
Exam Code: PR000005
Exam Name: Data Quality 9.x Developer Specialist
Certification Provider: Informatica
Corresponding Certification: Data Quality 9.x Developer Specialist
Product Screenshots
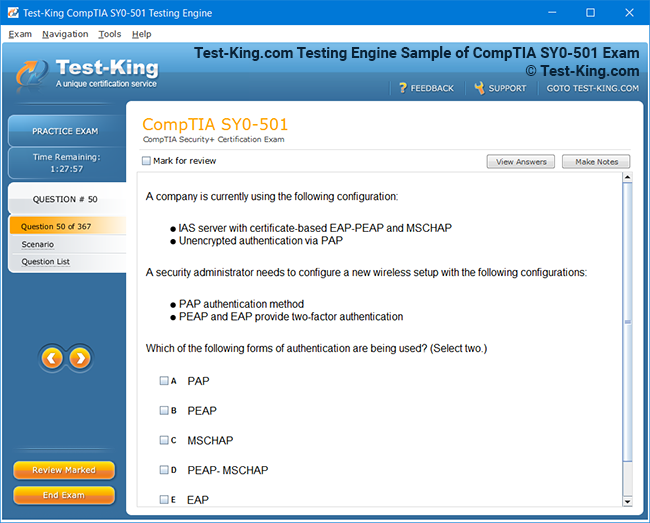
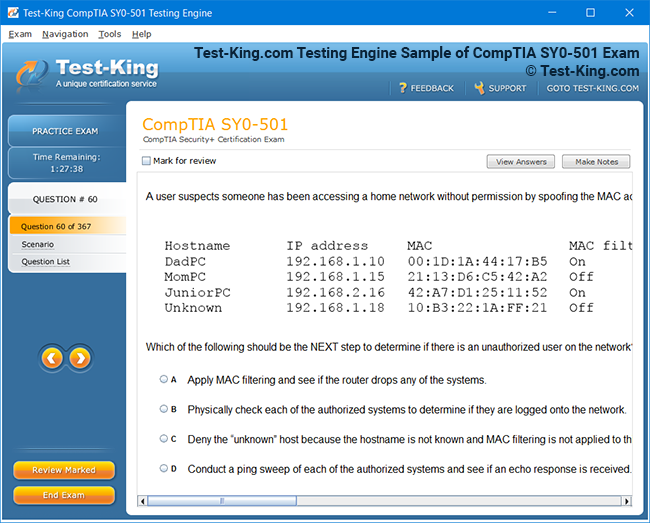
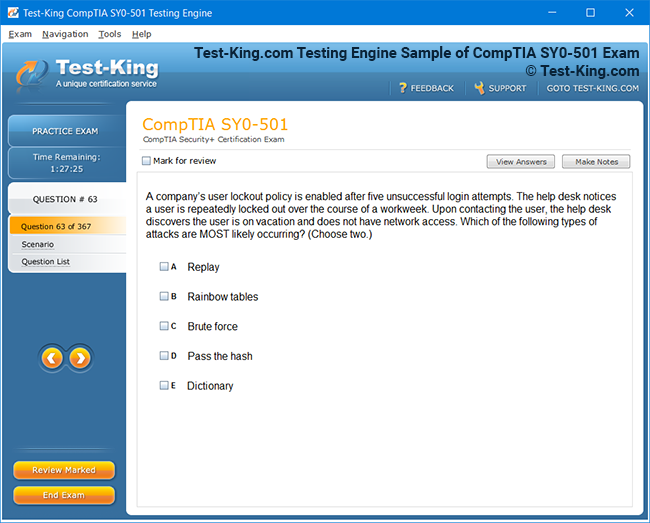
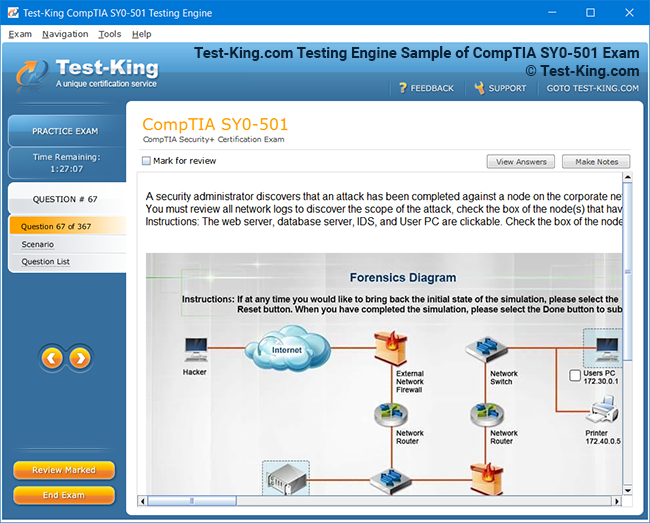
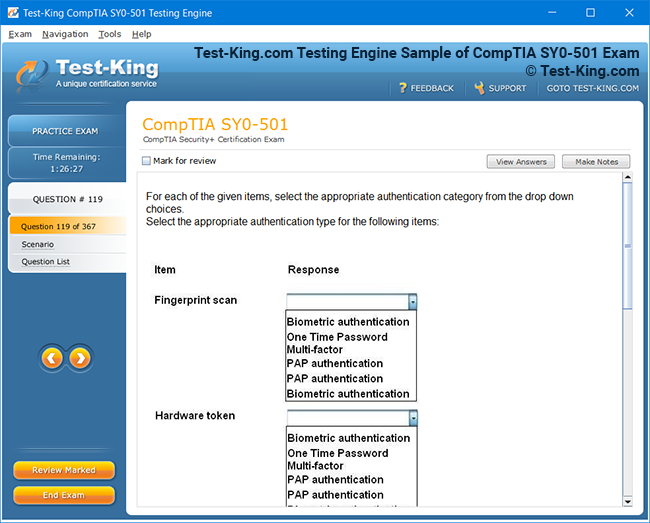
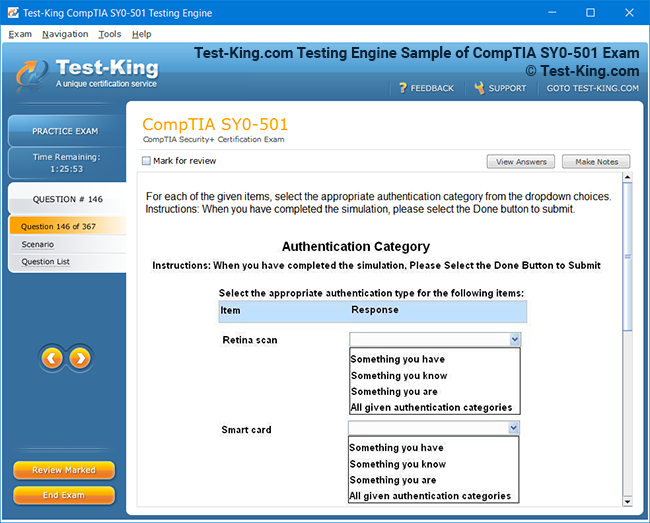
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Exam PR000005: Understanding Informatica Data Quality Concepts and Best Practices
In the contemporary digital landscape, organizations contend with an ever-increasing deluge of data. The sheer magnitude and heterogeneity of information necessitate not only efficient processing but also impeccable data quality. Informatica Data Quality 9.x has emerged as a robust and sophisticated solution to address these exigencies, offering comprehensive functionalities to ensure accuracy, consistency, and reliability across data ecosystems. For professionals aspiring to attain the PR000005 certification, a profound understanding of these capabilities and underlying concepts is paramount. This exam assesses the developer’s proficiency in deploying, managing, and optimizing data quality processes within Informatica environments, providing validation for expertise that extends beyond rudimentary operations.
Introduction to Data Quality and Informatica 9.x
The paradigm of data quality transcends mere error correction. It encompasses a meticulous framework involving validation, profiling, cleansing, standardization, matching, and enrichment. Organizations leverage Informatica Data Quality to establish a coherent and trustworthy dataset, facilitating informed decision-making and regulatory compliance. As enterprises increasingly depend on data-driven strategies, the imperative for developers skilled in designing and implementing robust data quality workflows has intensified. Attaining mastery in these areas requires both theoretical comprehension and hands-on experience with the suite’s components, from analytical transformations to governance protocols.
The Foundations of Data Profiling
At the heart of data quality lies profiling, an analytical process designed to unravel the intrinsic characteristics of datasets. Profiling serves as a diagnostic lens, enabling developers to discern anomalies, inconsistencies, and structural discrepancies. Informatica Data Quality 9.x empowers professionals to conduct detailed profiling operations, which can identify patterns, detect missing values, and uncover duplications that might otherwise compromise decision-making. The objective of profiling is not solely to detect errors but to construct a comprehensive understanding of the data’s inherent structure, cardinality, and interrelationships.
Through profiling, developers can measure completeness, uniqueness, and validity of attributes, thus laying a foundation for subsequent cleansing operations. By leveraging domain-specific rules and statistical metrics, Informatica facilitates the creation of profiles that illuminate subtle irregularities often overlooked in conventional review processes. This enables the identification of latent issues that may proliferate through downstream applications, thereby enhancing the resilience of data pipelines. The application of profiling extends beyond mere technical assessment; it serves as a strategic tool for prioritizing interventions and optimizing resource allocation.
Standardization and Transformation Techniques
Following profiling, the standardization and transformation of data become imperative. Data standardization involves the normalization of disparate representations of information into coherent formats, ensuring uniformity across systems. Informatica Data Quality offers a rich palette of transformations, enabling developers to harmonize names, addresses, and other critical attributes according to predefined rules. This harmonization mitigates the risks associated with inconsistent representations, enhancing interoperability and usability across enterprise applications.
Transformations in Informatica 9.x are not limited to surface-level modifications. They extend to sophisticated operations such as parsing complex strings, correcting typographical anomalies, and applying reference-based validations. The ability to implement transformations efficiently is integral to building robust data quality workflows, as it directly influences the reliability of reporting, analytics, and regulatory compliance. Mastery of these techniques requires a nuanced understanding of both the syntactic and semantic dimensions of data, allowing developers to craft interventions that preserve meaning while enforcing consistency.
Matching and Deduplication Strategies
Equally critical to the data quality continuum is the ability to identify and consolidate duplicate records. Duplicate data can proliferate due to variations in entry conventions, system migrations, or inadequate controls. Informatica Data Quality 9.x provides advanced matching algorithms that combine probabilistic, deterministic, and rule-based approaches to detect redundancies with high precision. Developers must be adept at configuring match keys, thresholds, and transformation rules to achieve optimal deduplication outcomes.
The intricacies of matching involve balancing sensitivity and specificity, as overly aggressive consolidation may erroneously merge distinct records, whereas conservative approaches may leave redundancies unaddressed. Professionals must exercise judicious calibration of algorithms, leveraging both automated scoring mechanisms and manual review processes. Effective deduplication not only improves operational efficiency but also enhances analytical fidelity, ensuring that insights drawn from datasets are both accurate and actionable.
Cleansing and Enrichment Practices
Once profiling, standardization, and matching are executed, the focus shifts to data cleansing and enrichment. Cleansing entails rectifying detected errors, ranging from typographical corrections to semantic adjustments, ensuring that datasets adhere to predefined quality standards. Informatica 9.x equips developers with transformative capabilities that facilitate these interventions, encompassing both attribute-level corrections and holistic record-level adjustments.
Enrichment complements cleansing by augmenting datasets with supplementary information derived from internal or external sources. This process enhances the completeness and contextual value of data, supporting sophisticated analytics and predictive modeling. Enrichment activities may involve geocoding addresses, appending demographic details, or integrating reference datasets to establish consistency and depth. Together, cleansing and enrichment forge a resilient data foundation, empowering organizations to derive actionable insights and maintain compliance with industry standards.
Implementing Best Practices in Data Quality Workflows
Developers preparing for the PR000005 exam must internalize best practices that govern the design and execution of data quality workflows. Central to these practices is the principle of modularity, wherein processes are constructed as discrete, reusable components. This promotes maintainability, scalability, and operational transparency. In addition, comprehensive auditing and logging mechanisms are indispensable, enabling professionals to trace transformations, identify anomalies, and ensure accountability within data quality operations.
Another cornerstone of best practice is the alignment of data quality initiatives with business objectives. Informatica Data Quality provides tools to translate technical operations into measurable business outcomes, facilitating communication between IT and decision-makers. Establishing clear metrics, defining success criteria, and continuously monitoring performance ensures that data quality interventions deliver tangible value. Moreover, fostering a culture of proactive data stewardship encourages ongoing vigilance, reducing the likelihood of degradation and sustaining the integrity of information assets over time.
Exam-Oriented Insights for Developers
For aspirants of the PR000005 certification, understanding these concepts in abstraction is insufficient. The exam evaluates both conceptual mastery and practical proficiency. Candidates are expected to demonstrate the ability to design and implement workflows that integrate profiling, cleansing, standardization, matching, and enrichment in cohesive sequences. Familiarity with transformation logic, rule creation, and error handling is critical, as is the capacity to interpret results and optimize processes.
Practical exercises, such as scenario-based problem solving and real-world project simulations, provide invaluable preparation. Developers should engage with diverse datasets to experience varied challenges, honing skills in anomaly detection, performance optimization, and workflow orchestration. The certification not only validates technical competence but also signals a developer’s readiness to contribute strategically to enterprise data governance and operational excellence.
The Architecture of Data Quality Development
Informatica Data Quality 9.x represents a sophisticated ecosystem designed to manage, enhance, and sustain the integrity of enterprise data. At its core, the platform combines multiple modules that interact seamlessly to provide profiling, cleansing, standardization, matching, and enrichment capabilities. Understanding the architectural framework is pivotal for professionals seeking PR000005 certification, as it elucidates how workflows are structured and executed. The architecture emphasizes modularity, allowing developers to construct reusable components that integrate effortlessly into complex pipelines. Each module operates with specialized transformations and rules that collectively ensure data fidelity, operational efficiency, and compliance with organizational standards.
The architecture also accommodates heterogeneous data sources, enabling developers to extract and process information from diverse systems without compromising consistency. By leveraging metadata-driven operations, Informatica ensures that transformations are traceable, reproducible, and adaptable to evolving business requirements. The integration of quality dashboards and monitoring tools enhances visibility into workflow performance, equipping developers with the ability to detect anomalies, optimize processes, and maintain a high level of data governance.
Understanding Data Quality Rules
Central to the development process is the creation and implementation of data quality rules. These rules serve as the guiding principles for validating, transforming, and correcting data. In Informatica 9.x, rules can range from simple format checks to complex conditional logic that evaluates interdependencies between attributes. For instance, a rule may ensure that an email address conforms to domain-specific conventions or that a customer identifier maintains uniqueness across multiple systems. The effectiveness of these rules hinges on precision, comprehensiveness, and alignment with business objectives.
Data quality rules also extend to reference-based validations, which involve cross-verifying attributes against authoritative datasets or industry-standard references. This ensures that records not only comply with syntactic correctness but also reflect semantic accuracy. Developers must balance rule complexity with maintainability, designing mechanisms that are both robust and flexible enough to adapt to future data requirements. Effective application of rules enhances confidence in downstream processes, from reporting to analytics, and underscores the strategic value of the Informatica platform.
Workflow Design and Orchestration
The orchestration of data quality workflows represents a critical skill for developers aiming to excel in the PR000005 certification. Workflows are designed as sequences of interdependent tasks that implement profiling, cleansing, standardization, matching, and enrichment. Properly orchestrated workflows enable automated, repeatable processes that minimize manual intervention while maximizing data integrity. Developers must consider task dependencies, error handling mechanisms, and performance optimization when constructing these pipelines.
Workflows can also incorporate conditional logic, branching, and iterative loops, allowing for sophisticated processing scenarios. By monitoring workflow execution in real time, developers gain insights into task efficiency, resource utilization, and potential bottlenecks. The ability to analyze and optimize workflow performance is a distinguishing factor for certified professionals, demonstrating not only technical acumen but also strategic foresight in managing enterprise data assets.
Profiling Strategies for Complex Datasets
While profiling is a foundational concept, advanced development requires nuanced strategies to handle complex or voluminous datasets. Informatica 9.x provides multiple profiling methodologies, including column-level, cross-column, and multi-table profiling. Each approach serves a distinct purpose: column-level profiling examines individual attributes for anomalies, cross-column profiling evaluates inter-attribute relationships, and multi-table profiling identifies inconsistencies across relational structures.
Advanced profiling also integrates statistical measures, pattern recognition, and anomaly detection algorithms, offering granular visibility into data quality challenges. Developers must interpret these insights to prioritize remediation efforts and design workflows that address both prevalent and subtle data irregularities. Effective profiling is iterative, combining automated scans with manual scrutiny to establish a comprehensive understanding of dataset characteristics.
Standardization and Transformation Complexity
Transformations in Informatica extend beyond superficial modifications, encompassing sophisticated operations that reconcile inconsistencies while preserving semantic integrity. Standardization involves normalizing diverse representations of information into coherent formats, such as harmonizing address components, formatting date values, and applying consistent naming conventions. Developers must carefully implement transformation logic to avoid unintended consequences, particularly in datasets with high variability or historical inconsistencies.
Informatica 9.x supports intricate transformations that include parsing complex strings, deriving computed attributes, and applying conditional logic based on business rules. The development process emphasizes both syntactic and semantic considerations, ensuring that transformations enhance usability without distorting meaning. Mastery of transformation complexity allows certified professionals to handle intricate data quality challenges, reflecting a deep understanding of the platform’s capabilities and practical applications.
Deduplication and Match Rule Optimization
A sophisticated aspect of data quality development involves deduplication, which requires identifying and consolidating redundant records without compromising accuracy. Informatica 9.x provides an array of match algorithms, including probabilistic, deterministic, and rule-based approaches. Developers must calibrate match keys, thresholds, and scoring mechanisms to achieve precise results, balancing sensitivity and specificity to prevent over-merging or under-detection.
Optimization of match rules demands careful analysis of data patterns, error tolerance, and workflow performance. Developers often employ iterative refinement, leveraging sample datasets to evaluate algorithm effectiveness and adjust parameters accordingly. Deduplication not only enhances operational efficiency but also fortifies analytical accuracy, ensuring that insights derived from datasets are reliable and actionable.
Error Handling and Data Governance
Integral to development is the establishment of robust error handling and governance practices. Informatica 9.x facilitates comprehensive logging, auditing, and exception management, enabling developers to track anomalies, diagnose failures, and implement corrective measures. Effective error handling minimizes workflow disruption, reduces data contamination risks, and supports accountability within organizational data management practices.
Data governance is intertwined with development processes, encompassing policies, standards, and stewardship activities that safeguard data quality. Developers contribute to governance by embedding validation rules, enforcing consistency, and documenting workflow logic. This alignment ensures that technical operations support strategic objectives, regulatory compliance, and long-term sustainability of enterprise information assets.
Practical Considerations for Exam Readiness
For those preparing for PR000005, familiarity with theoretical concepts must be complemented by hands-on experience. Real-world scenarios, encompassing diverse datasets and complex workflows, provide invaluable context for understanding the platform’s capabilities. Developers should engage with profiling, transformation, matching, and enrichment exercises, experimenting with rule creation, workflow orchestration, and error handling. This experiential approach consolidates knowledge, enhances problem-solving skills, and fosters confidence in applying data quality principles in professional settings.
Preparation also involves internalizing the rationale behind best practices, understanding the consequences of suboptimal design, and recognizing opportunities for optimization. By bridging conceptual understanding with practical application, candidates position themselves to not only succeed in the certification exam but also demonstrate tangible value in organizational data quality initiatives.
Profiling Methodologies for Accurate Insights
Informatica Data Quality 9.x provides a robust framework for data profiling, enabling developers to analyze datasets with granularity and precision. Profiling serves as the initial step in understanding the nuances, patterns, and irregularities present in enterprise data. Comprehensive profiling extends beyond merely identifying missing values or duplicates; it involves evaluating relationships between attributes, examining frequency distributions, detecting anomalies, and revealing underlying trends that might affect downstream operations. Advanced profiling techniques include cross-column analysis, pattern discovery, and multi-table assessment, allowing for a panoramic understanding of data characteristics across complex relational structures.
Effective profiling requires meticulous attention to both syntactic correctness and semantic coherence. Developers must discern whether discrepancies arise from typographical errors, system migrations, or inherent inconsistencies in source data. The application of sophisticated statistical measures, coupled with pattern recognition algorithms within Informatica, ensures that the developer can detect subtle anomalies, prioritize remediation, and design workflows that preempt potential operational issues. Profiling is not a one-time exercise but a continuous process that reinforces data integrity over the lifecycle of enterprise datasets.
Standardization for Uniform Data Representation
Following profiling, standardization emerges as a pivotal process in enhancing data usability and interoperability. In Informatica 9.x, standardization encompasses the harmonization of various data elements into coherent, universally interpretable formats. Attributes such as names, addresses, phone numbers, and dates are transformed according to defined conventions, eliminating inconsistencies that could impair analytics, reporting, or integration with other systems. Standardization also mitigates the risk of misinterpretation or misalignment when data traverses different applications or geographies.
The process involves both simple and complex transformations. Simple transformations might include trimming extraneous spaces, converting cases, or enforcing numeric formats, whereas complex transformations may entail parsing compound strings, restructuring hierarchical data, and applying context-specific rules. The skillful implementation of standardization preserves the semantic meaning of data while ensuring syntactic uniformity. Developers preparing for PR000005 must demonstrate proficiency in leveraging Informatica’s extensive transformation capabilities to enforce consistent representations that enhance operational and analytical efficacy.
Matching Strategies for Deduplication and Integrity
Deduplication and matching constitute an essential dimension of data quality, ensuring that redundant or overlapping records are identified and consolidated appropriately. Informatica 9.x offers a suite of matching algorithms, including deterministic, probabilistic, and rule-based approaches, which enable developers to detect duplicates with high precision. The choice of matching strategy depends on the nature of the dataset, business requirements, and tolerance for false positives or negatives.
Deterministic matching relies on exact comparisons of predefined keys, delivering rapid and straightforward results for datasets with standardized attributes. Probabilistic matching, by contrast, evaluates the likelihood that two records represent the same entity, accommodating minor variations, typographical errors, or inconsistencies in formatting. Rule-based matching allows developers to craft bespoke logic that combines multiple attributes and conditional criteria, yielding highly tailored deduplication outcomes. Optimizing match rules requires iterative refinement, testing against sample datasets, and balancing sensitivity and specificity to preserve both accuracy and data integrity.
Integrating Profiling, Standardization, and Matching Workflows
The synergy of profiling, standardization, and matching underpins effective data quality workflows in Informatica 9.x. Profiling informs the design of transformations and match rules by revealing anomalies and irregularities that necessitate intervention. Standardization ensures that these interventions operate on uniform data, reducing the likelihood of errors during matching or enrichment processes. Matching then consolidates records, eliminating redundancy and fortifying the reliability of analytical outputs.
Developers must design workflows that interconnect these processes seamlessly, incorporating conditional logic, iterative loops, and exception handling. Workflow orchestration within Informatica allows for automated execution, monitoring, and error detection, ensuring that data quality measures are consistently applied. By understanding the dependencies and interactions among profiling, standardization, and matching, professionals can create resilient pipelines that maintain the integrity of datasets throughout their lifecycle.
Handling Complex Data Scenarios
Enterprise datasets often present intricate challenges, including variations in structure, inconsistent encoding, incomplete information, and historical discrepancies. Effective application of data quality principles requires strategies to navigate these complexities. For example, hierarchical or nested data structures may require multi-level parsing and standardization, while missing or ambiguous attributes necessitate imputation or enrichment strategies. Similarly, records originating from multiple sources may exhibit overlapping or conflicting information, demanding sophisticated match logic to reconcile inconsistencies.
Informatica 9.x equips developers with a versatile toolkit to address these challenges. Advanced functions enable transformation, cleansing, and validation of complex datasets, while match algorithms provide the flexibility to consolidate records accurately. Handling complex data scenarios also requires an iterative approach: profiling identifies hidden issues, standardization mitigates variability, and matching resolves redundancy. This cyclical methodology reinforces data integrity, enhances operational efficiency, and ensures that downstream analytics reflect reliable and coherent information.
Monitoring and Optimization of Workflows
Beyond design and implementation, continuous monitoring and optimization of workflows are critical for sustaining data quality. Informatica 9.x provides dashboards and auditing capabilities that allow developers to track performance, detect anomalies, and evaluate the effectiveness of rules and transformations. Metrics such as error rates, transformation throughput, match accuracy, and processing time inform adjustments and refinements to workflows.
Optimization may involve tuning match thresholds, revising transformation logic, or redesigning workflow sequences to enhance performance and accuracy. Monitoring also supports proactive maintenance, enabling early detection of data degradation or workflow inefficiencies. Developers preparing for the PR000005 certification must cultivate a disciplined approach to monitoring, recognizing that high-quality data is maintained not only through initial interventions but also through ongoing stewardship and iterative refinement.
Practical Considerations for Certification Readiness
Achieving mastery in profiling, standardization, and matching requires a blend of conceptual understanding and hands-on experience. Candidates for PR000005 are expected to demonstrate not only familiarity with theoretical principles but also practical competence in designing workflows, configuring transformations, and optimizing match rules. Working with diverse datasets, simulating real-world anomalies, and testing rule logic across multiple scenarios cultivates the analytical skills necessary to manage complex enterprise data environments.
Preparation also entails internalizing best practices for modular workflow design, effective error handling, and integration with governance frameworks. Developers who can navigate the intricate interplay of profiling, standardization, and matching, while maintaining efficiency and accuracy, exemplify the expertise that Informatica seeks to validate through its certification. This knowledge translates directly into professional value, enabling organizations to leverage data as a strategic asset and ensuring that analytical insights are both reliable and actionable.
Foundations of Data Cleansing
Data cleansing is an intricate and indispensable component of maintaining the integrity and usability of enterprise datasets. Informatica Data Quality 9.x provides an extensive suite of tools to identify, correct, and standardize information that may be incomplete, inconsistent, or erroneous. Cleansing is not merely a mechanical correction of obvious errors; it involves a nuanced understanding of the context, dependencies, and business significance of each attribute. Developers are expected to discern between superficial anomalies and those that could compromise analytical accuracy or operational reliability.
The process begins with the identification of errors through systematic profiling. Once anomalies are discovered, corrective measures are applied in alignment with established data quality rules. These measures may include removing duplicate records, standardizing variations in spelling or format, correcting misaligned codes, and reconciling conflicting information. In complex datasets, cleansing often involves multi-layered transformations that preserve semantic meaning while improving structural uniformity. For candidates preparing for PR000005, proficiency in applying these cleansing methodologies is critical, as it reflects an ability to translate analytical insight into tangible improvements in data quality.
Enrichment Strategies for Comprehensive Data
Enrichment complements cleansing by enhancing datasets with additional attributes that improve completeness, context, and analytical value. Informatica 9.x facilitates enrichment through integration with internal and external data sources, reference datasets, and calculated transformations. Enrichment may involve augmenting demographic information, appending geospatial coordinates, integrating transactional histories, or validating information against authoritative sources. These enhancements not only improve the usability of data but also provide deeper insights for decision-making, predictive analytics, and regulatory compliance.
Developers must exercise discernment in enrichment, ensuring that the added information maintains coherence with existing records and aligns with business objectives. The enrichment process often requires complex transformations, conditional logic, and validation checks to prevent the introduction of inconsistencies or inaccuracies. By combining cleansing with enrichment, Informatica allows organizations to transform raw, heterogeneous data into high-quality, actionable information that underpins strategic initiatives.
Advanced Transformation Techniques
Transformations are central to both cleansing and enrichment, and advanced techniques enable developers to address the most intricate data quality challenges. Informatica 9.x supports a variety of transformations that extend beyond simple syntactic corrections, encompassing derived calculations, pattern-based adjustments, and context-sensitive modifications. For instance, complex string parsing can be applied to extract meaningful subcomponents from concatenated fields, while conditional transformations can adapt values based on multi-attribute evaluations.
Advanced transformations also include the creation of derived attributes, where new fields are computed using logical or mathematical operations applied to existing data. These derived attributes enhance the analytical richness of the dataset and enable more sophisticated business intelligence and reporting. Mastery of transformation techniques requires a balance between precision, efficiency, and scalability, as developers must ensure that processes remain robust under large volumes of data while preserving semantic integrity.
Handling Ambiguities and Incomplete Data
Ambiguities and missing values are common challenges in enterprise datasets, and effective cleansing and enrichment strategies must address them methodically. Informatica 9.x provides mechanisms to impute missing information, flag uncertain values, and reconcile conflicting data points. Developers often employ reference-based validations, probabilistic reasoning, or statistical imputations to fill gaps while maintaining data fidelity. Handling ambiguities also requires documenting assumptions and implementing error-handling logic that allows workflows to proceed without compromising quality.
In scenarios where data sources provide partial or inconsistent information, enrichment can be used to supplement these records, enhancing completeness without sacrificing accuracy. This combination of cleansing and enrichment is particularly valuable in customer relationship management, financial reporting, and compliance contexts, where incomplete or ambiguous information could lead to operational inefficiencies or regulatory risks.
Workflow Design for Cleansing and Enrichment
Efficient workflow design is pivotal in ensuring that cleansing and enrichment processes are executed effectively and reliably. In Informatica 9.x, workflows are orchestrated as sequences of transformations, validations, and integrations, allowing for automated execution across diverse datasets. Developers must consider task dependencies, error-handling mechanisms, and optimization of processing sequences to maximize efficiency while preserving data quality.
Workflows often incorporate iterative loops, conditional branching, and exception handling to address complex data scenarios. For example, a workflow might first profile a dataset to identify anomalies, then apply standardization transformations, followed by enrichment from external sources, and finally execute validation checks to ensure coherence. Such orchestrated workflows reduce manual intervention, enhance reproducibility, and maintain consistency, reflecting the advanced skill set expected for PR000005 certification.
Monitoring, Logging, and Continuous Improvement
Maintaining high-quality data is not a static endeavor; continuous monitoring and improvement are essential. Informatica 9.x provides comprehensive logging and monitoring capabilities that allow developers to track workflow execution, detect anomalies, and evaluate the effectiveness of cleansing and enrichment operations. Metrics such as transformation accuracy, enrichment completeness, processing throughput, and error rates provide actionable insights for optimization.
Continuous improvement involves iterative refinement of workflows, transformations, and rules. Developers can analyze performance metrics, adjust logic, and incorporate feedback from downstream applications to enhance data quality over time. This proactive approach ensures that enterprise datasets remain reliable, accurate, and enriched, supporting analytics, compliance, and strategic decision-making.
Practical Applications for Certification Readiness
Aspiring professionals preparing for PR000005 must combine theoretical knowledge with practical experience in cleansing and enrichment. Hands-on exercises with diverse datasets, scenario-based problem solving, and workflow simulations cultivate the analytical and operational skills required for certification. Exposure to real-world challenges, such as inconsistent formats, missing attributes, and complex relationships between records, enables candidates to develop robust solutions that demonstrate mastery of Informatica 9.x capabilities.
Understanding the interplay between cleansing and enrichment, along with the application of advanced transformations, equips developers to manage data quality at scale. This expertise not only facilitates success in the certification exam but also prepares professionals to contribute strategically to enterprise data governance, operational efficiency, and analytical excellence.
Understanding the Exam Framework
The PR000005 certification evaluates a developer’s ability to manage and enhance enterprise data using Informatica Data Quality 9.x. Achieving this certification requires both conceptual mastery and practical proficiency. The exam framework is designed to assess knowledge of data profiling, standardization, cleansing, matching, and enrichment, as well as workflow orchestration and optimization. Familiarity with the architecture of Informatica and the interrelationships between modules is essential. Developers must not only recognize how to apply transformations and rules but also understand the implications of their decisions on downstream processes, reporting accuracy, and overall data governance.
Preparation begins with a thorough understanding of these domains. Candidates should analyze the scope of the exam, identifying areas that carry significant weight and emphasizing concepts that frequently underpin practical scenarios. In addition to understanding technical functionality, professionals are expected to demonstrate problem-solving skills, the ability to implement best practices, and the foresight to anticipate challenges in complex datasets.
Creating an Effective Study Plan
A structured study plan is crucial for successful preparation. Given the multifaceted nature of Informatica 9.x, candidates benefit from balancing theoretical review with hands-on exercises. The study plan should include time for revisiting fundamental concepts, practicing workflow creation, and simulating real-world scenarios that involve profiling, cleansing, standardization, matching, and enrichment. Incorporating iterative review sessions ensures that knowledge is reinforced and retained.
Practical exercises are particularly valuable, as they allow candidates to apply rules, transformations, and workflow orchestration in a controlled environment. Simulating errors, duplicates, and incomplete data conditions helps aspirants cultivate troubleshooting skills and adaptability. By integrating incremental challenges, the study plan becomes dynamic, fostering deeper understanding and enhancing confidence in tackling unfamiliar problems during the exam.
Hands-On Experience with Data Workflows
Proficiency in designing and executing workflows is a hallmark of successful PR000005 candidates. Informatica 9.x workflows integrate multiple data quality processes into automated sequences, encompassing profiling, cleansing, standardization, matching, and enrichment. Developing expertise requires repeated practice in constructing, modifying, and monitoring these workflows. Realistic exercises include creating modular transformations, implementing conditional logic, and establishing error-handling mechanisms to ensure operational resilience.
Hands-on experience also reinforces understanding of performance considerations. Developers must evaluate task execution times, resource utilization, and the accuracy of transformations and match algorithms. By experimenting with different configurations, candidates learn to optimize workflows, reduce processing bottlenecks, and ensure that datasets maintain integrity and consistency throughout the pipeline.
Leveraging Scenario-Based Learning
Scenario-based learning is a particularly effective strategy for exam readiness. By engaging with datasets that mimic real-world complexities, candidates cultivate the ability to apply theoretical knowledge under practical constraints. Scenarios may involve cleansing datasets with inconsistent formatting, enriching incomplete records, or reconciling overlapping entities through matching rules. Such exercises not only enhance technical skill but also improve analytical reasoning, problem-solving, and decision-making capabilities.
This approach emphasizes understanding the rationale behind best practices, rather than memorizing procedures. Candidates learn to anticipate potential pitfalls, evaluate multiple strategies, and select the most effective solutions for a given context. Scenario-based preparation aligns closely with the exam’s focus on applied competence, providing a tangible bridge between knowledge acquisition and certification success.
Optimization Techniques for Exam Efficiency
Efficiency during the exam is as critical as technical proficiency. Candidates benefit from strategies that streamline workflow design, reduce the likelihood of errors, and enhance speed in problem-solving. Familiarity with Informatica’s interface, shortcut commands, and common transformation templates can significantly reduce execution time. Additionally, anticipating common pitfalls, such as duplicate detection nuances, standardization inconsistencies, or erroneous rule logic, allows candidates to preemptively apply corrective strategies.
Practicing under timed conditions cultivates the ability to manage tasks methodically, balance accuracy with speed, and maintain composure during the examination. Developers who internalize these techniques are better equipped to navigate complex scenarios, execute workflows effectively, and achieve the level of precision expected by the certification evaluators.
Integrating Knowledge and Practical Skill
Success in PR000005 hinges on the seamless integration of conceptual knowledge and practical expertise. Understanding the theoretical underpinnings of data quality—profiling, cleansing, standardization, matching, and enrichment—provides the foundation, while hands-on application solidifies proficiency. Candidates should continually reflect on the outcomes of their workflows, analyzing the impact of transformations, rule logic, and error handling on overall data quality. This reflective practice enhances understanding, reinforces best practices, and builds the adaptive skill set necessary for certification and professional application.
Conclusion
Effective preparation for the PR000005 certification requires a multidimensional approach that combines thorough understanding of Informatica Data Quality 9.x concepts, structured study plans, hands-on workflow practice, scenario-based learning, and optimization strategies. By integrating these elements, candidates cultivate both technical proficiency and analytical acuity, ensuring readiness to tackle complex datasets, design resilient workflows, and apply best practices in real-world contexts. Achieving certification validates a developer’s capability to manage enterprise data quality with precision and insight, providing tangible professional recognition and demonstrating the ability to contribute strategically to organizational data governance and operational excellence.

