
Certification: RCPE-P-NIV
Certification Full Name: RCPE Certified Professional - Network & Infrastructure Visibility
Certification Provider: Riverbed
Exam Code: 810-01
Exam Name: RCPE Certified Professional Network & Infrastructure Visibility
Product Screenshots
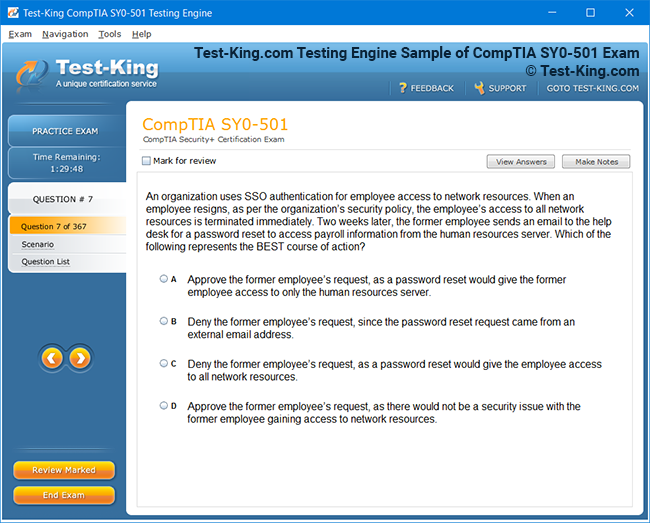
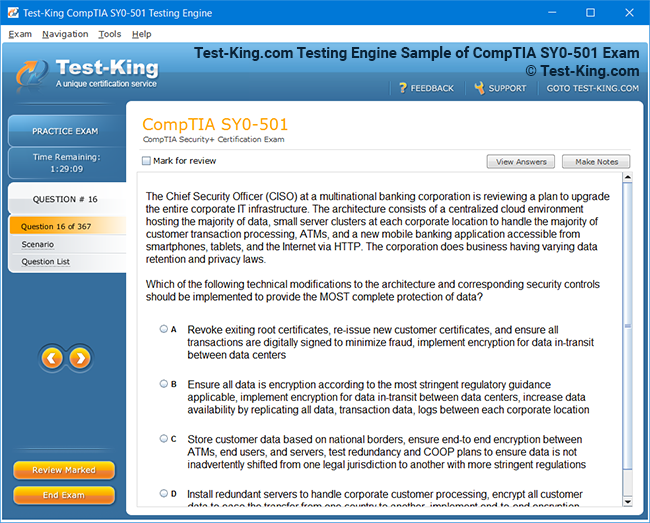
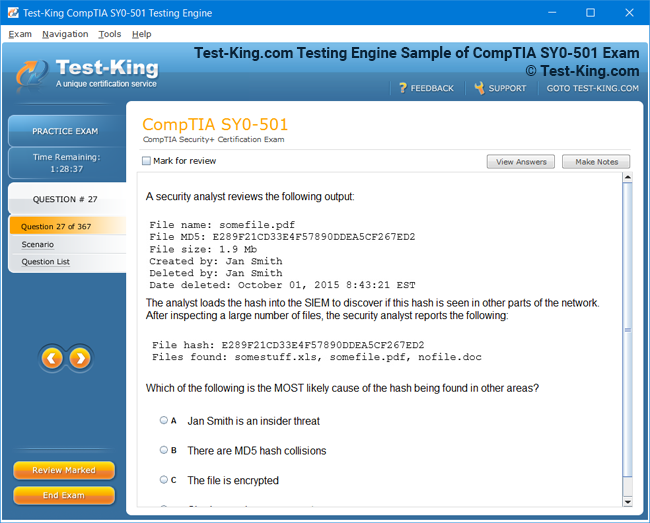
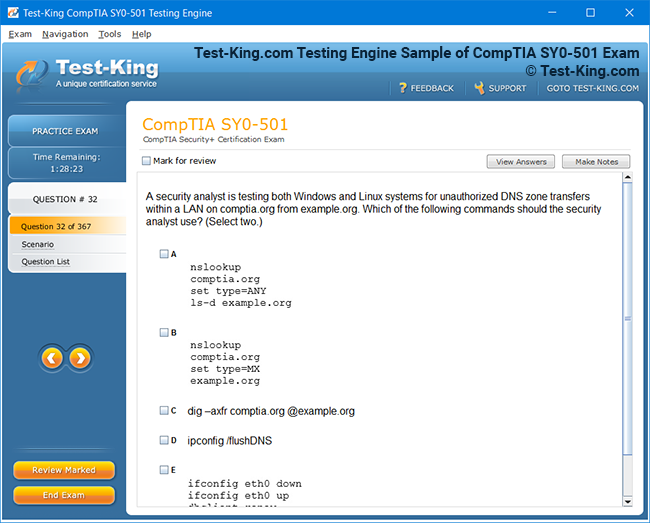
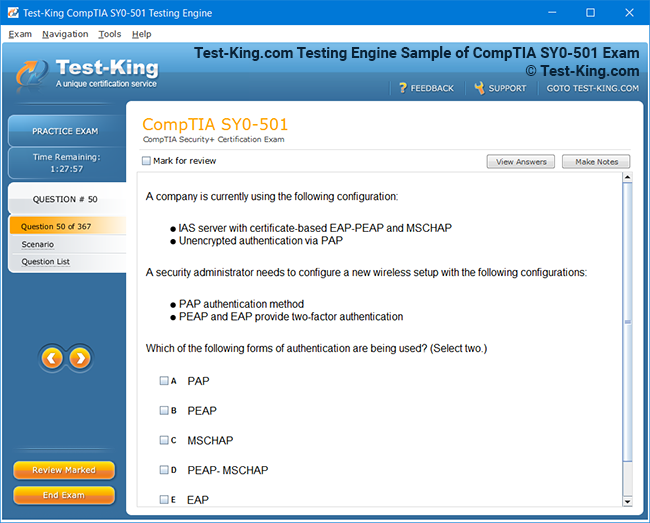
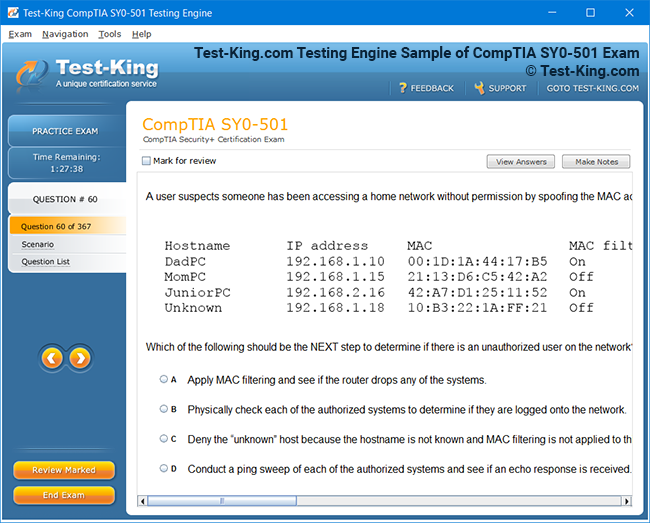
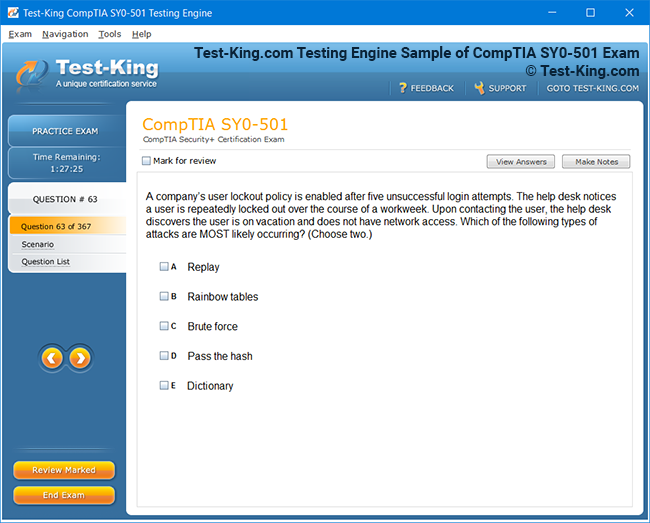
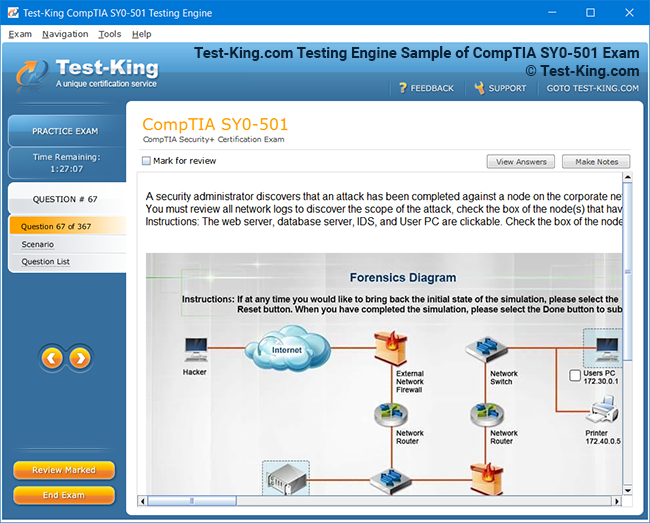
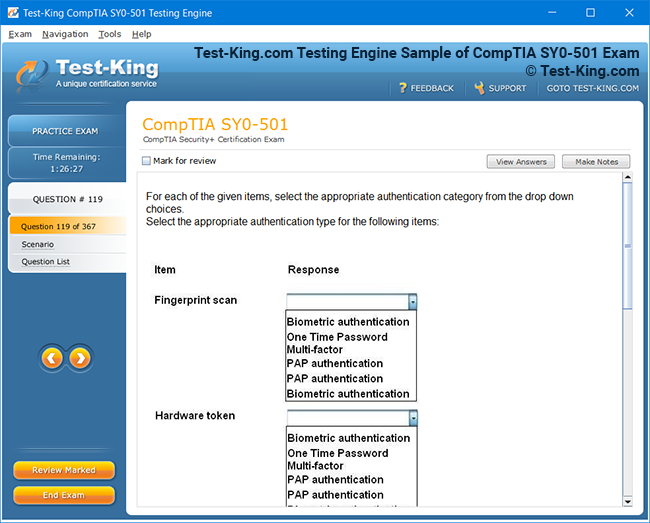
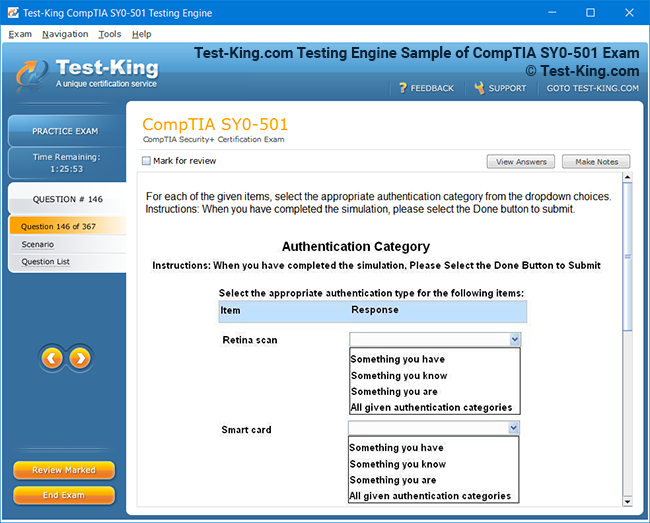
Riverbed 810-01 Certification: Comprehensive Guide to RCPE Certified Professional Network & Infrastructure Visibility
The RCPE Certified Professional Network & Infrastructure Visibility Exam, denoted by the code 810-01, is a highly regarded certification in the domain of network performance and infrastructure visibility. It serves as a formal acknowledgment of an individual's capability to evaluate, optimize, and troubleshoot complex network systems using Riverbed technologies. Achieving this certification demonstrates mastery over the principles of network performance management, network optimization, application acceleration, and security compliance. Professionals who attain this credential are recognized for their ability to interpret intricate network metrics, identify performance bottlenecks, and implement strategies that ensure seamless connectivity across expansive organizational networks.
Success in this exam not only validates technical expertise but also enhances career prospects significantly. Network engineers, system administrators, and IT consultants who pursue this credential are positioned to secure roles that demand a profound understanding of network visibility and infrastructure efficiency. The exam assesses both theoretical knowledge and practical application, making it essential for candidates to cultivate a balanced skill set that includes analytical reasoning, strategic planning, and hands-on experience with Riverbed products such as SteelHead and SteelCentral.
The preparation journey for this examination involves familiarization with a wide array of concepts, starting from the fundamentals of network performance management to advanced topics involving optimization and security compliance. The exam questions are designed to simulate real-world scenarios, prompting candidates to apply critical thinking and problem-solving techniques to complex network challenges. By understanding the underlying principles of network behavior, candidates can anticipate issues, design robust solutions, and ensure efficient data flow across enterprise networks.
Core Network Performance Management Concepts
A foundational component of the 810-01 evaluation revolves around the principles of network performance management. Candidates are expected to grasp the nuances of network latency, throughput, packet loss, jitter, and their collective impact on overall system efficiency. Network performance management is not merely about monitoring metrics but also involves interpreting patterns, recognizing anomalies, and proactively addressing potential bottlenecks. Professionals must develop the ability to assess network behavior over time, correlating traffic patterns with operational events to identify inefficiencies or vulnerabilities.
Understanding network metrics enables candidates to evaluate the health of an entire infrastructure. For instance, recognizing that high latency may be the result of inefficient routing protocols or congested links allows for targeted intervention. Similarly, packet loss may indicate hardware issues, misconfigured devices, or application-level constraints. Mastery in this area equips professionals with the capability to design network architectures that are resilient, scalable, and optimized for performance. By leveraging analytical tools and diagnostic methodologies, candidates can provide solutions that maintain continuous data flow and reduce downtime in mission-critical environments.
Riverbed SteelHead and SteelCentral Products
The proficiency in Riverbed products is another crucial focus of the 810-01 examination. Candidates must demonstrate an intricate understanding of SteelHead and SteelCentral, which are cornerstone technologies in the Riverbed suite. SteelHead serves as a robust tool for application acceleration, enhancing the performance of wide area networks by optimizing traffic, reducing latency, and ensuring efficient utilization of bandwidth. SteelCentral, on the other hand, provides visibility across the entire network, enabling detailed monitoring, analysis, and reporting of performance metrics.
The exam evaluates the candidate's ability to design, configure, and troubleshoot these products in real-world environments. This involves creating deployment strategies that maximize the effectiveness of SteelHead appliances, fine-tuning application acceleration settings, and integrating SteelCentral monitoring to ensure comprehensive network visibility. Troubleshooting scenarios require candidates to diagnose performance degradation, identify root causes, and implement corrective measures swiftly. Practical expertise in using these tools distinguishes certified professionals from those with only theoretical knowledge, as it allows for immediate application of best practices in complex networking environments.
Network Optimization and Acceleration
A critical domain within the 810-01 framework is the enhancement of network performance through optimization and acceleration techniques. This includes understanding the principles of wide area network optimization, application acceleration, and traffic management. Candidates are expected to apply strategies that improve data transmission efficiency, reduce latency, and streamline communication between geographically dispersed sites.
Optimization involves analyzing network traffic, prioritizing critical applications, and deploying acceleration technologies to minimize performance bottlenecks. Techniques such as data deduplication, caching, and protocol optimization are essential for ensuring that high-priority traffic is delivered efficiently while maintaining overall network integrity. By mastering these strategies, candidates demonstrate the ability to improve user experience, reduce operational costs, and maintain high levels of service availability across large-scale infrastructures.
The examination emphasizes the practical application of these concepts, requiring candidates to interpret traffic flows, adjust optimization settings, and resolve issues that hinder performance. Understanding the interplay between network architecture, application behavior, and user demands is key to achieving optimal acceleration. Professionals who excel in this area can predict network strain, implement preemptive measures, and maintain seamless connectivity even under high-load conditions.
Network Visibility and Troubleshooting
The capacity to monitor and troubleshoot network environments forms an essential aspect of the certification assessment. Candidates must demonstrate the ability to identify anomalies, analyze data flows, and implement effective solutions to resolve network issues. Riverbed tools provide advanced monitoring capabilities, enabling professionals to visualize network traffic, detect bottlenecks, and diagnose underlying problems efficiently.
Troubleshooting requires a structured approach, combining systematic investigation with analytical reasoning. Candidates are expected to recognize the symptoms of network degradation, correlate them with potential causes, and execute targeted interventions. This includes leveraging SteelCentral to gain granular insights into network performance, identifying trends that may indicate future issues, and proactively mitigating risks. The examination ensures that candidates are not only capable of identifying problems but also of implementing robust solutions that enhance overall network reliability.
Security and Compliance in Network Infrastructure
A fundamental requirement in modern network management is the adherence to security and compliance standards. The 810-01 evaluation assesses candidates’ knowledge of best practices for safeguarding sensitive data and maintaining regulatory compliance within enterprise networks. Professionals must demonstrate the ability to implement policies, monitor network activity for potential threats, and ensure that organizational standards are consistently met.
Security measures encompass access controls, encryption, intrusion detection, and regular auditing to identify vulnerabilities. Compliance requires familiarity with industry regulations, internal policies, and governance frameworks that dictate the handling of critical data. Riverbed tools support both security monitoring and compliance verification, allowing professionals to maintain a secure environment while optimizing performance. Candidates are expected to integrate these practices seamlessly into network management routines, balancing operational efficiency with robust protection against threats.
Preparation Strategies and Practice Resources
Effective preparation for the 810-01 exam necessitates a structured approach combining theoretical study with practical application. Practice questions and mock tests serve as essential instruments for gauging readiness and simulating the conditions of the actual examination. Reviewing updated questions enables candidates to familiarize themselves with the exam format, identify areas requiring further study, and refine problem-solving strategies.
Utilizing practice tests in both online and Windows-based formats provides a comprehensive preparation experience. These tests allow candidates to assess their understanding, track progress, and identify knowledge gaps that may hinder performance on the actual exam. Engaging in repeated practice cultivates confidence, reinforces learning, and ensures that candidates are equipped to tackle complex scenarios involving network performance, optimization, and troubleshooting.
Candidates are encouraged to analyze mistakes carefully during practice sessions, as this iterative process strengthens comprehension and enhances retention. By integrating practical exercises with conceptual study, candidates develop the dexterity required to apply knowledge effectively in real-world network environments. The preparation process also emphasizes time management, analytical thinking, and strategic problem-solving, which are critical for success in high-stakes certification examinations.
Understanding Network Fundamentals and Metrics
In the realm of modern network infrastructures, mastering the principles of network performance management is pivotal for professionals aiming to achieve proficiency in infrastructure visibility. The RCPE Certified Professional Network & Infrastructure Visibility Exam evaluates an individual’s ability to analyze, optimize, and troubleshoot network systems, emphasizing not only theoretical comprehension but also practical application. A crucial starting point in this journey is a thorough understanding of network fundamentals, including latency, throughput, jitter, and packet loss. Each metric serves as an indicator of network health, revealing insights into how data flows across a distributed environment and where potential inefficiencies may exist.
Latency, the time it takes for data packets to travel from source to destination, can be influenced by several factors such as physical distance, routing paths, and device processing times. Excessive latency often manifests as delayed application responses, degraded video quality, or slow file transfers. Professionals must develop the capacity to quantify latency using diagnostic tools, compare it against expected baselines, and interpret deviations accurately. By doing so, they can pinpoint areas requiring optimization and apply targeted interventions to enhance user experience.
Throughput, the measure of data transmitted successfully over a network within a given period, is another critical metric. High throughput indicates efficient utilization of network resources, while low throughput often signals congestion, suboptimal routing, or hardware limitations. Evaluating throughput necessitates a combination of packet analysis, traffic monitoring, and trend observation. Network administrators must not only detect current throughput bottlenecks but also anticipate scenarios that could strain network capacity, designing architectures resilient enough to accommodate varying workloads and peak demand periods.
Packet loss, the failure of one or more transmitted packets to reach their intended destination, can significantly compromise network integrity. It often arises from hardware malfunctions, software misconfigurations, or network congestion. The repercussions include incomplete data transfers, application timeouts, and impaired communication between networked devices. Recognizing packet loss patterns enables professionals to implement corrective measures, such as rerouting traffic, optimizing transmission protocols, or upgrading network components. By addressing these issues proactively, network engineers can maintain uninterrupted service and prevent cascading failures within critical systems.
Jitter, the variation in packet arrival times, represents another dimension of network performance that demands careful scrutiny. High jitter can disrupt real-time applications like VoIP, video conferencing, and financial trading systems, leading to erratic behavior or communication lapses. Monitoring jitter involves analyzing packet timing, evaluating buffer management, and adjusting quality-of-service parameters to maintain consistency. Understanding the interplay between latency, jitter, packet loss, and throughput is fundamental to achieving a holistic view of network behavior, allowing professionals to implement cohesive strategies that ensure optimal performance.
Diagnosing and Resolving Performance Bottlenecks
Identifying and resolving performance bottlenecks requires a meticulous blend of analytical reasoning, empirical observation, and strategic intervention. Bottlenecks occur when a particular component or path within the network restricts the flow of data, impeding overall system efficiency. These may manifest in hardware limitations, such as overloaded routers and switches, or in software inefficiencies, including poorly optimized applications or misconfigured protocols. A methodical approach to diagnosing these impediments involves capturing network traffic, analyzing performance metrics, and comparing observed patterns with historical baselines.
Once a bottleneck is identified, professionals must employ targeted strategies to mitigate its impact. This may include reconfiguring network devices, reallocating bandwidth, or implementing traffic shaping techniques that prioritize critical applications. Additionally, leveraging Riverbed tools enables a more granular analysis of traffic flows, revealing hidden bottlenecks that conventional monitoring might overlook. The ability to anticipate network strain and apply corrective measures preemptively is a hallmark of expertise, as it ensures that performance remains consistent even under fluctuating demand or unforeseen disruptions.
Optimizing network efficiency also involves evaluating routing algorithms and paths, identifying suboptimal configurations that introduce latency or packet loss. Techniques such as load balancing, redundant path implementation, and dynamic routing adjustments help distribute traffic evenly and reduce congestion. By combining theoretical understanding with practical application, network professionals can maintain high-performance standards across complex infrastructures, ensuring reliability, responsiveness, and scalability.
Network Monitoring and Metrics Analysis
Continuous monitoring and comprehensive metrics analysis are indispensable for maintaining an optimized network. Professionals must cultivate the ability to interpret diverse data sets, from bandwidth utilization charts to latency heatmaps, and draw actionable conclusions. Observing trends over time allows engineers to identify emerging patterns, anticipate potential disruptions, and design interventions that align with organizational objectives. Effective monitoring goes beyond merely observing numbers; it requires contextual understanding, correlating performance data with business-critical processes and application demands.
The application of advanced monitoring techniques, such as flow analysis, packet inspection, and anomaly detection, empowers professionals to uncover latent issues that could compromise network performance. For example, analyzing traffic at a granular level may reveal specific applications consuming disproportionate resources, or uncover unusual patterns indicative of security breaches or misconfigurations. By integrating these insights into operational practices, network managers can implement strategic optimizations that balance efficiency, security, and reliability.
Metrics analysis also serves as the foundation for proactive maintenance. Historical data provides a reference point for identifying deviations, predicting capacity requirements, and planning upgrades or expansions. Professionals adept at interpreting these metrics can make informed decisions, ensuring that network infrastructure evolves in tandem with organizational growth and technological advancements. This capability is essential for sustaining high-performance environments where data flow is mission-critical.
Application of Diagnostic Tools
Proficiency in diagnostic tools is a cornerstone of expertise in network performance management. These tools enable professionals to visualize traffic, pinpoint anomalies, and perform detailed analyses of complex infrastructures. For instance, packet capture utilities allow engineers to examine the content, sequence, and timing of transmitted data, offering insights into performance issues that may not be evident through standard monitoring techniques. By dissecting packet flows, professionals can identify errors, verify configurations, and evaluate protocol efficiency, forming the basis for informed troubleshooting.
Traffic simulators and network emulators provide additional layers of insight, allowing professionals to model scenarios, test interventions, and predict outcomes without impacting live operations. Utilizing these tools effectively requires not only technical knowledge but also analytical intuition, as interpreting simulated results demands careful attention to context, dependencies, and potential cascading effects. Professionals who master these capabilities can proactively address inefficiencies, mitigate risks, and ensure that networks remain resilient under diverse conditions.
Advanced diagnostic tools also facilitate the identification of trends, correlations, and hidden inefficiencies. Integrating data from multiple sources, including performance logs, device metrics, and application-level information, enables a comprehensive view of the network ecosystem. By synthesizing this information, professionals can detect subtle anomalies, anticipate degradation before it manifests, and implement precise, targeted solutions that enhance overall performance.
Proactive Network Optimization Techniques
Proactive network optimization transcends reactive troubleshooting, focusing instead on anticipating performance challenges and preemptively enhancing infrastructure efficiency. Strategies in this domain include bandwidth allocation, protocol tuning, latency reduction, and application prioritization. By aligning these optimizations with organizational objectives, network managers can ensure that critical services maintain uninterrupted performance even under peak demand.
Bandwidth management involves assessing utilization patterns, identifying high-traffic applications, and implementing measures to prevent congestion. Techniques such as traffic shaping, priority queuing, and policy-based routing ensure that essential operations receive preferential treatment while maintaining equitable access for less critical traffic. This balance is crucial in dynamic environments where network load fluctuates unpredictably, requiring adaptive and resilient strategies.
Protocol optimization addresses inefficiencies inherent in communication protocols, adjusting parameters to reduce overhead, streamline transmission, and enhance reliability. This includes fine-tuning TCP windows, optimizing packet sizes, and implementing error-correction strategies that minimize retransmissions. Such measures contribute to smoother, faster data flows and a more predictable network experience, particularly for latency-sensitive applications.
Application prioritization, another vital optimization technique, involves identifying mission-critical applications and allocating resources accordingly. By monitoring performance indicators and adjusting network configurations in real time, professionals can maintain service quality, minimize disruptions, and ensure that critical business functions operate seamlessly. The integration of Riverbed tools enhances this capability, providing visibility into traffic patterns and enabling precise control over resource distribution.
Integrating Analytical Thinking and Strategic Planning
The ability to analyze network performance data and translate insights into actionable strategies is a defining characteristic of certified professionals. Analytical thinking involves dissecting complex problems, identifying root causes, and formulating solutions that address both immediate symptoms and underlying issues. Strategic planning extends this analytical capability, enabling professionals to design long-term improvements that anticipate future demands, accommodate growth, and align with organizational goals.
This combination of analytical rigor and strategic foresight empowers professionals to navigate intricate network ecosystems effectively. By applying structured methodologies, leveraging diagnostic tools, and synthesizing performance metrics, network managers can implement interventions that enhance reliability, efficiency, and scalability. This proactive approach is essential for sustaining optimal performance in environments where data flow is continuous, complex, and critical to operational success.
Understanding Riverbed Product Suite and Its Applications
Riverbed SteelHead and SteelCentral are integral technologies for professionals aiming to excel in network and infrastructure visibility. These tools are designed to optimize performance, enhance visibility, and provide comprehensive insights into network behavior. The RCPE Certified Professional Network & Infrastructure Visibility Exam evaluates candidates on their proficiency with these products, requiring a deep understanding of both theoretical principles and practical deployment strategies.
SteelHead serves as a robust solution for wide area network acceleration, enhancing application performance across distributed networks. Its optimization capabilities reduce latency, maximize bandwidth efficiency, and improve user experience for critical applications. Professionals need to understand how SteelHead operates, including its traffic inspection, caching mechanisms, protocol optimization, and compression techniques. By mastering these functions, candidates can ensure that data flows smoothly between locations, mitigating the performance impact of distance, congestion, and network variability.
SteelCentral complements this by offering end-to-end visibility into network performance. It provides granular monitoring, diagnostic capabilities, and reporting features that allow professionals to assess system health, identify bottlenecks, and analyze trends. Understanding the integration of SteelCentral into network management practices is essential, as it enables proactive troubleshooting, informed decision-making, and the ability to maintain high service quality across enterprise networks. The exam emphasizes the importance of using these tools cohesively to achieve operational excellence.
Architecture and Deployment Strategies
Proficiency in SteelHead and SteelCentral requires a thorough comprehension of their architecture and deployment strategies. SteelHead appliances are typically deployed at key network locations, including branch offices and data centers, to optimize traffic between sites. Their architecture supports both physical and virtual deployments, allowing flexibility in addressing diverse network environments. Candidates must understand how to configure these devices to optimize traffic flows, accelerate applications, and ensure seamless integration with existing infrastructure.
Deployment strategies also involve considerations for redundancy, scalability, and failover mechanisms. Professionals are expected to plan installations that maintain continuity of operations even during hardware failures or network disruptions. The ability to align deployment decisions with business objectives, application requirements, and network topology is critical for ensuring both performance and reliability.
SteelCentral, on the other hand, requires careful planning for monitoring coverage, data collection, and analytics. Integrating SteelCentral into the network architecture involves selecting appropriate data sources, configuring probes, and establishing reporting frameworks. Professionals must be adept at correlating metrics across multiple devices and applications, synthesizing this information to produce actionable insights that drive performance improvements and maintain infrastructure visibility.
Configuration and Optimization Techniques
Configuration of SteelHead and SteelCentral involves detailed knowledge of policies, optimization profiles, and operational parameters. Candidates must demonstrate the ability to set up devices in a way that maximizes their efficiency while meeting organizational requirements. SteelHead configuration encompasses application acceleration settings, bandwidth management rules, and protocol-specific optimizations. Professionals need to balance resource allocation with performance needs, ensuring critical applications receive prioritized treatment while minimizing unnecessary overhead.
Optimization techniques extend beyond device configuration to include network-level strategies. For example, implementing caching mechanisms reduces repetitive data transfers, while compression minimizes bandwidth consumption. Protocol-specific optimizations, such as tuning TCP settings or enabling selective acknowledgement, enhance reliability and throughput across WAN links. Professionals must also understand the interplay between optimization settings and network architecture, as inappropriate configurations can lead to degraded performance or unforeseen conflicts.
SteelCentral configuration focuses on monitoring, analytics, and reporting. Establishing thresholds, alerting mechanisms, and dashboards allows professionals to maintain continuous visibility into network performance. The ability to interpret real-time and historical data, identify trends, and generate meaningful insights is crucial for proactive management. This ensures that issues are addressed before they escalate, and network resources are utilized efficiently.
Troubleshooting and Problem Resolution
Effective troubleshooting with SteelHead and SteelCentral requires a structured approach. Candidates must be capable of diagnosing performance issues, identifying root causes, and implementing corrective actions swiftly. Network degradation may arise from hardware limitations, misconfigurations, application behavior, or external factors. Professionals use SteelCentral to monitor traffic, visualize performance anomalies, and analyze patterns that reveal underlying problems.
SteelHead troubleshooting often involves examining traffic flows, evaluating optimization effectiveness, and adjusting policies to restore expected performance levels. This may include modifying acceleration rules, rebalancing bandwidth allocations, or addressing protocol-specific inefficiencies. Understanding how to leverage SteelHead logs and diagnostic features is critical for identifying subtle issues that impact application performance.
Integrating SteelCentral into troubleshooting provides a comprehensive perspective. By correlating metrics from multiple devices and applications, professionals can identify systemic problems and implement targeted interventions. This holistic approach ensures that solutions are not merely symptomatic but address the root causes of network inefficiencies. Candidates must demonstrate proficiency in combining insights from both SteelHead and SteelCentral to achieve optimal performance and maintain infrastructure reliability.
Enhancing Application Performance
A key objective of SteelHead deployment is the acceleration of application performance. Professionals must understand the mechanisms by which data-intensive applications, collaboration tools, and enterprise services can be optimized across WAN links. Techniques such as caching repetitive content, compressing data streams, and optimizing protocol behavior collectively reduce latency and enhance responsiveness.
Application acceleration also involves prioritizing traffic based on business-critical requirements. Professionals must assess which applications demand the highest performance and allocate resources accordingly. By doing so, they ensure that essential services remain responsive while maintaining overall network efficiency. This skill is tested in the exam through scenarios that require candidates to design and implement solutions that balance application performance with resource availability.
Integrating Monitoring and Optimization
The synergy between SteelHead and SteelCentral is central to effective network management. While SteelHead focuses on optimizing the flow of data, SteelCentral provides visibility and analytical capabilities that inform decision-making. Candidates must understand how to leverage these tools in tandem, using insights from monitoring to guide optimization strategies and adjustments.
For instance, monitoring data may reveal congestion points, underutilized links, or applications that consume disproportionate bandwidth. Professionals use this information to refine SteelHead policies, adjust resource allocation, and implement targeted optimization measures. This iterative process of monitoring, analysis, and adjustment ensures continuous performance improvement, maintaining seamless connectivity and enhancing user experience across the enterprise network.
Security Considerations and Compliance
While SteelHead and SteelCentral are primarily focused on performance and visibility, security and compliance remain integral considerations. Professionals must ensure that optimized traffic adheres to organizational policies and regulatory requirements. This includes implementing access controls, encryption, and monitoring mechanisms to detect unauthorized activities or potential breaches.
Candidates are expected to integrate security considerations into configuration, deployment, and optimization processes. For example, monitoring encrypted traffic without compromising privacy, ensuring compliance with data protection regulations, and maintaining audit trails are all critical responsibilities. By embedding security into performance management practices, professionals ensure that infrastructure visibility and optimization do not come at the expense of organizational risk mitigation.
Best Practices for Professional Mastery
Achieving mastery in SteelHead and SteelCentral involves a combination of theoretical knowledge, practical experience, and analytical skill. Professionals should focus on continuous learning, staying abreast of updates, new features, and evolving best practices. Hands-on experience with real-world deployments, performance tuning, and troubleshooting exercises provides the contextual understanding necessary to excel in the exam and in professional roles.
Analytical thinking, meticulous observation, and strategic planning underpin effective use of these technologies. Professionals who can anticipate network behavior, predict performance bottlenecks, and implement proactive interventions distinguish themselves as experts in network and infrastructure visibility. This holistic approach ensures that network resources are used efficiently, application performance remains optimal, and organizational objectives are consistently met.
Principles of Network Optimization and Acceleration
Network optimization and acceleration are essential disciplines in managing modern infrastructure, particularly in environments that rely on distributed enterprise systems and cloud-based applications. The RCPE Certified Professional Network & Infrastructure Visibility Exam evaluates a candidate’s ability to enhance data transmission efficiency, minimize latency, and improve user experience across complex networks. This requires an understanding of both conceptual frameworks and practical implementation strategies, ensuring that network resources are utilized effectively while maintaining seamless connectivity.
Network optimization is a multifaceted process that encompasses evaluating traffic flows, identifying inefficiencies, and deploying techniques to enhance throughput. Acceleration, on the other hand, focuses on improving the responsiveness of applications, ensuring that critical services function without interruption or delay. Together, these practices create a resilient and agile network environment capable of adapting to fluctuating demands and diverse workloads. Candidates are tested on their ability to apply these strategies in real-world scenarios, integrating insights from performance monitoring with targeted interventions to achieve superior network efficiency.
Wide Area Network Acceleration
One of the core elements of optimization is wide area network acceleration. WAN links often introduce latency, congestion, and bandwidth limitations, particularly when connecting geographically dispersed sites. Professionals must understand the underlying causes of these issues and implement techniques that mitigate their impact. This includes using compression algorithms to reduce the volume of transmitted data, caching repetitive content to avoid unnecessary transfers, and optimizing protocols to minimize overhead and retransmissions.
Acceleration strategies also involve prioritizing traffic based on application criticality. Mission-critical applications, such as enterprise resource planning systems or real-time collaboration tools, require preferential treatment to maintain responsiveness and reliability. Techniques such as quality-of-service configurations, traffic shaping, and selective packet prioritization allow network engineers to manage resources effectively while ensuring that essential applications operate without interruption. Mastery of these methods is crucial for candidates preparing for the examination, as it demonstrates their ability to translate theoretical knowledge into practical solutions that improve network performance.
Protocol Optimization and Traffic Management
Protocol optimization plays a vital role in network acceleration, as inefficient protocols can introduce unnecessary latency and reduce throughput. Candidates must understand the mechanisms of common protocols, including TCP, HTTP, and application-specific protocols, and how to fine-tune their parameters to achieve optimal performance. Adjusting window sizes, enabling selective acknowledgements, and optimizing packet segmentation are examples of techniques that can significantly enhance data flow across WAN links.
Effective traffic management complements protocol optimization by ensuring that network resources are allocated efficiently. This involves analyzing traffic patterns, identifying high-bandwidth applications, and implementing strategies that balance load across available links. Dynamic routing, link aggregation, and congestion avoidance techniques allow professionals to maintain stable performance even under variable network conditions. By mastering these practices, candidates demonstrate the ability to sustain high-quality service delivery and minimize the risk of disruptions that could impact business-critical operations.
Application Acceleration Techniques
Application acceleration is an indispensable component of modern network optimization, focusing on enhancing the responsiveness and reliability of software services. Techniques such as content caching, pre-fetching, and compression reduce the time required for applications to deliver data to end users. Additionally, optimizing the interaction between client and server, minimizing round-trip requests, and streamlining application workflows contribute to faster performance and improved user experience.
Candidates are expected to understand how acceleration techniques integrate with broader network strategies. This includes leveraging analytical insights from performance monitoring tools to identify applications that are resource-intensive or prone to delays. By applying targeted optimization measures, professionals can ensure that critical applications maintain high responsiveness, even when network conditions are suboptimal. The ability to harmonize application acceleration with overall network optimization distinguishes proficient professionals from those with only superficial understanding of network performance principles.
Bandwidth Efficiency and Resource Allocation
Optimizing bandwidth usage is central to network acceleration, particularly in scenarios where links are constrained or shared among multiple users and applications. Professionals must evaluate traffic demands, identify redundant transmissions, and implement techniques that conserve bandwidth while maintaining service quality. Methods such as deduplication, data compression, and selective prioritization reduce unnecessary data transfers, freeing capacity for essential operations.
Resource allocation extends beyond bandwidth management to include considerations of processing power, memory utilization, and storage efficiency. Ensuring that network appliances, servers, and endpoints operate within optimal parameters enhances overall performance and minimizes latency. Candidates are assessed on their ability to plan and implement resource allocation strategies that balance competing demands, ensuring that both critical and ancillary applications receive appropriate support without compromising network stability.
Monitoring and Performance Analytics
Continuous monitoring and performance analytics are critical to effective optimization and acceleration. Professionals must leverage diagnostic tools to track traffic flows, identify anomalies, and assess the impact of optimization strategies. Metrics such as throughput, latency, packet loss, and jitter provide valuable insights into network health, guiding decision-making and informing adjustments to acceleration policies.
Advanced monitoring enables proactive interventions, allowing network engineers to anticipate performance degradation before it affects end users. By correlating historical data with real-time metrics, professionals can identify emerging trends, predict potential bottlenecks, and implement preemptive measures. This approach not only improves efficiency but also reduces the risk of disruptions, ensuring consistent service delivery across complex infrastructures.
Integration with Riverbed Technologies
Riverbed technologies, including SteelHead and SteelCentral, play a pivotal role in network optimization and acceleration. SteelHead appliances accelerate traffic across WAN links, while SteelCentral provides comprehensive visibility into network performance. Candidates must demonstrate the ability to integrate these tools effectively, using monitoring insights to inform optimization strategies and applying acceleration techniques to enhance application responsiveness.
For example, performance analytics from SteelCentral can reveal high-traffic applications, inefficient routing, or latency-prone links. Professionals use this information to adjust SteelHead settings, implement traffic shaping, and optimize protocol behavior. The synergy between monitoring and optimization ensures that interventions are precise, targeted, and effective, maintaining high levels of performance while minimizing unnecessary overhead.
Troubleshooting Optimization Challenges
Optimization and acceleration efforts often encounter challenges that require diagnostic expertise and problem-solving skills. Network degradation may result from configuration errors, incompatible protocols, or unexpected traffic spikes. Professionals must employ systematic troubleshooting techniques, combining data analysis with practical interventions to restore optimal performance.
Using Riverbed tools, candidates can visualize traffic patterns, identify root causes of performance issues, and implement corrective measures. This may involve adjusting bandwidth allocation, modifying acceleration profiles, or resolving protocol inefficiencies. By integrating monitoring, analysis, and intervention, professionals ensure that network optimization efforts achieve the intended improvements and sustain consistent application performance.
Advanced Techniques for Complex Environments
In complex network environments, standard optimization techniques may be insufficient to address diverse challenges. Advanced methods such as dynamic traffic engineering, predictive modeling, and intelligent caching provide enhanced control over data flows. These approaches enable professionals to anticipate congestion, prioritize critical services, and adapt network behavior in real time.
Predictive modeling, for instance, allows engineers to simulate traffic scenarios and evaluate the potential impact of optimization strategies before implementation. Intelligent caching reduces repetitive transmissions, improving efficiency and reducing latency for frequently accessed content. Dynamic traffic engineering ensures that data flows follow optimal paths, avoiding congested links and minimizing delays. Mastery of these advanced techniques demonstrates a high level of expertise and readiness for real-world network management challenges.
Strategic Planning and Implementation
Effective network optimization and acceleration require strategic planning that aligns technical interventions with organizational objectives. Professionals must evaluate infrastructure capabilities, assess application requirements, and develop comprehensive strategies that maximize performance while minimizing costs and risks. This involves prioritizing interventions based on business-critical needs, forecasting future demands, and implementing scalable solutions that accommodate growth and evolving network conditions.
Strategic planning also includes continuous evaluation and adjustment. By monitoring performance outcomes, analyzing trends, and refining optimization strategies, professionals ensure that networks remain agile, resilient, and capable of supporting enterprise operations. The integration of analytical insight, practical implementation, and strategic foresight is essential for sustaining high-performance networks and achieving the objectives measured in the 810-01 exam.
Understanding the Importance of Network Visibility
Network visibility is a fundamental aspect of managing complex infrastructures, particularly in environments that demand high performance, reliability, and security. The RCPE Certified Professional Network & Infrastructure Visibility Exam evaluates a candidate’s ability to monitor, analyze, and troubleshoot network systems effectively. Professionals must understand the behavior of data flows, identify potential issues, and ensure that both applications and network resources operate efficiently.
Achieving comprehensive visibility involves more than merely observing metrics; it requires an integrated approach that encompasses real-time monitoring, historical data analysis, and correlation of performance indicators across diverse devices and applications. By cultivating a deep understanding of network architecture and communication patterns, professionals can detect anomalies, predict potential disruptions, and maintain seamless connectivity across distributed environments.
Diagnostic Tools and Monitoring Techniques
Effective troubleshooting begins with mastering diagnostic tools and monitoring techniques. Professionals use tools that capture traffic flows, inspect packets, and provide detailed metrics about application performance, latency, and bandwidth utilization. These insights allow candidates to identify performance bottlenecks, misconfigured devices, or application inefficiencies that could degrade network operations.
Monitoring extends beyond mere data collection; it involves contextual interpretation. Professionals must correlate observed anomalies with operational events, identifying patterns that indicate underlying issues. For example, periodic latency spikes may reveal congestion during peak business hours, while irregular packet loss might point to failing hardware or misaligned configurations. Understanding these relationships is essential for implementing targeted interventions that resolve problems effectively.
Troubleshooting Methodologies
Troubleshooting network issues requires a structured methodology that combines systematic investigation with analytical reasoning. Professionals begin by defining the scope of the problem, collecting relevant metrics, and isolating potential causes. This process involves examining network devices, application behavior, and traffic flows to determine where disruptions originate.
Once potential causes are identified, professionals apply corrective measures such as adjusting configurations, reallocating resources, or modifying traffic policies. For example, if a critical application experiences slow response times, analysis may reveal that bandwidth allocation is insufficient, necessitating traffic prioritization or protocol optimization. The ability to diagnose root causes accurately and implement precise solutions is a core competency evaluated in the 810-01 exam.
Analyzing Performance Metrics
Interpreting performance metrics is crucial for proactive troubleshooting. Professionals examine throughput, latency, jitter, and packet loss to assess network health and identify inefficiencies. These metrics provide insights into both current performance and emerging trends, enabling engineers to predict potential bottlenecks and take preventive action.
Historical analysis enhances this process by revealing patterns that may not be apparent in real-time monitoring. For instance, recurring spikes in latency during specific periods could indicate a predictable surge in application demand, guiding strategic adjustments in resource allocation or traffic management. By synthesizing historical and real-time data, professionals develop a comprehensive understanding of network behavior, enhancing their ability to maintain optimal performance.
Utilizing Riverbed Tools for Visibility
Riverbed tools, particularly SteelCentral, play a pivotal role in achieving network visibility. SteelCentral provides granular monitoring capabilities, allowing professionals to visualize traffic flows, detect anomalies, and perform in-depth analysis of performance issues. By integrating these insights with optimization strategies, candidates can implement targeted interventions that enhance both application performance and overall network efficiency.
Using SteelCentral, professionals can track application-specific metrics, monitor end-to-end transactions, and generate detailed reports that inform decision-making. This level of visibility enables the identification of underperforming links, misconfigured devices, or inefficient application interactions. Candidates are expected to leverage these insights to implement corrective measures and optimize network operations in real-world scenarios.
Proactive Troubleshooting Techniques
Proactive troubleshooting is essential for maintaining network reliability. Rather than reacting to disruptions as they occur, professionals anticipate potential issues and implement measures to mitigate them before they impact end users. This approach involves continuous monitoring, predictive analysis, and strategic interventions that address emerging problems at an early stage.
Techniques such as anomaly detection, trend analysis, and capacity forecasting enable professionals to identify deviations from normal behavior and predict areas of concern. For example, observing a gradual increase in packet retransmissions may indicate impending congestion or hardware degradation, prompting preemptive adjustments to maintain performance. By adopting proactive strategies, engineers ensure network resilience and minimize operational disruptions.
Root Cause Analysis and Resolution
Root cause analysis is a critical skill for troubleshooting complex network issues. Professionals must distinguish between symptoms and underlying causes, employing systematic investigation to identify the source of disruptions. This process often involves examining multiple layers of the network, from physical infrastructure to application-level interactions.
Once the root cause is determined, targeted interventions are implemented to resolve the issue effectively. This may include reconfiguring devices, optimizing application behavior, or adjusting traffic policies. Using Riverbed tools, professionals can validate the effectiveness of corrective measures, ensuring that the solution addresses the fundamental problem rather than merely mitigating symptoms. This competency is essential for candidates preparing for the 810-01 examination.
Integrating Analytical Thinking and Problem Solving
Troubleshooting network issues requires a combination of analytical thinking and methodical problem-solving. Professionals must dissect complex problems, evaluate multiple variables, and formulate solutions that address both immediate disruptions and long-term performance concerns. This approach involves synthesizing insights from monitoring tools, performance metrics, and operational knowledge to make informed decisions.
Analytical thinking also supports predictive troubleshooting, allowing engineers to anticipate the impact of network changes, application updates, or traffic fluctuations. By combining observation, analysis, and strategic planning, professionals can maintain high levels of service quality, ensuring that networks operate reliably and efficiently under diverse conditions.
Advanced Visibility Techniques
In complex environments, standard monitoring may be insufficient to detect subtle or intermittent issues. Advanced visibility techniques, such as deep packet inspection, flow analysis, and correlation of multi-source data, provide enhanced insight into network behavior. These methods allow professionals to uncover hidden inefficiencies, identify latent bottlenecks, and optimize performance proactively.
For example, flow analysis can reveal patterns of application usage, peak traffic periods, or sources of excessive bandwidth consumption. Deep packet inspection provides granular insight into protocol behavior and application interactions. By combining these techniques, candidates gain a comprehensive understanding of network dynamics, enabling precise troubleshooting and effective optimization.
Integration with Optimization Strategies
Network visibility and troubleshooting are closely linked to optimization and acceleration strategies. Insights gained from monitoring inform decisions about traffic shaping, protocol tuning, and resource allocation. Professionals must understand how visibility tools guide optimization efforts, ensuring that interventions are targeted, effective, and aligned with organizational objectives.
For instance, identifying a congested WAN link through monitoring may prompt adjustments to acceleration settings, prioritization of critical applications, or rerouting of traffic. The interplay between visibility and optimization enables continuous improvement of network performance, enhancing both efficiency and user experience.
Security and Compliance Considerations
While troubleshooting and monitoring focus primarily on performance, security and compliance remain integral considerations. Professionals must ensure that visibility practices adhere to organizational policies and regulatory requirements, protecting sensitive data while maintaining operational efficiency. This includes monitoring for unauthorized access, detecting anomalies indicative of security threats, and implementing corrective measures that uphold compliance standards.
Integrating security considerations into visibility practices ensures that performance optimization does not compromise data integrity or regulatory adherence. Candidates are expected to demonstrate the ability to balance these priorities, maintaining both high performance and robust security in network operations.
Importance of Security in Network Management
Security in modern network infrastructure is an essential component that complements performance, visibility, and optimization strategies. The RCPE Certified Professional Network & Infrastructure Visibility Exam evaluates a candidate’s understanding of safeguarding sensitive data, maintaining compliance with regulatory standards, and implementing best practices to prevent unauthorized access or disruptions. Professionals must integrate security considerations into all aspects of network management, from configuration and monitoring to troubleshooting and performance enhancement.
Protecting data and infrastructure requires a multifaceted approach. Access controls, authentication protocols, encryption, and monitoring systems form the foundation of a secure network environment. By ensuring that only authorized users and devices can interact with critical resources, professionals mitigate the risk of breaches and data leaks. Exam scenarios test candidates on their ability to design secure configurations, enforce policies, and respond effectively to potential threats.
Regulatory Compliance and Industry Standards
Adhering to regulatory compliance is another critical element of network security. Organizations are bound by industry regulations, corporate policies, and legal requirements that govern the handling of sensitive information, data retention, and auditing procedures. Candidates must demonstrate familiarity with frameworks that dictate security protocols, such as data protection laws, privacy regulations, and sector-specific guidelines.
Compliance extends beyond documentation; it involves practical implementation of policies and controls within the network environment. This includes ensuring encrypted transmission of sensitive data, maintaining audit trails of user activity, and performing periodic reviews of system access and permissions. By maintaining compliance, professionals protect both the organization and its clients while reducing the risk of regulatory penalties.
Implementing Security Measures
Effective security implementation encompasses a range of technical and procedural measures. Network professionals utilize firewall configurations, intrusion detection and prevention systems, secure protocols, and segmentation to protect infrastructure from internal and external threats. Segmentation, for example, isolates critical systems, reducing the potential impact of breaches or misconfigurations.
Authentication mechanisms, such as multi-factor authentication and role-based access controls, ensure that only authorized personnel can access sensitive systems. Encryption of data in transit and at rest further enhances protection, preventing unauthorized disclosure even if data is intercepted. Candidates are evaluated on their ability to configure these measures within Riverbed environments, aligning security protocols with operational efficiency.
Monitoring for Threat Detection
Monitoring is a pivotal component of maintaining security and compliance. Professionals employ continuous monitoring to detect anomalies, identify unauthorized activity, and respond proactively to potential threats. Using tools like Riverbed SteelCentral, network engineers gain granular visibility into traffic patterns, application behavior, and device interactions, enabling early detection of suspicious activity.
Real-time alerts and historical analysis provide insight into potential vulnerabilities. For instance, unusual traffic spikes, repeated failed login attempts, or unexpected application behavior may indicate a security incident or configuration anomaly. By integrating monitoring into standard network management practices, professionals ensure rapid identification and mitigation of threats before they escalate into significant disruptions.
Risk Assessment and Vulnerability Management
Conducting risk assessments and managing vulnerabilities are essential skills for network professionals. Risk assessment involves identifying potential threats, evaluating the likelihood of occurrence, and assessing the impact on operations. This process enables prioritization of resources and interventions, focusing attention on the most critical vulnerabilities.
Vulnerability management includes regular scanning, patch management, configuration reviews, and remediation of identified weaknesses. Candidates must demonstrate proficiency in using automated and manual tools to detect vulnerabilities, evaluate their severity, and implement corrective actions. Integrating these practices into daily network management ensures that systems remain resilient, secure, and compliant with established standards.
Security in Optimized and Accelerated Networks
Even in networks optimized for performance and accelerated for application responsiveness, security remains a paramount concern. Professionals must ensure that optimization techniques, such as traffic compression, caching, and protocol tuning, do not inadvertently introduce vulnerabilities or bypass security controls. Maintaining a balance between performance and security requires careful planning, configuration, and monitoring.
For example, while caching can improve application performance, sensitive data stored in cache must be protected from unauthorized access. Similarly, protocol optimizations should not compromise encryption or authentication mechanisms. Candidates are tested on their ability to harmonize security requirements with performance enhancement strategies, ensuring that networks remain both efficient and secure.
Incident Response and Recovery
Preparedness for security incidents is a critical aspect of network management. Professionals must develop and implement incident response plans that define procedures for identifying, containing, mitigating, and recovering from security breaches. Effective incident response minimizes downtime, reduces data loss, and maintains operational continuity.
Recovery strategies include data backup and restoration, system reconfiguration, and post-incident analysis to prevent recurrence. Candidates are expected to demonstrate familiarity with the complete lifecycle of incident management, including proactive measures, real-time response, and post-event evaluation. Integrating these practices into daily operations ensures a resilient network infrastructure capable of withstanding disruptions.
Integration of Security and Visibility Tools
Riverbed tools provide essential capabilities for integrating security with network visibility. SteelCentral, for instance, enables detailed monitoring of traffic flows, device interactions, and application behavior, allowing professionals to detect potential threats while maintaining operational efficiency. The ability to correlate security insights with performance data ensures that protective measures are both effective and minimally disruptive.
Professionals use these tools to monitor compliance with security policies, identify anomalies, and validate the effectiveness of implemented controls. By leveraging integrated visibility and security capabilities, candidates can maintain a secure and optimized network environment that aligns with organizational objectives and regulatory requirements.
Advanced Security Practices
Advanced security practices involve proactive threat hunting, predictive analytics, and adaptive security mechanisms. Proactive threat hunting identifies hidden threats before they manifest as incidents, using pattern recognition, anomaly detection, and intelligence feeds. Predictive analytics forecast potential vulnerabilities based on historical and real-time data, enabling preemptive interventions. Adaptive security mechanisms adjust protective measures dynamically in response to emerging threats, ensuring continuous resilience.
Candidates preparing for the exam must understand how to implement these advanced practices within Riverbed environments, combining analytical skills with technical proficiency to maintain a secure infrastructure.
Strategic Planning and Governance
Security and compliance also require strategic planning and governance. Professionals must align network security practices with organizational objectives, regulatory mandates, and industry standards. This includes defining policies, assigning responsibilities, and establishing oversight mechanisms to ensure consistent enforcement. Governance frameworks facilitate accountability, documentation, and continuous improvement of security practices.
Effective governance integrates with performance monitoring, optimization, and troubleshooting activities. By embedding security considerations into all aspects of network management, professionals create an environment where operational efficiency and risk mitigation coexist harmoniously. Strategic planning ensures that resources are allocated effectively, vulnerabilities are minimized, and compliance requirements are met.
Conclusion
Security and compliance are indispensable components of modern network infrastructure, ensuring that performance, visibility, and optimization efforts are supported by robust protective measures. Achieving proficiency in this domain requires a comprehensive understanding of regulatory requirements, risk assessment, incident response, and integration of security with performance tools. Professionals must apply best practices to safeguard sensitive data, maintain operational continuity, and enforce organizational policies. The RCPE Certified Professional Network & Infrastructure Visibility Exam evaluates candidates on their ability to harmonize security, compliance, and performance considerations, preparing them to manage complex networks with expertise, foresight, and resilience.
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
