
Exam Code: NS0-093
Exam Name: NetApp Accredited Hardware Support Engineer
Certification Provider: Network Appliance
Product Screenshots
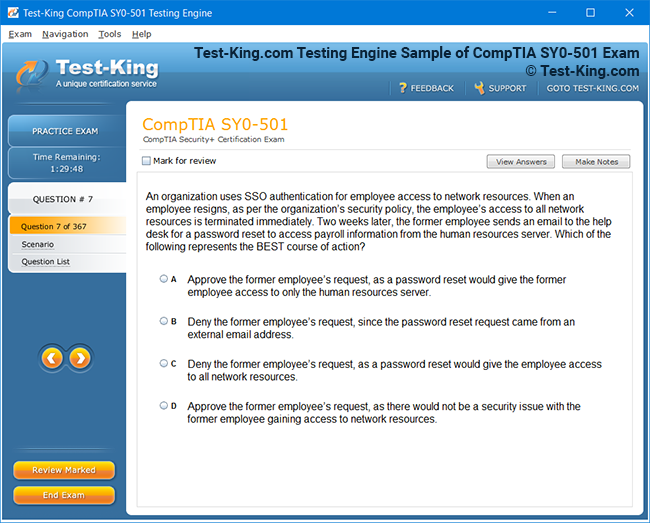
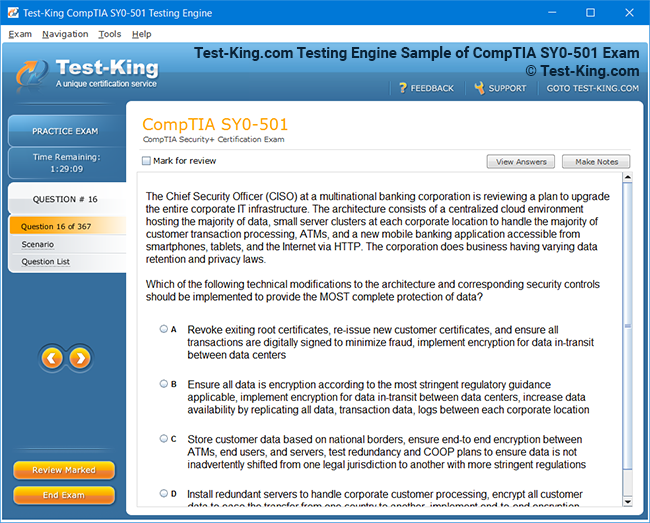
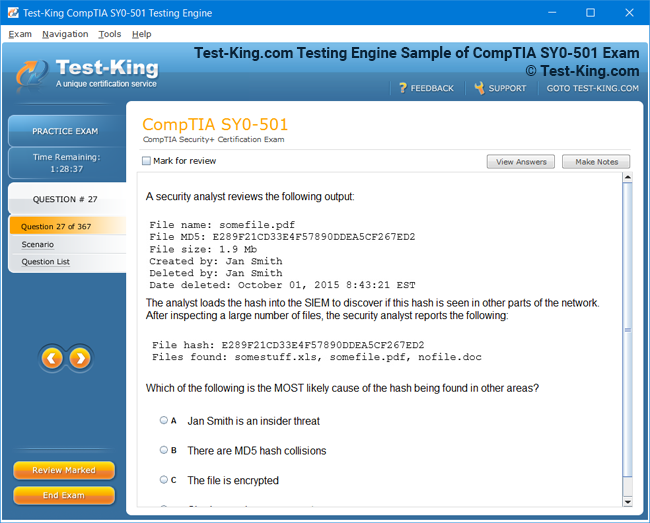
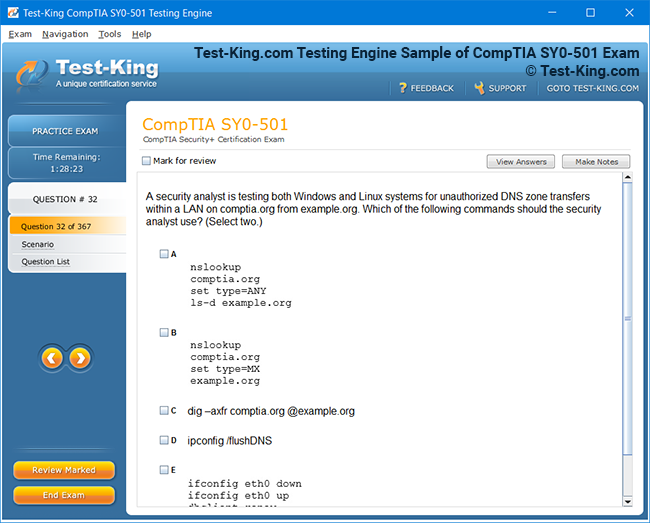
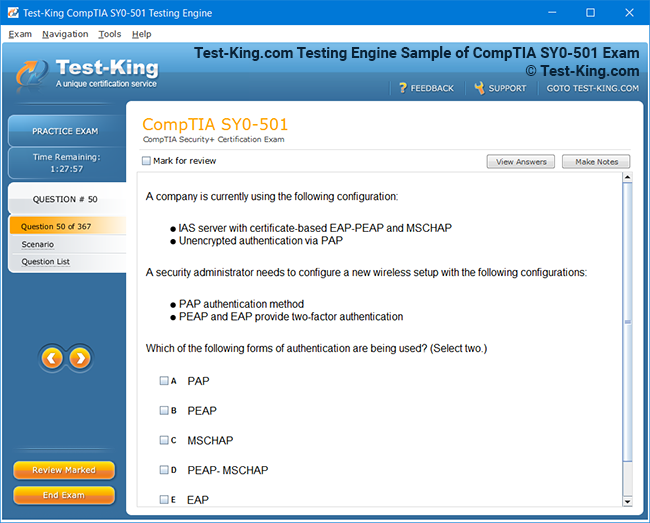
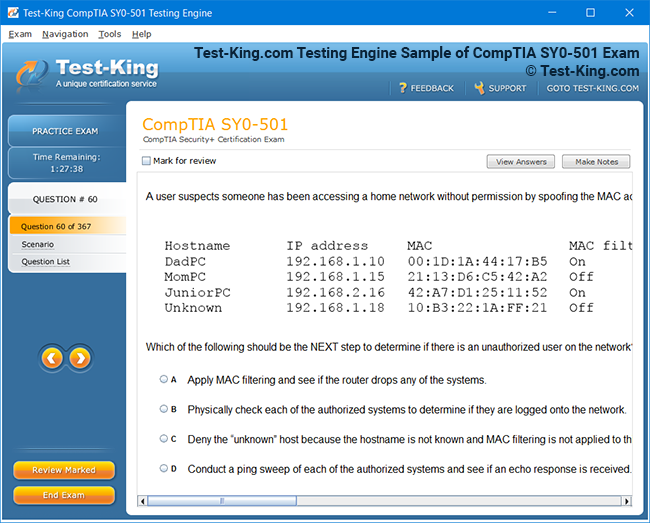
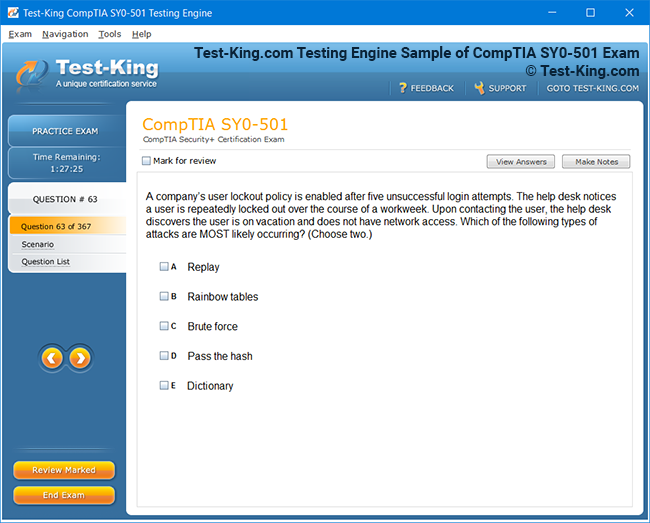
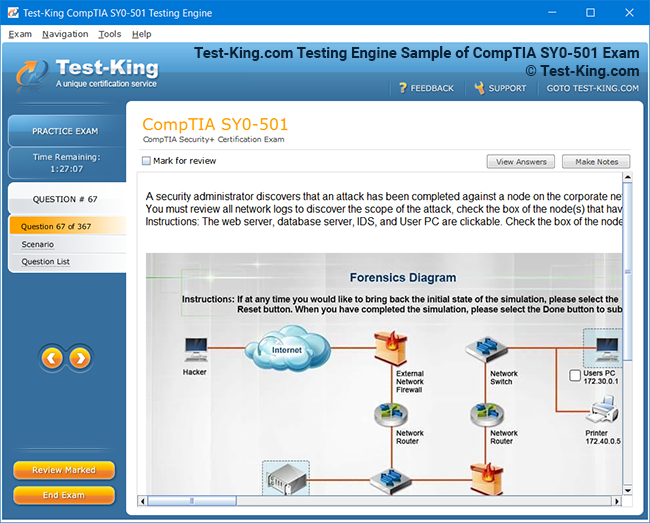
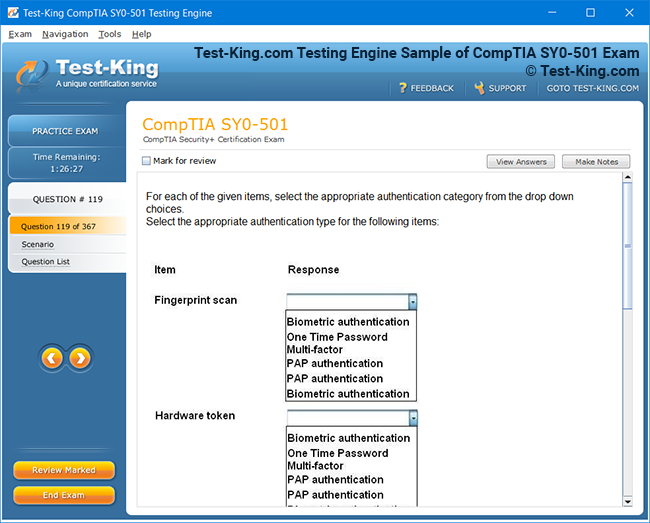
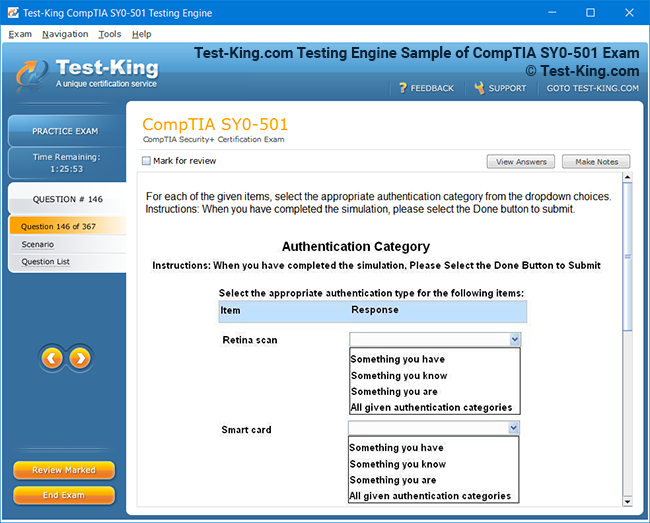
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Top Network Appliance Exams
- NS0-165 - NetApp Certified Data Administrator, ONTAP
- NS0-521 - NetApp Certified Implementation Engineer - SAN, ONTAP
- NS0-528 - NetApp Certified Implementation Engineer - Data Protection
- NS0-005 - NetApp Certified Technology Solutions Professional
- NS0-164 - NetApp Certified Data Administrator, ONTAP
- NS0-194 - NetApp Certified Support Engineer
- NS0-184 - NetApp Certified Storage Installation Engineer, ONTAP
- NS0-093 - NetApp Accredited Hardware Support Engineer
- NS0-175 - Cisco and NetApp FlexPod Design
- NS0-604 - Hybrid Cloud - Architect
NS0-093 Exam : Environmental and Power Requirements for NetApp Hardware Deployment
Deploying NetApp hardware within a data environment requires a meticulous approach that ensures efficiency, longevity, resilience, and unerring operational steadiness. Storage infrastructure thrives when environmental conditions and electrical arrangements are managed with precision. When these parameters are ignored or maintained haphazardly, the consequences may manifest as performance degradation, thermal stress, premature component teardown, unpredictable outages, or cascading failures that impact mission-critical business workloads. This narrative explores the essential environmental and power considerations for NetApp hardware deployment, emphasizing airflow dynamics, thermal sustainability, structured rack arrangement, humidity regulation, grounding discipline, power redundancy, and preventive oversight. The discussion focuses on shaping a conscientious awareness that avoids oversimplification and promotes operational safeguarding in professional storage environments.
Understanding the Environmental and Power Framework for Reliable NetApp Hardware Operation
When organizations host NetApp systems, the hardware architecture interacts intricately with its environment. Storage controllers, expansion shelves, and disk arrays generate heat while continuously running input and output operations. Without carefully managed airflow, hot air cycling may intensify thermal loads and jeopardize hardware integrity. Likewise, electrical power distributed to NetApp systems must provide consistent voltage, protective buffering, orderly redundancy, and stable grounding patterns to prevent electrical disturbances. Examining these aspects helps professionals maintain excellence in storage environments.
One foundational consideration in the environmental realm is the spatial layout of the data room or data center that will host the equipment. The placement of NetApp systems inside standard rack enclosures demands mindful alignment. Cooling patterns within a data facility often follow the traditional hot aisle and cold aisle strategy. Chilled air is directed toward the front of storage units, while heated exhaust air exits through the rear. Ensuring this directional airflow aligns with design principles preserves hardware temperatures within recommended ranges. If hardware is installed improperly, such as with reversed airflow orientation or in proximity to devices expelling high heat, temperature regulation becomes inconsistent. During continuous operations, thermal deviations stress components and accelerate wear. To counteract this, rack placement must harmonize with standardized cooling flows.
Cooling is influenced not only by rack orientation but also the capacity of the room’s HVAC systems. Data center cooling capacity is typically measured based on the heat output of equipment. Every hardware element, including storage controllers and disk shelves, contributes to thermal accumulation. A calculation of British Thermal Units or corresponding thermal units helps determine the necessary cooling output. For NetApp environments, ensuring the HVAC system is appropriately sized is fundamental, but equally important is maintaining airflow without obstruction. Cabling organization plays a role here. Dense cable bundles congesting the rear of a storage chassis can trap exhaust heat, impairing air circulation. Professional installations evaluate cable pathways and ensure that cables do not impede ventilation.
Humidity control is another essential environmental pillar. When humidity levels fall too low, electrostatic discharge risk increases, posing a hazard to sensitive electronic components. Conversely, high humidity invites condensation, corrosion, and fungal growth. Striking the correct balance sustains reliability. Data centers often rely on automated humidity monitoring systems that maintain relative humidity within an acceptable median range. The purpose is not merely to protect the hardware from immediate failure, but also to preserve component stability over prolonged operational lifespans. Storage environments require continuous awareness because humidity shifts can occur due to external seasonal variations, equipment additions, or system failures in climate control units. Stability must be preserved to avoid radical atmospheric fluctuations.
Alongside environmental requirements, power infrastructure forms one of the most vital influences on NetApp hardware deployment. Electrical power must remain continuous and stable. Systems supporting enterprise workloads cannot afford downtime caused by voltage spikes, surges, brownouts, or sudden outages. Redundant power arrangements ensure equipment remains operational even when one power source is compromised. Many storage enclosures come equipped with dual power supplies designed to connect to two independent power circuits. By feeding each supply from separate power distribution units, redundancy is maintained. If one power path falters, the other sustains the system without interruption. This architectural principle strengthens business continuity and safeguards data accessibility.
Power distribution units installed in data racks must match capacity ratings that align with storage system draw. Overloading a PDU risks overheating and system instability. Likewise, uninterruptible power supplies add a protective layer, providing temporary backup power during utility interruptions. This grace period allows systems to continue functioning or, if necessary, be gracefully shut down to protect the integrity of data and file systems. The quality of the UPS matters, especially when dealing with sensitive storage workloads that depend on stable voltage regulation. Line conditioning capabilities ensure electrical noise and distortions are minimized. The consistency of power contributes to predictable operational behavior.
Grounding practices are also pivotal. A well-grounded installation shields equipment from electrical anomalies and static discharge. Errors in grounding may create hazardous faults that could propagate through interconnected systems. Installation teams must align with grounding protocols and ensure that grounding lines, terminal blocks, and protective bonding are secured correctly. This is not merely an electrical precaution; it is a stability and longevity necessity. Proper grounding weaves into system resilience and reduces risks of hardware damage.
Environmental preparation involves evaluating the room’s physical structure. The depth and height of racks must match the dimensions of NetApp units. Adequate clearance must exist not just at the front and rear of racks, but also beneath raised flooring or above suspended ceilings if cooling systems and cable paths utilize these spaces. Some facilities employ raised floors as air plenums to deliver cooled air upward into hardware inlets. However, if the airflow under the raised floor is obstructed by cables, debris, or uneven paneling, the chilling effect is diminished. Routine inspection prevents such airflow blockages. Similarly, overhead cable trays must not trap warm air near exhaust outlets. A balanced approach prevents thermal layering.
Sound levels within the data environment should not be disregarded. NetApp hardware contains fans that adjust speed based on temperature feedback. When the environment reaches elevated temperatures, fans accelerate, increasing noise output. This is not merely an auditory concern; it signals environmental stress. If fan speeds frequently remain high, the system is signaling that ambient cooling is insufficient. In such cases, either the cooling capacity needs adjustment, or airflow impediments must be resolved. Monitoring fan performance becomes an indirect environmental diagnostic tool. Intelligent maintenance teams interpret such patterns.
When implementing storage clusters or scaling environments, the density of equipment becomes a consideration. Dense deployment intensifies thermal output. Organizations planning large NetApp clusters should ensure facilities scale cooling capacity parallel to cluster expansion. Insufficient scaling results in gradual rises in equipment temperature trends over time. Trend analysis plays a meaningful role. Instead of reacting only when thermal warnings appear, monitoring tools can observe temperature curves. A rising curve may imply environmental inadequacies before a failure occurs. Proactive facilities management incorporates these readings into operational planning.
Preventive maintenance is instrumental in sustaining ideal environmental and power conditions. Dust accumulation inside or around racks obstructs airflow and introduces thermal inefficiencies. Periodic cleaning schedules prevent dust infiltration into fans and vents. Visual inspections detect worn cables, loose power connectors, or discoloration indicating heat stress. Equipment that operates continuously benefits from systematic review, ensuring no subtle degradation progresses unnoticed. Maintenance routines should not rely on crisis events but instead cultivate regular observation.
System firmware and controller boot environments interact with hardware health as well. Power interruptions during firmware procedures can cause failures. Ensuring stable power during maintenance operations is essential. Before initiating firmware modifications, checking the operational integrity of power distribution and UPS runtime capacity prevents unintended complications.
When storing and staging NetApp hardware before deployment, environmental considerations remain relevant. Hardware should not be stored in locations experiencing high humidity, excessive temperature fluctuations, or unregulated dust exposure. Components stored improperly before installation may suffer latent failures that only surface after deployment. Care during staging secures reliability once the system enters live use.
Transport considerations are also essential. When moving NetApp appliances, either within a facility or from one location to another, shock, vibration, and tilt angles must be controlled. Hard drives and solid-state components can be sensitive to abrupt impacts. Handling care prevents unintentional micro-damages that compromise storage device reliability. It is not enough to handle hardware carefully during installation alone; the entire lifecycle from shipping to operational placement influences the reliability of the system.
Data center personnel must understand these environmental and power principles not just theoretically but in practical application. Visualizing how air behaves through rack enclosures, how humidity interacts with electronic assemblies, and how electrical power flows through redundant paths builds an intuitive awareness. This awareness enables quick identification of environmental risks and promotes protective action before complications escalate. Thorough documentation supports organizational memory. Diagrams of rack placement, cable routing, power distribution paths, and grounding layouts provide clarity for both new technicians and experienced engineers.
In environments that employ modular data center technologies, containerized computing spaces, or edge deployments, environmental expectations become even more critical. External climates influence internal facility conditions far more aggressively in these contexts. Desert climates, coastal humidity, mountain low-pressure environments, and industrial dust zones all impose unique environmental pressures. In such deployments, additional filtration, reinforced cooling, portable humidity stabilizers, and rugged enclosure designs may be necessary. Understanding these contextual variables ensures that NetApp hardware remains dependable even when deployed at the network edge, remote branches, or specialized facilities.
Continuous monitoring forms the basis of environmental sustainability. Modern systems include sensors that track temperature, fan speeds, airflow rate, power supply output, power draw trends, and voltage fluctuations. Integrating these readings with centralized monitoring dashboards gives data center technicians a panoramic real-time view of environmental health. Alerts notify when thresholds approach risk zones. Taking immediate corrective action prevents failures. Human awareness and automated oversight coalesce to reinforce the stability of NetApp environments.
When designing or assessing data center upgrades intended to support NetApp deployments, planning should account for future growth. Equipment lifecycles, capacity expansions, densification, and performance upgrades may require more cooling power, more electrical feeds, or more rack space. Planning ahead prevents rushed modifications that compromise environmental integrity. Strategic foresight enhances operational continuity.
By maintaining carefully controlled environmental and power conditions, NetApp hardware operates gracefully, achieving sustained performance and reliability. Such environments reflect a philosophy of protection, intentionality, and operational wisdom. The storage infrastructure becomes more than equipment; it forms a dependable backbone for enterprise computing, supporting data availability with elegant consistency.
Advanced Considerations for Stabilizing Cooling Dynamics, Power Redundancy, and Operational Continuity in NetApp Infrastructure
The careful orchestration of environmental parameters and electrical continuity is imperative in sustaining the dependable functioning of NetApp storage systems across diverse data landscapes. Once the foundational understanding of airflow management, heat distribution, and balanced humidity is recognized, deeper intricacies arise in how these variables behave under evolving workloads, equipment densification, room scale expansion, and shifting operational patterns. The environmental ecosystem supporting NetApp hardware should never exist as a static construct. Instead, it must present itself as a living continuum, capable of sensing fluctuations, accommodating changes, reinforcing resilience, and guarding against internal and external perturbations. Elaborating on these advanced conditions illuminates the path toward creating an infrastructure environment embodying endurance, harmony, and technological elegance.
NetApp hardware continuously processes data through storage controllers, disks, caching mechanisms, network interfaces, and associated interconnects. This perpetual movement of data and electrical signals naturally induces heat, electrical draw variation, and airflow turbulence. When device density increases within a rack or cluster, heat concentration elevates in hyper-local zones. These micro thermal pockets are subtle yet impactful, often forming in areas blocked by cable bundles, obstructed vent perforations, or insufficient rack spacing. While general facility cooling may seem adequate, localized hot regions create thermal stress zones that can shorten component longevity. Preventing such occurrences requires engineers to engage in meticulous airflow diagnostics. This may involve tracing airflow paths with thermal imaging, measuring air velocity at intake vents, and evaluating exhaust airflow pressure patterns. Sometimes, adjustments as seemingly minor as rerouting a cable bundle or rotating a unit’s vertical alignment can rejuvenate cooling equilibrium.
Moreover, data centers may employ containment strategies that isolate hot and cold streams, improving cooling efficiency while limiting energy waste. Cold aisle containment surrounds cold intake aisles, allowing chilled air to saturate equipment fronts without intermixing with hot exhaust streams. Hot aisle containment encapsulates the outflow side, channeling heated air toward return ducts. The choice between these containment strategies depends on facility architecture, thermal gradients, budget availability, and scalability plans. For NetApp environments, where hardware arrays may expand over time, containment planning must anticipate equipment growth rather than reacting after heat escalation becomes evident. Thoughtfully installed containment solutions reduce fan load inside storage systems. Reduced fan intensity leads to quieter operation, lower wear on fan bearings, stabilized component temperatures, and a more graceful thermal profile overall.
Humidity remains a crucial factor, but its relationship with temperature is more nuanced than simple thresholds. When data center temperature rises but humidity remains low, the increased dryness intensifies electrostatic discharge risk. When humidity rises and temperature drops, condensation hazards may emerge on metallic and circuit surfaces. Therefore, humidity control must work in tandem with temperature regulation to produce stable atmospheric conditions that protect sensitivity-prone storage elements. Facilities often utilize automated sensors to maintain an equilibrium zone, but operators must be prepared for environmental drift caused by seasonal influences, mechanical failures, or human error. Routine atmospheric logging allows predictive pattern recognition. If the humidity curve begins trending upward during particular hours or seasonal periods, proactive adjustments can prevent harmful anomalies.
The structural and spatial organization of NetApp hardware installations also contributes to environmental success. Rack enclosures must provide not just vertical support but sufficient depth to permit complete airflow clearance and backend cable management space. Placing systems in enclosures lacking proper clearance constrains cooling efficiency. When racks are positioned too close together, or when rear access panels remain closed during operation, airflow stagnation intensifies. Some facilities allow for filtered perforated floor tiles positioned directly beneath rack intake fronts, channeling cooled air precisely where systems require it. Ensuring these tiles remain unobstructed by debris or misplaced equipment is critical. Minor obstructions can cause disproportionate airflow loss.
The electrical power dimension requires attention equal to environmental detail. Stable and redundant power supply pathways underpin continuous NetApp function. Dual power supplies in NetApp systems should receive power from separate power distribution sources rather than drawing from the same electrical circuit. This separation prevents a single circuit failure from disabling the system. In larger environments, electrical redundancy is typically structured in tiered configurations, often referred to as redundant configurations in the electrical infrastructure domain. While the naming conventions may differ depending on the design approach, the underlying principle is consistent: no single electrical pathway should be capable of bringing down a critical storage environment.
Electrical power consistency extends beyond redundancy. Voltage regulation must be smooth and noise levels must remain minimal. Voltage fluctuations, often invisible to casual observation, can degrade component longevity. When fluctuations become frequent, even if small, the constant micro-adjustment stresses capacitors, regulators, and power conversion circuits. Over time, this contributes to hardware vulnerability and operational instability. Uninterruptible power supplies with voltage conditioning capabilities stabilize such fluctuations. The storage environment should also include surge protection elements to defend against abrupt transient spikes that may originate from external utility infrastructure or internal switching events.
Grounding discipline is a foundational pillar within electrical deployment. A properly grounded system protects both human operators and equipment assets. Incorrect grounding can lead to unintended current movement or static accumulation. Engineers must evaluate grounding continuity across racks, PDUs, chassis frames, and building grounding grids. If the grounding network exhibits inconsistent resistance at different points or suffers from corrosion, degradation, or loose bonding points, subtle and unpredictable electrical behavior may occur. Addressing grounding oversights sometimes requires coordinated facility-level maintenance rather than localized equipment focus.
Cooling and electrical power considerations also intersect in ways that may not be immediately obvious. Increasing cooling system performance typically increases electrical consumption. Likewise, electrical inefficiencies generate heat requiring additional cooling effort. Therefore, the energy ecosystem supporting NetApp deployments behaves as a coupled balance. Optimizing one dimension may beneficially influence the other. For instance, improving airflow and containment may reduce fan speeds, in turn decreasing power draw. Lower power draw reduces heat output. Reduced heat allows the cooling system to operate in a more stable and less stressed state, enhancing efficiency and extending equipment lifespan. This mutual reinforcement creates a self-sustaining cycle where environmental health promotes electrical stability and vice versa.
Scaling NetApp hardware deployments introduces further considerations. When clusters expand, power circuits must be sized to anticipate future electrical load rather than solely accommodating existing equipment. Planning for future load capacity prevents the need for rushed or improvisational power reallocation, which can introduce instability. Likewise, cooling and airflow plans should leave overhead for expansion. Facilities that scale reactively often encounter hotspots or overloaded power strips. Forethought ensures that expansion appears graceful rather than abrupt.
Monitoring plays a vital role in advanced environmental and power management. NetApp hardware includes temperature, fan speed, and power monitoring capabilities that integrate with centralized management platforms. Facility teams should utilize these metrics not as emergency alerts but as data streams that reveal ongoing environmental health. When temperatures trend upward across multiple storage arrays, the trend indicates broader environmental drift rather than isolated equipment failure. If multiple controllers simultaneously exhibit rising power draw without corresponding workload increase, then the cause may lie in environmental strain rather than system load. Human interpretation of metric patterns is irreplaceable. Automated systems provide data, but skilled personnel provide meaning.
At a broader operational level, organizational awareness contributes to environmental stability. Facilities and IT teams must communicate effectively. The facility team may handle HVAC, electrical distribution, and physical building maintenance, while the IT team configures systems, ensures firmware integrity, deploys clusters, and maintains logical data flow. Misalignment between these groups can undermine even the best technical planning. For example, if the facility team schedules a cooling unit maintenance shutdown without notifying IT, NetApp systems may suddenly face thermal stress. Likewise, IT may expand system capacity without informing the facility team of increased heat output requirements. Establishing shared operational calendars, coordinated escalation protocols, and clear reporting lines reduces these hazards.
Environmental considerations extend beyond the data center interior when deployments occur in branch offices, remote locations, industrial environments, or edge computing sites. These environments often lack the controlled precision of centralized facilities. Remote deployments may rely on small-scale cooling solutions, office-grade power circuits, or inconsistent electrical frequency stability. Dust levels may be higher, airflow may be more restricted, ambient temperatures may fluctuate widely, and access to on-site technical personnel may be limited. In these contexts, deploying NetApp equipment requires reinforcing environmental armor. This may include additional enclosure sealing, dust filtration modules, vibration dampening pads, and portable climate stabilizers. The key principle remains the preservation of system stability despite external variability.
Transportation and physical handling continue to influence system reliability. Hard drives, cables, connectors, interface cards, and chassis structures all react to vibration and shock forces. When equipment is transported or repositioned, even short distances within the same facility, abrupt impacts or tilting can damage drive assemblies or loosen internal seating. Ensuring that staff handling equipment understand proper lifting techniques, transport preparation, and re-securing of internal modules protects hardware integrity. Visual inspection after transport should verify that drive carriers remain locked, fans seated, cables routed, and power modules latched.
Recordkeeping supports ongoing environmental and power consistency. Documenting rack layout, airflow direction, PDU assignments, UPS runtime capacity, grounding points, and sensor configuration allows future engineers to maintain continuity. Without documentation, operational knowledge dissolves over time, particularly as staff roles shift. Maintaining these records in clear formats that future teams can reference ensures that environmental intelligence persists.
The ethos underlying advanced environmental and power integrity is the cultivation of stability. Stability emerges not from any single technological choice but from a thoughtful interplay of airflow, electrical redundancy, temperature control, protective grounding, operational foresight, spatial arrangement, and continuous monitoring. When these elements synchronize, NetApp hardware enters a realm of sustained reliability, minimizing risk, maximizing performance efficiency, and enabling organizational confidence in the storage layer that sustains data operations.
Sustaining Thermal Balance, Electrical Stability, and Infrastructure Longevity in Evolving Operational Landscapes
Creating an enduring operational environment for NetApp storage infrastructure requires a deeper exploration of the interplay between physical climate, power reliability, ongoing monitoring, and the way these adaptive mechanisms transform with scaling workloads and changing organizational priorities. The environment must remain more than just adequate; it must be optimized, responsive, and resilient. As organizations expand their storage frameworks, integrate more applications, and accommodate increasingly intensive data operations, the atmospheric and electrical conditions that support NetApp hardware must evolve in parallel. This narrative explores this evolving interplay by examining how data centers and distributed sites can continually preserve, monitor, and refine environmental and power conditions while preventing subtle erosion in equipment reliability, component durability, and storage performance fidelity.
A central principle in establishing sustainability for NetApp environments lies in maintaining thermal equilibrium at both micro and macro scales. Even when general ambient temperatures appear stable, airflow irregularities can create concentrated warm pockets that silently exert stress on chassis components, controller boards, memory modules, disk surfaces, and power regulators. These localized hotspots may develop behind cable assemblies, within crowded racks, or near equipment that emits high heat. Over time, these hotspots gradually shorten component lifespan, triggering intermittent faults that may appear unpredictable. To prevent such gradual degradation, technicians must regularly evaluate air movement patterns, mechanical ventilation integrity, and the distribution of heat across equipment arrays.
Thermal equilibrium begins with ensuring that chilled air reaches equipment intakes without obstruction. This necessitates thoughtful placement of racks to align with cold aisle pathways, precise orientation of intake panels, and disciplined cable arrangement behind chassis units. When cables accumulate in disorganized bundles, airflow resistance intensifies, forcing system fans to work harder. Increased fan speed not only elevates energy consumption but also increases wear on fan bearings and blower motors. Maintaining clear ventilation paths ensures that cooling systems operate at designed efficiency levels, preserving both performance and hardware longevity.
The temperature stability of the room also relies on the steady functioning of the facility’s cooling apparatus. Any fluctuation in the cooling system, whether caused by mechanical wear, filter clogging, coolant depletion, or miscalibrated thermostatic control, can result in gradually rising temperatures. Continuous thermal monitoring combined with predictive maintenance routines can detect gradual drifts long before thresholds move into hazardous territory. This predictive maintenance is vital, because waiting until alarm thresholds trigger may coincide with thermal stress already affecting system reliability. It is not the alarm event itself that should drive action, but the observed trend that precedes it.
Humidity regulation must remain synchronized with temperature management to preserve internal component stability. An environment too dry increases static discharge risks, especially when personnel interact with racks or when air circulates rapidly through ventilation channels. On the other hand, excess humidity introduces risks of moisture condensation or slow corrosion on metallic conduits and connectors. Even minor moisture accumulation can accelerate oxidation within connector pins or circuit traces, leading to increased electrical resistance and potential signal instability. Maintaining humidity within a controlled range fosters a protective equilibrium, supporting both electronic safety and component longevity. This equilibrium becomes even more essential when equipment operates in climates with drastic seasonal atmospheric swings.
Electrical integrity forms another fundamental axis in maintaining the resilience of NetApp systems. Power supplied to storage clusters must remain stable, continuous, and evenly distributed. Voltage fluctuations, even if brief, can cause internal voltage regulators and capacitors to engage in repeated compensation cycles. When such compensation becomes persistent, thermal and electrical stress accumulates inside delicate circuitry. Power fluctuations may result from grid instability, transformer variances, or harmonics within the building’s electrical network. To counteract these influences, uninterruptible power units with voltage conditioning must be utilized. These devices filter noise, regulate current flow, and offer interim continuity when external supply interruptions occur.
Redundancy in power sources forms another protective layer. NetApp units are typically equipped with dual power supplies, enabling connection to two independent electrical circuits. However, redundancy is effective only when implemented correctly. If both power supplies connect to the same circuit, the redundancy becomes illusory. The storage infrastructure must draw power from distinct distribution pathways, ensuring that a fault in one line does not impact both supplies. This configuration aligns with the broader principle that infrastructure resilience emerges through diversification rather than duplication alone. Multipath power feeds, properly distributed PDUs, and clear documentation of circuit mapping prevent hidden vulnerabilities.
Grounding provides additional protection against electrical anomalies. A well-grounded environment safeguards hardware by channeling stray voltage, mitigating electrostatic build-up, and establishing a stable reference point for electrical signals. Incorrect or inconsistent grounding can provoke unpredictable electrical behavior, or in severe cases, physical hazard. Technicians must routinely verify grounding continuity across racks, floor systems, and hardware frames. Variations in grounding resistance can indicate corrosion or bonding deterioration. Correcting grounding disparities prevents subtle malfunctions and promotes operational safety.
Environmental and electrical requirements become even more intricately linked when scaling a storage environment. As organizations increase storage capacity, add additional controllers, or expand rack footprints, heat output escalates proportionally. Cooling requirements grow not just in volume but in airflow pattern complexity. Similarly, power draw increases, requiring both increased supply and enhanced redundancy. Scaling without environmental planning may lead to scenarios where cooling systems operate near their maximum thresholds, leaving little margin for unexpected heat load spikes. The better strategy is to engineer margin capacity into the environment. This ensures that growth does not destabilize equilibrium.
Monitoring plays a vital role in sustaining long-term environmental and power consistency. NetApp systems provide temperature, voltage, fan speed, and component health telemetry that can be integrated into monitoring platforms. This telemetry should be reviewed not solely for reactive alerting but for trend interpretation. Trends offer insight into environmental drift, cooling inefficiency, or power inconsistency long before functional failure manifests. A slow rise in system fan RPM levels across storage nodes, for example, may indicate cooling airflow reduction. A subtle upward shift in average power draw without a corresponding workload increase may suggest electrical inefficiency or internal degradation. Technicians must develop interpretive awareness rather than relying solely on threshold alarms.
Coordination between IT teams and facility management personnel influences long-term operational stability. Environmental conditions are rarely determined solely by the IT domain; they depend on building infrastructure, mechanical maintenance protocols, and power delivery planning. When these teams operate in disconnection, misalignments can occur. For example, facility teams might schedule cooling system maintenance without informing IT, creating a temporary thermal imbalance that affects storage hardware. Conversely, IT may expand equipment without alerting facilities, increasing heat loads that exceed current cooling capacity. Establishing consistent communication channels prevents environmental stress events caused by uncoordinated change.
Beyond centralized data centers, NetApp systems are often deployed in remote environments, small offices, manufacturing floors, or industrial-controlled spaces where environmental conditions lack refinement. Such environments may introduce dust, vibration, airborne particulates, fluctuating temperature conditions, or unpredictable electrical continuity. In these contexts, additional protective measures become necessary. Physical dust filters must be installed to prevent particulate accumulation within chassis interiors. Vibration dampening pads may be used to shield sensitive rotating storage media from mechanical shock. Supplemental air conditioning units or environmental enclosures may be required to maintain climate parameters when building systems are insufficient. These adaptations represent the practical awareness that not all environments provide ideal baseline conditions.
Transport and relocation of storage hardware introduce yet another dimension. Even short relocations within the same building can pose risks if equipment is not secured, cushioned, or handled correctly. Hard disks are particularly sensitive to mechanical impact, and even solid-state drives, while more resilient, can suffer connector strain or solder stress under shock. After relocation, visual inspection and re-seating of modules confirm that hardware remains structurally stable. Internal components must be checked for seating integrity to prevent unexpected faults once systems resume service.
Documentation supports the continuity and predictability of environmental and power stability. Rack layouts, airflow designs, cooling capacity calculations, circuit allocations, grounding points, and monitoring thresholds must be recorded in centralized and accessible formats. Without documentation, operational awareness degrades over time, especially as staffing changes occur. When documented knowledge erodes, systems become increasingly dependent on reactive troubleshooting rather than systematic stability planning. Thorough documentation strengthens organizational memory.
The enduring goal in sustaining environmental and power requirements for NetApp hardware deployment is to establish an operational environment where storage systems function at peak performance under all conditions. This pursuit is not merely about maintaining minimum acceptable standards but about cultivating consistency, stability, foresight, and responsive adaptation. The environment must continuously support the system, anticipating stress before it arises, adjusting airflow before heat concentrates, stabilizing electrical conditions before fluctuations disrupt circuitry, and preserving structural integrity before degradation threatens reliability.
Detailed Understanding of Hardware Health, Diagnostics, and Sustenance Approaches
Fostering a robust comprehension of hardware integrity within NetApp storage environments involves an immersive outlook toward the lifecycle of components, operational resilience, and methodical diagnostic behavior. The individual who aims to function adeptly within the role connected to NetApp Accredited Hardware Support Engineer responsibilities must cultivate deep familiarity with system architecture, maintenance methodologies, proactive risk mitigation, and rigorous failure response patterns. This realm is not simply about resolving issues when an anomaly strikes; it is about weaving a constant observatory presence over physical elements so anomalies are preempted rather than merely confronted.
The entirety of hardware operations begins with an appreciation for how system subsystems interlace to form a cohesive data infrastructure. Disk shelves, controllers, power distribution modules, input-output interfaces, and cabling arrays each play integral parts within operational continuity. A subtle disturbance in one domain may cascade across broader functionality if overlooked. Thus, routine inspection habits are not optional but rather the foundation of procedural discipline, where every cable seating, fan noise, measurable temperature variance, and LED pattern becomes a meaningful indicator. The capacity to interpret these subtle cues often separates novice oversight from expert guardianship.
Diagnosing hardware irregularities requires attention to auditory signatures, thermal changes, and latency deviations. When a disk begins to show early read instability or an onboard controller cache exhibits inconsistent behavior, the hardware support engineer must recognize these as embryonic warnings. In many instances, systems will continue operating, masking vulnerability beneath a veneer of temporary functionality. However, one who is attentive to patterns understands that stability is not defined only by the present performance but by the trajectory of component behavior. A proactive diagnosis ensures that replaceable components are substituted before degradation escalates into service disruption.
Monitoring frameworks inherently enhance this perception-driven approach. Environmental sensors report airflow quality, heat concentration, and energy consumption balance. Through interpretive analysis of these readings, maintenance strategies can be refined with surgical precision. Cold aisle and hot aisle arrangements within data centers must be harmonized to sustain adequate thermal regulation. Too little airflow may result in accelerated hardware fatigue, while excessive cooling can introduce condensation-related risks. The engineer’s role is to maintain equilibrium while understanding how mechanical and environmental dynamics interplay with operational longevity.
When addressing component replacement, it is essential to follow ergonomic and antistatic handling methods. Electrostatic discharge can instantaneously compromise a functioning module. Therefore, grounding practices, antistatic straps, and static-neutral work surfaces are indispensable. The objective is not only to remove a failing component but to ensure no inadvertent harm is introduced in the process. Each physical interaction becomes part of an intentional choreography designed to preserve the integrity of delicate circuitry.
Storage drive management is among the most recurrent aspects of hardware support. As storage drives endure continuous read-write cycles, they are naturally susceptible to wear. The engineer must evaluate drive performance thresholds, identify predictive signs of sector failure, and manage drive pool allocation. Raid architectures or distributed data parity may offer resilience, yet their strength is contingent on timely drive replacement and rebuild strategy oversight. A delayed rebuild may result in an unrecoverable fault if additional drives exhibit concurrent decline. Thus, prioritizing time-sensitive responses is paramount.
In many operational environments, firmware consistency becomes a stabilizing factor that governs predictability. Firmware updates should follow structured testing, avoiding indiscriminate application that could lead to device incompatibility or subsystem instability. The individual must analyze release notes, cross-reference compatibility matrices, and ensure alignment with system architecture prerequisites. The deliberate act of updating firmware is not merely a technical step but a strategic decision influencing overall system reliability.
Power cycling procedures are another domain requiring finesse. Abrupt shutdowns may generate filesystem inconsistency or lead to incomplete cache flushing. Controlled shutdown protocols ensure synchronization across subsystem components. Additionally, power redundancy strategies—such as dual power supplies and uninterrupted power sources—serve as shields against abrupt electrical turbulence. Engineers must verify power draw distribution and confirm that circuits are not inadvertently overloaded, as such imbalances may induce silent, incremental harm to power delivery units.
Hardware log interpretation acts as the narrative memory of the system. Logs relay alerts about temperature spikes, drive timeouts, controller retries, port negotiation anomalies, or memory parity errors. The ability to translate these messages into actionable insights forms the essence of diagnostic intelligence. Logs are not merely records; they are coded language that reveals evolving dynamics. Reading them fluidly demands familiarity, patience, and pattern recognition skill.
Furthermore, operational discipline encompasses the structuring of documentation practices. When maintenance actions are performed, recording specifics such as serial identifiers, timestamps, observed symptoms, part numbers, and procedural steps ensures traceable continuity. This documentation empowers future troubleshooting, simplifies audit trails, and contributes to organizational knowledge retention. A well-documented maintenance cycle enables engineers to evolve collective competency rather than rely solely on personal recollection.
Human communication also plays a subtle yet essential role. Hardware support involves interacting with data center personnel, remote administrators, logistics coordinators, and technical escalation teams. The clarity of communication affects the precision of hardware handling. For instance, remotely guided component swaps must be articulated unambiguously to prevent missteps. Thus, articulation becomes as critical as physical dexterity.
Environmental wellness extends from equipment to the broader data center macrocosm. Dust intrusion, ambient humidity misalignment, vibrations from nearby heavy machinery, and suboptimal rack configurations can cumulatively reduce hardware lifespan. Regular inspection of surrounding conditions contributes to safeguarding internal systems. A hardware support engineer becomes not only a caretaker of devices but an observer of their habitat.
Over time, as hardware ages, planning for lifecycle rotation becomes inevitable. Retirement and replacement scheduling should be governed by empirical performance data, not merely time duration. Components may age differently based on workload intensity, environmental stability, and historical maintenance patterns. Recognizing when hardware is nearing the threshold of diminishing returns and preparing successor components forms part of strategic foresight.
In certain situations, hardware anomalies may originate from manufacturing variances or rarely occurring electrical phenomena. The engineer must discern when a situation aligns with known failure patterns versus when it signals an atypical discrepancy requiring deeper diagnostic escalation. In such cases, collaboration with vendor support teams becomes vital. Effective communication helps convey diagnostic findings succinctly and accurately, enabling advanced support resources to intervene efficiently.
Operational resiliency relies on the synchronized interplay of prescriptive and reactive behaviors. Prescriptive actions revolve around routine checks, structured maintenance cycles, and proactive replacements. Reactive actions require rapid, precise decision-making when a hardware interruption occurs unexpectedly. The adept engineer balances both mindsets without hesitancy or disarray.
Sometimes, intricate failure patterns emerge where multiple symptoms converge. Seemingly unrelated alerts may share a deeper root cause, such as power supply voltage irregularity affecting multiple controllers simultaneously. Pattern correlation becomes essential in such scenarios. By examining timelines, error frequencies, and subsystem interactions, root cause pathways gradually come to light.
Testing equipment also enhances diagnostic prowess. Tools that measure voltage stability, cable continuity, or component thermal output enable tangible confirmation rather than inference. Combining sensory cues, log interpretation, and instrumented readings produces a comprehensive diagnostic picture that strengthens confidence in decisions.
It is also important to understand the psychological aspect of equipment familiarity. Over time, engineers develop intuitive recognition of what normal operation looks, sounds, and feels like. This instinct is cultivated through daily interaction and immersion rather than theoretical study alone. The soft hum of fans, the rhythm of LED indicators, and the tactile sensation of module fittings become sensory guides.
When performing hardware replacements, it is vital to ensure that storage redundancy remains intact. Ensuring that data protection states are healthy prior to removal avoids exposing data to heightened vulnerability. Synchronization awareness must always precede action. The engineer does not rush but moves deliberately with awareness of storage resiliency posture.
A key competency lies in minimizing disruption. The engineer’s objective is not simply to fix issues but to ensure continuity with minimal operational interference. Scheduling maintenance windows and coordinating with workload administrators prevents abrupt interruptions to business processes. Each hardware manipulation must be harmonized with system usage timelines.
Lastly, operational maturity increases when the engineer not only resolves current faults but identifies strategies to prevent their recurrence. Post-maintenance reflection allows for refining procedures, adjusting inspection frequency, updating environmental controls, or expanding monitoring coverage. Improvement evolves organically through analysis of historical outcomes.
Through persistent discipline, observational mastery, structured diagnostics, proactive replacement strategies, and environmental stewardship, the individual advancing through NetApp hardware support capacity develops not only technical skill but a cultivated craftsmanship. The result is resilience not only in systems but in professional approach—an evolving mastery that forms the undercurrent of dependable infrastructural support.
Comprehensive Insight into Recovery Dynamics, Incident Handling, and Sustainability Framework
Safeguarding data infrastructure reliability within NetApp storage landscapes requires an elevated understanding of restoration workflows, incident reaction protocols, and operational continuity principles. The role associated with NetApp Accredited Hardware Support Engineer responsibilities demands a nuanced perception of how hardware, firmware, storage architectures, and environmental controls interconnect to create cohesive functionality. Within this domain, the work extends beyond mechanical replacement tasks and moves toward an intricate orchestration of diagnostic analysis, service reactivation precision, and long-term system wellness. The professional contributes not only to immediate repairs but also to sustained durability that protects organizational workloads from disruption.
Within restoration dynamics, the primary focus involves systematically identifying the root cause of an outage, instability, or performance decline. It is paramount to distinguish between symptomatic noise and meaningful indicators. Some anomalies may present as intermittent latency or sporadic read inconsistencies, while others manifest as critical errors that bring operational processes to a halt. The individual must learn to recognize the behavioral subtleties that differentiate minor fluctuations from the early onset of component deterioration. This understanding emerges from immersive exposure to system logs, environmental telemetry, drive performance metrics, and observed physical attributes. Each signal acts as part of a narrative that requires interpretation, not merely observation.
During an incident, the immediate objective is containment. Containment ensures that the issue does not propagate across broader system elements or compromise data integrity. If a storage controller begins to malfunction, isolation strategies must be applied carefully to avoid undue pressure on surviving resources. If a drive shows signs of imminent failure, risk-aware data redistribution becomes vital to prevent cascading redundancy loss. The engineer applies knowledge of data resilience behaviors, storage layout topology, and hardware interdependencies to ensure that protective steps are executed without compromising continuity.
A vital cornerstone of incident handling lies in the ability to differentiate recoverable scenarios from those requiring component replacement. For example, a transient cache error may resolve through controlled power sequencing and memory refresh routines. However, a repeated parity mismatch within a storage controller module may signify deep hardware malfunction. Determining which response is appropriate requires refined pattern interpretation and familiarity with known failure signatures. Experience plays a profound role here, as repeated exposure cultivates intuitive recognition of fault typologies.
When a physical replacement becomes necessary, careful coordination is essential. The task is not merely mechanical but strategic. Before extraction of a component such as a drive, power supply, controller module, or shelf element, the engineer verifies system data protection health. If redundancy features are already degraded or rebuilding progress is in motion, extracting another component could induce catastrophic failure. Therefore, confirmation is not a trivial step but a foundational principle. It is performed through command outputs, monitoring interfaces, environmental dashboards, and logged status notifications.
Safe removal practices must accommodate antistatic precautions, controlled tool usage, and deliberate mechanical motions. Electrostatic discharge is an invisible hazard that can destroy sensitive circuit pathways instantly. Even minor mishandling can introduce latent failures that only manifest later, complicating subsequent diagnostics. Therefore, every handling step, from wrist grounding to surface contact selection, is executed with intentional caution.
The replacement process itself must be synchronized with system reinitialization behaviors. Some hardware components automatically rejoin the operational fabric upon detection, while others require manual configuration or post-replacement validation. Rebuild processes, whether for drive parity recalculation or controller cache reintegration, demand patient oversight. During this phase, system performance may be temporarily altered, and workloads may need throttling adjustments to avoid strain. The engineer monitors resource utilization patterns, rebuild speed, and error recurrence probability to ensure the environment remains stable.
After restoration has completed, validation becomes the next priority. Validation involves assessing that the environment matches expected performance baselines. This can include evaluating throughput, latency consistency, storage pool health, and thermal distribution. Logs are reviewed post-repair to confirm the absence of recurrent errors. Temperature and power consumption metrics are compared to historical patterns. Network port negotiation rates are verified to prevent performance throttling due to misaligned configuration.
Communication is a fundamental pillar throughout the restoration process. Even if the engineer is the primary executor of hardware support, coordination with broader operational teams ensures alignment. Workload administrators may need to reschedule high-intensity processes or reroute traffic temporarily. Data center technicians may assist with equipment access or rack modifications. External vendor escalation may be required in situations involving manufacturing deviations or unusual failure signatures. The clarity and precision of communication influence the efficiency and confidence of these interactions.
To sustain recovered environments, preventative strategies must be integrated. Preventative maintenance routines encompass drive wear evaluation, controller load distribution balancing, temperature zoning adjustments, firmware calibration checks, and cable integrity audits. These measures operate as ongoing guardians of operational vitality, reducing the frequency and severity of restoration events.
Environmental stability remains a foundational determinant of system longevity. Temperature fluctuations, airborne particulates, humidity imbalances, and structural vibrations all contribute to gradual hardware degradation. Engineers must evaluate airflow ducting efficiency, rack arrangement patterns, and placement proximity relative to heat-generating equipment. Periodic data center walkthroughs, environmental sensor trend analysis, and collaboration with facility management teams elevate the sustainability of these conditions.
An often-underestimated facet of operational continuity lies in cumulative knowledge retention. Every incident handled provides insight into hardware behavior patterns and improvement opportunities. Documenting failure patterns, restoration steps, component serial identifiers, context details, and after-effects serves to institutionalize knowledge. This documentation empowers future troubleshooting processes, reduces future restoration time, and strengthens organizational resilience. Without documentation, lessons remain isolated experiences rather than accelerated learning resources.
Lifecycle planning emerges from the understanding that hardware will eventually reach end-of-usefulness points. Proactively identifying imminent aging thresholds allows organizations to avoid failures rather than simply respond to them. Lifecycle strategies consider workload intensity, thermal exposure, historical repair frequency, and manufacturer lifecycle advisories. The engineer plays a central role in recommending when replacement is appropriate, ensuring continuity without unplanned downtime.
Testing tools supplement restorative actions by providing empirical metrics that validate system conditions. Voltage meters verify power stability. Thermal scanners evaluate localized hotspots. Diagnostic interface utilities measure data-path integrity. Rather than relying solely on assumptions, engineers incorporate instrument-based confirmation.
Over time, engineers develop instinctual familiarity that fine-tunes diagnostic intuition. Sensory perceptions such as the pitch of system fans, subtle vibration pulses, LED cadence rhythms, and tactile resistance during module insertion convey meaningful cues. This sense-based awareness emerges through constant presence and deliberate attentiveness. It complements analytical reasoning, forming a holistic mastery that strengthens confidence and accelerates intervention.
Operational continuity is not defined by merely restoring a system to functionality. It is defined by restoring the environment to a steady condition that supports future workloads without elevated risk. This means ensuring that every restoration is thorough, validated, and accompanied by preventative adjustments. The engineer’s goal is not only to bring the system back online but to ensure its next operational interval unfolds with improved stability.
Conclusion
The domain of restoration and operational continuity in NetApp hardware support environments requires a synthesis of analytical discernment, technical dexterity, preventative foresight, and disciplined system stewardship. The individual fulfilling this responsibility becomes both a guardian and an interpreter of infrastructure behavior. Through containment awareness, precise replacement strategies, environmental equilibrium management, and continuous documentation, the engineer ensures that data ecosystems remain protected and resilient. This evolving practice cultivates refined craftsmanship, enabling infrastructures to operate reliably and sustainably while aligning with the enduring demands of organizational stability and performance expectations.

