
Certification: Data Quality 9.x Developer Specialist
Certification Full Name: Data Quality 9.x Developer Specialist
Certification Provider: Informatica
Exam Code: PR000005
Exam Name: Data Quality 9.x Developer Specialist
Product Screenshots
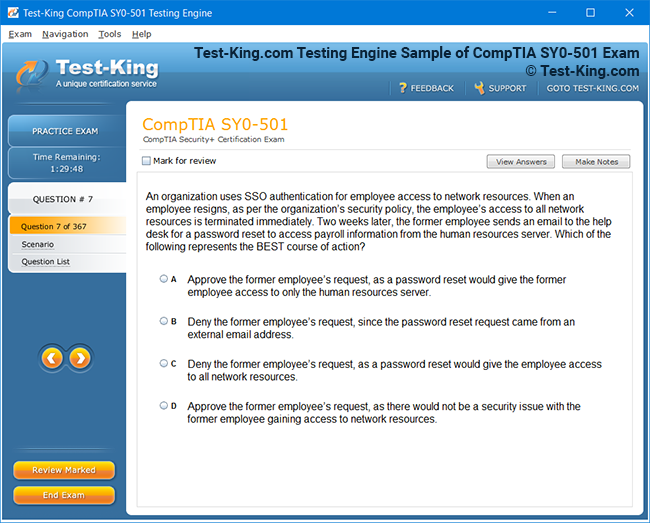
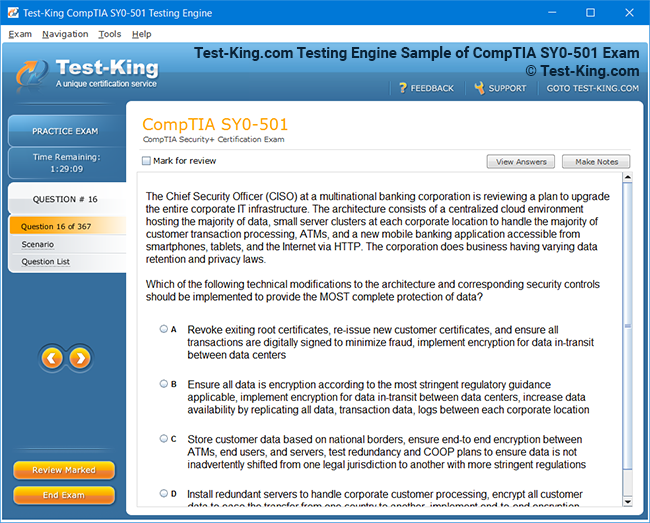
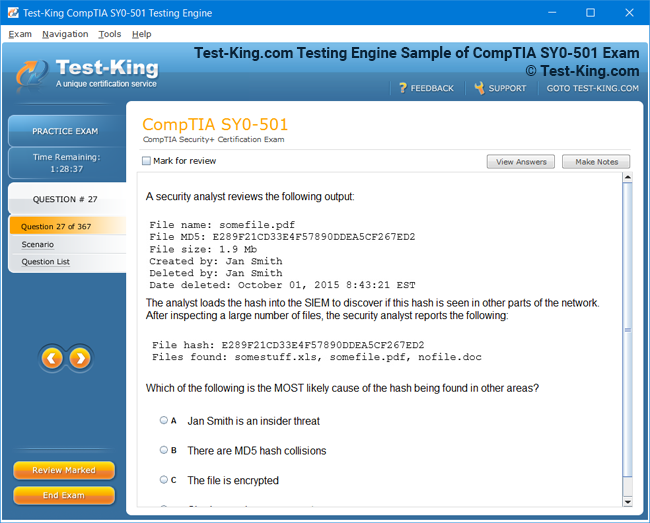
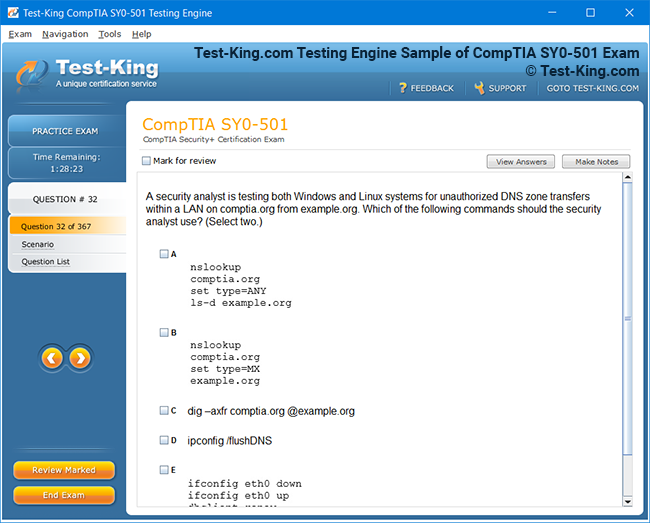
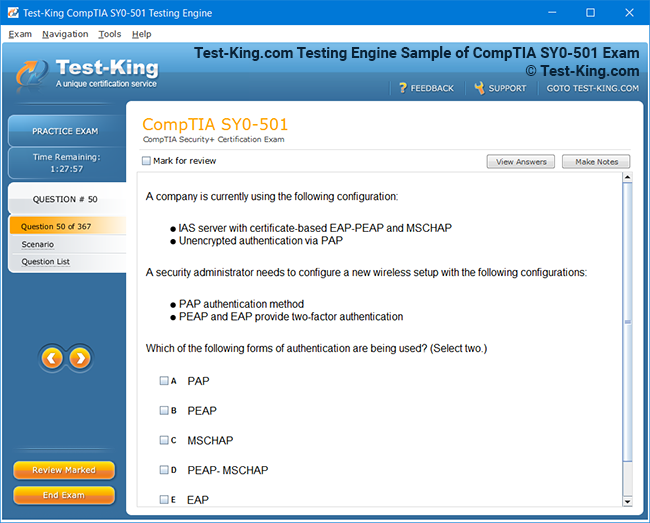
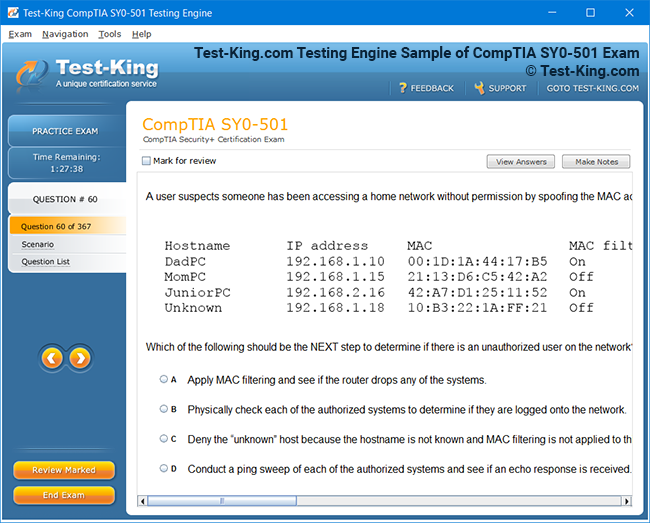
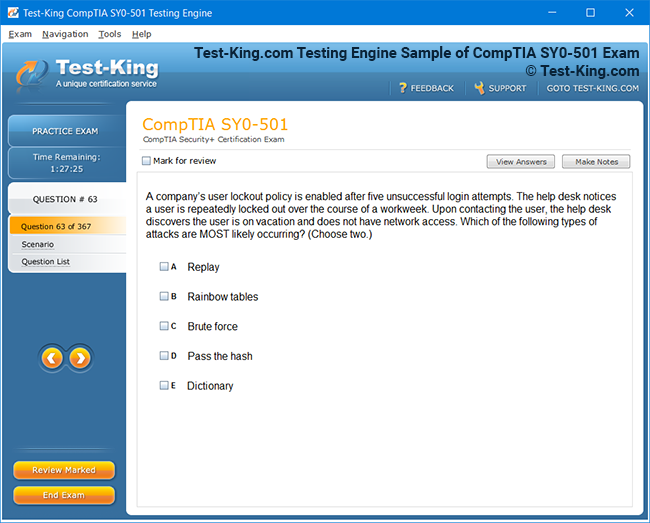
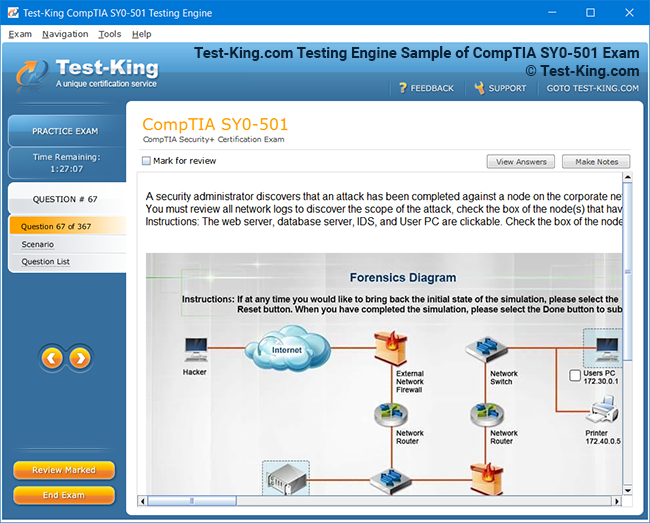
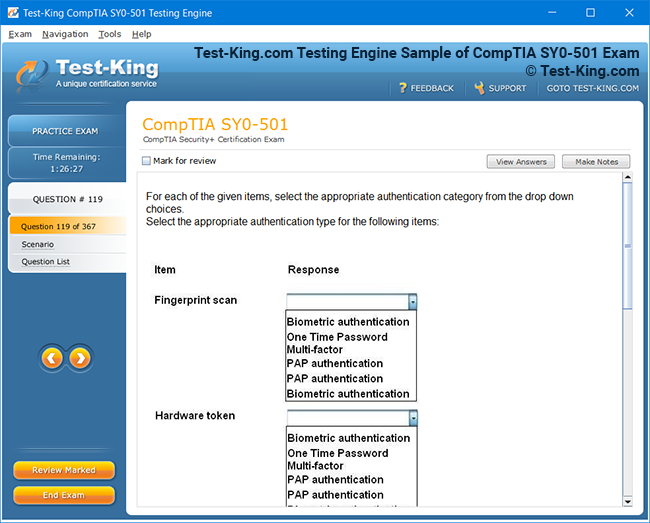
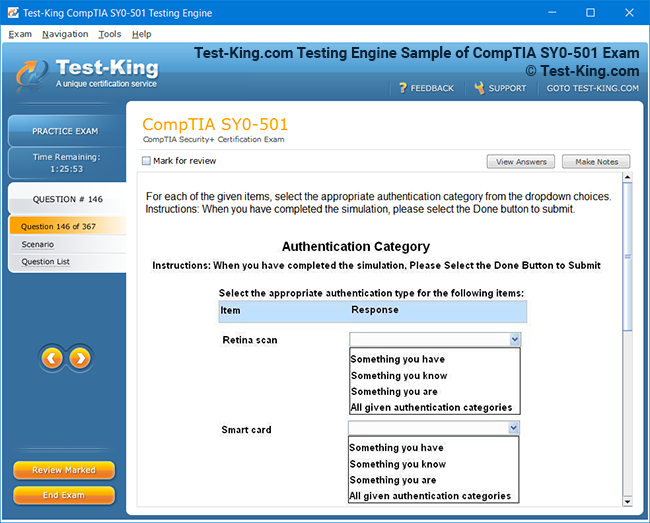
Comprehensive Guide to Becoming a Data Quality 9.x Developer Specialist Certification
Data has emerged as the quintessential asset in contemporary enterprises, influencing decisions, strategies, and overall organizational efficacy. Within this ecosystem, the concept of data quality assumes a paramount role, as the reliability of data directly impacts operational efficiency, regulatory compliance, and business intelligence outcomes. Data quality encompasses attributes such as accuracy, completeness, consistency, timeliness, and validity, ensuring that information can be trusted and leveraged for critical decision-making. Enterprises increasingly recognize that poor data quality can result in erroneous insights, wasted resources, and diminished customer trust, which underscores the demand for proficient professionals who can maintain, enhance, and govern data quality effectively.
Understanding Data Quality and Its Significance in Modern Enterprises
Informatica Data Quality 9.x serves as a robust framework for assessing, monitoring, and improving data quality across heterogeneous systems. The platform offers a suite of tools designed to perform data profiling, cleansing, standardization, enrichment, matching, and monitoring. By equipping developers with sophisticated capabilities, it facilitates the construction of scalable and maintainable data quality solutions. Organizations across finance, healthcare, retail, and technology sectors deploy Informatica Data Quality 9.x to ensure their information assets are accurate, consistent, and actionable, thereby reinforcing the strategic value of certified professionals adept in these tools.
The role of a Data Quality 9.x Developer Specialist transcends simple technical implementation. It demands an understanding of data governance frameworks, enterprise data architectures, and business requirements to design solutions that are both technically sound and aligned with organizational objectives. These developers serve as the linchpin between raw data and actionable insights, transforming chaotic, incomplete, or inconsistent data into reliable resources for analytics, reporting, and operational processes.
Core Competencies and Knowledge Areas
Aspiring professionals must acquire a spectrum of skills to navigate the multifaceted responsibilities inherent in this role. Mastery of the Informatica Data Quality platform begins with proficiency in data profiling, which entails examining data sources to identify anomalies, redundancies, and patterns that may compromise data integrity. Profiling enables developers to detect issues such as null values, format inconsistencies, duplicate records, and referential discrepancies, providing the foundation for subsequent remediation processes.
Cleansing and standardization are subsequent pillars of expertise. Developers design rules and transformations to correct, normalize, and harmonize data according to predefined standards. These transformations may involve parsing complex text fields, standardizing date formats, validating postal codes, and reconciling inconsistent naming conventions. Such procedures require meticulous attention to detail, a deep understanding of data structures, and the ability to anticipate downstream impacts of changes on related datasets.
Enrichment is another critical competency. In many scenarios, raw datasets are incomplete or insufficient for analytical purposes. Developers integrate external data sources, apply reference datasets, or generate derived attributes to augment the informational value of existing data. This process enhances the comprehensiveness and reliability of datasets, enabling more informed decision-making and sophisticated analytics.
Matching and deduplication form a distinct but complementary domain. The ability to identify records that represent the same entity across disparate sources, despite variations in spelling, formatting, or incomplete fields, is a nuanced skill that requires familiarity with probabilistic matching algorithms, fuzzy logic, and scoring techniques. Accurate deduplication not only reduces redundancy but also enhances downstream reporting and operational processes, such as customer relationship management and regulatory compliance.
Workflow orchestration and process automation are essential to operationalize these activities. Developers design end-to-end pipelines that automate data quality assessments, transformations, and monitoring. Such pipelines must be robust, scalable, and maintainable, capable of handling large volumes of data while adhering to performance and reliability benchmarks. Awareness of best practices in job scheduling, error handling, and logging is indispensable to ensure continuous and efficient operations.
Prerequisites and Learning Pathways
While there are no rigid entry-level restrictions for pursuing this specialization, aspirants typically benefit from a foundation in database management, data integration, and basic programming. Familiarity with SQL, relational database concepts, and data modeling enhances comprehension of how datasets interact and how transformations impact underlying structures. Prior exposure to ETL (Extract, Transform, Load) processes is advantageous, as it provides context for designing and implementing data quality workflows within complex data ecosystems.
Professional preparation often combines theoretical study with hands-on experience. Candidates are encouraged to experiment with sample datasets, create cleansing rules, execute profiling tasks, and develop end-to-end workflows to internalize concepts. Engaging with community forums, attending webinars, and reviewing case studies enhances understanding of practical challenges and common pitfalls in real-world scenarios. Such immersive learning cultivates not only technical proficiency but also analytical acumen, enabling candidates to devise solutions that address both immediate data issues and broader organizational objectives.
Knowledge of data governance and regulatory frameworks is another significant asset. Data quality does not exist in isolation; it operates within a broader ecosystem of policies, standards, and compliance requirements. Professionals who understand frameworks such as GDPR, HIPAA, or ISO 8000 can design solutions that ensure data integrity while maintaining adherence to statutory and contractual obligations. This awareness elevates the value of certified developers in organizations that prioritize data stewardship and risk mitigation.
Exam Structure and Evaluation Criteria
The certification evaluation is designed to measure a candidate’s proficiency in implementing, managing, and troubleshooting data quality solutions using Informatica 9.x. The exam emphasizes applied knowledge, scenario-based problem-solving, and practical comprehension of platform functionalities. Topics typically cover data profiling, cleansing, transformation, standardization, enrichment, matching, workflow design, and process automation. Candidates are assessed on their ability to analyze data quality challenges, select appropriate tools or transformations, and execute solutions that adhere to best practices.
Understanding the examination methodology is crucial for strategic preparation. Practitioners often engage with sample exercises, scenario questions, and simulation environments to cultivate familiarity with the types of problems presented. Emphasis is placed on conceptual clarity, as questions frequently involve interpreting data anomalies, recommending remedial actions, or optimizing workflows rather than simple recall of facts. This approach ensures that certified individuals possess the practical skills necessary to contribute effectively in professional environments.
Time management, analytical reasoning, and structured problem-solving are implicit skills evaluated during the examination. Candidates must demonstrate the ability to dissect complex data quality issues, prioritize remedial actions, and design coherent solutions within prescribed timeframes. Mastery of platform-specific tools, coupled with a deep understanding of underlying data principles, equips candidates to navigate both the exam and the demands of real-world projects with confidence.
Career Advantages and Professional Trajectory
Obtaining certification as a Data Quality 9.x Developer Specialist confers significant professional advantages. Certified individuals are recognized for their expertise in transforming raw, inconsistent data into reliable, actionable assets. This expertise positions them as key contributors to initiatives such as business intelligence, analytics, regulatory compliance, and enterprise data governance. Organizations increasingly value certified professionals for their ability to implement robust data quality frameworks that mitigate risks, reduce operational inefficiencies, and enhance strategic decision-making.
The certification opens pathways to diverse roles, ranging from data quality developer and analyst to data governance specialist and solutions architect. In industries where data accuracy is critical—such as banking, insurance, healthcare, and e-commerce—certified professionals often command higher remuneration, access to complex projects, and opportunities for career advancement. The versatility of the skills acquired allows for mobility across domains and the potential to assume leadership or consultancy roles focused on data strategy and governance.
Beyond immediate career benefits, certification cultivates a mindset attuned to precision, analytical rigor, and continuous improvement. Professionals who achieve this credential often develop a systematic approach to problem-solving, an ability to anticipate data-related risks, and a capacity to implement scalable, sustainable solutions. These qualities not only enhance employability but also contribute to long-term professional resilience in an evolving data landscape.
Integration of Rare and Advanced Concepts
Proficiency in Informatica Data Quality 9.x is enriched by exploring nuanced concepts that extend beyond routine operations. Concepts such as probabilistic matching, phonetic encoding, reference data harmonization, and multi-source reconciliation provide developers with sophisticated techniques to tackle complex data quality challenges. Understanding the interplay between semantic consistency, syntactic normalization, and contextual validation allows professionals to design solutions that account for subtle discrepancies and latent data issues.
Advanced workflow orchestration involves not merely sequential task execution but adaptive pipelines that respond dynamically to anomalies, exceptions, or data volume variations. Such sophistication ensures operational resilience and facilitates continuous monitoring, alerting, and remediation. Developers who internalize these advanced paradigms are better equipped to handle enterprise-scale environments where data flows are voluminous, heterogeneous, and time-sensitive.
Knowledge of rare yet impactful practices, such as data lineage mapping, metadata stewardship, and anomaly pattern detection, further distinguishes certified developers. These practices empower professionals to provide transparency into data transformations, identify latent inconsistencies, and reinforce organizational trust in data assets. By integrating such concepts, individuals transcend basic technical execution, positioning themselves as strategic enablers of enterprise data quality initiatives.
Building the Foundation for Excellence in Data Quality
Embarking on the journey to become a Data Quality 9.x Developer Specialist necessitates a solid foundation of technical and analytical proficiencies. In contemporary enterprises, the capacity to ensure accurate, consistent, and reliable data is not merely advantageous but indispensable. This responsibility demands a blend of theoretical understanding and hands-on expertise in areas such as data integration, profiling, transformation, and governance. Professionals who aspire to excel in this domain must cultivate both fundamental knowledge and advanced skills to navigate the complexities inherent in modern data ecosystems.
Database management forms the cornerstone of this expertise. Understanding the architecture of relational databases, normalization principles, indexing mechanisms, and query optimization equips aspiring developers with the ability to interrogate data effectively. SQL proficiency is particularly crucial, as it enables developers to extract, filter, and aggregate data with precision, forming the basis for profiling, cleansing, and enrichment operations. Beyond relational databases, familiarity with semi-structured and unstructured data, including XML, JSON, and text-based datasets, broadens a developer’s ability to handle diverse sources prevalent in contemporary environments.
Proficiency in ETL processes complements database expertise. Extract, Transform, Load methodologies underpin the movement and manipulation of data across heterogeneous systems. A developer must understand the lifecycle of data from ingestion to transformation and ultimately to integration into target systems. This involves awareness of data dependencies, transformation logic, workflow orchestration, and error handling. Grasping these concepts ensures that data quality initiatives are seamlessly embedded into broader enterprise operations without disruption or loss of fidelity.
Analytical thinking is an indispensable skill for a Data Quality 9.x Developer Specialist. The ability to scrutinize datasets for anomalies, inconsistencies, or deviations from expected patterns requires a meticulous approach and a keen sense of detail. Developers must anticipate potential issues, recognize latent trends, and devise corrective measures that preempt downstream problems. This cognitive agility enables professionals to navigate scenarios where data may be incomplete, duplicated, or misaligned with organizational standards, ensuring that outputs remain accurate and reliable.
Technical Skills in Data Profiling and Transformation
Data profiling constitutes a pivotal competency. It involves evaluating the content, structure, and quality of datasets to uncover discrepancies, redundancies, and patterns that may affect integrity. Developers must be adept at generating frequency distributions, identifying null or missing values, detecting anomalies, and performing statistical analyses that illuminate hidden irregularities. This skill not only informs the design of cleansing rules but also provides a diagnostic lens through which overall data health can be assessed.
Cleansing and transformation abilities further enhance a developer’s toolkit. These processes involve the application of rules and logic to rectify inaccuracies, standardize formats, and harmonize datasets. Developers routinely engage in parsing operations, address normalization, date standardization, and character set transformations to ensure consistency across diverse data sources. Mastery of these techniques requires both precision and foresight, as transformations must preserve essential attributes while rectifying inconsistencies. The ability to implement scalable and reusable transformations distinguishes proficient practitioners from novices.
Enrichment constitutes another critical facet. Raw datasets often lack completeness or context, necessitating augmentation with external reference data, derived metrics, or supplementary attributes. Professionals skilled in enrichment can enhance the informational value of data, enabling more robust analytics, reporting, and decision-making processes. This capability requires an understanding of reference sources, validation mechanisms, and integration techniques, ensuring that added data contributes meaningfully to the overall dataset while maintaining integrity and reliability.
Matching and deduplication skills are essential for maintaining accuracy across consolidated data systems. Developers must identify records representing identical entities despite discrepancies in formatting, spelling variations, or incomplete fields. Techniques such as fuzzy matching, phonetic algorithms, and probabilistic scoring empower practitioners to detect and reconcile duplicates, reducing redundancy and enhancing the precision of subsequent analytics. These operations require both technical acumen and analytical judgment to balance sensitivity and specificity in identifying legitimate matches.
Workflow Design and Process Automation
A proficient Data Quality 9.x Developer Specialist must also excel in workflow orchestration. Designing automated pipelines that execute profiling, cleansing, enrichment, and matching tasks ensures efficiency and repeatability. Developers must understand job sequencing, dependency management, error handling, and logging to build resilient workflows capable of operating in high-volume environments. Automation reduces manual intervention, mitigates human error, and enables continuous monitoring of data quality, thereby enhancing enterprise reliability and operational agility.
Integration skills are critical in this context. Developers often interface with disparate systems, applications, and data repositories, requiring familiarity with connectors, APIs, and integration frameworks. Understanding the nuances of data exchange protocols, performance optimization, and system interoperability ensures that quality initiatives do not disrupt operational processes. This expertise enables professionals to implement seamless, end-to-end solutions that maintain fidelity across complex data landscapes.
Soft Skills and Analytical Acumen
Beyond technical proficiency, certain cognitive and interpersonal abilities are crucial for success. Analytical reasoning allows developers to deconstruct complex datasets, identify anomalies, and anticipate the impact of transformations. Attention to detail ensures that even subtle deviations in data are detected and addressed, preserving accuracy across processes. Problem-solving skills enable the formulation of corrective actions and contingency strategies that mitigate potential failures, enhancing the robustness of data quality solutions.
Communication skills are also vital. Developers frequently interact with stakeholders from diverse domains, including business analysts, data architects, and compliance officers. The ability to convey technical findings, propose solutions, and align initiatives with organizational goals ensures that data quality efforts receive appropriate support and integration. Professionals who cultivate these soft skills can bridge the gap between technical execution and strategic impact, elevating their role within the enterprise.
Learning Resources and Hands-On Experience
Acquiring these skills is facilitated through a combination of theoretical study, practical exercises, and engagement with professional communities. Accessing official Informatica training programs, documentation, and sample exercises provides foundational knowledge of platform functionalities and best practices. Complementary resources such as webinars, workshops, and forums allow aspirants to observe real-world applications, learn from peer experiences, and internalize advanced techniques.
Hands-on practice is paramount. Working with sample datasets to perform profiling, cleansing, enrichment, and deduplication tasks enables the application of conceptual knowledge to tangible scenarios. Developing end-to-end workflows, experimenting with transformations, and testing error handling mechanisms cultivate practical problem-solving abilities. Such experiential learning fosters familiarity with the nuances of the platform, enhances confidence, and prepares candidates for complex tasks encountered in professional environments.
Engagement with case studies further enriches understanding. Reviewing instances of data quality challenges, the strategies employed, and the outcomes achieved illuminates the practical implications of theoretical concepts. Aspiring specialists gain insight into decision-making processes, optimization strategies, and best practices, enabling them to approach similar problems with informed judgment.
Understanding Data Governance and Compliance
Data quality does not exist in isolation; it operates within a framework of governance, policies, and regulatory mandates. Familiarity with governance concepts, such as stewardship, lineage, metadata management, and compliance, enhances a developer’s ability to design solutions aligned with organizational and legal requirements. Professionals who integrate governance principles into their workflows ensure that data quality initiatives are not only technically sound but also accountable, auditable, and sustainable.
Regulatory frameworks like GDPR, HIPAA, and ISO 8000 underscore the criticality of compliance in data management. Certified specialists who understand these mandates can implement validation, monitoring, and reporting mechanisms that maintain adherence while preserving operational efficiency. This dual focus on quality and compliance distinguishes accomplished developers, positioning them as indispensable assets in environments where data integrity is both a strategic and regulatory priority.
Advanced Concepts and Rare Competencies
To distinguish oneself further, mastering advanced and rare concepts is invaluable. Techniques such as semantic normalization, reference data harmonization, anomaly detection, and adaptive workflow orchestration equip developers to handle sophisticated challenges. Understanding probabilistic matching algorithms, phonetic encoding methods, and multi-source reconciliation strategies allows professionals to address subtle discrepancies and latent errors that conventional approaches might overlook.
Awareness of metadata stewardship and lineage tracking enhances transparency, enabling organizations to trace data transformations, understand dependencies, and ensure accountability. Anomalies detected through pattern recognition or statistical modeling can preempt potential errors, reinforcing the reliability of critical datasets. These advanced proficiencies, while less common, amplify the strategic impact of a Data Quality 9.x Developer Specialist within the enterprise.
Navigating the Examination Landscape
Achieving the credential of a Data Quality 9.x Developer Specialist requires a comprehensive understanding of the examination structure, its content areas, and effective preparation methodologies. The assessment is designed to measure applied knowledge, practical problem-solving abilities, and conceptual clarity regarding data quality management using Informatica 9.x. Candidates are evaluated on their ability to interpret complex data scenarios, implement appropriate transformations, and design resilient workflows. Unlike rote memorization exercises, the examination emphasizes understanding, analytical reasoning, and the capability to handle real-world data quality challenges.
The exam typically encompasses multiple domains, each focusing on a critical facet of the platform and the developer’s role. Data profiling is frequently examined, requiring candidates to demonstrate the ability to evaluate datasets for anomalies, inconsistencies, and redundancies. This involves identifying missing or null values, frequency distribution errors, pattern deviations, and referential inconsistencies. Practical comprehension of profiling techniques ensures that aspirants can diagnose issues accurately and recommend corrective measures that enhance overall data integrity.
Cleansing and transformation are central to the examination. Candidates are expected to design and implement rules that standardize data, rectify inaccuracies, and harmonize diverse datasets. Examples include parsing text fields, normalizing dates and addresses, and implementing character set transformations. Mastery of these functions demands precision, foresight, and an understanding of how changes in one dataset can impact downstream systems. Effective preparation requires extensive practice in applying transformations in varied scenarios to ensure both accuracy and efficiency.
Enrichment and matching are additional focus areas. Candidates must be adept at augmenting datasets with external reference data or derived attributes, thereby enhancing informational completeness and analytical value. Matching involves reconciling duplicate or related records across multiple sources, often employing probabilistic scoring, fuzzy logic, or phonetic algorithms. Successful navigation of these topics demonstrates the candidate’s ability to maintain consistency and reliability in complex, heterogeneous data landscapes.
Structuring a Study Plan
A methodical approach to preparation significantly enhances the likelihood of success. Candidates are advised to begin with a thorough review of platform functionalities, including data profiling, cleansing, transformation, enrichment, and workflow orchestration. Familiarity with each tool’s capabilities, options, and best practices provides a solid foundation for practical problem-solving. It is beneficial to create a study schedule that allocates dedicated time for conceptual review, hands-on exercises, and practice assessments.
Hands-on practice is particularly vital. Engaging with sample datasets allows aspirants to simulate real-world scenarios, perform profiling analyses, apply cleansing rules, and execute workflows from end to end. Repeated exposure to these tasks reinforces procedural knowledge, hones analytical reasoning, and develops an intuitive understanding of the platform’s operational nuances. It also prepares candidates to tackle scenario-based questions commonly encountered in the exam.
Scenario questions are a distinctive feature of the examination. These items present complex, realistic data issues that require critical analysis and the selection of appropriate solutions. Candidates must evaluate the data, recognize anomalies, consider business requirements, and determine the most effective transformations or workflows. Preparing for such questions involves studying case studies, reviewing past experiences, and developing an approach that balances technical accuracy with practical applicability.
Time management is another essential component of preparation. The examination is structured to challenge both proficiency and efficiency. Candidates must learn to allocate sufficient time to analyze each scenario, identify key issues, apply suitable methodologies, and verify their solutions without sacrificing thoroughness. Practicing under timed conditions can help develop pacing strategies, reduce anxiety, and improve overall performance on examination day.
Utilizing Resources for Effective Preparation
A variety of resources can enhance readiness for the certification. Official training programs, documentation, and practice exercises provide structured guidance on platform features, best practices, and common pitfalls. Engaging with community forums, professional networks, and discussion groups allows aspirants to learn from peers, gain insights into challenging scenarios, and explore alternative approaches to problem-solving. Webinars and workshops often present nuanced techniques and real-world applications, further deepening understanding.
Study materials should also emphasize applied knowledge. Rather than focusing solely on memorization of functionalities, candidates benefit from exercises that simulate enterprise-scale challenges. This may include designing workflows to handle high-volume data, applying multiple cleansing and enrichment transformations, or resolving complex duplicate detection issues. Such immersive experiences cultivate confidence and ensure that aspirants can translate theoretical knowledge into actionable skills.
Mock exams and practice tests are invaluable in gauging readiness. These exercises allow candidates to assess their strengths and identify areas requiring additional attention. Detailed review of incorrect responses provides insight into knowledge gaps, misinterpretations, or procedural errors. Iterative practice combined with targeted study ensures that preparation is both comprehensive and efficient.
Emphasizing Conceptual Clarity
Conceptual understanding is at the core of success. Candidates must comprehend not only the “how” but also the “why” behind each operation. Understanding the principles of data profiling, the logic underlying cleansing transformations, and the rationale for enrichment and matching strategies enables developers to adapt solutions to varied contexts. This depth of comprehension is critical when confronted with unfamiliar or complex scenarios, as the ability to reason analytically often outweighs rote procedural knowledge.
The examination also tests awareness of workflow orchestration principles. Candidates are expected to design automated processes that execute profiling, cleansing, enrichment, and matching operations efficiently. Knowledge of dependency management, error handling, logging, and job sequencing ensures that workflows operate reliably under diverse conditions. Practicing the design and optimization of workflows enhances both exam performance and professional competence in real-world deployments.
Strategies for Scenario-Based Problem Solving
Scenario-based questions require a structured analytical approach. Candidates should begin by carefully examining the dataset, noting anomalies, inconsistencies, or missing information. Identifying the root cause of data issues allows the formulation of targeted remediation strategies. Selecting appropriate transformations, applying enrichment techniques, and reconciling duplicates are subsequent steps that demand both technical proficiency and critical thinking.
Professionals should cultivate the ability to anticipate the impact of each intervention. Altering data without consideration of downstream dependencies can inadvertently introduce new errors or compromise operational workflows. Scenario practice helps candidates develop foresight, enabling them to predict potential consequences and implement solutions that are robust, scalable, and maintainable. Repetition of these exercises strengthens analytical acuity and builds confidence in approaching complex examination problems.
Advanced Preparation Techniques
In addition to standard study routines, advanced preparation techniques can confer an advantage. Simulating enterprise-level datasets with diverse anomalies, integrating multiple sources, and applying layered cleansing and enrichment rules familiarizes candidates with the intricacies of large-scale deployments. Understanding the subtleties of probabilistic matching, phonetic encoding, reference data harmonization, and adaptive workflows equips candidates to handle nuanced challenges that may appear in the examination.
Documentation and note-taking also enhance preparation. Recording observations, summarizing key concepts, and creating visual representations of workflows consolidates understanding and provides a quick reference for review. Reflecting on hands-on experiences, analyzing errors, and iteratively refining techniques reinforces learning and promotes retention.
Maintaining engagement with professional communities offers exposure to rare challenges and advanced practices. Peer discussions, case studies, and shared problem-solving approaches provide perspectives that extend beyond textbook knowledge. Candidates who leverage these opportunities gain insight into unconventional solutions, practical optimizations, and evolving best practices, all of which contribute to a more holistic grasp of the platform and its applications.
Mental Readiness and Exam Day Strategies
Preparation extends beyond technical mastery to encompass mental readiness. Familiarity with the examination format, timing, and question types reduces anxiety and enhances confidence. Candidates benefit from developing a disciplined approach to time management, ensuring that sufficient attention is given to each scenario without compromising accuracy. Maintaining composure, reading questions carefully, and applying structured problem-solving techniques are critical for optimal performance.
Visualization and rehearsal techniques also contribute to readiness. Mentally simulating the workflow of a profiling, cleansing, or enrichment operation can reinforce procedural memory, streamline execution, and minimize errors. Combining this with regular practice on simulated datasets enables candidates to approach examination scenarios with clarity, precision, and confidence.
Mastering the Informatica Data Quality Ecosystem
Excelling as a Data Quality 9.x Developer Specialist necessitates mastery over a multifaceted ecosystem of tools, techniques, and methodologies designed to ensure the accuracy, consistency, and reliability of enterprise data. Informatica Data Quality 9.x offers an extensive suite of capabilities that enable professionals to profile, cleanse, standardize, enrich, match, and monitor data across heterogeneous systems. The developer’s role is to harness these functionalities to design scalable, maintainable, and efficient solutions that address both immediate and latent data quality challenges.
The foundation of effective data quality initiatives lies in profiling tools. Profiling involves systematically examining datasets to uncover anomalies, patterns, and redundancies that could compromise integrity. Developers generate statistical distributions, assess frequency counts, identify null or missing values, and detect inconsistencies across relational, semi-structured, and unstructured data sources. Profiling serves as both a diagnostic and planning tool, guiding the design of subsequent cleansing, enrichment, and matching operations. A nuanced understanding of profiling metrics and advanced functions empowers developers to preemptively address data quality issues before they propagate downstream.
Cleansing and transformation represent the operational core of data quality management. These processes involve applying rules and logic to correct inaccuracies, harmonize formats, and standardize values across diverse datasets. Developers routinely perform text parsing, address normalization, date standardization, character set conversions, and field validation. Mastery of transformation techniques requires meticulous attention to detail, anticipation of downstream effects, and an ability to design reusable, parameterized rules that can accommodate evolving data structures. Transformation strategies must strike a balance between precision, efficiency, and maintainability, particularly in enterprise-scale implementations where large volumes of data flow through complex pipelines.
Enrichment extends the informational value of datasets, addressing incompleteness and enhancing analytical capability. Developers integrate reference datasets, external sources, and derived attributes to augment existing records. Effective enrichment demands knowledge of source reliability, contextual validation, and integration best practices to ensure that additional data enhances, rather than undermines, overall integrity. By incorporating enrichment techniques into workflows, developers transform raw or incomplete datasets into actionable, high-quality resources that drive strategic decision-making and operational effectiveness.
Matching and deduplication are pivotal to maintaining consistency and eliminating redundancies. Developers identify records that represent the same entity across disparate sources despite variations in spelling, formatting, or incomplete fields. Techniques such as probabilistic matching, fuzzy logic, and phonetic encoding are employed to reconcile discrepancies and assign confidence scores to potential matches. Accurate deduplication improves the fidelity of reporting, analytics, and operational systems while reducing resource waste and mitigating risks associated with inconsistent information. Understanding the trade-offs between false positives and false negatives is essential to designing effective matching algorithms and ensuring reliable outcomes.
Workflow orchestration is another critical competency. Developers design automated processes that execute profiling, cleansing, enrichment, and matching tasks in a seamless sequence. Effective workflows account for dependencies, error handling, logging, and performance optimization, ensuring that operations run reliably even under high-volume conditions. Adaptive workflows can respond dynamically to exceptions, anomalies, or varying data volumes, enhancing resilience and operational efficiency. Incorporating monitoring and alerting mechanisms further ensures that data quality initiatives remain proactive and continuously aligned with enterprise standards.
Best practices are integral to professional competence. Developing reusable transformations, maintaining version control, documenting workflows, and adhering to naming conventions fosters consistency, maintainability, and collaboration across teams. Developers should also consider the scalability of their solutions, designing pipelines that accommodate growth in data volume, complexity, and diversity without degradation in performance or accuracy. Emphasizing modularity, parameterization, and configurability allows for flexibility in addressing evolving organizational needs and unforeseen data challenges.
Metadata management and lineage tracking are additional competencies that enhance transparency and accountability. By documenting the origin, transformation, and movement of data, developers provide visibility into workflows, enabling stakeholders to trace anomalies, assess impact, and ensure compliance with governance policies. Understanding metadata structures, lineage relationships, and documentation standards strengthens the reliability of data quality initiatives and positions certified specialists as strategic contributors to organizational data governance.
Advanced techniques elevate a developer’s capability to handle complex challenges. Semantic normalization, reference data harmonization, anomaly detection, and adaptive matching strategies address subtle discrepancies that may escape conventional approaches. Developers who integrate these advanced methods can design solutions capable of handling nuanced errors, latent inconsistencies, and multi-source reconciliation scenarios. Familiarity with these rare competencies distinguishes proficient professionals and enhances the strategic value of their contributions to enterprise data ecosystems.
Integration with broader enterprise systems is another essential consideration. Developers must ensure seamless interaction between data quality workflows and data warehouses, business intelligence platforms, and operational systems. Awareness of connectors, APIs, data exchange protocols, and performance optimization ensures that data quality processes complement broader enterprise operations rather than disrupt them. This systemic perspective enables certified specialists to design solutions that are both technically robust and aligned with organizational objectives.
Continuous monitoring and proactive remediation are central to maintaining high-quality data. Developers should implement real-time or scheduled monitoring to detect anomalies, validate transformations, and ensure adherence to standards. Alerting mechanisms, exception handling, and automated corrective actions enable rapid response to emerging issues, preventing the propagation of errors and maintaining the integrity of operational and analytical outputs. A culture of continuous improvement and vigilance ensures that data quality initiatives remain effective and resilient over time.
Collaboration and communication skills complement technical expertise. Developers interact with data architects, business analysts, compliance officers, and other stakeholders to understand requirements, present findings, and align initiatives with organizational goals. Clear communication of technical concepts, potential impacts, and proposed solutions fosters understanding and support for data quality programs. Professionals who cultivate these soft skills can bridge the gap between technical execution and strategic decision-making, enhancing the overall impact of their work.
Engaging with hands-on projects reinforces theoretical understanding. Working with diverse datasets to perform profiling, cleansing, enrichment, and matching exercises allows developers to internalize concepts, refine workflows, and anticipate operational challenges. Repeated practice builds confidence and ensures that solutions are both effective and efficient. Experimenting with advanced techniques and rare methodologies further deepens expertise, preparing professionals for complex scenarios encountered in enterprise environments.
Awareness of emerging trends in data quality strengthens a specialist’s relevance. Developments such as AI-driven data cleansing, real-time anomaly detection, cloud-based integration, and automated metadata management are shaping the future of the field. Developers who remain informed about these innovations can incorporate forward-looking approaches into their workflows, ensuring that their solutions are both contemporary and strategically advantageous.
Professional development also involves engaging with communities, participating in forums, and reviewing case studies to learn from real-world experiences. Exposure to diverse perspectives, uncommon challenges, and innovative solutions enhances problem-solving capabilities and broadens understanding. Aspiring specialists benefit from observing how complex data quality initiatives are executed, the methodologies employed, and the outcomes achieved, providing a roadmap for their own professional growth.
By integrating robust tools, sophisticated techniques, and established best practices, Data Quality 9.x Developer Specialists create high-value solutions that elevate the reliability, consistency, and usefulness of enterprise data. Mastery of these elements ensures that professionals are equipped to address both routine and exceptional challenges, reinforcing their strategic importance within data-driven organizations.
Exploring Professional Trajectories in Data Quality
The role of a Data Quality 9.x Developer Specialist offers expansive professional avenues across multiple industries. In contemporary enterprises, accurate and consistent data is not merely a technical requirement but a strategic asset that informs decision-making, regulatory compliance, and operational efficiency. As organizations increasingly prioritize data governance, the demand for certified professionals capable of designing, implementing, and managing high-quality data pipelines continues to grow. Certified specialists are recognized for their ability to transform raw or inconsistent data into reliable, actionable insights that drive business intelligence, analytics, and operational excellence.
One prominent career trajectory is that of a data quality developer. Professionals in this role focus on building robust workflows that perform data profiling, cleansing, transformation, enrichment, and matching. They design reusable transformations, manage dependencies, and ensure that automated processes operate efficiently under diverse conditions. This position demands both technical expertise and analytical acumen, as developers must anticipate anomalies, devise corrective measures, and maintain alignment with organizational standards. Experienced developers often assume leadership of larger projects, coordinating teams and optimizing workflows to achieve enterprise-wide data quality objectives.
Data quality analysts represent another key avenue. In this role, specialists monitor and assess the integrity of datasets, identifying discrepancies, inconsistencies, and potential risks. They generate reports, provide insights into data trends, and recommend interventions to maintain compliance and accuracy. Analytical skills, attention to detail, and a comprehensive understanding of data quality metrics are essential for success. Professionals who combine technical proficiency with strategic awareness often contribute to policy development, standardization initiatives, and governance frameworks within their organizations.
Solutions architects constitute a more advanced trajectory, where professionals leverage their expertise to design holistic data quality frameworks across enterprise systems. They assess data sources, design workflows, implement best practices, and integrate monitoring and remediation mechanisms. Architects also focus on scalability, resilience, and maintainability, ensuring that data quality initiatives can adapt to evolving business needs and increasing volumes of heterogeneous data. The ability to align technical solutions with organizational objectives enhances the strategic value of specialists in this capacity.
Data governance specialists are another relevant pathway. Certified professionals often participate in stewardship initiatives, metadata management, lineage tracking, and compliance enforcement. Their role involves establishing standards, documenting data transformations, and ensuring that quality practices align with regulatory frameworks such as GDPR, HIPAA, or ISO 8000. By integrating governance principles into operational workflows, these specialists ensure that data remains both accurate and auditable, reinforcing enterprise trust and reliability.
Industry applications of Data Quality 9.x are diverse and consequential. In finance and banking, accurate data is critical for risk assessment, fraud detection, regulatory reporting, and customer relationship management. Certified specialists design workflows that reconcile customer records, standardize financial transactions, and validate compliance data. Their work reduces operational risk, enhances reporting accuracy, and ensures regulatory adherence, directly impacting organizational stability and stakeholder confidence.
Healthcare is another sector where data quality expertise is invaluable. Patient records, treatment histories, and clinical research datasets must be accurate, complete, and consistent to ensure safe and effective care. Specialists implement cleansing, enrichment, and matching strategies to eliminate duplicate records, standardize clinical codes, and reconcile data from multiple sources. High-quality data enhances decision-making, supports research initiatives, and ensures regulatory compliance, ultimately improving patient outcomes and operational efficiency.
In retail and e-commerce, data quality drives customer engagement, supply chain optimization, and marketing effectiveness. Specialists ensure that product catalogs, customer profiles, and transaction histories are accurate and synchronized across channels. Enrichment with external reference data or derived metrics enhances personalization and predictive analytics. Accurate and complete data enables organizations to anticipate trends, optimize inventory, and deliver superior customer experiences, reinforcing competitive advantage.
Technology and software enterprises also rely heavily on certified specialists to maintain reliable operational and analytical data. Workflow orchestration, automated cleansing, and real-time monitoring ensure that data from multiple applications, databases, and cloud services remains consistent and actionable. Professionals design solutions that integrate diverse data sources, detect anomalies, and provide visibility into data lineage and transformations. These initiatives enhance operational efficiency, support business intelligence platforms, and facilitate data-driven innovation.
Salaries and remuneration trends reflect the strategic value of certified professionals. Organizations recognize the expertise required to implement, manage, and optimize complex data quality solutions and offer compensation that corresponds to experience, skill level, and industry. In high-demand sectors such as finance, healthcare, and technology, certified specialists can access premium opportunities, project leadership roles, and consultancy engagements that further enhance professional growth and exposure.
Consultancy roles provide another avenue for leveraging certification. Professionals with deep expertise can advise organizations on data quality frameworks, best practices, and strategic implementations. They may conduct assessments, design remediation strategies, recommend tools and workflows, and train internal teams. Consulting opportunities often involve exposure to diverse environments, complex datasets, and unique business challenges, enriching experience and expanding professional networks.
Emerging career opportunities also exist in areas such as artificial intelligence-driven data quality, cloud integration, and real-time monitoring. Specialists who understand these innovations can implement cutting-edge solutions that enhance automation, predictive error detection, and dynamic data governance. Staying abreast of technological developments ensures that certified professionals remain relevant, adaptable, and capable of driving continuous improvement across enterprise data landscapes.
Hands-on project experience amplifies career prospects. Working on real-world datasets to design workflows, apply cleansing and enrichment transformations, and perform deduplication exercises equips specialists with practical skills that extend beyond theoretical knowledge. This experience fosters confidence, enhances problem-solving abilities, and prepares professionals to address challenges encountered in operational, analytical, or governance contexts.
Professional networking and engagement with communities further bolster career trajectories. Participating in forums, attending workshops, and reviewing case studies allows specialists to learn from peer experiences, discover innovative methodologies, and explore uncommon applications of data quality solutions. Exposure to diverse approaches enhances adaptability, strategic thinking, and technical dexterity, contributing to sustained professional advancement.
Advanced skills, including probabilistic matching, semantic normalization, multi-source reconciliation, and adaptive workflow orchestration, distinguish top-tier specialists. These competencies enable professionals to tackle nuanced challenges, manage complex datasets, and provide enterprise-wide solutions that address subtle inconsistencies and latent anomalies. Mastery of these rare skills positions certified specialists as indispensable contributors to high-value projects and strategic initiatives.
Collaboration with cross-functional teams is also critical. Specialists must communicate findings, recommendations, and workflow designs to business analysts, data architects, compliance officers, and management. Clear articulation of technical concepts, potential impacts, and remediation strategies ensures alignment with organizational priorities and enhances the credibility of data quality initiatives. Strong interpersonal skills combined with technical acumen amplify the overall influence of certified professionals within their organizations.
Long-term career growth involves continuous learning and skill refinement. Data quality landscapes evolve with technological advances, regulatory changes, and increasing volumes of complex data. Professionals who pursue ongoing training, explore emerging tools, and adopt innovative methodologies maintain relevance and strategic value. This commitment to professional development ensures sustained career opportunities, expanded responsibilities, and recognition as thought leaders within the data management domain.
By integrating technical expertise, analytical insight, industry-specific applications, and advanced methodologies, Data Quality 9.x Developer Specialists unlock a breadth of professional opportunities. Their contributions enhance operational efficiency, regulatory compliance, and strategic decision-making across sectors, affirming their essential role in contemporary data-driven enterprises.
Applying Expertise in Real-World Environments
The role of a Data Quality 9.x Developer Specialist extends beyond theoretical knowledge and technical proficiency, encompassing practical application in diverse organizational contexts. Real-world case studies illustrate how certified professionals transform data from unreliable or inconsistent states into high-quality, actionable assets that enhance decision-making, operational efficiency, and regulatory compliance. In finance, for instance, one global banking institution faced challenges with inconsistent customer records, duplicate accounts, and incomplete transaction histories. By deploying comprehensive data profiling, cleansing, and matching workflows using Informatica Data Quality 9.x, specialists were able to reconcile customer data, standardize formats, and eliminate redundancies. The initiative not only improved reporting accuracy but also facilitated compliance with stringent regulatory mandates, reducing operational risk and improving customer trust.
Healthcare organizations frequently encounter similar challenges with patient records and clinical datasets. One large hospital network struggled with fragmented patient data across multiple departments, leading to inefficiencies in care delivery and reporting. Certified specialists implemented standardized data models, applied advanced cleansing transformations, and enriched records with external reference sources. Matching algorithms reconciled duplicate entries and ensured consistency across disparate systems. The result was a cohesive patient data repository that enhanced clinical decision-making, supported research initiatives, and ensured adherence to regulatory requirements such as HIPAA.
In retail and e-commerce, accurate product and customer data drives both operational efficiency and customer engagement. A multinational retail chain faced discrepancies in product catalogs, misaligned inventory data, and fragmented customer profiles. Data Quality 9.x Developer Specialists implemented robust profiling, cleansing, and enrichment processes, harmonizing product and customer information across online and offline channels. This enabled personalized marketing, accurate demand forecasting, and improved inventory management. Real-time monitoring of workflows ensured that anomalies were detected and remediated promptly, preventing data degradation and sustaining high-quality customer interactions.
Technology and software enterprises also leverage certified specialists to maintain operational data integrity. A cloud-based SaaS provider experienced inconsistencies between internal application logs, customer databases, and analytics systems. By designing automated workflows for profiling, cleansing, enrichment, and deduplication, specialists ensured that data across all systems was reliable and synchronized. These workflows incorporated adaptive error handling and logging, enabling continuous monitoring and proactive remediation. As a result, the organization gained accurate operational insights, improved system reliability, and enhanced decision-making for product development and customer support.
Consultancy engagements provide additional examples of applied expertise. Data Quality 9.x Developer Specialists frequently assist organizations in assessing current data landscapes, identifying anomalies, and designing scalable remediation strategies. In one instance, a consultancy project for a multinational insurance firm involved reconciling policyholder records across multiple legacy systems. The specialists implemented probabilistic matching techniques, semantic normalization, and enrichment using third-party data sources. This comprehensive approach not only reduced duplicate records but also improved risk assessment accuracy, underwriting efficiency, and compliance with regulatory frameworks.
These real-world applications demonstrate the transformative impact of certified specialists on enterprise data ecosystems. Their contributions ensure that organizations can rely on accurate, consistent, and complete data to inform decisions, optimize processes, and maintain regulatory compliance. Moreover, hands-on experience with diverse datasets and complex challenges cultivates problem-solving acumen, technical dexterity, and strategic insight that reinforce a professional’s value within the organization.
Emerging Trends Shaping Data Quality
The field of data quality is continuously evolving, influenced by technological advancements, regulatory changes, and the growing complexity of enterprise data. One of the most significant trends is the integration of artificial intelligence and machine learning into data quality management. AI-driven anomaly detection, automated profiling, and predictive cleansing tools enable real-time identification of data inconsistencies and proactive remediation. Certified specialists who incorporate AI techniques can enhance workflow efficiency, reduce manual intervention, and detect subtle errors that conventional methods might overlook.
Cloud-based data platforms are also reshaping the landscape. Organizations increasingly operate hybrid and multi-cloud environments, requiring data quality workflows that span diverse systems and geographic locations. Specialists design scalable pipelines capable of handling high volumes of heterogeneous data while maintaining consistency, integrity, and compliance. Integration with cloud-native tools allows real-time monitoring, automated remediation, and enhanced accessibility for stakeholders across the enterprise.
Real-time data quality monitoring is another emerging trend. Organizations demand immediate detection of anomalies, enabling rapid corrective actions to prevent downstream errors in analytics, reporting, or operations. Specialists implement continuous monitoring frameworks, combining rule-based validation, statistical anomaly detection, and alerting mechanisms. This proactive approach ensures that high-quality data is available at all times, supporting dynamic decision-making and operational agility.
Data governance and regulatory compliance continue to influence best practices. Certified specialists are expected to maintain awareness of evolving standards such as GDPR, CCPA, and ISO 8000. Workflows increasingly incorporate auditing, lineage tracking, and metadata management to provide transparency and accountability. This ensures that organizations not only maintain data quality but also adhere to legal and ethical requirements, mitigating risk and reinforcing stakeholder trust.
Automation and orchestration advancements further enhance efficiency. Adaptive workflows that respond dynamically to exceptions, varying data volumes, or unexpected anomalies reduce the burden of manual intervention. Specialists leverage workflow automation to implement complex sequences of profiling, cleansing, enrichment, and matching, ensuring that operational and analytical data remains reliable without constant oversight. Parameterization and modular design allow flexibility and reusability across diverse projects, improving scalability and maintainability.
The convergence of data quality with analytics and business intelligence platforms represents another important trend. Accurate and consistent data is foundational to advanced analytics, predictive modeling, and artificial intelligence applications. Specialists ensure that datasets feeding these systems are reliable, enabling organizations to derive actionable insights, optimize strategies, and maintain competitive advantage. This intersection underscores the strategic importance of certified professionals in bridging technical execution with enterprise decision-making.
Emerging methodologies, such as semantic normalization, multi-source reconciliation, and reference data harmonization, are becoming increasingly relevant. These approaches address nuanced inconsistencies, latent errors, and heterogeneous data sources, enabling specialists to deliver high-fidelity datasets. Mastery of such techniques distinguishes top-tier professionals, allowing them to tackle complex challenges that may otherwise compromise operational or analytical outcomes.
Professional development is integral to remaining relevant in this evolving landscape. Specialists who engage with advanced training, industry forums, and case studies gain exposure to cutting-edge techniques, uncommon challenges, and innovative solutions. Continuous learning ensures that certified professionals maintain technical agility, anticipate trends, and implement solutions that are both contemporary and strategically advantageous.
Strategic Implications for Enterprises
The influence of Data Quality 9.x Developer Specialists extends to strategic decision-making and operational resilience. High-quality data supports accurate forecasting, resource optimization, regulatory compliance, and customer satisfaction. Organizations that invest in certified specialists are better positioned to leverage data as a strategic asset, aligning operational execution with business objectives. By integrating data quality initiatives with governance frameworks, enterprises enhance transparency, accountability, and risk mitigation, reinforcing organizational credibility and stakeholder confidence.
Cross-functional collaboration amplifies this impact. Specialists coordinate with business analysts, data architects, compliance officers, and management to design solutions that meet technical requirements and business goals. Clear communication, documentation of workflows, and demonstration of outcomes ensure alignment and foster trust. Professionals who excel in bridging technical and strategic dimensions contribute to both operational efficiency and enterprise-wide decision-making.
Hands-on project experience and exposure to complex datasets cultivate a problem-solving mindset and operational dexterity. Specialists who navigate diverse challenges develop the analytical rigor, technical creativity, and foresight required to address emerging issues effectively. These competencies enhance employability, career advancement, and the capacity to assume leadership or consultancy roles within organizations.
The integration of advanced methodologies, real-time monitoring, AI-driven techniques, and cloud-native tools ensures that certified specialists remain at the forefront of data quality management. Their expertise positions organizations to maintain data integrity, drive operational efficiency, and capitalize on analytics and intelligence initiatives. The strategic influence of these professionals underscores the value of certification and continuous skill development in sustaining organizational excellence.
Conclusion
The role of a Data Quality 9.x Developer Specialist embodies both technical proficiency and strategic insight. Real-world applications across finance, healthcare, retail, and technology illustrate the transformative impact of certified professionals in enhancing data reliability, operational efficiency, and regulatory compliance. Emerging trends, including AI integration, cloud adoption, real-time monitoring, and advanced methodologies, continue to shape the field, demanding ongoing professional development and adaptability.
Certified specialists contribute to enterprise success by designing robust workflows, implementing best practices, and fostering collaboration across cross-functional teams. Their work ensures that data is accurate, consistent, and actionable, supporting informed decision-making, optimizing operations, and reinforcing stakeholder trust. Mastery of both foundational and advanced competencies equips professionals to address current challenges while anticipating future demands, solidifying their role as indispensable contributors to data-driven organizations.
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
