
Exam Code: 304-200
Exam Name: LPIC-3 Virtualization & High Availability
Certification Provider: LPI
Corresponding Certification: LPIC-3
Product Screenshots
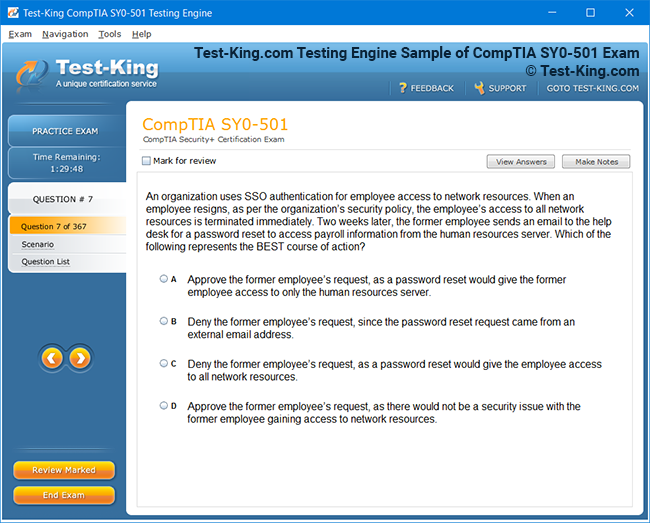
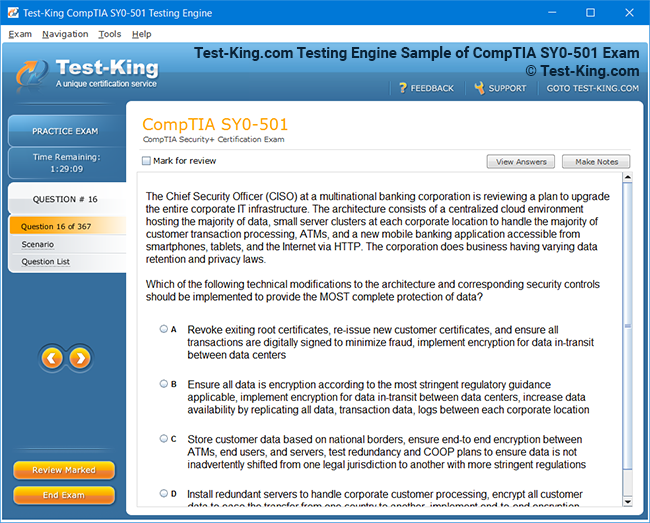
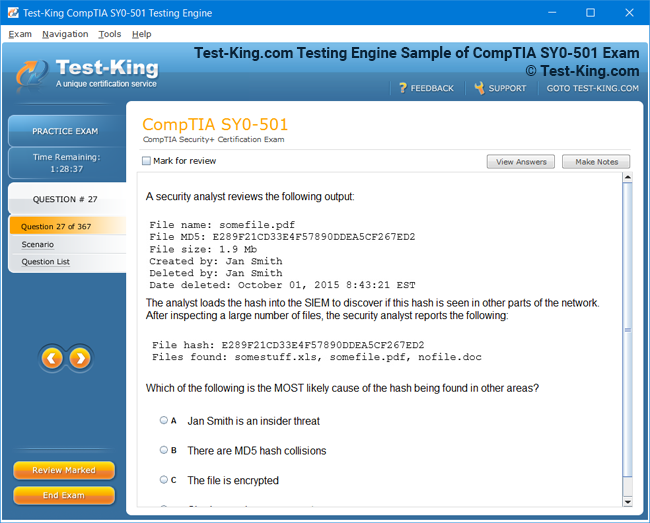
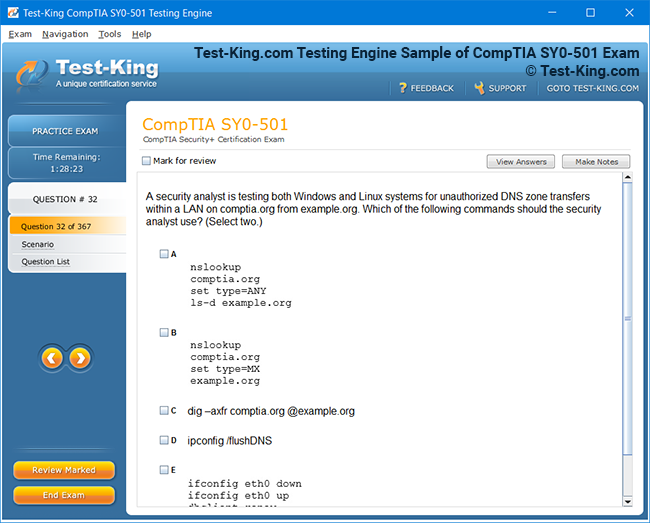
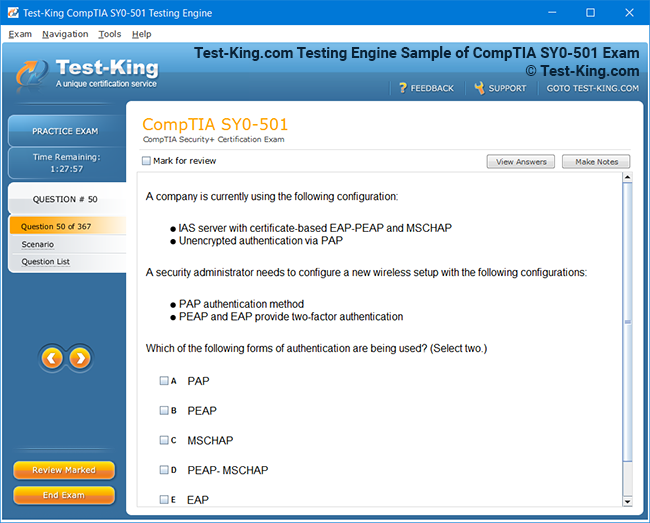
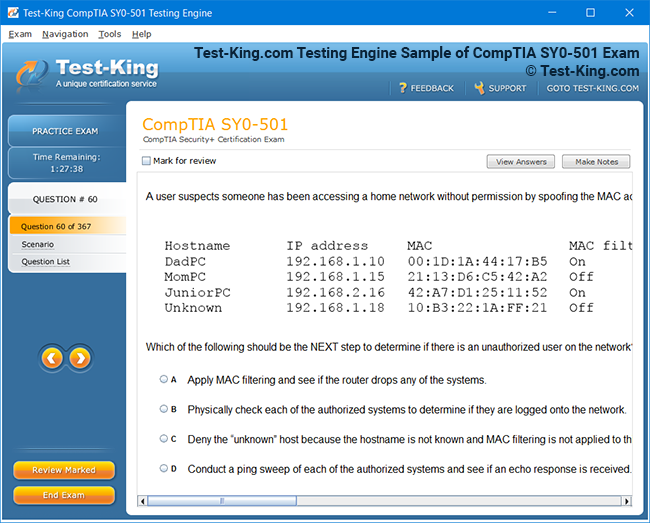
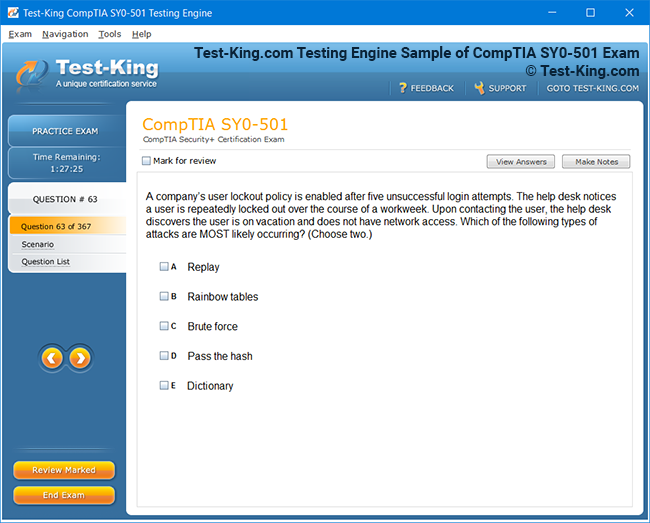
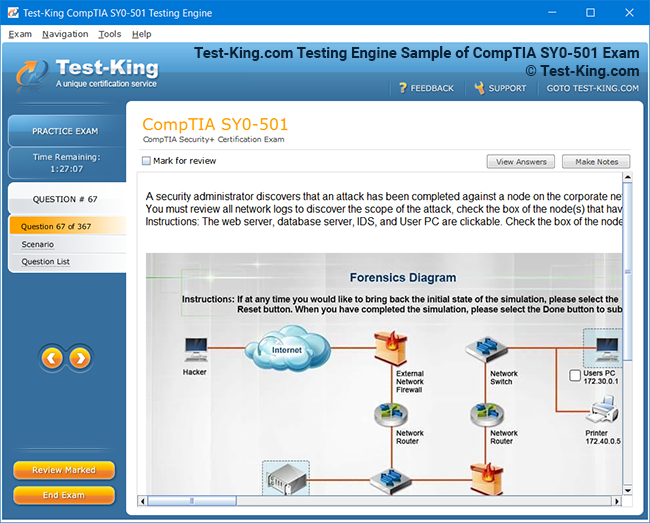
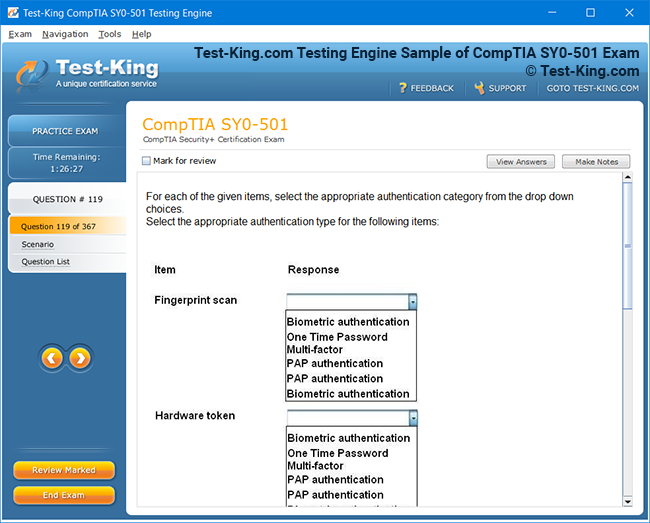
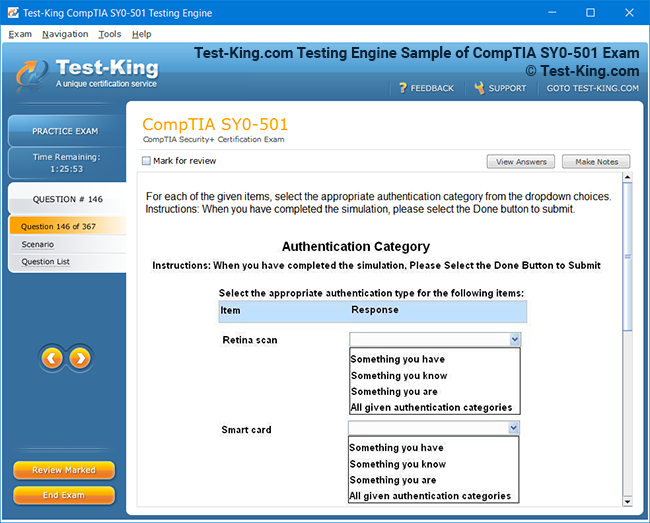
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Top LPI Exams
- 010-160 - Linux Essentials Certificate Exam, version 1.6
- 101-500 - LPIC-1 Exam 101
- 201-450 - LPIC-2 Exam 201
- 102-500 - LPI Level 1
- 202-450 - LPIC-2 Exam 202
- 305-300 - Linux Professional Institute LPIC-3 Virtualization and Containerization
- 300-300 - LPIC-3 Mixed Environments
- 304-200 - LPIC-3 Virtualization & High Availability
- 701-100 - LPIC-OT Exam 701: DevOps Tools Engineer
- 303-300 - LPIC-3 Security Exam 303
- 303-200 - Security
LPIC-3 304-200 Virtualization and High Availability: Understanding the Certification and Effective Preparation Strategies
LPIC-3 is the pinnacle of professional Linux certifications designed to validate enterprise-level skills and knowledge in managing complex Linux infrastructures. Unlike other Linux certifications that might focus on distribution-specific knowledge, this credential emphasizes a distribution-neutral approach, ensuring that the candidate demonstrates mastery over concepts and practical applications across various Linux environments. Achieving LPIC-3 is a significant milestone for system administrators who aspire to manage extensive enterprise networks, implement high availability solutions, and maintain robust virtualization infrastructures. The certification specifically addresses two vital domains within enterprise Linux administration: virtualization and high availability, which are indispensable for contemporary IT ecosystems.
The path to this credential is rigorous and requires not only theoretical understanding but also practical competence. Candidates must already hold an active LPIC-2 certification, which serves as a foundation for the more advanced concepts explored in LPIC-3. However, it is notable that the exams for LPIC-2 and LPIC-3 may be undertaken in any order, allowing candidates some flexibility in planning their professional development. Achieving LPIC-3 signifies the ability to administer Linux across an enterprise-wide infrastructure, ensuring both efficiency and reliability through virtualization strategies and high availability clustering mechanisms.
The Importance of Enterprise-Level Linux Expertise
Enterprise environments demand a level of sophistication that goes beyond basic Linux administration. Organizations today rely heavily on continuous service availability, resource optimization, and resilient infrastructure to sustain their operations. Virtualization allows multiple operating systems and applications to coexist on the same physical hardware, reducing costs and improving efficiency while facilitating scalability. Meanwhile, high availability clustering ensures that critical services remain operational despite hardware failures, software faults, or unexpected outages.
Candidates preparing for LPIC-3 must develop a mindset attuned to designing and maintaining environments that are both scalable and resilient. This includes understanding the nuances of distributed systems, storage replication techniques, network redundancy, and the orchestration of virtual machines. A deep comprehension of these topics enables administrators to foresee potential points of failure and implement strategies to mitigate downtime, thereby contributing to an organization’s operational continuity and reliability.
Exam Objectives and Preparation Resources
The LPIC-3 304 exam encompasses a diverse set of objectives that guide the preparation process. These objectives are meticulously structured to cover both conceptual knowledge and practical skills in virtualization and high availability. Among the primary focus areas are virtualization concepts, the deployment and management of Xen and KVM hypervisors, the configuration of other virtualization solutions such as VirtualBox, and the management of cloud environments using tools like OpenStack. Additionally, the examination emphasizes the administration of high availability clusters, including load balancing techniques, failover clustering, and storage solutions such as DRBD, clustered logical volumes, and distributed file systems.
To effectively prepare for the exam, candidates should engage with a variety of study resources. Classical texts such as Pro Linux High Availability Clustering provide a comprehensive exploration of clustering techniques, while Teach Yourself Linux Virtualization and High Availability offers practical guidance tailored to exam readiness. Supplementing textual resources with video instruction, such as Sander van Vugt’s complete high availability clustering course, enhances understanding by demonstrating real-world application of concepts. These resources, when combined with hands-on experimentation in a home lab environment, allow candidates to internalize both theoretical knowledge and practical skills. A home lab setup is invaluable, enabling the deployment of virtual machines, configuration of clusters, and simulation of failover scenarios, thereby consolidating the learning experience.
Effective Study Techniques
Preparing for LPIC-3 demands a blend of structured study, practical exercises, and critical reflection. Candidates benefit from an incremental approach, beginning with conceptual mastery before transitioning to applied exercises. For virtualization, this entails comprehending the theoretical underpinnings of hypervisors, the differences between type 1 and type 2 virtualization, and the mechanics of live migration. Following this, practical exercises such as configuring Xen or KVM, setting up network bridges, and managing virtual instances solidify the knowledge gained from study materials. Similarly, for high availability, understanding the principles of clustering, quorum management, and resource allocation is crucial. Hands-on experimentation with Pacemaker, Corosync, and DRBD, as well as setting up load-balancing clusters using LVS or HAProxy, allows candidates to witness how theory translates into operational stability.
A methodical approach involves dividing study sessions into thematic segments, allowing for concentrated focus on each topic while revisiting complex areas periodically to reinforce retention. Supplementary techniques, such as note-taking, diagrammatic visualization of cluster topologies, and the simulation of failure scenarios, provide an experiential layer to the preparation. Additionally, reviewing external documentation, such as OpenStack manuals and hypervisor guides, exposes candidates to a broader range of deployment strategies, enhancing adaptability and problem-solving skills.
Understanding Virtualization Concepts
Virtualization forms the backbone of modern enterprise Linux environments. At its core, virtualization allows multiple operating systems to run concurrently on a single physical host, providing flexibility and resource optimization. Candidates preparing for LPIC-3 must grasp the theoretical foundations, including abstraction layers, hypervisor types, and the management of virtual instances. Xen, for instance, operates as a type 1 hypervisor, providing direct control over hardware while supporting live migration of virtual machines. Understanding the nuances of Dom0 and DomU roles, as well as the integration of storage replication using DRBD, is essential for designing resilient virtualized infrastructures.
KVM, another focal point of the exam, leverages Linux’s kernel capabilities to enable virtualization, requiring administrators to manage virtual bridges, guest networking, and performance tuning. Other virtualization solutions, including VirtualBox, provide accessible alternatives for experimental labs or environments with limited resources. Cloud management tools such as OpenStack further extend the virtualization paradigm, allowing orchestration of compute, storage, and networking resources across large-scale deployments. Candidates must become adept at deploying, configuring, and managing these platforms, recognizing their role in creating agile and resilient enterprise systems.
High Availability Clustering Fundamentals
High availability clustering ensures that critical services remain accessible even in the event of hardware or software failures. Understanding the principles underlying clustering is pivotal for LPIC-3 aspirants. Clusters may be designed for load balancing, failover, or both, depending on the operational requirements. Load-balanced clusters distribute client requests across multiple nodes to optimize resource utilization and maintain performance, while failover clusters provide redundancy, automatically transferring workloads to standby nodes in the event of a failure.
The administration of high availability clusters involves configuring nodes, defining resources, managing dependencies, and implementing fencing mechanisms to prevent split-brain scenarios. Pacemaker and Corosync are central components in modern clustering, orchestrating resource allocation, monitoring node health, and ensuring continuity of service. DRBD enables block-level replication between nodes, forming the basis for active/passive configurations, while clustered logical volumes and distributed file systems support active/active topologies, ensuring data integrity and consistency across the cluster. Mastery of these technologies enables administrators to build resilient environments capable of sustaining enterprise operations under adverse conditions.
Load Balancing and Failover Techniques
Load balancing and failover strategies form an integral part of enterprise Linux administration. In a load-balanced environment, services such as web servers or database instances are distributed across multiple nodes to prevent bottlenecks, reduce latency, and maximize throughput. Techniques such as NAT-based or direct-routing configurations using LVS, combined with HAProxy for application-layer balancing, ensure that client requests are efficiently managed. Heartbeat and Ldirectord provide additional mechanisms for monitoring node health and dynamically adjusting service distribution.
Failover clusters complement load balancing by providing redundancy and resilience. In an active/passive configuration, standby nodes remain ready to assume service responsibilities upon detection of failure in primary nodes. Effective failover management requires meticulous configuration of cluster resources, replication protocols, and fencing strategies. For instance, configuring DRBD for synchronous replication ensures that data remains consistent between primary and secondary nodes, while STONITH fencing prevents scenarios where two nodes attempt to control shared resources simultaneously, which could compromise integrity. Candidates must develop both theoretical understanding and practical experience in these mechanisms to ensure readiness for the exam.
Storage Considerations for High Availability
Storage architecture plays a critical role in high availability clusters. Active/passive clusters often utilize DRBD or clustered logical volumes to replicate data, ensuring that secondary nodes can immediately assume responsibility without data loss. Active/active clusters, on the other hand, employ distributed file systems such as GFS2 or OCFS2 to allow concurrent access from multiple nodes. These configurations require careful attention to quorum management, conflict resolution, and performance optimization.
Candidates must understand the interplay between storage replication, resource allocation, and failover procedures. Designing a high availability cluster involves balancing redundancy with performance, ensuring that replicated storage does not become a bottleneck while maintaining data integrity. Integrating iSCSI or other networked storage protocols further complicates the configuration, necessitating familiarity with both the underlying storage technologies and the cluster orchestration tools. This comprehensive understanding enables administrators to construct resilient storage infrastructures capable of supporting enterprise workloads reliably.
Hands-On Practice and Home Lab Setup
A theoretical grasp of virtualization and high availability concepts is insufficient without practical application. Setting up a home lab provides a controlled environment to deploy, configure, and test virtualized systems and high availability clusters. Candidates should create multiple virtual machines, configure network bridges, simulate node failures, and test load-balancing and failover strategies. Experimenting with different hypervisors, replication protocols, and cluster configurations reinforces understanding and builds confidence in real-world scenarios.
The home lab also allows candidates to explore advanced topics, such as cloud orchestration with OpenStack, live migration of virtual machines, and integration of clustered storage with failover clusters. Regular experimentation, troubleshooting, and performance tuning within the lab environment cultivate both problem-solving abilities and practical proficiency, ensuring that candidates are well-prepared for the rigors of enterprise Linux administration and the demands of the LPIC-3 304 exam.
Strategic Approach to Exam Readiness
Exam preparation extends beyond studying concepts and practicing lab exercises. A strategic approach involves understanding the weighting of various topics, prioritizing areas where the candidate has limited experience, and systematically revisiting complex topics to reinforce retention. Creating study schedules, tracking progress, and setting achievable milestones ensures consistent advancement toward readiness.
Candidates benefit from integrating multiple study methods, including reading authoritative texts, watching instructional videos, participating in online forums, and performing hands-on exercises. Simulating exam conditions, practicing time management, and self-assessing performance are crucial for building confidence and identifying areas that require further review. Emphasizing both comprehension and application ensures that candidates develop a holistic understanding of virtualization, high availability, and enterprise Linux administration, which is essential for achieving LPIC-3 certification.
Understanding Virtualization in Linux Systems
Virtualization represents one of the most transformative paradigms in modern enterprise computing, allowing multiple operating systems and applications to operate concurrently on a single physical host. In Linux environments, virtualization extends beyond mere resource sharing; it creates isolated environments where applications can run securely, reliably, and independently. This abstraction allows administrators to maximize hardware utilization while maintaining operational flexibility, which is essential in data centers and enterprise-grade infrastructures.
At its core, virtualization relies on the deployment of hypervisors, which can be categorized into type 1 and type 2. Type 1 hypervisors operate directly on the host hardware and are often referred to as bare-metal solutions, offering minimal latency and high efficiency. They provide a robust foundation for enterprise workloads, enabling administrators to allocate computing resources dynamically, manage multiple virtual machines, and maintain high performance under varying load conditions. Type 2 hypervisors, on the other hand, operate on top of an existing operating system, offering flexibility and ease of use for development, testing, or smaller-scale deployments. Both types have distinct advantages and are selected based on specific organizational requirements, performance considerations, and administrative convenience.
Understanding the fundamental concepts of virtualization includes grasping the notions of virtual CPU allocation, memory management, storage abstraction, and network isolation. These concepts form the basis for advanced configurations such as live migration, high availability of virtual instances, and integration with clustered storage. Administrators must appreciate the interplay between virtual machines, physical resources, and hypervisor management tools to design efficient and resilient infrastructures.
Xen Hypervisor and Advanced Implementation
Xen is a prominent type 1 hypervisor widely deployed in enterprise Linux environments. Its architecture relies on a privileged domain, known as Dom0, which has direct access to physical hardware, and unprivileged domains, DomU, which operate isolated virtual machines. This separation ensures both security and stability while allowing administrators to manage virtual resources effectively. One of the most compelling features of Xen is its support for live migration, which enables virtual machines to be transferred between physical hosts without disrupting ongoing services.
Implementing Xen in a Linux environment requires a thorough understanding of domain management, storage configuration, and networking. Integrating DRBD for block-level replication ensures that live migration occurs without data loss, providing continuity for mission-critical applications. Administrators must configure Dom0 to manage hardware resources efficiently, create virtual interfaces for DomU, and monitor performance metrics to maintain optimal system operation. In addition, networking considerations such as bridging and firewall configurations are essential to ensure secure and seamless connectivity for virtual instances.
Advanced deployment scenarios involve clustering Xen hosts to provide both scalability and redundancy. By combining multiple physical hosts under a unified management layer, enterprises can distribute workloads, balance resource utilization, and recover rapidly from hardware failures. Administrators must be adept at troubleshooting inter-domain communication, resolving storage synchronization issues, and configuring failover strategies to guarantee uninterrupted service availability.
KVM Virtualization and Enterprise Deployment
KVM, or Kernel-based Virtual Machine, leverages Linux kernel capabilities to enable full virtualization. Unlike Xen, which relies on a separate hypervisor layer, KVM integrates directly with the Linux kernel, transforming it into a hypervisor capable of managing multiple isolated virtual machines. This approach simplifies the management of virtual instances and takes advantage of existing kernel functionalities, such as memory management, process scheduling, and I/O handling.
Deploying KVM requires administrators to configure virtual bridges for networking, manage virtual disk images, and optimize CPU and memory allocation to ensure balanced performance. The creation of guest networks involves setting up public bridges, virtual switches, and firewall rules to maintain secure and efficient communication between virtual machines and the external network. KVM also supports advanced features such as live migration, snapshots, and resource overcommitment, allowing enterprises to optimize resource utilization without compromising stability.
A critical aspect of KVM implementation is monitoring and performance tuning. Administrators must regularly evaluate virtual CPU usage, memory consumption, and disk I/O patterns to prevent bottlenecks and ensure smooth operation under variable workloads. Integrating KVM with storage replication technologies and high availability clusters further enhances the resilience of the virtualized environment. Understanding the nuances of KVM in comparison to other hypervisors allows administrators to select the most suitable solution based on performance, scalability, and operational requirements.
VirtualBox and Alternative Virtualization Solutions
In addition to Xen and KVM, alternative virtualization solutions like VirtualBox offer versatile options for testing, development, and smaller-scale deployments. VirtualBox operates as a type 2 hypervisor, running atop an existing operating system, which simplifies installation and configuration. While it may not match the performance of bare-metal hypervisors in enterprise contexts, VirtualBox provides a practical platform for experimentation, training, and proof-of-concept deployments.
Setting up VirtualBox in a headless server environment allows administrators to manage virtual machines remotely without the overhead of graphical interfaces. Configuring networking, shared storage, and automated snapshots ensures that virtual instances remain manageable and reproducible. These configurations are particularly useful for educational purposes, lab exercises, or scenarios where resource efficiency and flexibility are more critical than raw performance.
Alternative solutions also include lightweight hypervisors and container-based virtualization, which emphasize rapid deployment, portability, and microservices orchestration. While containers differ fundamentally from traditional virtual machines, they complement virtualization strategies by allowing applications to run in isolated environments without the overhead of a full guest operating system. Integrating containerized workloads with traditional virtual machines and clustered infrastructure provides a hybrid approach that maximizes resource efficiency and operational flexibility.
Cloud Management and Orchestration
Modern enterprise Linux environments increasingly rely on cloud management platforms to orchestrate virtualized resources across large-scale deployments. OpenStack exemplifies such a platform, providing comprehensive capabilities for compute, storage, and networking management. Administrators using OpenStack can deploy virtual machines, allocate storage volumes, and configure network topologies from a centralized interface, streamlining operations across geographically distributed data centers.
Understanding cloud orchestration involves grasping the concepts of resource scheduling, automated provisioning, and policy-based management. Administrators must configure compute nodes, storage backends, and network controllers to ensure that virtual machines can be instantiated, migrated, and managed dynamically. Integrating cloud orchestration with existing virtualization infrastructures enhances scalability, simplifies administrative tasks, and allows for rapid adaptation to changing workloads. Moreover, cloud platforms provide APIs and automation tools, enabling administrators to script repetitive tasks, implement monitoring and alerting systems, and ensure compliance with operational policies.
Practical Considerations and Hands-On Implementation
Theoretical knowledge of virtualization concepts must be complemented by hands-on implementation. Administrators should experiment with configuring multiple hypervisors, deploying virtual machines, and setting up network bridges and storage replication. Testing live migration, failover mechanisms, and resource allocation strategies in a controlled environment helps build confidence and operational proficiency. Home lab setups offer the flexibility to simulate enterprise scenarios, including multi-node clusters, high availability configurations, and cloud orchestration tasks.
In practice, managing virtualized environments requires attention to performance, security, and fault tolerance. Administrators must monitor CPU, memory, and I/O utilization, optimize storage access, and implement network segmentation to prevent congestion and maintain security boundaries. Backup and recovery strategies are integral, ensuring that virtual machines can be restored swiftly in the event of hardware failure, software corruption, or misconfiguration. Through continuous experimentation and iterative refinement, administrators gain the skills necessary to design resilient, efficient, and scalable virtualized infrastructures suitable for enterprise deployment.
Advanced Topics in Virtualization
Beyond basic deployment and management, advanced virtualization topics encompass automation, high availability, and hybrid architectures. Automating the provisioning and configuration of virtual machines reduces operational overhead and minimizes human error. Administrators can leverage scripting and orchestration tools to define templates, manage resource allocation, and enforce compliance policies consistently across multiple hosts.
High availability in virtualized environments often requires combining hypervisors with clustering technologies, storage replication, and network redundancy. Configuring failover for virtual machines, synchronizing storage, and monitoring system health are crucial tasks that ensure continuous service availability. Hybrid architectures, which blend traditional virtual machines with containerized workloads and cloud orchestration platforms, provide additional flexibility, enabling enterprises to optimize resource utilization while maintaining operational resilience.
Monitoring and analytics play a central role in advanced virtualization. Tools that collect performance metrics, detect anomalies, and provide predictive insights allow administrators to preemptively address potential bottlenecks or failures. Understanding these tools and integrating them into operational workflows enhances decision-making, facilitates capacity planning, and improves overall system reliability.
Exam-Oriented Strategies for Virtualization Topics
Candidates preparing for certification must approach virtualization topics with both breadth and depth. Focusing on the core principles of hypervisor operation, guest management, and network configuration provides a foundation, while in-depth practice with live migration, storage replication, and cloud orchestration ensures readiness for practical scenarios. Engaging with a combination of textual resources, video instruction, and lab experimentation fosters a comprehensive understanding of virtualization in enterprise Linux environments.
Prioritizing areas that are weighted more heavily in the examination allows candidates to allocate time efficiently. For example, mastering Xen and KVM deployment, understanding advanced networking configurations, and configuring cloud management tools prepares candidates for the most challenging elements of the test. Simultaneously, revisiting less complex virtualization solutions, such as VirtualBox, ensures that all potential scenarios are familiar and manageable. A disciplined and methodical approach to studying, combined with rigorous hands-on practice, positions candidates for success while cultivating expertise applicable to real-world enterprise deployments.
Troubleshooting and Optimization
Effective virtualization management extends beyond deployment to ongoing monitoring, troubleshooting, and optimization. Administrators must identify and resolve performance bottlenecks, misconfigurations, and resource contention. Understanding log analysis, diagnostic tools, and system metrics is essential for detecting issues before they impact service availability.
Optimization strategies involve balancing CPU and memory allocation, fine-tuning storage performance, and configuring network throughput to match workload requirements. Virtualization environments are dynamic, with fluctuating demands that necessitate continuous monitoring and adjustment. Administrators who cultivate an anticipatory approach to resource management, performance analysis, and issue resolution enhance system efficiency and reduce the risk of downtime.
Understanding High Availability in Linux Environments
High availability represents a cornerstone of enterprise Linux administration, ensuring that critical services remain operational even in the presence of hardware failures, software anomalies, or unexpected disruptions. In contemporary computing environments, organizations cannot afford prolonged downtime, as operational continuity directly impacts productivity, revenue, and reputation. High availability clustering addresses these challenges by providing redundancy, fault tolerance, and automated failover capabilities that allow systems to maintain service despite adverse conditions.
At its essence, high availability relies on the orchestration of multiple nodes within a cluster, where workloads are distributed or replicated to prevent service interruption. Nodes are connected through network interfaces and often share storage resources, enabling synchronized data access and resource management. Administrators must understand the theoretical foundations of high availability, including quorum management, heartbeat signaling, and failover mechanisms. Quorum ensures that decisions regarding resource allocation are made reliably, preventing split-brain scenarios where two nodes simultaneously attempt to control the same resources. Heartbeat signals continuously monitor node health, and automated failover mechanisms transfer services from failing nodes to operational nodes without human intervention, minimizing service downtime.
Load-Balancing Clusters and Their Implementation
Load-balancing clusters are designed to distribute workloads across multiple nodes to optimize resource utilization, enhance system responsiveness, and ensure uninterrupted service. In Linux environments, several techniques and tools facilitate load balancing. Network Address Translation (NAT) based clusters allow multiple backend servers to appear as a single endpoint to clients, redirecting traffic efficiently according to preconfigured rules. Direct-routing clusters offer higher performance by sending requests directly to backend nodes without the need for address translation, reducing latency and processing overhead.
Application-layer load balancing is achieved through tools such as HAProxy, which intelligently distributes client requests based on server load, session persistence, or routing algorithms. Keepalived complements HAProxy by providing health checks, virtual IP failover, and dynamic reconfiguration of load-balancing rules in response to node failures. The combination of these tools allows administrators to create resilient, scalable, and responsive clusters capable of handling fluctuating workloads and maintaining service availability.
Implementing load-balancing clusters requires a meticulous understanding of network topologies, server capacities, and traffic patterns. Administrators must configure monitoring systems to detect node health, define load-balancing rules that prevent overloading specific nodes, and plan for redundancy in case of simultaneous failures. By combining various load-balancing strategies, such as NAT, direct routing, and application-level distribution, enterprises can achieve both efficiency and fault tolerance, ensuring that critical services remain consistently available to end-users.
Failover Clusters and Redundancy Strategies
Failover clusters complement load-balancing solutions by providing redundancy for critical resources and ensuring continuity of service in the event of node or application failures. These clusters often employ an active/passive configuration, where primary nodes handle workloads while standby nodes remain ready to assume responsibility in case of failure. Administrators configure cluster resources, monitor node health, and define failover policies to automate the transfer of services seamlessly.
Technologies such as Pacemaker and Corosync form the foundation of modern failover clusters. Pacemaker manages resource allocation, dependency relationships, and failover procedures, while Corosync provides reliable messaging, quorum management, and cluster membership monitoring. Block-level replication using DRBD ensures that data on primary nodes is mirrored to secondary nodes, allowing the standby nodes to take over without data loss. Fencing mechanisms, such as STONITH, prevent scenarios where two nodes attempt to control shared resources simultaneously, which could compromise data integrity and cluster stability.
Administrators implementing failover clusters must consider storage synchronization, network redundancy, and resource dependencies carefully. Active/passive configurations require meticulous planning to ensure that failover occurs smoothly, while active/active configurations demand even more attention to concurrent access, conflict resolution, and performance optimization. By mastering these principles, Linux professionals can design clusters capable of sustaining enterprise operations under adverse conditions, minimizing downtime and ensuring high service reliability.
Monitoring and Maintaining Cluster Health
Monitoring the health of high availability clusters is a critical administrative responsibility. Continuous observation allows administrators to detect anomalies, performance degradation, or potential failures before they impact services. Cluster monitoring involves evaluating metrics such as CPU utilization, memory consumption, network throughput, disk I/O performance, and response times for critical applications.
In addition to traditional monitoring, administrators must implement alerting systems that provide real-time notifications when nodes or resources experience issues. These alerts enable proactive intervention, allowing corrective actions to be taken before service disruption occurs. Monitoring tools may also provide historical data, trend analysis, and predictive insights, helping administrators identify recurring patterns, anticipate resource bottlenecks, and plan for capacity expansion. Effective monitoring and maintenance practices ensure that clusters remain resilient, responsive, and aligned with operational requirements.
High Availability in Enterprise Linux Distributions
Enterprise Linux distributions offer native high availability solutions that simplify cluster deployment and management. Red Hat Enterprise Linux provides a High Availability Add-On that integrates Pacemaker, Corosync, and resource agents, streamlining the configuration of failover clusters, load-balancing nodes, and storage replication. SUSE Linux Enterprise delivers a High Availability Extension that offers similar functionality, including automated fencing, resource monitoring, and cluster configuration tools.
Understanding the specific features, limitations, and best practices for each distribution is crucial for administrators. While core clustering principles remain consistent across environments, distribution-specific tools, command-line utilities, and resource agents may vary, requiring familiarity with the underlying implementation details. Enterprise Linux distributions often include preconfigured templates, documentation, and automation scripts that expedite cluster deployment, allowing administrators to focus on design, optimization, and operational maintenance rather than low-level configuration.
Storage Considerations for High Availability
Storage plays an essential role in high availability clusters, serving as the backbone for data replication, resource allocation, and fault tolerance. Active/passive clusters typically employ block-level replication technologies such as DRBD, which synchronize data between primary and standby nodes. This ensures that critical applications, databases, and file systems remain consistent and recoverable during failover events.
Active/active clusters, designed for concurrent data access, rely on distributed or clustered file systems such as GFS2 or OCFS2. These file systems coordinate simultaneous writes from multiple nodes while maintaining data integrity and preventing conflicts. Administrators must consider network latency, storage performance, and replication overhead when designing clustered storage solutions, as these factors influence overall cluster efficiency and responsiveness. Integrating storage solutions with virtualization, load balancing, and failover mechanisms creates a cohesive environment where data availability and system reliability are reinforced.
Hands-On Implementation and Practical Exercises
Practical experience is indispensable for mastering high availability and load-balancing concepts. Administrators should set up multiple nodes, configure cluster communication channels, and define resources for failover and load distribution. Simulating node failures, testing failover procedures, and validating data replication reinforce theoretical knowledge while building operational confidence.
Creating a controlled environment for experimentation allows administrators to explore advanced configurations, such as hybrid clusters combining load balancing with failover redundancy, integrating storage replication, and implementing fencing mechanisms. Testing different scenarios, observing system behavior, and refining configurations help develop a nuanced understanding of cluster dynamics and potential pitfalls. Hands-on practice not only prepares candidates for certification exams but also equips them with the expertise needed to manage real-world enterprise Linux infrastructures effectively.
Troubleshooting High Availability Clusters
Troubleshooting is an integral component of cluster administration. Administrators must identify the root causes of failures, misconfigurations, or performance issues and implement corrective actions promptly. Effective troubleshooting involves analyzing logs, interpreting error messages, monitoring network and storage activity, and verifying resource configurations.
Cluster-specific challenges include split-brain situations, replication delays, resource contention, and fencing failures. Administrators must understand the interdependencies between nodes, services, and storage to isolate and resolve issues efficiently. Developing troubleshooting skills requires repeated exposure to different failure scenarios, systematic testing, and a methodical approach to diagnosing problems. By cultivating this expertise, Linux professionals ensure that clusters remain robust, resilient, and capable of maintaining high availability under diverse conditions.
Advanced Load-Balancing Techniques
Beyond fundamental load-balancing configurations, advanced techniques enhance efficiency and resilience. Administrators may implement weighted load balancing, session persistence, and dynamic adjustment of routing rules to optimize resource utilization. Traffic monitoring and analysis allow for fine-tuning distribution policies, ensuring that high-demand nodes are not overwhelmed while underutilized nodes contribute effectively to overall performance.
Combining load balancing with failover mechanisms provides an additional layer of reliability. If a node within a load-balanced cluster fails, traffic is automatically redirected to healthy nodes, preventing service interruptions. Administrators must coordinate these mechanisms with cluster monitoring, resource management, and storage replication to create a seamless and resilient enterprise environment.
Strategic Approaches to Cluster Design
Designing high availability and load-balancing clusters requires strategic planning, taking into account workload characteristics, performance requirements, and fault tolerance objectives. Administrators must consider node capacities, network topologies, storage configurations, and operational policies to ensure that clusters can handle peak loads, recover from failures, and maintain service continuity.
Effective strategies include segregating workloads by function, replicating critical services across multiple nodes, implementing automated failover policies, and continuously monitoring system health. Strategic design also involves scalability considerations, allowing clusters to expand as enterprise demands increase without compromising stability or performance. By approaching cluster architecture with foresight and methodical planning, administrators can achieve resilient infrastructures that support enterprise operations reliably.
Understanding Failover Clusters and Their Role
Failover clusters are fundamental to enterprise Linux environments, providing redundancy, resilience, and continuity of service in the presence of system failures. Unlike load-balancing clusters, which distribute workloads across multiple nodes, failover clusters focus on ensuring that critical services remain available when individual nodes experience hardware malfunctions, software errors, or network interruptions. These clusters are typically designed in an active/passive configuration, where primary nodes handle operational workloads while standby nodes remain idle but fully synchronized, ready to assume responsibility instantaneously in the event of failure.
At the core of failover clustering lies the ability to monitor node health, detect failures, and execute automated failover processes. Administrators must comprehend the intricate orchestration of resources, quorum management, and heartbeat signaling to maintain cluster integrity. Quorum mechanisms prevent split-brain scenarios, where two nodes simultaneously attempt to control shared resources, potentially corrupting data. Heartbeat protocols continuously exchange status messages between nodes, enabling timely detection of failures and triggering failover procedures that maintain uninterrupted service.
Technologies Underpinning Failover Clusters
Modern enterprise Linux failover clusters utilize a combination of technologies to ensure high availability. Pacemaker serves as the resource manager, overseeing the allocation of services, managing dependencies, and coordinating failover operations. Corosync provides the cluster communication layer, maintaining cluster membership, delivering reliable messaging, and supporting quorum calculations. Block-level replication tools, such as DRBD, synchronize data between active and passive nodes, ensuring that the standby node possesses an exact copy of the primary node’s data at all times.
Effective failover configuration also requires the implementation of fencing mechanisms, such as STONITH, to prevent scenarios where a failed or unreachable node continues to control shared resources. Fencing isolates malfunctioning nodes, protecting data integrity and preserving cluster stability. Administrators must carefully configure these mechanisms, taking into account network reliability, storage synchronization, and resource dependencies. Understanding the interplay between these components is essential for building robust clusters that can sustain enterprise operations without disruption.
Active/Passive Cluster Deployment
Deploying active/passive clusters involves a sequence of deliberate actions that ensure seamless failover capabilities. Initially, primary nodes are configured to host the services and resources critical to enterprise operations, while secondary nodes are prepared with identical configurations and synchronized data. DRBD replication ensures that the standby node mirrors the primary node’s storage in real time, allowing immediate takeover when necessary. Administrators must validate that the replication process maintains data consistency and that failover occurs without service interruption.
Resource allocation within the cluster must be meticulously defined, including dependencies between services, start-up priorities, and recovery policies. Pacemaker orchestrates these resources, monitoring their status, and executing predefined actions in the event of failure. Corosync maintains communication between nodes, providing heartbeat messages, detecting node unavailability, and facilitating quorum decisions. STONITH fencing ensures that compromised nodes are isolated, preventing data corruption and maintaining operational stability. Active/passive clusters are particularly effective for applications requiring strict consistency and minimal downtime, such as database services, critical enterprise applications, and transactional systems.
Active/Active Cluster Deployment and Considerations
Active/active clusters differ from active/passive configurations by allowing multiple nodes to handle workloads simultaneously. This approach provides higher performance, improved resource utilization, and enhanced fault tolerance, but it introduces additional complexity. Administrators must manage concurrent access to shared resources, implement mechanisms to prevent conflicts, and ensure that data remains consistent across nodes. Distributed file systems such as GFS2 or OCFS2 are commonly used in active/active clusters to coordinate simultaneous access while maintaining data integrity.
Network design, storage performance, and replication overhead are critical considerations in active/active clusters. Administrators must monitor traffic patterns, adjust resource allocation dynamically, and implement redundancy to prevent bottlenecks. High-speed interconnects and optimized storage protocols contribute to reduced latency and increased efficiency. By mastering these factors, Linux professionals can construct active/active clusters capable of supporting mission-critical applications, high-demand services, and enterprise-level workloads with minimal risk of failure.
Integration of Storage Solutions with Clustering
Storage architecture is integral to the functionality of failover clusters. Active/passive clusters rely on block-level replication technologies such as DRBD to mirror data between primary and standby nodes. This replication ensures that the secondary node can assume control immediately in the event of a failure, preserving data integrity and operational continuity. Active/active clusters, which support concurrent access, utilize clustered file systems that coordinate writes across multiple nodes, preventing conflicts and maintaining consistency.
Administrators must carefully consider network latency, storage throughput, and replication overhead when designing clustered storage solutions. Improper configuration can lead to performance degradation, data inconsistencies, or extended failover times. Integrating storage solutions with clustering software, resource managers, and monitoring tools creates a cohesive high availability environment where data replication, failover, and load distribution operate seamlessly to support enterprise operations.
Enterprise Linux High Availability Solutions
Enterprise Linux distributions offer comprehensive tools and extensions to simplify the deployment and management of high availability clusters. Red Hat Enterprise Linux provides a High Availability Add-On, which integrates Pacemaker, Corosync, and preconfigured resource agents. This add-on facilitates the creation of active/passive and active/active clusters, automated failover, fencing mechanisms, and monitoring capabilities. SUSE Linux Enterprise includes a High Availability Extension that provides similar functionality, offering administrators prebuilt templates, configuration tools, and management utilities to streamline cluster deployment.
Understanding the specific features, limitations, and best practices of each distribution is critical for successful cluster implementation. While the underlying principles of clustering remain consistent, distribution-specific tools, commands, and configuration files vary. Administrators must familiarize themselves with these differences to optimize performance, maintain stability, and ensure compatibility with enterprise workloads. The extensions provided by enterprise Linux distributions accelerate deployment, reduce configuration errors, and support long-term maintainability of high availability environments.
Configuring Fencing Mechanisms
Fencing mechanisms are essential for maintaining cluster integrity, particularly during node failures or network partitions. STONITH is a common fencing technique that isolates malfunctioning nodes to prevent them from accessing shared resources. Administrators must configure fencing devices, define failover policies, and integrate these mechanisms with resource managers to ensure that clusters respond correctly to failures. Proper fencing prevents split-brain scenarios, data corruption, and service inconsistencies, thereby safeguarding enterprise applications.
Fencing can be implemented using various approaches, including power management devices, network isolation, or storage-level fencing. The choice of method depends on the hardware infrastructure, network topology, and specific application requirements. Testing fencing procedures in a controlled environment is crucial to verify that failover occurs as expected and that the cluster maintains its integrity under different failure scenarios.
Monitoring, Troubleshooting, and Optimization
Maintaining failover clusters requires continuous monitoring, proactive troubleshooting, and performance optimization. Administrators must track node health, resource utilization, and service availability to detect potential issues before they escalate. Cluster monitoring tools provide real-time status updates, alerts, and performance metrics, enabling administrators to intervene promptly when necessary.
Troubleshooting involves identifying the root causes of failures, such as misconfigurations, network interruptions, or storage inconsistencies. Administrators analyze logs, evaluate heartbeat signals, and validate resource dependencies to resolve issues efficiently. Optimization focuses on balancing workloads, minimizing failover latency, and enhancing storage and network performance. By combining monitoring, troubleshooting, and optimization practices, administrators ensure that high availability clusters operate reliably, efficiently, and resiliently in enterprise environments.
Practical Hands-On Exercises for Enterprise Readiness
Building practical experience is indispensable for mastering failover clusters and enterprise high availability. Administrators should set up multiple nodes, configure resource managers, deploy replicated storage, and simulate failure scenarios. Testing failover procedures, observing cluster behavior, and refining configurations enable the development of operational competence and problem-solving skills.
Hands-on exercises also allow experimentation with advanced configurations, such as integrating load-balancing mechanisms, combining active/passive and active/active clusters, and implementing fencing policies. Regular testing and validation provide insight into cluster dynamics, performance optimization, and potential failure modes. These exercises cultivate both confidence and expertise, equipping administrators to manage complex enterprise Linux environments effectively and ensuring that high availability objectives are consistently met.
Strategic Considerations for Enterprise High Availability
Designing enterprise high availability clusters requires a strategic approach, balancing redundancy, performance, scalability, and operational simplicity. Administrators must assess application requirements, workload characteristics, and resource constraints to determine the appropriate cluster topology, resource allocation, and failover strategies.
Scalability is a critical consideration, as clusters must accommodate growing workloads without compromising stability or performance. Resource management, storage replication, and network design must be aligned to support dynamic scaling. Strategic planning also involves defining monitoring protocols, maintenance schedules, and contingency plans to handle unexpected failures. By adopting a strategic mindset, administrators can construct resilient high availability environments that sustain enterprise operations under diverse conditions while minimizing risk and operational overhead.
Understanding High Availability Cluster Storage
High availability cluster storage forms the backbone of resilient enterprise Linux environments, providing redundancy, data integrity, and continuous access to critical applications. Storage in high availability clusters must be meticulously configured to accommodate both active/passive and active/active configurations. In active/passive clusters, block-level replication tools like DRBD synchronize data between primary and standby nodes, ensuring that the standby can assume full operational responsibility without data loss. This replication occurs in real time, providing seamless continuity during failover events and preserving transactional consistency.
Active/active clusters, on the other hand, allow concurrent access to shared storage across multiple nodes. Distributed file systems such as GFS2 or OCFS2 coordinate simultaneous writes, maintain data integrity, and prevent conflicts. These systems are particularly valuable for workloads that demand high throughput, real-time data access, and fault tolerance. Administrators must understand the interplay between network latency, storage performance, and replication mechanisms to ensure that cluster storage remains efficient, resilient, and capable of supporting enterprise-level workloads.
DRBD and Clustered Logical Volumes
DRBD, or Distributed Replicated Block Device, is a cornerstone technology for high availability clusters, enabling real-time block-level replication between nodes. By replicating data across networked nodes, DRBD ensures that standby nodes maintain an exact copy of the primary node’s data. This capability is critical for active/passive clusters where failover must occur without loss of information or interruption of service. Administrators must configure replication modes, monitor synchronization status, and validate data integrity to ensure robust operation.
Clustered logical volumes, or cLVM, provide additional flexibility and redundancy by allowing storage resources to be shared across multiple nodes while supporting volume snapshots, dynamic resizing, and replication. When integrated with failover mechanisms, cLVM ensures that storage resources are consistently available and that data remains synchronized, even during node failures. Properly configuring DRBD in conjunction with cLVM allows administrators to build resilient storage architectures that form the foundation for high availability clusters.
Clustered File Systems and Concurrent Access
In active/active clusters, where multiple nodes access the same data concurrently, clustered file systems are indispensable. GFS2, the Global File System version 2, and OCFS2, the Oracle Clustered File System, manage simultaneous read and write operations across multiple nodes while preventing conflicts and ensuring consistency. These file systems rely on lock management protocols and journaling techniques to coordinate access, maintain data integrity, and prevent corruption.
Administrators must consider storage performance, network speed, and cluster node topology when deploying clustered file systems. High-speed interconnects, optimized caching, and proper lock management enhance efficiency and reduce latency. By mastering these technologies, Linux professionals can design active/active clusters capable of handling high-demand workloads, ensuring continuous access to critical applications, and maintaining data integrity even under concurrent access scenarios.
Hands-On Practice and Home Lab Setup
Practical experience is vital for mastering high availability cluster storage. Setting up a home lab allows administrators to deploy multiple nodes, configure DRBD replication, establish clustered logical volumes, and implement active/active or active/passive configurations. Hands-on experimentation provides insight into storage synchronization, failover procedures, and cluster dynamics, enabling administrators to anticipate potential pitfalls and optimize performance.
A home lab setup also allows the testing of advanced scenarios, such as simulating node failures, observing replication lag, and validating failover and recovery processes. Administrators can experiment with different storage topologies, network configurations, and cluster management tools to develop a comprehensive understanding of high availability storage. This experiential learning builds both confidence and expertise, ensuring readiness for enterprise deployment and certification examinations.
Practical Exercises for Failover and Recovery
Simulating failover events in a controlled environment is essential for developing operational proficiency. Administrators should intentionally bring down nodes, disrupt network connections, and observe how failover mechanisms respond. This hands-on approach allows for validation of DRBD replication, cluster resource management, and fencing mechanisms, ensuring that standby nodes can assume operational responsibility seamlessly.
Testing recovery procedures is equally important. Restoring nodes, resynchronizing storage, and verifying data consistency provide administrators with an understanding of the time required for recovery, the reliability of replication processes, and the robustness of cluster configurations. Repeated exercises enhance problem-solving skills, foster familiarity with failure scenarios, and improve the ability to maintain uninterrupted service in real-world enterprise environments.
Integrating Storage with Virtualization and Clustering
High availability cluster storage often operates in conjunction with virtualized environments and failover clusters. Administrators must coordinate storage replication with virtual machine management, ensuring that virtual instances remain operational and data consistent during migration or failover. For example, DRBD replication supports live migration by synchronizing virtual machine disks across nodes, while clustered file systems allow multiple virtual instances to access shared storage concurrently without conflicts.
This integration requires careful planning, including network segmentation, resource allocation, and performance monitoring. Administrators must anticipate bottlenecks, optimize storage throughput, and implement redundancy to ensure seamless operation. By integrating storage with virtualization and clustering mechanisms, enterprise Linux environments achieve enhanced resilience, operational flexibility, and high availability for critical applications.
Advanced Storage Management Techniques
Advanced storage management in high availability clusters includes capacity planning, performance optimization, and predictive analysis. Administrators must monitor disk I/O, evaluate replication latency, and optimize caching strategies to maintain cluster efficiency. Storage performance directly affects failover time, virtual machine responsiveness, and application availability, making proactive management essential.
Capacity planning involves forecasting growth, ensuring that storage resources can accommodate increasing workloads without compromising performance. Predictive analysis uses historical data and monitoring metrics to identify trends, anticipate potential failures, and implement preemptive measures. By mastering advanced storage management, administrators can maintain high availability, prevent unexpected downtime, and optimize resource utilization in enterprise environments.
Troubleshooting Storage and Cluster Issues
Troubleshooting high availability cluster storage requires a systematic approach to identify root causes of failure or performance degradation. Common challenges include replication lag, misconfigured logical volumes, network bottlenecks, and lock contention in clustered file systems. Administrators must analyze logs, monitor replication status, and verify resource configurations to resolve issues effectively.
Understanding the interactions between storage, clustering software, and virtualization platforms is crucial for diagnosing problems. Troubleshooting exercises should include simulating network interruptions, storage node failures, and concurrent access conflicts. Repeated practice enhances diagnostic skills, builds familiarity with error patterns, and improves administrators’ ability to maintain uninterrupted service in enterprise Linux environments.
Strategic Planning for High Availability Storage
Designing high availability cluster storage requires strategic consideration of redundancy, performance, scalability, and reliability. Administrators must evaluate the workload characteristics, criticality of applications, and resource requirements to select appropriate replication strategies, file systems, and cluster configurations.
Strategic planning also includes defining monitoring protocols, failover policies, and recovery procedures. By aligning storage architecture with enterprise objectives, administrators ensure that critical applications remain operational, data integrity is preserved, and service continuity is maintained even under adverse conditions. Scalable storage solutions allow for future expansion, accommodating growing workloads while maintaining high performance and reliability.
Combining Labs, Experimentation, and Learning
Hands-on experimentation reinforces theoretical knowledge and prepares administrators for enterprise deployment. Home labs allow for controlled testing of storage replication, failover procedures, clustering configurations, and integration with virtualized environments. Repeated practice cultivates problem-solving skills, enhances understanding of system interactions, and builds operational confidence.
Experimentation should include diverse scenarios, such as simultaneous node failures, network interruptions, and replication conflicts. Observing system behavior, analyzing outcomes, and refining configurations foster deep comprehension of high availability principles. This experiential approach ensures that administrators are equipped to manage complex enterprise Linux environments effectively and efficiently.
Conclusion
High availability cluster storage is a critical component of resilient enterprise Linux infrastructures, ensuring continuous access to applications, data integrity, and operational continuity. By mastering block-level replication, clustered logical volumes, and distributed file systems, administrators can build robust storage architectures that support both active/passive and active/active configurations. Hands-on practice in home labs, simulation of failover events, and integration with virtualized environments reinforce theoretical understanding and cultivate practical proficiency.
Strategic planning, advanced management techniques, and rigorous troubleshooting enhance system reliability, optimize performance, and prepare administrators for enterprise deployment. By combining experiential learning with theoretical knowledge, Linux professionals achieve the expertise necessary to maintain uninterrupted service, safeguard data integrity, and manage high availability environments effectively. Mastery of high availability cluster storage equips administrators to address the challenges of modern enterprise computing, ensuring resilient, efficient, and scalable infrastructures capable of sustaining critical applications in dynamic and demanding operational contexts.

