecks and guiding optimization efforts. Administrators combine these insights with workload analysis to prioritize optimization tasks and maintain consistent cluster performance.
Load Balancing and Service Optimization
RAC services enable administrators to manage workload distribution and optimize resource utilization. Services abstract workloads from specific instances, allowing dynamic allocation based on node availability, session count, and resource usage. Configuring preferred instances, failover policies, and resource plans ensures equitable distribution of workloads while maintaining high availability.
Load balancing reduces contention for hot blocks and optimizes response times by directing client connections to underutilized nodes. Dynamic adjustments account for changing workloads, redistributing sessions to prevent overloading specific instances. Administrators monitor service performance, evaluate response times, and fine-tune service parameters to maintain consistent and efficient operation.
Service-level management also facilitates prioritization of critical workloads. By assigning resource plans and defining failover behaviors, administrators can ensure that high-priority transactions are executed promptly, even during periods of peak activity or node failures.
Monitoring and Diagnostic Techniques
Continuous monitoring is essential for maintaining RAC performance. Administrators track metrics related to CPU utilization, memory usage, disk I/O, interconnect latency, and session activity. Dynamic performance views, workload history repositories, and alert logs provide insights into current conditions and historical trends.
Diagnostic tools allow for identification of bottlenecks, anomalies, and misconfigurations. For instance, analyzing wait events such as global cache enqueues, I/O waits, or interconnect-related delays helps pinpoint sources of contention. Administrators correlate metrics across nodes, instances, and services to understand performance holistically and implement targeted optimizations.
Proactive monitoring, combined with trend analysis, enables administrators to anticipate resource requirements, adjust configurations, and plan capacity expansions before performance degradation occurs. Alerts and automated notifications facilitate rapid response to emerging issues, minimizing disruption to business operations.
Parallel Execution and Resource Utilization
Parallel execution is a powerful mechanism in RAC environments that distributes SQL operations across multiple instances, leveraging CPU and I/O resources effectively. Administrators define parallel execution degrees, monitor parallel query performance, and adjust settings based on workload characteristics.
Understanding inter-instance communication during parallel execution is crucial. Excessive data movement across the interconnect can degrade performance, particularly for queries that require access to hot blocks or large datasets. Administrators employ partitioning, efficient join strategies, and optimal query design to minimize interconnect traffic and maximize parallel execution efficiency.
Parallel execution complements other performance strategies, including load balancing, memory optimization, and disk I/O tuning. Administrators monitor metrics such as parallel query execution times, interconnect throughput, and CPU utilization to ensure that resources are used effectively and workloads complete efficiently.
Tuning Cluster Interconnects
The cluster interconnect is the lifeline of RAC environments, facilitating heartbeat messages, cache fusion transfers, and global resource coordination. Proper interconnect configuration is essential for minimizing latency, avoiding packet loss, and ensuring timely synchronization between nodes.
Administrators monitor interconnect latency, throughput, and errors to detect issues that could impair cluster performance. Techniques such as network bonding, redundant paths, and dedicated interconnect switches enhance reliability and reduce the likelihood of split-brain conditions. Understanding the interplay between interconnect performance, cache fusion, and workload distribution informs tuning decisions and ensures that communication remains efficient under varying loads.
Optimizing interconnect performance often involves adjusting buffer sizes, network protocol parameters, and instance-level configurations to match workload characteristics. Low-latency, high-bandwidth interconnects are critical for maintaining RAC efficiency, particularly during peak activity periods or when executing parallel queries.
Wait Event Analysis and Optimization
Wait events provide insight into where time is being spent within the RAC environment. Common waits include I/O waits, global cache waits, latch contention, and enqueue waits. Analyzing these events helps administrators identify performance bottlenecks and determine whether they stem from database design, configuration, or workload patterns.
By categorizing waits and correlating them with SQL execution, memory utilization, and interconnect performance, administrators can implement targeted optimizations. For example, hot block contention may require query tuning, service reassignment, or partitioning, while I/O waits may indicate the need for additional disks, ASM rebalancing, or storage tier adjustments.
Proactive wait event monitoring prevents performance degradation and ensures that RAC environments remain responsive and efficient. Trend analysis over time allows for prediction of emerging bottlenecks and facilitates strategic resource planning.
Tuning Undo and Redo Management
Undo tablespaces and redo logs play critical roles in RAC performance, as they support transaction consistency and recovery operations. Administrators optimize undo allocation to prevent excessive contention, sizing undo tablespaces appropriately based on transaction volume and instance activity.
Redo logs are placed strategically across high-speed storage devices to minimize I/O contention. Log buffer sizing, multiplexing, and redo group management further enhance performance. Monitoring redo log usage and contention patterns helps administrators adjust configurations to reduce waits and ensure that transactions are recorded efficiently.
In RAC environments, redo management also interacts with interconnect traffic. Efficient redo propagation and log file access prevent bottlenecks that could impair cluster performance, particularly during periods of heavy transaction processing.
Implementing Advanced Caching Techniques
Advanced caching strategies enhance RAC performance by reducing physical I/O, minimizing interconnect traffic, and accelerating query response times. Techniques include tuning buffer caches, shared pools, and library caches to ensure frequently accessed data and metadata remain resident in memory.
Administrators analyze access patterns to identify hot blocks, frequently executed SQL, and temporary object usage. Caching strategies are adjusted to accommodate these patterns, including increasing cache allocations, enabling result caching, or leveraging global temporary tables for intermediate data storage.
Understanding how cached data interacts with cache fusion, redo propagation, and instance memory structures allows administrators to implement caching policies that maximize throughput while maintaining consistency across the cluster.
Understanding Security in RAC Environments
Oracle RAC and Grid Infrastructure environments are inherently complex, incorporating multiple instances, shared storage, and interconnect networks. Ensuring the security of such environments requires a multilayered approach that encompasses authentication, authorization, encryption, and monitoring. Security administration begins with defining user roles, privileges, and responsibilities, taking into account both cluster-wide and instance-specific considerations.
Authentication mechanisms validate users before granting access to the database. RAC environments support centralized authentication methods, including LDAP integration, operating system authentication, and password policies. Proper authentication ensures that only authorized personnel can access critical resources, reducing the risk of unauthorized data exposure.
Authorization involves granting permissions to perform specific actions, such as querying tables, executing procedures, or administering database objects. Administrators define roles that encapsulate sets of privileges and assign these roles to users according to their responsibilities. Fine-grained access controls allow for precise permission assignment, ensuring that users can perform required tasks without overexposure to sensitive data.
Encrypting Data at Rest and in Transit
Protecting data both at rest and in transit is essential for safeguarding information in RAC environments. Oracle provides encryption capabilities for data files, redo logs, and temporary files stored in ASM disk groups. Encrypting these files prevents unauthorized access in the event of physical theft, disk failure, or storage mismanagement.
In addition to encrypting storage, administrators implement network encryption for interconnect communication and client connections. Secure Sockets Layer (SSL) and Transparent Data Encryption ensure that data transmitted between instances, services, and clients remains confidential. Proper key management, including rotation and secure storage of encryption keys, is critical for maintaining the integrity of encrypted data.
Implementing encryption strategies requires balancing security with performance. While encryption introduces additional computational overhead, careful configuration of storage and network parameters can minimize latency and maintain cluster efficiency. Administrators monitor encrypted I/O and interconnect activity to ensure that performance remains acceptable under heavy workloads.
Auditing User Activity and System Changes
Auditing is a fundamental aspect of RAC security, providing visibility into user actions, configuration changes, and system events. Oracle RAC environments support detailed auditing of database activities, including login attempts, object modifications, DML operations, and administrative actions.
Audit trails capture essential information such as the user performing the action, the timestamp, the operation type, and the affected object or resource. Administrators analyze audit logs to detect unauthorized activity, identify policy violations, and support regulatory compliance. Auditing also helps investigate incidents, providing a forensic record of actions that led to data anomalies or system errors.
System-level auditing extends beyond database operations to include clusterware, ASM disk groups, and interconnect events. Monitoring node membership changes, service registration, and cluster resource modifications allows administrators to detect potential misconfigurations or malicious actions that could compromise availability or integrity.
Compliance Considerations for Regulatory Standards
RAC environments often host critical applications subject to regulatory frameworks such as GDPR, HIPAA, SOX, or PCI DSS. Compliance requires implementing policies for data protection, retention, and auditing, as well as demonstrating adherence through reporting and documentation.
Administrators ensure that sensitive data is encrypted, access is strictly controlled, and audit logs are maintained for the required retention period. Procedures for backup, recovery, and incident response are documented and tested to demonstrate operational readiness. Compliance also includes validating that services, cluster configurations, and ASM storage align with organizational policies and regulatory requirements.
Regular reviews and assessments help identify gaps in security or compliance. Vulnerability scans, penetration testing, and policy audits allow administrators to proactively address weaknesses, ensuring that the RAC environment meets both internal and external expectations for data protection and operational governance.
Managing Privileged Accounts
Privileged accounts, including database administrators and system users, pose a particular security risk in RAC environments. Mismanagement of these accounts can lead to unauthorized access, accidental data modification, or privilege escalation.
Administrators implement strict controls over privileged accounts, including multifactor authentication, password rotation, and activity monitoring. Separation of duties ensures that no single individual has unchecked control over all critical components, reducing the risk of misuse. Monitoring and auditing privileged account activity provides an additional layer of security, alerting administrators to suspicious or anomalous actions.
Service accounts used for cluster operations, ASM management, and background processes are also carefully managed. These accounts have specific, minimal privileges necessary for operation, preventing overexposure and limiting the potential impact of compromise.
Network Security and Segmentation
Network security is a crucial aspect of RAC hardening, particularly given the dual-network architecture commonly used for public client access and private interconnect traffic. Administrators segregate networks to prevent unauthorized access and reduce exposure to attacks.
Virtual IP addresses and firewalls are used to control access to nodes, services, and ASM resources. Traffic between instances is secured through encryption and monitored for anomalies. Network segmentation ensures that public-facing services are isolated from internal interconnect communications, protecting the cluster from both external and internal threats.
Administrators also implement monitoring of network latency, packet loss, and errors to detect issues that could impact performance or indicate potential security breaches. Proactive measures, such as redundant network paths and failover configurations, enhance both security and availability.
Hardening Clusterware and ASM
Clusterware and ASM are critical components of RAC environments, and their security directly impacts the overall resilience of the system. Hardening involves configuring access controls, monitoring activities, and limiting exposure to unnecessary privileges.
Clusterware components, such as the Oracle Cluster Registry and voting disks, are secured against unauthorized modification. Proper placement of these files on reliable storage, with restricted access, prevents tampering or accidental corruption. ASM disk groups are also carefully managed, ensuring that only authorized instances and users can access the disks.
Monitoring and auditing of clusterware and ASM activities help detect unusual behavior, such as unauthorized node additions, unexpected disk group modifications, or abnormal cluster evictions. Administrators regularly review logs, validate configuration settings, and implement proactive measures to maintain cluster integrity.
Implementing Patch Management for Security
Applying patches is a critical part of maintaining RAC security. Oracle releases regular patches addressing vulnerabilities, bug fixes, and performance improvements. Administrators implement rolling patch strategies, updating nodes one at a time to minimize downtime and maintain high availability.
Patch management involves validating prerequisites, backing up critical data, and ensuring that dependencies between clusterware, ASM, and database instances are respected. Testing patches in a controlled environment helps identify potential conflicts, ensuring smooth deployment. Detailed documentation and rollback procedures are essential for managing risk during patch application.
Regular patching, combined with monitoring for new vulnerabilities, ensures that RAC environments remain secure and resilient against emerging threats. Administrators integrate patch schedules with maintenance windows, balancing operational continuity with the need to address security concerns promptly.
Monitoring for Intrusions and Anomalies
Continuous monitoring is a key aspect of RAC security, enabling administrators to detect intrusions, suspicious activity, or configuration anomalies. Monitoring includes tracking login patterns, session activity, resource usage, and interconnect traffic. Alerts can be configured to notify administrators of unusual events, such as failed login attempts, unexpected node membership changes, or abnormal I/O patterns.
Advanced monitoring tools provide correlation of events across instances, ASM disk groups, and clusterware components. This holistic view allows administrators to identify potential security breaches quickly and respond proactively. Monitoring also supports compliance reporting, providing evidence of oversight and control over the RAC environment.
Securing Backup and Recovery Operations
Backup and recovery operations are an essential part of RAC security. Backup files, whether stored locally, on shared storage, or offsite, contain sensitive data and must be protected. Administrators implement encryption for backup sets, control access to backup destinations, and monitor backup activities for anomalies.
Recovery procedures are secured to prevent unauthorized restoration or tampering. Access controls ensure that only authorized personnel can perform recovery operations, and audit logs track all recovery activities. Maintaining the integrity of backups and recovery procedures is critical for both data protection and regulatory compliance.
Compliance Reporting and Documentation
Maintaining comprehensive documentation is a critical aspect of security and compliance in RAC environments. Administrators document configuration settings, access controls, patching history, audit logs, and incident response procedures. These records provide evidence of adherence to policies and regulatory requirements.
Compliance reporting includes generating summaries of user activity, security events, service-level adherence, and system changes. Reports are tailored to the requirements of specific regulatory frameworks, demonstrating that the RAC environment operates under controlled and secure conditions. Documentation also supports internal reviews, audits, and forensic investigations in the event of security incidents.
Implementing Proactive Security Measures
Proactive security measures include vulnerability scanning, penetration testing, and periodic security reviews. Administrators identify potential weaknesses in RAC configurations, ASM disk groups, clusterware components, and interconnect networks. Mitigating these vulnerabilities before they are exploited reduces the risk of breaches and enhances overall system resilience.
Security awareness and training for administrators and operators are also essential. Understanding best practices, potential threats, and response procedures ensures that personnel can manage the RAC environment securely. Proactive monitoring, regular updates, and diligent oversight collectively create a fortified environment resistant to both internal and external threats.
Managing Service and Instance Security
Services and instances within RAC environments must be secured to prevent misuse or unauthorized access. Service-level authentication, access controls, and monitoring ensure that client connections are legitimate and that workloads are directed appropriately. Administrators configure failover policies and load balancing with security in mind, preventing abuse of resources or accidental exposure of data.
Instance security includes controlling administrative privileges, monitoring instance-level activity, and enforcing secure startup and shutdown procedures. Proper configuration of memory structures, temporary files, and redo logs prevents leakage of sensitive information and maintains transactional integrity.
Handling Security Incidents and Response
Despite preventive measures, security incidents may occur. RAC administrators establish incident response procedures that define roles, responsibilities, and actions for containing, investigating, and mitigating security breaches. Timely identification of anomalies, correlation with audit data, and coordinated response across nodes and instances are critical for minimizing impact.
Recovery from incidents involves restoring integrity, verifying system stability, and validating backups. Post-incident reviews identify root causes, assess effectiveness of controls, and implement measures to prevent recurrence. Continuous improvement of security procedures ensures that the RAC environment evolves to meet emerging threats and changing regulatory expectations.
Understanding Troubleshooting in RAC Environments
Troubleshooting Oracle RAC and Grid Infrastructure environments requires a deep comprehension of cluster dynamics, inter-node communication, and shared storage behavior. Unlike single-instance databases, RAC involves multiple instances accessing common data files simultaneously, introducing complexity in diagnosing performance issues, connectivity problems, and operational anomalies.
Administrators begin by monitoring key metrics such as CPU utilization, memory consumption, interconnect latency, disk I/O throughput, and session activity. Patterns of waits, particularly global cache enqueues, latch contention, and I/O-related waits, often reveal the source of performance degradation. Careful analysis of alert logs, trace files, and dynamic performance views allows identification of root causes with greater precision.
Understanding the sequence of cluster operations is essential. Node evictions, service failovers, and cache fusion operations interact in subtle ways that can influence both availability and performance. Troubleshooting often involves correlating events across nodes and examining clusterware behavior to determine whether anomalies originate from hardware, software, or configuration issues.
Common Troubleshooting Scenarios
Several recurring scenarios require attention in RAC environments. For example, slow query response may stem from cache contention on frequently accessed blocks, inefficient SQL execution plans, or disk group hotspots. Administrators investigate these scenarios by examining query execution statistics, reviewing service placement, and assessing ASM disk utilization.
Another common issue involves node evictions triggered by interconnect failures, heartbeat loss, or cluster quorum mismanagement. Understanding voting disk placement, interconnect redundancy, and cluster verification logs helps administrators prevent unnecessary evictions and maintain high availability. Similarly, redo log contention or slow write operations may signal I/O bottlenecks, prompting disk rebalancing or storage optimization.
Connection failures and service registration issues also arise frequently. Virtual IP misconfigurations, DNS problems, or misaligned service definitions can prevent clients from connecting to available instances. Troubleshooting these problems requires coordinated examination of network configurations, service mappings, and cluster registry entries.
Using Diagnostic Tools Effectively
Oracle provides a suite of diagnostic tools to aid administrators in resolving complex issues. Dynamic performance views offer real-time insights into instance activity, interconnect usage, and session behavior. Alert logs capture critical events, while trace files provide granular information on process execution, waits, and errors.
Proactive monitoring tools, such as Oracle Enterprise Manager, assist administrators in visualizing system health, identifying anomalies, and generating alerts. Historical data from workload repositories enable trend analysis, allowing administrators to correlate incidents over time and anticipate future issues. Combining these tools with structured troubleshooting methodologies ensures efficient problem resolution in RAC environments.
Disaster Recovery Planning and Strategies
Disaster recovery planning is a cornerstone of high availability in RAC and Grid Infrastructure environments. Effective planning requires identifying critical business processes, defining recovery time objectives (RTO), and recovery point objectives (RPO). These parameters guide the design of backup strategies, replication methods, and failover configurations.
Oracle RAC supports multiple disaster recovery techniques, including physical standby databases, logical replication, and Data Guard configurations. Physical standby databases maintain an exact copy of the primary database on a remote site, allowing administrators to switch roles in the event of primary site failure. Logical replication enables selective data propagation to remote systems, providing flexibility for partial recovery or reporting workloads.
Backup policies are integral to disaster recovery. Regular full and incremental backups, combined with archived redo log retention, ensure that the database can be restored to a specific point in time. Administrators must secure backups, monitor their integrity, and verify recoverability to prevent surprises during a disaster scenario.
Implementing Data Guard in RAC Environments
Data Guard integration with RAC environments provides automated failover and switchover capabilities, enhancing resilience. Administrators configure primary and standby databases, ensuring that redo logs are transmitted efficiently and applied consistently to the standby site.
Monitoring Data Guard involves tracking log shipping performance, standby database synchronization, and network latency. Alerts notify administrators of lag or disruptions, allowing timely corrective action. Testing failover procedures ensures that both primary and standby sites can assume operational roles seamlessly, minimizing downtime during planned or unplanned events.
Disaster recovery strategies are further enhanced by configuring services, ensuring that client connections are redirected appropriately after failover. Combining service-level management with Data Guard guarantees continuity of critical workloads and supports high availability across geographically dispersed sites.
Operational Strategies for High Availability
High availability in RAC environments extends beyond disaster recovery to encompass day-to-day operational strategies. Administrators employ rolling upgrades, patching, and maintenance procedures to minimize downtime while ensuring that all nodes remain synchronized and services remain accessible.
Instance tuning, load balancing, and resource management contribute to sustained high availability. By defining service-level resource allocations, prioritizing workloads, and monitoring resource consumption, administrators prevent performance bottlenecks and maintain responsive systems under peak loads.
Redundancy in network interconnects, disk groups, and voting disks further enhances operational stability. Administrators regularly validate cluster health, verify service registration, and monitor inter-node communication to ensure that failures are handled gracefully without impacting user operations.
Capacity Planning and Scalability
Scalability and capacity planning are essential for future-proofing RAC environments. Administrators analyze workload trends, session growth, and data volume increases to anticipate resource needs. Scaling involves adding new nodes, expanding ASM disk groups, or adjusting memory allocations to accommodate evolving requirements.
Dynamic workload redistribution through service-level management ensures that newly added resources are utilized efficiently. Parallel execution, caching strategies, and optimized interconnect configurations complement capacity planning, allowing the cluster to handle increasing demands without compromising performance.
Monitoring metrics over time, including CPU, memory, I/O, and session activity, informs proactive adjustments. Predictive analysis enables administrators to implement scaling measures before resource exhaustion occurs, maintaining optimal performance and availability.
Advanced Maintenance Strategies
Maintenance in RAC environments requires careful coordination to prevent service disruption. Rolling patch applications, node-by-node upgrades, and controlled service migration allow administrators to perform updates without complete system downtime.
ASM disk management, including rebalancing and resizing, is scheduled to minimize impact on active workloads. Memory and redo log adjustments are performed in accordance with workload patterns, ensuring that operational efficiency remains high throughout maintenance activities.
Automation plays a key role in advanced maintenance, with scripts and scheduling tools orchestrating repetitive tasks such as backups, statistics gathering, and system verification. This reduces human error, ensures consistency, and frees administrators to focus on strategic improvements.
Proactive Monitoring and Predictive Analysis
Proactive monitoring extends troubleshooting and maintenance into predictive territory. Administrators leverage historical metrics, trend analysis, and anomaly detection to anticipate potential performance degradation, resource contention, or failures.
Predictive analysis of interconnect latency, disk group performance, and session behavior enables early intervention, such as redistributing workloads, adding storage, or tuning memory allocations. This approach minimizes the likelihood of unplanned downtime and supports continuous operational excellence.
Monitoring also informs capacity planning, disaster recovery readiness, and performance tuning strategies. By combining real-time alerts with historical trend analysis, administrators maintain a comprehensive understanding of the RAC environment and can respond to emerging challenges proactively.
Integrating Backup and Disaster Recovery
Backup and disaster recovery strategies are intertwined, forming the foundation of resilient RAC operations. Administrators align backup schedules with recovery objectives, ensuring that full, incremental, and archivelog backups are available for restoration to a defined point in time.
Integration of backup tools with ASM, Data Guard, and service-level management ensures that recovery processes are consistent and efficient. Automated backup verification, combined with periodic restore tests, validates the integrity of backup data and confirms that recovery procedures meet business requirements.
Coordinated disaster recovery planning, combined with robust backup strategies, ensures that data loss is minimized and downtime is controlled, even in catastrophic scenarios. This holistic approach strengthens the reliability and trustworthiness of RAC deployments.
Handling Performance Degradation During Failover
Failover events, whether due to node failure or planned maintenance, can introduce temporary performance degradation. Administrators anticipate these scenarios by defining service priorities, allocating resources dynamically, and monitoring interconnect and disk group activity.
Load balancing and resource management ensure that critical workloads are prioritized during failover, while lower-priority operations may experience temporary throttling. Monitoring session activity, wait events, and I/O throughput during failover allows administrators to adjust configurations and maintain acceptable performance levels.
Understanding the interactions between cache fusion, redo propagation, and service registration is essential for minimizing the impact of failover. Effective planning, combined with real-time monitoring, ensures that users experience minimal disruption and that recovery is seamless.
Advanced Operational Strategies for Long-Term Stability
Long-term stability in RAC environments relies on a combination of preventive maintenance, monitoring, capacity planning, and proactive performance management. Administrators implement structured procedures for patching, backups, service optimization, and resource allocation to maintain a reliable operational environment.
Continuous evaluation of cluster health, memory utilization, disk performance, and interconnect efficiency supports ongoing tuning and optimization. By integrating predictive analysis, automated maintenance, and service-level management, administrators sustain high availability, consistent performance, and robust resilience over time.
Documenting operational procedures, incident responses, and maintenance activities ensures that institutional knowledge is preserved and facilitates rapid onboarding of new administrators. Continuous learning and adaptation to emerging best practices reinforce the RAC environment’s stability and efficiency.
Leveraging Automation and Orchestration
Automation is critical for managing complex RAC environments efficiently. Administrators leverage automated scripts, scheduled jobs, and orchestration tools to perform routine tasks such as backups, rebalancing, patching, and monitoring.
Automation reduces the risk of human error, ensures consistency across nodes, and allows administrators to focus on strategic initiatives. Integration with monitoring and alerting systems enables responsive, automated remediation of minor issues before they escalate into operational disruptions.
Advanced orchestration extends automation to multi-node operations, coordinating maintenance, failover testing, and capacity scaling across the entire cluster. This holistic approach ensures seamless operation, high availability, and optimized resource utilization.
Conclusion
Oracle 12c RAC and Grid Infrastructure provide unparalleled capabilities for high availability, scalability, and performance. Effective troubleshooting, comprehensive disaster recovery planning, and advanced operational strategies are essential for harnessing the full potential of these environments. By integrating proactive monitoring, predictive analysis, automated maintenance, and service-level management, administrators can ensure that RAC deployments remain resilient, performant, and secure.
Combining technical expertise with structured procedures allows organizations to minimize downtime, optimize resource utilization, and achieve operational excellence. Strategic planning, disciplined administration, and continuous improvement create a RAC environment that supports critical business operations while accommodating growth and evolving requirements.
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
