
Certification: SnowPro Advanced Data Engineer
Certification Full Name: SnowPro Advanced Data Engineer
Certification Provider: Snowflake
Exam Code: SnowPro Advanced Data Engineer
Exam Name: SnowPro Advanced Data Engineer
Product Screenshots
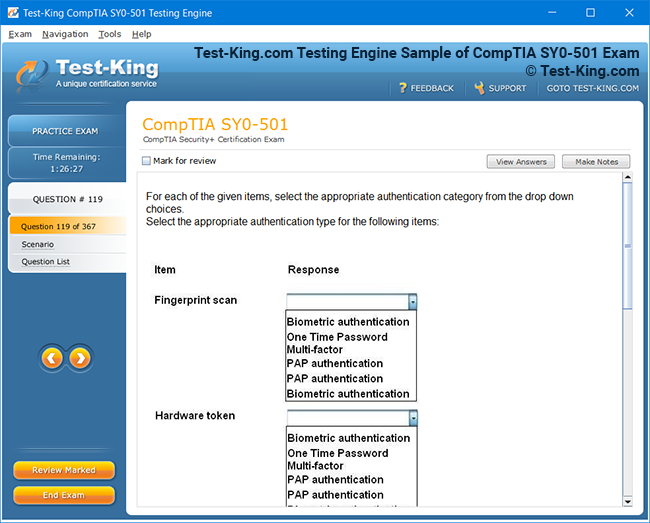
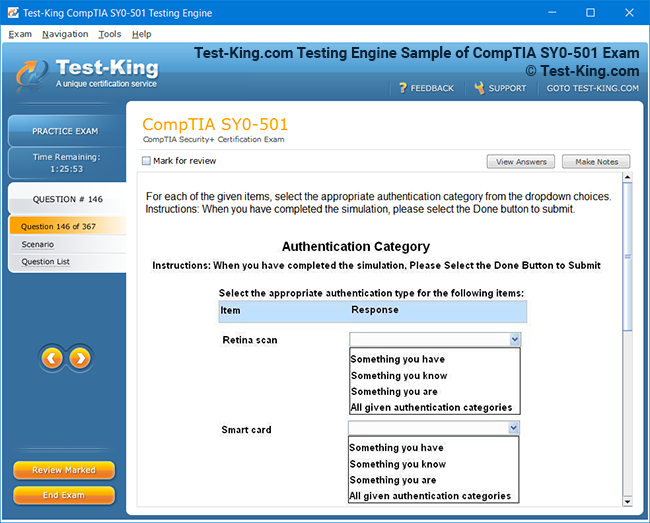
SnowPro Advanced Data Engineer Exam Preparation
The SnowPro Advanced Data Engineer Certification offered by Snowflake represents a distinguished milestone in the professional journey of data specialists who aspire to demonstrate mastery in building, optimizing, and managing intricate data solutions. Unlike foundational credentials, which validate introductory skills, this advanced recognition is specifically designed to test a deeper understanding of Snowflake’s architecture, functions, and performance engineering strategies. The nature of the exam compels candidates to engage not only with theoretical frameworks but also with pragmatic techniques that mirror real-world implementations in enterprise data landscapes.
Understanding the SnowPro Advanced Data Engineer Certification
This certification is pursued by individuals seeking to prove their expertise in domains such as query optimization, clustering, materialized views, role-based access control, Snowpipe automation, semi-structured data handling, and the orchestration of secure, high-performing data pipelines. With the data ecosystem expanding at an extraordinary rate, the ability to manage streaming data, govern access at a granular level, and scale virtual warehouses in line with demand has become indispensable. As organizations move rapidly toward cloud-native ecosystems, possessing verified competence in these areas positions professionals at the forefront of modern data engineering.
The structure of the SnowPro Advanced Data Engineer Certification is deliberately crafted to assess the candidate’s analytical acumen and decision-making ability. Instead of relying on rote memory, the exam frequently introduces scenarios that imitate authentic challenges faced by organizations. These may include determining whether multi-cluster warehouses should operate in auto-scale or maximize mode, or identifying the optimal strategy when a query profile indicates extensive partition scans. Every question is an invitation to apply knowledge in a context that demands both precision and discernment.
Registration for the examination is accomplished through Snowflake’s credential portal, where candidates can choose the most convenient option for scheduling. Pearson VUE facilitates the process, offering both on-site test centers and online proctored delivery. The online approach has become the prevailing preference due to its accessibility, but it requires meticulous preparation. The testing software known as OnVUE must be downloaded beforehand, enabling validation of system requirements such as camera clarity, microphone functionality, and network stability. This preparation should never be left for the final moment, as ensuring readiness a few days before the scheduled date significantly reduces anxiety and mitigates potential disruptions.
On the appointed day, the candidate undergoes a rigorous identity and environment verification procedure. Official identification is checked, and photographs of the testing environment must be uploaded to confirm adherence to security policies. Proctors remain vigilant throughout the duration of the exam, monitoring through both video and audio to guarantee integrity. The workspace must remain devoid of any extraneous materials such as notepads, pens, mobile phones, or even innocuous items like the cover of a pair of glasses. Any deviation from the stringent protocols may lead to termination of the session. The atmosphere is designed to replicate the sanctity of an examination hall, ensuring the legitimacy of the certification process.
The value of this certification cannot be overstated. In professional spheres, it functions as an unmistakable symbol of capability, often serving as a differentiator among candidates vying for prestigious roles. Recruiters and employers recognize the advanced credential as a reliable indication that a professional is capable of addressing complex challenges. Beyond employment, it also enhances the credibility of consultants and freelancers, enabling them to command greater trust and higher engagement from clients. In the evolving digital ecosystem where data serves as the nucleus of decision-making, the ability to harness Snowflake’s advanced features equips professionals to become indispensable contributors to organizational success.
Preparation begins with a careful study of the exam blueprint provided by Snowflake. This document lays out the domains that will be assessed and the proportion of questions that each area contributes. For example, significant emphasis is placed on clustering, streams, and query performance analysis, while complementary but equally vital areas such as Kafka connectors or Snowpark also receive attention. By assimilating this distribution, candidates can allocate their time and energy strategically, ensuring that weightier topics receive the focus they merit without neglecting the finer details that often differentiate a borderline attempt from a successful outcome.
Engagement with Snowflake’s official documentation is indispensable. The platform’s extensive knowledge base explains not only the mechanics of functions but also outlines constraints, potential pitfalls, and recommended practices. Reading about clustering strategies, for instance, illuminates how metrics such as average depth and overlaps provide insights into table performance. Yet it is not sufficient to simply absorb this knowledge passively. The true mastery lies in recreating these scenarios in a personal environment, observing how metrics evolve under varying conditions, and interpreting the implications. This hands-on familiarity provides the intuitive confidence required to answer scenario-driven questions with authority.
In addition to documentation, many aspirants find immense value in consuming supplemental resources that extend beyond the official material. Industry whitepapers, specialized blogs, and case studies bring to light how organizations have overcome specific challenges using Snowflake. A whitepaper detailing how an enterprise improved ingestion pipelines through Snowpipe automation can provide nuanced understanding of how streaming workloads behave in volatile environments. Likewise, a case study describing role-based access control implementation at scale may shed light on governance dilemmas that frequently arise in regulated industries. These narratives provide the texture of lived experiences, which are often echoed in exam questions designed to assess applied reasoning.
Communal learning plays an understated yet powerful role in the journey toward certification. Participation in forums, professional groups, or communities dedicated to Snowflake fosters the exchange of experiences, common pitfalls, and emergent strategies. It is within these conversations that subtle insights often emerge, such as the distinction between append-only and insert-only streams or the nuanced behavior of multi-cluster warehouses under specific scaling policies. While solitary study builds the foundation, collaborative discourse cements understanding and exposes blind spots that might otherwise remain unnoticed.
One of the most critical aspects of preparation lies in cultivating practical expertise. Snowflake’s features are multifaceted, and reading alone cannot substitute for the tactile experience of building, testing, and troubleshooting. Configuring a stream on a table, observing its behavior, and experimenting with downstream consumption builds intuition that reading alone cannot deliver. Similarly, analyzing query profiles under different circumstances sharpens analytical ability. When confronted with metrics indicating that all partitions have been scanned, the prepared candidate instinctively considers clustering, pruning, or micro-partition strategies to improve performance. These reflexive thought patterns are developed only through consistent practice.
The journey toward this certification also involves embracing the breadth of Snowflake’s functionality. Topics such as materialized views, semi-structured data handling, and the Kafka connector may appear peripheral at first glance, but their inclusion in the exam underscores their significance. For instance, handling semi-structured data with the variant column and lateral flatten functions represents a cornerstone capability in modern data ecosystems where JSON and similar formats dominate. Likewise, Kafka connectors embody the nexus of Snowflake with real-time data streams, and understanding how ingestion operates through internal stages, partitions, and related objects ensures preparedness for questions on integration and streaming.
Snowpark, one of Snowflake’s newer innovations, also finds a prominent place in exam preparation. Candidates must familiarize themselves with the mechanics of data frame creation, the principle of lazy evaluation, and the orchestration of Snowpark-based stored procedures. Although the documentation explains these functions in precise detail, true understanding comes from creating and executing data frames, testing transformations, and experimenting with evaluation methods. The exam frequently requires recognition of how such features align with broader architectural goals, making Snowpark knowledge not merely beneficial but essential.
Beyond the technical realm, preparation demands a deliberate mindset. The scope of content can appear overwhelming, and the temptation to skim topics is strong. Yet the very design of the exam ensures that superficial knowledge is insufficient. By framing questions around complex real-world scenarios, the assessment uncovers whether the candidate has truly internalized the concepts. Thus, a disciplined study regimen is paramount, one that balances reading, experimentation, revision, and practice exams. Simulated exams serve as both a diagnostic and a rehearsal, highlighting areas of weakness while acclimating the mind to the rhythm of timed assessments.
Another noteworthy dimension of this credential is its role in promoting best practices within organizations. Professionals who prepare thoroughly for the exam become conduits for institutional excellence, guiding teams away from suboptimal habits. For example, learning that it is not advisable to use the accountadmin role for creating databases and schemas becomes more than an exam answer; it transforms into a principle that prevents governance issues within enterprise environments. Similarly, understanding managed access schemas contributes to building more secure and sustainable data architectures.
In essence, the SnowPro Advanced Data Engineer Certification is not a mere accolade but an affirmation of deep-seated capability. The process of preparation, though demanding, cultivates a holistic understanding of Snowflake’s advanced functionalities and their application in complex contexts. Every hour spent analyzing clustering metrics, configuring Snowpipe pipelines, experimenting with role hierarchies, or interpreting query profiles contributes to a reservoir of expertise that transcends the exam itself. The knowledge acquired becomes a permanent asset, enabling professionals to excel in roles that demand technical precision, architectural foresight, and unwavering adherence to best practices.
Clustering, Streams, and Materialized Views
The journey toward mastering the SnowPro Advanced Data Engineer Certification demands a thorough understanding of some of Snowflake’s most intricate capabilities. Among the many domains tested, clustering, streams, and materialized views hold immense weight because they not only embody the sophistication of the platform but also represent areas where data engineers make architectural choices that directly affect cost, performance, and long-term maintainability of data solutions. Each of these topics can appear deceptively simple at the surface, yet they are embedded with nuances that challenge even seasoned practitioners. Grasping them in their entirety requires more than casual reading; it demands an immersion into their operational mechanics, limitations, and practical applications across real-world data landscapes.
Clustering serves as a bedrock concept within Snowflake because it governs how data is physically organized within micro-partitions. At its core, clustering is designed to improve query performance by minimizing the number of partitions scanned when executing queries. Micro-partitions in Snowflake are immutable, contiguous units of storage, and every table is automatically divided into these partitions. Without explicit clustering, Snowflake manages partitions internally, but in large-scale environments where queries filter on specific columns frequently, natural clustering may not suffice. This is where defining clustering keys becomes paramount. The exam often expects candidates to recognize when to use system functions like clustering depth and clustering information to diagnose the state of partitioning. For example, clustering depth provides an indication of how efficiently partitions are organized relative to a clustering key, while clustering information offers valuable insights into overlap and partition count. High depth values might indicate a less efficient arrangement, prompting engineers to consider re-clustering or redefining keys.
Beyond these mechanics, the exam challenges professionals to apply this knowledge contextually. Consider a scenario where an analytical workload queries a massive fact table by date and region repeatedly. Without clustering, every query could end up scanning nearly the entire table, increasing both latency and compute costs. Introducing a clustering key on date and region can drastically reduce the scanned partitions, leading to significant cost optimization. However, clustering is not a panacea. It comes with its own overhead, as maintaining clusters during insert or update operations can increase compute consumption. Thus, candidates must demonstrate not only how to implement clustering but also when it is most appropriate, balancing performance gains against resource usage.
Streams represent another powerful feature central to Snowflake’s architecture, particularly in scenarios where near real-time data ingestion and change tracking are required. A stream essentially provides a changelog of data modifications—insertions, updates, and deletions—that occur on a source object such as a table. This enables engineers to design pipelines where downstream processes can consume only the incremental changes instead of repeatedly processing entire datasets. The exam requires deep familiarity with the various types of streams available, including standard streams, append-only streams, and insert-only streams. Each variant offers distinct advantages depending on the use case.
In practical application, a standard stream records all changes including inserts, updates, and deletes, making it suitable for complex change data capture scenarios. An append-only stream, by contrast, records only new rows added to a table, which is often used in scenarios where updates or deletes are irrelevant. Insert-only streams further narrow this by tracking only inserted rows and ignoring other modifications entirely. These differences might appear subtle, but they have profound implications when designing pipelines. For instance, a pipeline responsible solely for handling new log entries could be more efficient with an append-only stream, avoiding the overhead of tracking updates or deletes that never occur.
An additional dimension of streams lies in understanding their applicability to different objects. While most often associated with tables, streams can also be applied to views, expanding their utility in complex architectures. However, their behavior is subject to certain restrictions, and being aware of these is critical. In an exam scenario, a candidate may be asked to determine the feasibility of applying a stream to a specific type of object, and only those familiar with the constraints will answer correctly. Furthermore, streams are ephemeral by nature; if not consumed properly, their data can be lost. This requires thoughtful pipeline design to ensure that every incremental change is captured and processed before it expires.
Materialized views form the third critical pillar in this domain. These constructs are designed to store the results of a query physically, enabling faster access and reducing repetitive computation. Unlike regular views, which execute their underlying query every time they are accessed, a materialized view stores the precomputed data, making it a powerful performance optimization tool. However, their maintenance introduces complexity, as the underlying data changes must be propagated into the view to keep it synchronized. Snowflake automates much of this maintenance, but engineers must understand the limitations and the operational considerations.
In preparing for the certification, candidates are expected to know not just how materialized views function but also the range of operations they support. For example, certain SQL clauses such as group by are permissible within materialized views, enabling aggregation-based performance gains. However, others may be restricted, and awareness of these limitations often forms the basis of exam questions. A candidate might encounter a scenario asking whether a specific operation involving order by can be embedded within a materialized view, and only those with detailed knowledge of documentation and practice will identify the correct behavior.
Another nuance lies in how materialized views interact with advanced Snowflake features such as time travel and cloning. Since time travel allows querying historical data, the interaction between it and materialized views can introduce unexpected behaviors if not properly understood. Similarly, cloning a database containing materialized views has implications for storage and maintenance that engineers must anticipate. Such intricacies are not mere academic curiosities; they directly affect how organizations optimize query performance at scale while controlling costs.
Performance optimization through materialized views is not simply about speed but also about strategic resource management. By precomputing heavy aggregations or joins, engineers can offload expensive query workloads from the warehouses, reducing the overall consumption of credits. Yet materialized views themselves consume storage and require background maintenance compute. Striking the right balance becomes an exercise in architectural foresight. For example, a materialized view on a frequently updated transactional table might create excessive maintenance costs, outweighing its benefits. Conversely, a materialized view on a large but relatively static analytical table could deliver immense efficiency gains. The certification often presents scenarios that test such judgment, requiring candidates to analyze cost-benefit tradeoffs and apply best practices accordingly.
These three domains—clustering, streams, and materialized views—are deeply interwoven with Snowflake’s philosophy of performance, efficiency, and scalability. A well-clustered table accelerates queries, a properly designed stream enables agile pipelines, and a carefully planned materialized view reduces redundant computation. Together, they form a triad that defines how modern data architectures achieve speed without compromising on cost-effectiveness.
In real-world contexts, these features seldom exist in isolation. A robust architecture might, for instance, combine streams with materialized views, enabling downstream dashboards to reflect near real-time changes with minimal latency. Similarly, clustering may enhance the efficiency of both streams and materialized views by reducing the underlying partitions scanned during maintenance or incremental refresh. Understanding these synergies is essential, and the certification expects candidates to not only identify features individually but also recognize how they complement one another.
Preparing for this part of the exam involves an iterative cycle of reading, experimenting, and reflecting. Reading the official documentation lays the foundation, experimenting with real data sets provides tactile familiarity, and reflecting on the outcomes ensures that knowledge is internalized rather than superficially memorized. Candidates are advised to construct practice environments where they can repeatedly test clustering strategies, build and consume streams under different workloads, and evaluate the performance impact of materialized views. Only through such immersive practice can one develop the intuition required to handle the scenario-based questions that characterize the certification.
Additionally, aspirants benefit from studying how enterprises leverage these features in production. Case studies abound in the data community, illustrating how global organizations improved query performance through clustering or reduced pipeline latency through streams. Such narratives provide a broader perspective, demonstrating that the knowledge acquired for the exam translates directly into professional competence. They also expose subtleties that might not be immediately evident in documentation, such as the real cost implications of re-clustering massive tables or the intricacies of maintaining materialized views in rapidly evolving datasets.
Ultimately, clustering, streams, and materialized views embody the ethos of Snowflake’s design—simplicity on the surface, but immense depth for those willing to explore. For the professional preparing for the SnowPro Advanced Data Engineer Certification, mastering these concepts represents both a challenge and an opportunity. It is a challenge because the concepts demand a thorough, hands-on exploration, and it is an opportunity because proficiency in these areas elevates a professional into the ranks of those capable of architecting truly high-performing, scalable, and cost-efficient data ecosystems.
Snowpipe, Virtual Warehouses, and Role-Based Access Control
Among the multifaceted subjects tested in the SnowPro Advanced Data Engineer Certification, few areas carry as much weight and practical significance as Snowpipe, virtual warehouses, and role-based access control. These capabilities together define how data is ingested, processed, and governed within Snowflake, and mastery over them demonstrates a professional’s ability to design architectures that are both efficient and secure. While these topics may appear distinct, in reality they form an interconnected web of features that are indispensable in constructing reliable and scalable data ecosystems. Understanding them requires not only an appreciation of their individual characteristics but also insight into how they converge in solving real-world engineering challenges.
Snowpipe is often introduced as Snowflake’s managed service for continuous data ingestion, yet its influence extends beyond simple data loading. The philosophy behind Snowpipe lies in enabling near real-time or micro-batch processing of data streams without the administrative burden traditionally associated with such systems. Instead of requiring engineers to manually schedule batch jobs or manage complex orchestration frameworks, Snowpipe automates the process by monitoring staging areas and loading files as they arrive. This mechanism dramatically reduces the latency between data generation and availability for analysis, creating an environment where dashboards, applications, and decision-making systems reflect the most current state of information.
A critical element of Snowpipe lies in understanding its behavior under different conditions. In practice, data engineers encounter scenarios where ingestion pipelines need to recover gracefully from interruptions. Exam questions frequently probe awareness of how pipelines can be restarted, how to identify when a pipe has become stale, and what diagnostic steps can reveal its status. The service provides load history and status details that offer transparency into its functioning, and candidates must be able to interpret these signals accurately. A pipe might report success, partial failure, or a stalled state, and recognizing the implications of each is essential. Misinterpreting these statuses could lead to data loss or duplication, which in production systems can have cascading consequences.
Another aspect of Snowpipe that demands attention is its integration with external cloud storage systems. Whether loading from Amazon S3, Azure Blob Storage, or Google Cloud Storage, Snowpipe provides connectors that continuously monitor and trigger ingestion events. Exam preparation involves understanding not only how these connectors operate but also the security and cost considerations attached to them. For instance, every file load incurs compute costs, and improperly designed ingestion workflows may result in fragmented micro-batches that unnecessarily inflate credit usage. Thus, optimization of file sizes, staging patterns, and trigger mechanisms becomes part of the data engineer’s toolkit.
Equally important is recognizing Snowpipe’s limitations. While it is highly effective for near real-time ingestion, it is not designed for ultra-low-latency streaming at millisecond levels. Professionals must be able to discern when Snowpipe is suitable and when alternative approaches are necessary. In an exam scenario, candidates may be asked to evaluate whether Snowpipe suffices for a financial trading system requiring second-by-second updates, or whether a different ingestion paradigm should be considered. Only those with nuanced understanding will select the appropriate strategy.
Virtual warehouses represent another core concept that defines how Snowflake executes queries and manages compute resources. Unlike traditional systems where compute and storage are tightly coupled, Snowflake separates them, enabling independent scaling. Virtual warehouses embody the compute layer, responsible for processing queries, performing transformations, and executing all computational workloads. Their configurability and elasticity grant Snowflake its renowned flexibility, but with that flexibility comes the responsibility to choose wisely.
Candidates for the certification must thoroughly understand the distinction between single-cluster and multi-cluster warehouses. A single-cluster warehouse suffices for predictable workloads where concurrency is low, but when multiple users or processes submit queries simultaneously, contention may arise. This is where multi-cluster warehouses shine, as they allow scaling out horizontally to accommodate concurrent demands. However, the ability to scale introduces further considerations, such as the choice between auto-scale mode and maximize mode. Auto-scale mode dynamically adjusts the number of clusters based on workload demand, conserving credits by scaling down during idle times. Maximize mode, on the other hand, keeps all clusters active, ensuring consistent performance but at higher cost. The exam often presents scenarios requiring candidates to recommend the appropriate configuration, weighing performance requirements against fiscal responsibility.
Scaling policies also form part of this subject area. Standard and economy scaling policies dictate how quickly warehouses respond to spikes in demand. The standard policy prioritizes responsiveness, adding clusters quickly to handle surges, while the economy policy is more conservative, reducing costs by delaying scale-out. In environments where latency is critical, standard scaling might be chosen, but in cost-sensitive workloads, economy scaling could be preferable. Candidates are expected to understand these subtleties and apply them contextually.
Another intricate dimension of virtual warehouses lies in their resource usage and optimization. Exam scenarios often probe knowledge of how warehouses cache results, how they suspend and resume to conserve credits, and how size impacts performance. Choosing an oversized warehouse may result in wasted resources, while undersizing could cause queries to spill to disk, reducing efficiency. Engineers must therefore balance warehouse size with workload characteristics, ensuring that resources are aligned with actual needs. Spilling, bytes scanned, and memory utilization are common indicators that require analysis to fine-tune configurations.
Moving into governance, role-based access control (RBAC) forms the foundation of Snowflake’s security framework. Unlike simplistic access systems, RBAC in Snowflake provides a granular and hierarchical model that aligns with enterprise governance standards. At the heart of RBAC is the principle that access should be granted to roles rather than directly to users, with users then assigned to roles. This abstraction not only simplifies administration but also enforces separation of duties.
Aspirants preparing for the certification must understand advanced concepts such as role inheritance and managed access schemas. Role inheritance enables a role to acquire privileges from another role, forming a hierarchy that mirrors organizational structures. This hierarchy allows for efficient administration, as granting a privilege to a higher-level role automatically cascades to its child roles. Managed access schemas add another layer of governance by ensuring that only schema owners can modify grants, centralizing control and preventing accidental privilege escalations.
Equally vital is knowledge of system-defined roles within Snowflake, such as accountadmin, sysadmin, and securityadmin. Each serves a specific purpose, and best practices dictate careful usage. For instance, creating databases or schemas using the accountadmin role is discouraged because it conflates governance responsibilities with operational tasks. Instead, lower-level roles should handle object creation while higher-level roles oversee governance. Exam questions often challenge candidates to identify violations of best practices, ensuring that they not only understand how to configure RBAC but also why certain patterns are preferable.
RBAC also intersects with compliance and regulatory requirements. Industries such as healthcare and finance impose stringent rules regarding data access, and Snowflake’s RBAC model equips organizations to meet these mandates. By assigning roles aligned with job responsibilities, data engineers can enforce principles of least privilege, ensuring that individuals access only the data necessary for their functions. The exam reflects this reality by presenting governance scenarios that mirror real compliance challenges, requiring candidates to apply RBAC concepts to solve them.
When considering Snowpipe, virtual warehouses, and RBAC together, it becomes clear how deeply they interconnect in building holistic solutions. A pipeline may use Snowpipe to ingest data continuously, a virtual warehouse to process and transform the ingested records, and RBAC to secure access to both the pipeline and the resulting datasets. Neglecting any one of these elements compromises the integrity of the entire architecture. For example, efficient ingestion through Snowpipe loses its value if warehouses are poorly sized and queries underperform, or if improper RBAC configurations expose sensitive data to unauthorized users. The exam therefore emphasizes not just individual knowledge but the ability to integrate these features cohesively.
Preparation for this portion of the certification requires a multi-pronged approach. Documentation remains the authoritative source, explaining every nuance of Snowpipe’s load history, warehouse scaling policies, and RBAC best practices. However, practical experimentation is irreplaceable. Candidates are advised to simulate ingestion pipelines, observe how Snowpipe behaves under stress, adjust warehouse configurations to handle varying workloads, and test role hierarchies to confirm expected behavior. These exercises cultivate not only understanding but also the instinctive decision-making that scenario-based questions demand.
Peer learning further enhances preparation, as discussions with colleagues or community members often surface overlooked insights. For instance, engineers who have operated Snowpipe pipelines in production may share hard-earned lessons about error recovery or cost optimization. Similarly, practitioners with deep governance experience may highlight subtle pitfalls in RBAC implementations that are not immediately obvious from documentation. Such exchanges provide perspective and depth, reinforcing knowledge in ways solitary study cannot achieve.
Real-world case studies also illuminate the practical significance of these features. Enterprises that have adopted Snowpipe frequently report drastic reductions in latency for their data pipelines, enabling analytics that were previously impossible with traditional batch systems. Organizations that leverage virtual warehouses effectively often highlight both performance improvements and cost savings achieved through judicious scaling policies. Those that implement RBAC rigorously demonstrate how governance not only satisfies compliance but also enhances operational efficiency by reducing administrative complexity. These narratives confirm that the knowledge tested in the certification translates directly into tangible benefits in the professional arena.
The convergence of Snowpipe, virtual warehouses, and RBAC epitomizes the essence of advanced data engineering on Snowflake. Each represents a critical dimension of a broader architectural puzzle—ingestion, computation, and governance. Mastering them equips professionals with the ability to design systems that are not only functional but also elegant, efficient, and secure. In the crucible of the exam, candidates who internalize these concepts and can apply them with dexterity distinguish themselves as true experts in the art of modern data engineering.
Query Profiling, Kafka Connector, and Semi-Structured Data Handling
Among the themes explored in the SnowPro Advanced Data Engineer Certification, query profiling, Kafka integration, and semi-structured data processing stand out as decisive aspects that showcase both analytical depth and technical agility. These areas together represent the capacity to optimize workloads, manage ingestion from dynamic data sources, and harness the potential of unstructured and nested formats in a disciplined way. Each topic on its own requires attention to detail, but the true measure of proficiency lies in comprehending how they intersect within the broader Snowflake ecosystem.
Query profiling is more than a diagnostic tool; it is a window into the invisible mechanics of query execution. Snowflake provides a visual and textual breakdown of how queries traverse partitions, consume compute cycles, and leverage caching. The examination frequently evaluates how well candidates interpret these details, because they form the bedrock of optimization. For example, a profile might reveal that a query scans all available partitions instead of a subset, indicating that pruning has failed. In such cases, professionals must discern whether the issue lies in clustering design, filtering logic, or indexing strategies. Another recurring theme is spilling, where operations exceed memory capacity and overflow to disk, slowing performance. Candidates must not only recognize this symptom but also propose remedies such as adjusting warehouse size, revising query patterns, or optimizing joins.
Equally central to profiling is the comprehension of bytes scanned and the implications for efficiency. A query that processes vast amounts of unnecessary data suggests poor partitioning or imprecise predicates. In contrast, a well-tuned query minimizes scans, focusing compute on the most relevant slices of data. The ability to distinguish between these scenarios, and to propose targeted improvements, reflects mastery of the art of performance engineering. Exam questions often present a profile screenshot and ask what steps should be taken to reduce execution time, requiring not rote memorization but analytical reasoning that comes only from extensive exposure to query patterns and optimization practices.
Another aspect of query profiling involves understanding execution stages. Each query breaks down into discrete tasks such as scanning, joining, aggregating, and returning results. By examining the time consumed at each stage, engineers can identify bottlenecks. For instance, a disproportionate amount of time spent in aggregation may suggest opportunities for materialized views or pre-computed summaries. Similarly, excessive join costs may indicate a need for denormalization or revised schema design. Query profiling thus transcends individual query tuning; it informs architectural decisions about schema layout, clustering strategy, and workload management.
Turning to Kafka connector integration, one enters the realm of streaming ingestion and high-velocity pipelines. Kafka has become ubiquitous as a backbone for real-time data transport, and Snowflake’s Kafka connector enables seamless delivery of these streams into Snowflake tables. For the exam, understanding the mechanics of this connector is indispensable. Candidates must know what objects are required for ingestion, such as stages, pipes, and topics, and how they interact. The Kafka connector operates by capturing messages from Kafka partitions and writing them into Snowflake in a structured and reliable manner.
Practical challenges often revolve around partitioning. Kafka divides streams into partitions for scalability, and the connector must handle these partitions gracefully. A candidate may be asked to explain how the connector ensures ordering within a partition but not across partitions, and what implications this has for downstream queries. Internal stages also play a vital role, serving as transient storage for messages before they are ingested. Mastery of this workflow requires recognizing not only its normal behavior but also its failure modes. What happens if a connector loses connectivity? How does it recover? How are offsets managed to ensure exactly-once or at-least-once delivery semantics? These are the kinds of subtleties that transform surface-level knowledge into genuine expertise.
Another element of Kafka connector proficiency involves resource considerations. Streaming ingestion is continuous, and the cost of maintaining active pipelines can accumulate quickly. Engineers must balance the desire for low-latency ingestion with the realities of credit consumption. Tuning batch sizes, monitoring throughput, and designing schemas to accommodate variable data volumes all fall within the responsibilities of a data engineer. In the certification context, candidates are expected to understand these trade-offs and select appropriate strategies for different business scenarios.
Semi-structured data handling in Snowflake constitutes yet another pivotal domain. Modern data rarely conforms neatly to relational tables; instead, it arrives as JSON, Avro, Parquet, or other nested formats. Snowflake distinguishes itself by offering native support for these structures, primarily through the VARIANT data type. This flexibility allows engineers to store raw semi-structured data without rigid schema definition, while still querying it with standard SQL. However, the exam requires more than a cursory awareness of these capabilities; it demands fluency in manipulating semi-structured data efficiently.
One of the most critical techniques is the use of lateral flatten. This function unpacks nested arrays or objects within a VARIANT column, transforming them into relational views that can be queried directly. For example, a deeply nested JSON file representing customer transactions may contain arrays of line items. Flattening enables each line item to be extracted and analyzed independently, aligning the data with analytical requirements. Candidates must be able to visualize this transformation process and understand its implications for performance and schema design.
Querying semi-structured data also entails mastering path notation, where specific attributes are accessed through dotted syntax. While conceptually straightforward, the challenge arises in ensuring accuracy when navigating deeply nested hierarchies. Missteps in notation can result in null values or overlooked fields, undermining the analysis. The exam frequently incorporates scenario-based questions where candidates must extract precise values from intricate JSON documents, testing both technical syntax knowledge and logical acuity.
Beyond querying, performance considerations remain paramount. Semi-structured data is flexible but can be costly to process if not managed wisely. Engineers must understand when to retain data in its raw VARIANT form and when to transform it into relational tables for efficiency. For instance, fields that are frequently queried may be extracted into dedicated columns, enabling pruning and indexing, while less-used fields remain in the VARIANT payload. This hybrid approach balances flexibility with performance, and candidates must recognize scenarios where such strategies are advantageous.
An often-overlooked dimension of semi-structured data handling is schema evolution. Unlike rigid relational models, JSON and similar formats evolve over time as new attributes are added or existing ones change. Snowflake accommodates this variability gracefully, but engineers must still anticipate the consequences. Queries written against older structures may fail or return incomplete results if they do not account for newly introduced fields. The certification exam may pose questions that require reasoning through such scenarios, asking how to design resilient queries that adapt to evolving data.
The convergence of query profiling, Kafka ingestion, and semi-structured data processing creates a tapestry of skills that defines advanced data engineering competence. Consider a real-world example: a company ingests customer interaction logs from Kafka, each message formatted as JSON. Snowpipe or the Kafka connector continuously loads these records into Snowflake, where they are stored as VARIANT columns. Engineers then query the data, flattening arrays of actions, extracting specific fields, and joining them with relational customer tables. Meanwhile, query profiles reveal performance bottlenecks, guiding adjustments to warehouse sizing, clustering strategies, or query logic. Simultaneously, RBAC ensures that only authorized roles can access sensitive portions of the logs, preserving compliance. This holistic workflow exemplifies the scenarios that certification candidates must be prepared to navigate.
Preparation for these topics involves immersing oneself in Snowflake documentation and practicing extensively with live datasets. For query profiling, running complex queries and analyzing their execution plans provides practical familiarity with the indicators Snowflake exposes. For Kafka connectors, setting up test environments with simulated streams offers hands-on understanding of ingestion pipelines and their quirks. For semi-structured data, working with diverse JSON files cultivates comfort with path expressions, flattening, and schema evolution. These experiences not only reinforce knowledge but also cultivate the confidence to handle unpredictable exam scenarios.
The journey through query profiling, Kafka connector integration, and semi-structured data management is both demanding and rewarding. It equips professionals with the ability to interrogate system performance, manage high-velocity data pipelines, and tame the unruly world of nested formats. Together, these capabilities form a triad of expertise that reflects the essence of modern data engineering in Snowflake.
Snowpark, Bulk Loading, Copy Into, Data Sharing, and Advanced Features
Snowpark, bulk loading, copy into constructs, data sharing, and advanced services like user-defined functions, table functions, and search optimization represent the culminating domains of expertise for the SnowPro Advanced Data Engineer Certification. Together, they embody Snowflake’s ambition to unify programming, scalability, and collaboration under one coherent platform. Candidates preparing for this exam must not only memorize definitions or recall isolated functionalities but also cultivate a profound comprehension of how these tools integrate into practical data engineering landscapes. Each concept is vast in its own right, but in combination, they illustrate the elasticity and power of Snowflake as a data cloud.
Snowpark introduces a paradigm shift for data engineers by extending the realm of programming directly into the Snowflake environment. Traditionally, manipulation of data within a warehouse was restricted to SQL, but Snowpark allows developers to build data pipelines and transformations using familiar languages such as Java, Scala, and Python. This means developers can use established programming ecosystems while still benefiting from Snowflake’s scalability and security. The concept of lazy evaluation is central to Snowpark, where computations are not immediately executed but instead defined as logical plans. This design ensures that execution happens only when results are required, allowing the query optimizer to apply the most efficient strategy. In practical use, this approach minimizes unnecessary processing and enables highly complex pipelines to run efficiently. Candidates must understand the nuances of Snowpark methods available for DataFrame creation, the distinctions between transformations and actions, and the methods for invoking Snowpark-based stored procedures. For certification purposes, mastery of these principles demonstrates an ability to handle not only SQL-driven workloads but also code-driven workflows that operate seamlessly in the same environment.
Bulk loading forms another cornerstone of Snowflake expertise. While Snowpipe provides near real-time ingestion, bulk loading is the preferred method for moving massive historical or batched datasets into Snowflake. It relies heavily on staged files, whether in internal storage or external cloud platforms. Candidates are expected to know how to orchestrate large-scale imports, manage file formats, and optimize performance for terabytes or petabytes of data. The distinction between continuous ingestion and high-volume loading is critical, as each use case demands a different design. For example, an organization migrating decades of archived data into Snowflake would choose bulk loading for its efficiency in processing large static files. The exam will often probe understanding of how to maximize throughput, how to split large files into smaller chunks for parallelization, and how to configure warehouses to avoid bottlenecks during ingestion.
The copy into command is at the heart of both bulk loading and unloading. This construct instructs Snowflake to transfer data between staged files and Snowflake tables, or vice versa. It offers a level of control unmatched by automated tools, enabling engineers to define file formats, specify error handling, and direct data into structured destinations. For exam preparation, candidates must grasp the subtle distinctions between copy into table and copy into location, where the former ingests external data into Snowflake and the latter exports Snowflake data back to storage. Understanding the role of parameters such as validation mode, error limits, and parallel execution allows candidates to demonstrate refined control over ingestion. Since real-world scenarios often involve imperfect data, the ability to configure copy into for resilience against malformed files or incomplete rows reflects professional-grade mastery.
Data sharing introduces a dimension of collaboration that transcends organizational silos. Snowflake’s secure data sharing mechanism enables enterprises to exchange live, queryable data sets without moving or duplicating files. This model eliminates the inefficiencies of data transfers, ensuring that recipients always access the most current version of a dataset. In certification contexts, candidates may be asked to design or evaluate data sharing architectures involving providers, consumers, and reader accounts. Providers make specific objects available, while consumers access them in their own Snowflake environments. Reader accounts extend this paradigm further by allowing sharing with entities that do not maintain their own Snowflake instance. Exam questions in this domain often challenge candidates to balance governance with accessibility, requiring careful application of role-based access control within the data sharing model. For instance, only authorized roles should be able to expose or consume shared data, ensuring compliance and security.
In parallel, the concept of search optimization service exemplifies Snowflake’s push toward performance excellence. Traditional data systems often rely on indexing to accelerate queries on specific columns, but Snowflake employs a more adaptive approach. Search optimization service creates specialized metadata that enables faster retrieval of selective queries, particularly those that filter by high-cardinality attributes. Professionals preparing for certification must know when to activate this service, since it incurs additional cost but yields dramatic improvements in retrieval times for targeted workloads. Questions may involve identifying workloads that benefit most, such as queries filtering billions of rows by unique identifiers or transactional keys. This domain emphasizes not only technical understanding but also economic judgment in determining where optimization justifies its expense.
The realm of user-defined functions and table functions further expands Snowflake’s flexibility. User-defined functions allow engineers to encapsulate custom logic in reusable components, extending the native SQL syntax with tailored behavior. These can be scalar functions returning single values, or table functions returning result sets that can be joined with other tables. Advanced engineers must appreciate not only how to build these objects but also how to manage their security, performance, and lifecycle. Certification candidates may encounter scenarios asking how to implement specialized transformations unavailable in built-in SQL, requiring the application of UDFs or UDTFs. The critical skill lies in knowing when to employ them and how to safeguard against inefficiencies such as unnecessary complexity or lack of optimization.
Snowflake’s approach to data sharing also intersects with governance. As organizations increasingly rely on cross-enterprise collaboration, maintaining compliance with regulations such as GDPR or HIPAA becomes paramount. Engineers must design data sharing models that restrict sensitive fields, apply role hierarchies judiciously, and ensure that only permissible attributes flow across boundaries. This is not a mere technical exercise; it embodies the principle of responsible data stewardship. Candidates should be prepared to apply this reasoning to exam scenarios where compliance obligations frame the permissible architecture of sharing solutions.
When these domains are considered together, they present a vision of Snowflake as not merely a data warehouse but as a living, breathing ecosystem capable of ingesting, transforming, optimizing, and sharing data at scale. A pipeline might begin with bulk loading of historical records via copy into, continue with real-time enrichment using Snowpark transformations, and culminate in live sharing of curated datasets with partners through secure mechanisms. Along the way, performance bottlenecks are alleviated with search optimization, and specialized business rules are encoded into user-defined functions. This integrated workflow exemplifies the holistic mastery that the certification seeks to evaluate.
In practice, Snowpark enables data engineers to unify code and SQL within a single environment, bulk loading provides the muscle to ingest massive archives, copy into supplies precise control, data sharing ensures collaborative fluidity, and advanced optimization services refine performance for selective queries. Together, they form a toolkit that equips modern professionals to confront the complexity of data engineering challenges across industries. The certification exam does not treat these as isolated features; instead, it tests how adeptly candidates can orchestrate them into seamless architectures that balance performance, cost, security, and flexibility.
Conclusion
SnowPro Advanced Data Engineer Certification represents more than a credential; it signifies a professional’s ability to harness Snowflake’s ecosystem with precision and creativity. Mastery of Snowpark demonstrates proficiency in extending programming paradigms into the warehouse, while bulk loading and copy into constructs exhibit control over large-scale data movement. Data sharing reflects a commitment to collaboration and governance, while services like user-defined functions and search optimization reveal the engineer’s ability to tailor and refine performance. Together, these elements represent the frontier of modern data engineering, where pipelines are no longer mere conveyors of information but carefully designed systems that transform raw inputs into accessible, optimized, and shareable insights. By internalizing these concepts, candidates not only prepare themselves to succeed in the certification exam but also position themselves as practitioners capable of shaping the future of data-driven enterprises.
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Top Snowflake Exams
- SnowPro Core - SnowPro Core
- SnowPro Advanced Architect - SnowPro Advanced Architect
- SnowPro Specialty Gen AI GES-C01 - SnowPro Specialty Gen AI GES-C01
- SnowPro Core COF-C03 - SnowPro Core COF-C03
- SnowPro Advanced Data Engineer - SnowPro Advanced Data Engineer
- SnowPro Advanced Data Scientist - SnowPro Advanced Data Scientist DSA-C03
- SnowPro Advanced Administrator - SnowPro Advanced Administrator ADA-C01
- SnowPro Advanced Administrator ADA-C02 - SnowPro Advanced Administrator ADA-C02
- SnowPro Core Recertification - SnowPro Core Recertification (COF-R02)
