
Exam Code: SPLK-1004
Exam Name: Splunk Core Certified Advanced Power User
Certification Provider: Splunk
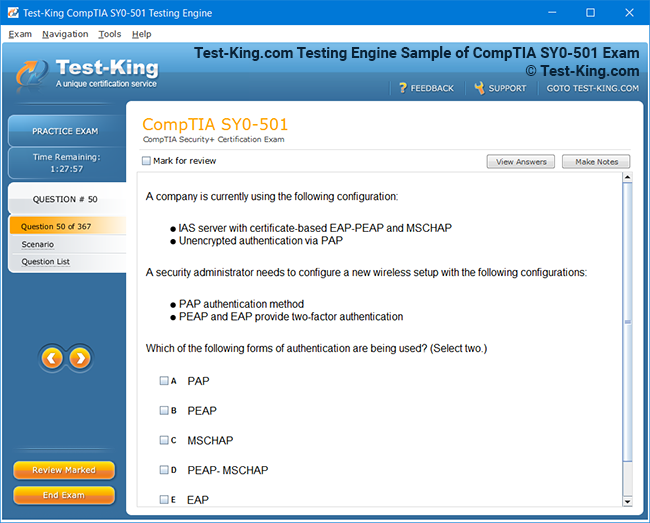
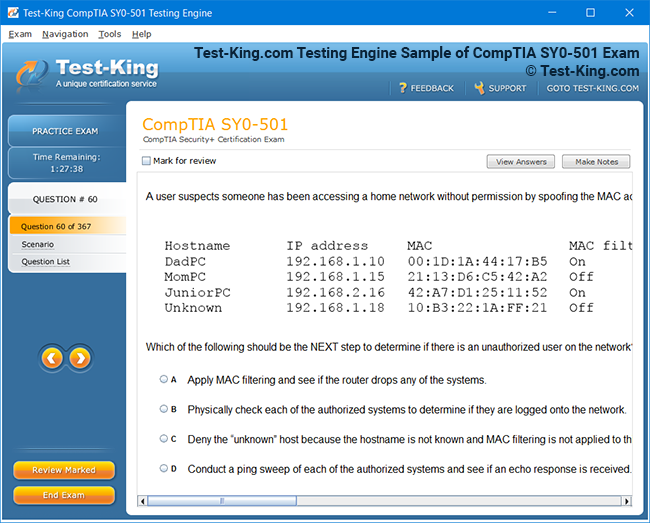
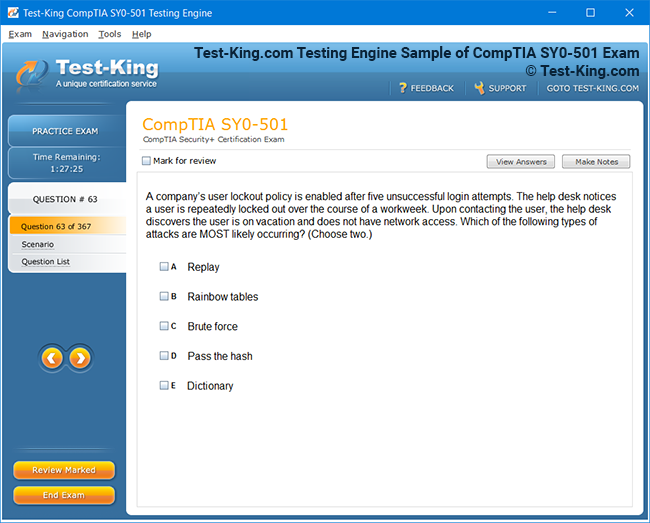
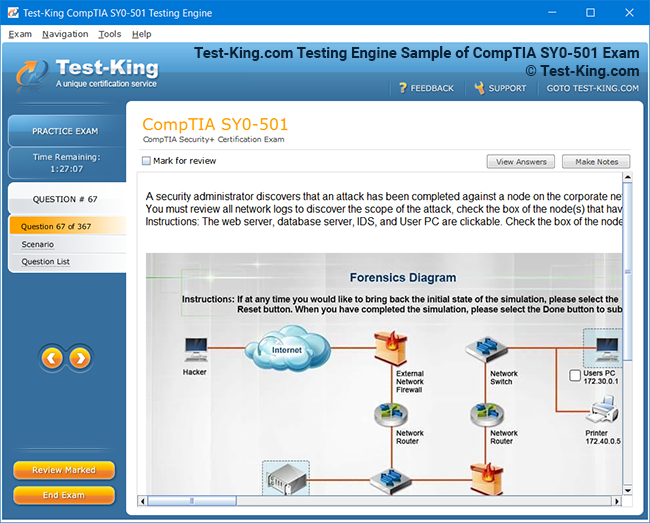
Product Screenshots
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Top Splunk Exams
- SPLK-1002 - Splunk Core Certified Power User
- SPLK-1003 - Splunk Enterprise Certified Admin
- SPLK-1001 - Splunk Core Certified User
- SPLK-3003 - Splunk Core Certified Consultant
- SPLK-1005 - Splunk Cloud Certified Admin
- SPLK-2002 - Splunk Enterprise Certified Architect
- SPLK-3001 - Splunk Enterprise Security Certified Admin
- SPLK-5001 - Splunk Certified Cybersecurity Defense Analyst
- SPLK-5002 - Splunk Certified Cybersecurity Defense Engineer
- SPLK-1004 - Splunk Core Certified Advanced Power User
- SPLK-3002 - Splunk IT Service Intelligence Certified Admin
- SPLK-4001 - Splunk O11y Cloud Certified Metrics User
- SPLK-2003 - Splunk SOAR Certified Automation Developer
SPLK-1004 : Common Mistakes to Avoid on the Splunk Core Certified Advanced Power User Exam
One of the most pervasive errors that candidates make when preparing for the Splunk Core Certified Advanced Power User exam is misinterpreting the exam objectives and underestimating the syllabus. Many aspirants rely on cursory overviews or outdated study guides, assuming they are sufficient for adequate preparation. This superficial approach often leads to a fragmented understanding of crucial concepts, particularly in areas such as field extractions, transaction commands, event correlation, and workflow actions. The exam is structured not merely to test rote memorization but to evaluate an individual’s capacity to apply Splunk functionalities to complex, real-world scenarios. Consequently, overlooking even seemingly minor sections of the syllabus can result in significant loss of points.
Misinterpreting Exam Objectives and Syllabus
Candidates frequently devote disproportionate time to basic search commands or dashboard creation, thinking that these are the most critical areas of study. While familiarity with basic commands is essential, the SPLK-1004 exam emphasizes a deeper comprehension of the search processing language and optimization techniques for complex searches. Candidates who fail to fully grasp these advanced concepts often find themselves unprepared for scenario-based questions that require analytical reasoning. Developing a comprehensive and methodical study plan aligned with the official exam blueprint is essential to avoid this pitfall. Regularly revisiting the objectives ensures that preparation remains focused and prevents the last-minute panic that often arises from neglected topics.
Another subtle but significant mistake involves ignoring updates to Splunk’s functionalities. The platform frequently integrates new commands and features, which may not be reflected in older study materials. Aspirants who rely exclusively on secondary resources risk learning outdated methodologies that are no longer applicable. Engaging with official Splunk documentation, community forums, and webinars can provide insights into the latest features and less commonly discussed functionalities. These updates often include rare commands, advanced search modifiers, and optimization techniques that can make the difference between a mediocre and an exceptional performance on the exam.
Understanding exam weighting is another area where candidates frequently falter. Certain sections of the SPLK-1004 exam carry more influence on the overall score, such as knowledge objects, data models, and pivot reports. Focusing too much on familiar or easier areas while neglecting higher-weight topics creates an imbalanced study strategy that can jeopardize performance. Effective preparation involves allocating time and effort proportionally to the significance of each topic, ensuring that high-impact areas receive adequate attention. This approach also allows for repeated practice in complex areas, building the dexterity required for scenario-based problem solving.
A common trap that many examinees fall into is over-reliance on memorization. While remembering commands and workflows may seem advantageous, the SPLK-1004 exam prioritizes analytical thinking and practical application. Candidates who memorize procedures without understanding the underlying logic often struggle when confronted with questions that present unfamiliar combinations of challenges. It is imperative to engage with hands-on exercises and simulated scenarios, which cultivate not only procedural knowledge but also the agility to manipulate Splunk functionalities in dynamic contexts. These exercises reinforce comprehension and expose gaps in understanding that might otherwise remain hidden.
Time mismanagement during preparation is closely related to misinterpreting the syllabus. Some candidates spend excessive periods revisiting basic topics or repeatedly practicing familiar commands while neglecting advanced concepts such as data normalization, event correlation, and workflow orchestration. This inefficient allocation of study time can result in shallow preparation, leaving candidates ill-equipped for complex exam scenarios. Creating a structured study schedule that emphasizes both depth and breadth is crucial, allowing for targeted review of weaker areas without neglecting overall coverage.
The intricacies of field extractions and knowledge objects represent another area where aspirants frequently err. Misunderstanding the nuances of regular expressions, field aliases, calculated fields, and event types can lead to errors not only in the exam but also in practical applications. Candidates often underestimate the cognitive load required to master these concepts and attempt to shortcut their learning through memorization rather than comprehension. Engaging with practical examples and exploring multiple approaches to field extraction cultivates flexibility in problem solving, an invaluable skill during the exam.
Another overlooked challenge is grasping the complexities of transaction commands and event correlation. Many candidates focus on isolated commands without appreciating their interactions in multifaceted scenarios. For instance, correctly configuring a transaction command requires understanding event ordering, grouping criteria, and performance considerations. Ignoring these subtleties can result in answers that are superficially correct but fail under nuanced evaluation. Practical experimentation, coupled with analytical review of results, equips candidates to navigate these intricacies effectively.
Dashboard creation and report optimization also represent frequent stumbling blocks. Candidates may understand how to generate visualizations but neglect the importance of efficiency, filtering, and contextual awareness. The exam often tests the ability to design dashboards that convey meaningful insights while minimizing resource consumption. Neglecting performance considerations or failing to implement best practices for data visualization can lead to lower scores, despite technically correct outputs. Practicing the integration of complex searches into coherent dashboards strengthens both technical proficiency and strategic thinking.
A further pitfall lies in underestimating the significance of advanced SPL functions. Functions such as stats, eval, chart, and timechart are often treated superficially, without exploring their full range of parameters and applications. Candidates may know the basic syntax but fail to comprehend how these commands interact in nested searches or when combined with other functions. This shallow understanding can impede the ability to solve scenario-based questions efficiently. Dedicating time to explore edge cases and uncommon function combinations enhances both confidence and performance.
Finally, many candidates neglect the value of continuous review and self-assessment. Sporadic study or last-minute cramming frequently leads to fragmented knowledge and lapses in understanding. Integrating periodic practice exams, scenario-based exercises, and iterative review cycles helps to consolidate learning. Self-assessment exposes weak points, reinforces retention, and builds the cognitive endurance required for a rigorous exam like SPLK-1004. Those who underestimate the necessity of sustained engagement with the material often face avoidable setbacks on the day of the exam.
Through careful attention to exam objectives, structured study planning, hands-on practice, and continuous self-assessment, candidates can mitigate the common pitfalls that have hindered many aspiring Splunk Advanced Power Users. This approach emphasizes comprehension over memorization, strategic allocation of study time, and an appreciation for the evolving nature of Splunk’s functionalities. By cultivating these habits, aspirants develop the nuanced expertise necessary to navigate complex scenarios, optimize searches, and fully leverage the capabilities tested in the exam.
Inefficient Time Management and Practice Errors
One of the most critical errors that candidates make while preparing for the Splunk Core Certified Advanced Power User exam is inefficient time management. Many aspirants dedicate a disproportionate amount of effort to topics they are already comfortable with, neglecting areas that are both challenging and carry significant weight on the exam. This imbalance in preparation can lead to a superficial understanding of advanced features, leaving gaps in the ability to execute complex searches, optimize dashboards, or manage knowledge objects effectively. A well-structured timetable that allocates time based on the relative difficulty and importance of topics is crucial to avoid this pitfall. Without it, candidates often expend energy on familiar commands and lose opportunities to master intricate concepts such as transaction grouping, event correlation, and field transformations.
Another prevalent misstep is attempting to cram large amounts of information in a short period. Splunk is a platform that demands hands-on experience and analytical thinking, not rote memorization. When learners try to accelerate their study through extended, uninterrupted sessions without proper segmentation or review cycles, retention diminishes, and stress levels escalate. This hurried approach may create the illusion of productivity while leaving critical areas insufficiently understood. Dividing study periods into manageable intervals with strategic review of weak topics allows knowledge to consolidate in long-term memory, enhancing both confidence and competence.
Over-reliance on practice exams alone is a frequent source of inefficiency. While simulated tests can provide insight into exam readiness, using them as the primary study tool without complementary practical exercises can be counterproductive. Practice exams typically emphasize familiar scenarios and do not always reflect the full spectrum of challenges in the SPLK-1004 evaluation. Candidates who depend solely on these assessments may become adept at answering patterned questions but fail to develop the adaptability required for unconventional or complex problem-solving scenarios. Integrating hands-on labs, scenario-based exercises, and exploratory tasks in addition to practice exams ensures a more comprehensive mastery of the material.
Inadequate reflection on performance during practice exercises is another common error. Some candidates treat incorrect answers as failures rather than opportunities for deeper learning. Each mistake in a practice exercise presents an avenue to uncover misunderstandings about field extractions, statistical commands, or data model navigation. By analyzing the underlying reasons for errors and exploring alternative approaches, learners cultivate the analytical acumen needed to approach unfamiliar questions with confidence. Without this reflective process, the same mistakes tend to recur, creating cycles of inefficiency and diminishing returns on study time.
Misjudging the complexity of advanced searches is another obstacle related to poor time management. Candidates often underestimate the cognitive load required to construct optimized searches that involve multiple joins, nested commands, or intricate statistical manipulations. Attempting these searches without adequate practice or understanding of performance implications can result in frustration and wasted effort. Allocating sufficient time to dissect, experiment with, and refine complex queries builds both skill and intuition, allowing candidates to approach advanced tasks with dexterity during the exam.
The management of dashboards and reports also presents a potential source of inefficiency. Many aspirants focus on producing visually appealing dashboards but neglect performance considerations, filter optimization, or the strategic presentation of data. Spending excessive time on aesthetics while overlooking functional optimization leads to shallow mastery. A more productive approach involves integrating complex searches into coherent dashboards, experimenting with time-range selectors, data pivots, and report scheduling, and evaluating the impact on system performance. This iterative method not only deepens understanding but also saves time by reinforcing principles that are applicable across multiple scenarios.
Time allocation for reviewing knowledge objects is often insufficient, despite their prominence in the exam. Understanding event types, field aliases, calculated fields, and tags requires deliberate, repetitive practice. Candidates who rush through this domain frequently fail to internalize the subtle interactions between objects, resulting in errors during scenario-based questions. Structured practice, where each knowledge object is explored through multiple use cases, cultivates cognitive flexibility and ensures that learners are prepared to apply these elements effectively under time constraints.
Another inefficiency stems from ignoring the evolution of Splunk’s features in favor of outdated strategies. Time spent mastering deprecated commands or legacy approaches is time lost. Candidates who fail to reference the latest documentation, community discussions, and release notes may find themselves underprepared for questions that test contemporary best practices. Keeping abreast of updates, exploring newly introduced commands, and experimenting with innovative techniques ensures that preparation is both current and efficient. This proactive approach reduces wasted effort spent learning antiquated methods that no longer hold relevance in practical applications or the exam.
Many candidates also underestimate the importance of scenario-based exercises that simulate real-world problems. Focusing exclusively on command syntax or dashboard creation without integrating these elements into operational workflows can produce a fragmented understanding. Scenario-based practice encourages learners to think holistically, connecting field extractions, transaction commands, event correlation, and visualization in a seamless manner. This comprehensive approach not only improves efficiency during study sessions but also mirrors the analytical thinking required to solve complex problems in the exam environment.
Time mismanagement frequently extends into the approach to continuous review. Sporadic or haphazard study sessions diminish retention and make it difficult to recognize recurring weaknesses. Effective preparation involves iterative review cycles, spaced repetition, and active recall techniques, ensuring that all critical topics, including rare commands and advanced search functions, are reinforced over time. Candidates who neglect structured repetition often find themselves revisiting the same mistakes repeatedly, expending energy without meaningful progress.
A common oversight involves ignoring the subtle interplay between search optimization and resource management. Candidates may know the syntax of advanced commands but fail to appreciate the impact of search efficiency on system performance. Without practice that includes timing searches, evaluating results, and refining queries for efficiency, learners expend excessive time running ineffective searches. Developing a habit of scrutinizing search performance alongside correctness ensures that study sessions are productive and reflective of the demands of the exam.
Additionally, many aspirants fail to integrate exploratory learning into their practice. Sticking rigidly to predetermined exercises or study guides limits exposure to uncommon scenarios or creative problem-solving opportunities. Engaging in experimental searches, testing edge cases, and exploring atypical datasets encourages a mindset of curiosity and adaptability. This type of learning not only deepens technical expertise but also optimizes the use of preparation time by reinforcing understanding through practical discovery rather than passive repetition.
An underappreciated factor in inefficient preparation is the failure to track progress systematically. Without monitoring areas of strength and weakness, candidates may misallocate time, spending too long on mastered topics while neglecting critical gaps. Implementing a detailed progress log that captures performance across knowledge objects, search functions, and scenario exercises allows for precise adjustment of study priorities. This evidence-based approach maximizes efficiency, ensuring that each hour of preparation contributes meaningfully to competence in high-weight areas.
Time inefficiency is often compounded by neglecting cognitive load management. Intensive study sessions without strategic breaks or mental recovery diminish focus and analytical acuity. Candidates may inadvertently spend extended periods on repetitive tasks with diminishing returns, leading to frustration and burnout. Scheduling intermittent review periods, alternating between theory, practical exercises, and scenario-based problem solving, preserves mental clarity and facilitates sustained, productive preparation.
Another common pitfall is focusing narrowly on passing the exam rather than internalizing knowledge for practical application. Candidates who prioritize memorization over comprehension often encounter difficulties when confronted with scenario-based questions that require the synthesis of multiple concepts. Integrating exercises that mirror operational environments not only improves retention but also trains the mind to approach challenges holistically, enhancing both exam performance and real-world skill acquisition.
Many aspirants also overlook the importance of peer interaction and collaborative learning in optimizing preparation efficiency. Engaging with forums, study groups, and online communities exposes candidates to diverse approaches, uncommon scenarios, and alternative solutions. This collective exploration accelerates learning, clarifies misconceptions, and introduces rare insights that might be missed when studying in isolation. Structured participation in collaborative discussions ensures that study time is maximized through exposure to varied perspectives and techniques.
Time mismanagement frequently manifests in insufficient emphasis on error analysis. Simply completing practice exercises or reviewing dashboards without critically examining mistakes results in superficial knowledge. Analyzing why certain approaches failed, exploring alternative solutions, and documenting insights cultivates a disciplined, reflective mindset. This deliberate reflection transforms errors into productive learning opportunities, making preparation sessions both efficient and impactful.
Finally, candidates often misjudge the integration of advanced SPL functions with practical applications. Understanding the theoretical mechanics of commands such as stats, eval, chart, and timechart is insufficient without examining their deployment in complex scenarios. Neglecting this integration leads to fragmented knowledge and wasted time when attempting to reconcile command functionality with scenario requirements during the exam. Systematic practice that combines command mastery with real-world application ensures that preparation time is fully leveraged.
Through structured time management, reflective practice, hands-on scenario exercises, and deliberate attention to complex interactions within the platform, candidates can overcome inefficiencies that have hindered many aspiring Splunk Advanced Power Users. Emphasizing comprehension, adaptability, and iterative learning ensures that every hour invested in preparation translates into measurable proficiency and exam readiness.
Misunderstanding Field Extractions and Knowledge Objects
One of the most frequent and consequential mistakes that candidates make when preparing for the Splunk Core Certified Advanced Power User exam is misunderstanding field extractions and knowledge objects. Many aspirants approach these topics superficially, assuming that the mechanics are straightforward, when in fact they demand a nuanced comprehension of Splunk’s underlying architecture and data processing logic. Field extractions, event types, tags, and calculated fields are interconnected components that provide the structural foundation for advanced searches, statistical analysis, and visualization. Overlooking the intricacies of these elements can result in inefficient searches, incomplete dashboards, and lower performance on scenario-based questions.
Candidates often make the error of memorizing extraction syntax without grasping the logic behind it. For example, regular expressions and delimiter-based extractions are not simply formulas to apply blindly; they require an understanding of event patterns, multi-line logs, and hierarchical relationships within data. Failing to consider the variety of log formats or the subtle differences in field naming conventions leads to brittle extractions that break under slightly altered scenarios. Practical experimentation with diverse datasets is essential to develop dexterity in crafting flexible and resilient field extractions.
A related misstep involves neglecting the cascading nature of knowledge objects. Event types, tags, and saved searches are often treated as isolated constructs, whereas in reality they build upon one another to enable advanced analytics. Misunderstanding these dependencies can result in logical errors when combining multiple knowledge objects in searches or dashboards. Candidates who overlook this interconnectedness may find themselves unable to reconcile data from disparate sources or to produce coherent reports under examination conditions. Engaging in exercises that combine multiple knowledge objects reinforces the understanding of their hierarchical and relational properties.
Another common oversight is the underappreciation of calculated fields. Many aspirants focus on basic field extractions and assume that calculated fields are optional enhancements. In truth, calculated fields can dramatically simplify complex searches and enable more powerful statistical analysis. Misapplying or misconfiguring calculated fields, however, can produce inaccurate results, particularly when dealing with dynamic data sources or multi-step searches. Developing familiarity with various functions, nested calculations, and performance implications is essential to avoid inefficiency and error.
The misuse of field aliases is also a prevalent mistake. Field aliases allow data from different sources to be normalized, ensuring consistency in searches and reports. Candidates who fail to implement aliases correctly often encounter discrepancies in results when attempting to merge or correlate events. Misalignment of field names across indexes can compromise the integrity of statistical analyses and dashboards, leading to incorrect conclusions. Practicing the creation and verification of field aliases across diverse datasets fosters confidence and ensures that searches produce reliable, reproducible results.
A subtle but impactful error is the failure to account for extraction performance. Candidates may construct technically correct extractions that, when executed on large datasets, consume excessive resources or yield slow search results. Understanding the computational implications of regex complexity, search scope, and index optimization is crucial to developing efficient and scalable searches. Practical exposure to performance monitoring, iterative refinement, and benchmarking equips learners to balance accuracy with resource efficiency, a skill frequently tested on the SPLK-1004 exam.
The mismanagement of tags is another common stumbling block. Tags allow for semantic grouping of events, enabling searches to reference meaningful categories rather than raw fields. Many aspirants overlook the potential of tags or create them inconsistently, which can limit their utility in advanced searches. Applying tags thoughtfully across multiple datasets enhances search clarity and enables faster retrieval of relevant events. Exercises that emphasize tagging consistency and exploration of hierarchical tag structures strengthen both conceptual understanding and practical capability.
Some candidates also fail to recognize the interplay between knowledge objects and dashboard visualizations. A dashboard is only as effective as the underlying objects it references. If event types, field extractions, or calculated fields are misconfigured, the resulting visualizations can be misleading or fail to render correctly. Understanding how knowledge objects feed into panels, time-based visualizations, and statistical charts is critical. Candidates who integrate hands-on experimentation with theoretical study gain the agility to troubleshoot and optimize dashboards efficiently.
Another error arises from overcomplicating extractions. Aspirants may attempt to create highly generalized regular expressions or intricate field definitions, assuming that complexity equates to completeness. In reality, overly complex extractions often introduce ambiguity, increase computational load, and reduce maintainability. Developing parsimonious solutions that achieve accuracy without unnecessary complexity enhances performance, reduces errors, and simplifies future adjustments. This balance between precision and simplicity is a hallmark of advanced Splunk expertise.
Neglecting the iterative nature of learning knowledge objects is another frequent mistake. Candidates often perform a single extraction, save a calculated field, or create an event type, and then move on without testing or refinement. Splunk environments are dynamic, and real-world data often presents anomalies, multi-line events, or inconsistent patterns. Iterative testing across diverse scenarios ensures that field extractions and knowledge objects are resilient and adaptable, preventing failure during scenario-based exam questions.
Misunderstanding the relationship between base searches and knowledge objects is another area of concern. Saved searches, for instance, serve as building blocks for reports, alerts, and dashboards. Candidates who do not appreciate how base searches propagate through derived knowledge objects may inadvertently introduce redundancies, conflicts, or performance bottlenecks. Practicing the integration of base searches with multiple dependent objects cultivates an understanding of systemic relationships, enabling efficient design and execution of advanced workflows.
Some learners also underestimate the significance of documenting knowledge object logic. Maintaining clear descriptions of field extractions, calculated fields, and tags is essential for both collaboration and personal review. Candidates who fail to document their objects may struggle to recall nuances under exam conditions or to troubleshoot unexpected results. Developing the habit of concise, precise documentation enhances clarity, reduces cognitive load, and ensures reproducibility across exercises.
Another subtle mistake is the misinterpretation of multi-source data normalization. Splunk frequently aggregates events from multiple indexes, each with distinct schemas. Candidates who fail to normalize fields consistently across sources encounter discrepancies in searches, dashboards, and statistical evaluations. Addressing normalization proactively through aliases, calculated fields, and standardized naming conventions ensures that results remain coherent and comparable. Hands-on practice with heterogeneous datasets strengthens competence and reduces errors during the exam.
Failing to account for temporal considerations in field extractions is also common. Events may span multiple time zones, have irregular timestamps, or present delayed indexing. Candidates who overlook these temporal nuances risk producing inaccurate statistical aggregates or misaligned dashboards. Incorporating exercises that handle timestamp parsing, time conversions, and chronological grouping reinforces temporal awareness and ensures accuracy in dynamic scenarios.
The improper sequencing of knowledge object creation is another frequent pitfall. Creating dependent objects in the wrong order, such as generating calculated fields before establishing base extractions, can lead to logical errors and redundant effort. Adopting a methodical, layered approach to object creation—starting with field extractions, followed by aliases, calculated fields, tags, and event types—optimizes both efficiency and accuracy. This disciplined methodology mirrors best practices in real-world Splunk environments and is critical for exam readiness.
Some candidates also neglect to validate extractions and knowledge objects against multiple datasets. An extraction that works flawlessly on one log source may fail on another due to variations in structure, delimiters, or event patterns. Testing across diverse datasets ensures robustness, reduces surprises during complex scenario questions, and enhances confidence in analytical reasoning. Validation practices, such as sample indexing and comparison of expected versus actual results, are indispensable for advanced users.
Additionally, misunderstanding the implications of object inheritance can create errors. Event types derived from base searches inherit specific filters and field extractions, which may conflict with manually applied adjustments. Candidates who ignore inheritance relationships may inadvertently override or obscure critical data, compromising both search accuracy and visualization integrity. Exploring inheritance behavior through practical exercises enables learners to anticipate interactions and design consistent, reliable solutions.
Finally, many aspirants overlook the strategic integration of knowledge objects into alerting and reporting workflows. Alerts, scheduled searches, and automated dashboards depend on correctly configured objects. Candidates who fail to consider end-to-end applications of field extractions, event types, and tags often produce incomplete or inefficient workflows. Comprehensive exercises that trace objects from creation to reporting reinforce both conceptual and practical mastery, bridging the gap between theoretical knowledge and applied expertise.
Through disciplined, iterative practice, hands-on experimentation, and mindful integration of knowledge objects and field extractions, candidates can avoid these common mistakes and cultivate the nuanced expertise required for the Splunk Core Certified Advanced Power User exam. This approach emphasizes comprehension, adaptability, and the interconnectedness of advanced Splunk functionalities, ensuring readiness for both the exam and practical, real-world applications.
Misusing Advanced SPL Commands and Statistical Functions
A prevalent challenge that candidates encounter when preparing for the Splunk Core Certified Advanced Power User exam is misusing advanced SPL commands and statistical functions. Many aspirants approach SPL superficially, focusing primarily on basic search syntax while underestimating the complexity and versatility of advanced commands. The SPLK-1004 exam is designed to test the candidate’s ability to manipulate, transform, and analyze data efficiently using intricate command combinations, statistical aggregations, and multi-stage searches. Overlooking the subtleties of these commands often leads to errors, inefficient searches, or incomplete analyses during the exam.
One common error is the misapplication of statistical functions such as stats, chart, timechart, and eventstats. Candidates frequently use these commands without fully understanding their contextual requirements, operational differences, or performance implications. For instance, using stats in scenarios where eventstats or streamstats would provide more meaningful insights can lead to unnecessary data aggregation or incomplete correlation. This misunderstanding often arises from a lack of hands-on experimentation or insufficient exposure to diverse datasets. Developing dexterity with these commands through iterative practice, comparing output variations, and analyzing performance implications is essential to achieve proficiency.
Another frequent mistake involves improper nesting of commands. SPL allows for the sequential combination of searches, statistical functions, and evaluation expressions to produce highly customized results. Candidates who fail to appreciate the precedence and execution order of nested commands often encounter logical errors or incomplete results. Misinterpreting how eval interacts with stats or how where clauses influence timechart outputs can compromise the integrity of analytical workflows. Continuous experimentation with nested commands, examining edge cases, and tracing execution order cultivates a more profound comprehension and enhances accuracy under exam conditions.
Many learners also struggle with the correct application of eval expressions. Eval is a versatile function that enables field manipulation, conditional calculations, and dynamic transformations. A common error is creating overly complex or inefficient expressions that strain performance or produce unintended results. Candidates may overlook the importance of evaluating data types, null handling, or precedence rules within expressions. Practicing the construction of modular, logically sequenced eval statements and validating results across diverse datasets strengthens analytical agility and minimizes errors.
The misuse of time-based statistical functions is another frequent pitfall. Timechart, for example, requires careful consideration of span, aggregation, and alignment. Candidates who ignore temporal granularity or fail to adjust time ranges appropriately may generate misleading trends or incomplete visualizations. Understanding the nuances of chronological grouping, interval selection, and time zone normalization is essential. Exercises that involve real-time monitoring data, historical logs, and event timelines reinforce temporal awareness and ensure accurate interpretation during complex scenario-based exam questions.
A related mistake is inefficient handling of multi-value fields. Commands such as mvexpand, mvcount, and mvindex enable powerful manipulations of lists and arrays within events, but their misuse can lead to redundant processing or incorrect aggregations. Many candidates either neglect multi-value capabilities entirely or apply them incorrectly, resulting in incomplete correlation and analysis. Engaging in exercises that explore multi-value manipulations across diverse scenarios strengthens conceptual understanding and improves execution speed under exam conditions.
Another common oversight involves neglecting filtering and conditional logic when applying statistical functions. The where clause, conditional eval expressions, and search filters are essential for narrowing data sets before aggregation. Candidates often perform computations on unfiltered datasets, resulting in excessive data processing and reduced efficiency. Practicing the integration of filtering, conditional logic, and statistical commands fosters precision and reduces unnecessary computational load, a skill highly valued in both the exam and real-world Splunk environments.
Misunderstanding join operations is also a frequent source of errors. Joins allow the combination of datasets from different indexes or event types, but incorrect use can produce duplicates, mismatched records, or performance bottlenecks. Candidates who fail to comprehend the distinction between inner, left, and outer joins, or who overlook join keys and matching criteria, often generate inaccurate results. Hands-on exercises that involve dataset alignment, cross-index correlation, and verification of outputs reinforce mastery of joins and their appropriate applications.
The improper application of lookup commands presents another challenge. Lookups extend Splunk’s analytical power by enriching events with external reference data. However, candidates often struggle with field mapping, case sensitivity, and handling missing values. Misconfigured lookups can produce incomplete or misleading results, undermining the integrity of dashboards and statistical reports. Practicing a variety of lookup scenarios, including automatic lookups, manual mappings, and chained enrichments, cultivates confidence and precision in implementing these features during the exam.
Many aspirants also fail to appreciate the interaction between aggregation and performance optimization. Commands such as stats or chart, when applied to large datasets without proper filters or summarization, can result in sluggish searches or timeouts. Candidates who do not consider the impact of event volume, time spans, and index selection may waste valuable exam time or produce incomplete results. Learning to structure searches efficiently, leveraging summary indexing and data sampling where appropriate, ensures that advanced SPL commands operate effectively without sacrificing accuracy.
A frequent misstep involves overlooking the subtle differences between similar commands. For example, using stats instead of eventstats, or chart instead of timechart, can create logically correct but contextually inappropriate results. Candidates who fail to internalize these distinctions often produce outputs that superficially appear correct but fail under nuanced scrutiny. Comparative exercises that analyze command behavior across different scenarios enhance discernment and reinforce correct application.
Misinterpreting the role of functions within eval statements is another common error. Functions such as if, case, coalesce, and round can transform data in sophisticated ways, but their misuse can distort analytical outcomes. Candidates often overlook null handling, operator precedence, or type conversions, leading to errors that compromise statistical summaries. Iterative experimentation, combined with validation against expected outcomes, builds both technical acumen and analytical confidence.
Some learners also underestimate the importance of search optimization when applying advanced SPL commands. Commands that are functionally correct but inefficient in execution can lead to performance penalties, especially when applied to multi-index datasets. Understanding search acceleration techniques, efficient command ordering, and selective field inclusion is critical to ensuring both accuracy and speed. Hands-on exposure to performance monitoring, search profiling, and iterative refinement strengthens preparation and mitigates inefficiency.
Another error arises from neglecting subsearches and their limitations. Subsearches provide powerful capabilities for dynamically generating search criteria, but they have inherent constraints on size, execution time, and resource consumption. Candidates who ignore these constraints may create searches that fail or produce incomplete results. Practicing subsearch construction with attention to performance implications ensures that learners can leverage these tools effectively under exam conditions.
Misuse of event grouping commands, such as transaction, is also prevalent. Transaction requires careful definition of grouping criteria, time boundaries, and event sequencing. Candidates who overlook the impact of order, overlap, or duration on results frequently generate inaccurate aggregations. Exercises that involve multi-event patterns, overlapping sequences, and boundary conditions cultivate precision and mastery of transactional analysis.
Many aspirants fail to integrate statistical commands with knowledge objects effectively. Saved searches, field extractions, and event types are often underutilized when performing statistical operations. Candidates who do not consider these integrations may perform repetitive or redundant computations, wasting time and reducing clarity. Systematic practice linking SPL commands with existing knowledge objects strengthens both efficiency and accuracy.
Another frequent mistake is ignoring edge cases in statistical analysis. Outliers, missing values, or irregular event patterns can skew results if not handled correctly. Candidates who apply commands mechanically without considering data anomalies risk producing misleading conclusions. Developing scenarios that include anomalies, irregular distributions, and extreme values ensures preparedness for unexpected challenges in the exam.
Some learners also struggle with multi-stage pipelines. SPL allows chaining multiple commands to produce complex analyses, but candidates often fail to maintain coherence across stages. Errors in field naming, aggregation order, or conditional logic can propagate through the pipeline, compromising results. Iterative testing and modular construction of multi-stage searches cultivates clarity and ensures each stage produces intended outputs.
Finally, candidates often neglect the importance of documentation and review. Complex SPL commands, especially when nested or combined with statistical functions, can become difficult to manage without systematic notes. Documenting logic, assumptions, and expected outcomes not only aids retention but also provides a reference for iterative refinement and troubleshooting during preparation. This habit cultivates both clarity and analytical discipline, essential for excelling in the SPLK-1004 exam.
Through deliberate practice, iterative testing, scenario-based experimentation, and mindful integration of statistical functions with advanced SPL commands, candidates can avoid common mistakes and develop the nuanced expertise required for the Splunk Core Certified Advanced Power User exam. This approach emphasizes comprehension, analytical agility, and efficient application of commands across complex datasets, ensuring readiness for both the exam and practical deployment in dynamic environments.
Inefficient Dashboard and Report Design and Visualization Errors
One of the most frequent mistakes candidates make when preparing for the Splunk Core Certified Advanced Power User exam is inefficient dashboard and report design. Many aspirants focus on producing visually appealing displays without considering functionality, optimization, and analytical clarity. While aesthetic elements are important, they must be balanced with performance, interpretability, and data accuracy. The SPLK-1004 exam emphasizes the ability to design dashboards and reports that not only present information but also facilitate rapid analysis and actionable insights. Neglecting these critical aspects can lead to suboptimal visualizations that obscure key patterns, misrepresent data, or strain system resources.
A common error involves overcomplicating dashboards with excessive panels, charts, and filters. Candidates often assume that a more elaborate dashboard is inherently superior, when in reality, an overcrowded interface can confuse users and impede comprehension. Each panel should have a defined purpose, and the dashboard should guide the observer through the data logically and intuitively. Exercises that involve designing minimalist dashboards focused on clarity, relevance, and efficiency help candidates develop an instinct for purposeful visual organization.
Another prevalent issue is the improper use of visualizations. Candidates may select charts that are visually appealing but poorly suited to the underlying data type or analytical objective. For instance, using pie charts for datasets with numerous categories or time-series line charts for discrete events can lead to misinterpretation. Understanding the strengths and limitations of each visualization type, including column, bar, line, area, and scatter plots, is essential. Practicing with diverse datasets and iteratively evaluating chart selection cultivates the ability to match data to the most informative and comprehensible visualization.
Many aspirants also neglect performance optimization when creating dashboards. Dashboards that execute multiple complex searches simultaneously, or rely on unfiltered datasets, can result in slow load times and delayed responsiveness. Candidates often overlook the computational cost of panel refresh rates, subsearches, and statistical aggregations, leading to inefficient dashboards that would not be practical in a real-world environment. Incorporating performance considerations, such as summary indexing, accelerated searches, and selective filtering, ensures dashboards remain both functional and responsive under varying data loads.
A frequent misstep involves insufficient attention to dynamic filtering and user interactivity. Dashboards often include time range selectors, dropdowns, and input controls that allow users to manipulate and drill into data. Candidates may create static visualizations that fail to accommodate exploration or contextual analysis. Practicing the integration of dynamic inputs, drilldowns, and chained filters strengthens interactive capabilities and aligns dashboard design with practical analytical workflows.
Another common oversight is the improper alignment between dashboard panels and underlying searches. Each visualization is only as accurate as the search it represents. Candidates frequently overlook the need for consistent field extractions, calculated fields, and knowledge objects, resulting in panels that display incomplete or inconsistent information. Verifying that each panel is connected to reliable and appropriately scoped searches ensures that dashboards accurately reflect the intended data and analytical objectives.
Some learners also make errors in report configuration and scheduling. Reports are often generated with inappropriate time ranges, sampling intervals, or aggregation methods, leading to incomplete or misleading results. Understanding the interplay between search parameters, scheduled execution, and report formatting is crucial to producing reliable outputs. Practicing the creation of reports under varied conditions and examining outputs for consistency reinforces the skills needed for both exam performance and real-world application.
Neglecting the importance of logical layout is another frequent mistake. Panels should be organized to create a narrative flow, guiding viewers through key metrics, trends, and anomalies. Candidates who arrange visualizations haphazardly may inadvertently obscure relationships between data points or create cognitive overload. Exercises that focus on storytelling through dashboards, with careful sequencing and grouping of related panels, enhance both clarity and interpretability.
A subtle but significant error involves overlooking thresholding, conditional formatting, and alerting within dashboards. Visual cues such as color gradients, markers, and thresholds help observers identify deviations, trends, or anomalies quickly. Candidates who omit these elements may create dashboards that are visually complete but analytically impoverished. Practicing the strategic application of visual alerts, conditional formatting, and dynamic indicators ensures that dashboards communicate insights effectively and efficiently.
Another common mistake is the misuse of single-value panels and summary indicators. Single-value visualizations are powerful for highlighting key metrics, but candidates often present them without context or comparative analysis. Understanding how to integrate summary panels with supporting charts, trend lines, and historical baselines enhances comprehension and allows for more meaningful analysis. Exercises that combine summary indicators with trend-based visualizations develop a more holistic approach to dashboard design.
Many aspirants also underestimate the importance of scaling and consistency across multiple dashboards. Visualizations that use inconsistent color schemes, time ranges, or data labels can confuse users and reduce analytical clarity. Establishing design standards, consistent units of measurement, and uniform time intervals ensures that multiple dashboards provide coherent and comparable insights. Practicing design consistency across dashboards builds visual literacy and professional presentation skills.
A further pitfall is neglecting the cognitive load of dashboard users. Overly dense dashboards, with numerous simultaneous searches, can overwhelm users and obscure important insights. Candidates should consider user perspective, focusing on clarity, prioritization of metrics, and logical grouping of panels. Exercises that involve user-centered design principles, including iterative feedback and usability testing, reinforce the importance of reducing cognitive strain while preserving analytical depth.
Errors also arise from insufficient validation of dashboard outputs. Candidates often create dashboards based on assumed correctness of searches or data structures without cross-checking results. This can lead to panels that report misleading trends, overlook anomalies, or misrepresent aggregated values. Validation practices, including cross-comparison with raw events, statistical verification, and scenario testing, ensure reliability and integrity of visualizations.
Some learners fail to leverage drilldowns and contextual navigation effectively. Dashboards that lack interactivity or links to detailed reports constrain the user’s ability to investigate anomalies or trends further. Candidates should practice integrating drilldowns, linking summary panels to underlying event-level data, and enabling contextual exploration. This enhances both analytical depth and practical utility, aligning dashboards with operational and investigative workflows.
Another frequent mistake involves ignoring multi-source data integration. Dashboards often aggregate data from multiple indexes, event types, or sources, but candidates may fail to normalize or align fields properly. Misaligned time ranges, inconsistent field naming, and conflicting data formats can lead to misleading visualizations. Practicing multi-source integration, normalization, and cross-referencing of data ensures dashboards provide coherent, actionable insights.
Mismanagement of time ranges and refresh intervals also contributes to inefficiency. Candidates may set default ranges that fail to capture relevant events, or refresh panels too frequently, straining system resources. Understanding optimal time ranges, relative versus absolute intervals, and appropriate refresh strategies is critical to designing efficient, responsive dashboards. Exercises that simulate live monitoring, historical review, and trend analysis help candidates develop practical temporal management skills.
A subtle but pervasive error is the failure to optimize panel queries for scalability. Dashboards designed without consideration of dataset growth, user load, or computational efficiency may perform adequately on small datasets but degrade rapidly under larger, real-world volumes. Practicing query optimization, selective field inclusion, and summarized indexing ensures dashboards remain performant and resilient.
Candidates also frequently overlook the importance of descriptive labeling and annotations. Panels without clear titles, axis labels, or explanatory notes can confuse users and reduce interpretability. Integrating concise, informative labels and annotations enhances user comprehension and strengthens the analytical narrative of the dashboard. Exercises that emphasize clarity, precision, and contextual cues cultivate professional-level visualization skills.
Another common mistake is underutilizing drill-down functionality for multi-level analysis. Dashboards that present only high-level metrics without paths for deeper exploration limit analytical insight. Candidates should practice designing hierarchical dashboards, where users can start with summary metrics and progressively drill down into finer details. This approach fosters deeper understanding, efficient anomaly detection, and effective scenario-based analysis.
Some learners neglect the strategic use of color and visual hierarchy. Improper or inconsistent color schemes, lack of emphasis on critical metrics, or uniform presentation of diverse panels can reduce the intuitive understanding of the dashboard. Practicing visual hierarchy, selective emphasis, and color differentiation improves both interpretability and engagement.
Candidates often underestimate the importance of integrating reports with dashboards. Reports provide historical, aggregated, or comparative perspectives that complement real-time visualizations. Failing to link or reference reports diminishes the analytical depth of dashboards. Exercises that integrate reporting outputs with dashboards, including scheduling, alerts, and summary metrics, enhance the overall coherence of data presentation.
Finally, many aspirants overlook iterative testing and feedback. Dashboards and reports are rarely perfect on the first attempt, especially when dealing with complex datasets. Continuous refinement, validation against expected outcomes, and feedback from peers or mentors ensure that designs are both functional and insightful. Engaging in iterative cycles of evaluation, adjustment, and optimization cultivates a mindset of analytical precision and operational readiness.
Through deliberate design practice, iterative refinement, validation, and attention to user experience, candidates can avoid common errors in dashboard and report visualization and develop the sophisticated expertise required for the Splunk Core Certified Advanced Power User exam. This approach emphasizes clarity, efficiency, interactivity, and analytical integrity, ensuring that visualizations are both informative and actionable in real-world contexts.
Neglecting Real-World Scenario Practice and Troubleshooting
A significant error that many candidates commit when preparing for the Splunk Core Certified Advanced Power User exam is neglecting real-world scenario practice and troubleshooting exercises. While theoretical understanding of SPL commands, field extractions, knowledge objects, dashboards, and statistical functions is crucial, the exam primarily evaluates the ability to apply these skills in practical, dynamic contexts. Candidates who focus exclusively on memorization and pre-defined examples often struggle when confronted with scenarios that deviate from familiar patterns or involve multiple interconnected elements.
Many aspirants fail to appreciate the importance of troubleshooting skills, assuming that knowing the correct commands and configurations is sufficient. In reality, the exam often presents questions where searches fail, dashboards return unexpected results, or data correlations do not align as anticipated. Candidates must be adept at identifying root causes, diagnosing errors, and adjusting commands or configurations appropriately. Developing a systematic approach to troubleshooting—analyzing search syntax, reviewing field extractions, validating knowledge objects, and evaluating performance metrics—is essential to success.
Another common mistake is avoiding multi-source integration exercises. Real-world Splunk deployments frequently aggregate data from disparate indexes, event types, and external sources, each with unique schemas, timestamp formats, and field naming conventions. Candidates who practice only with uniform datasets are ill-prepared for scenarios requiring normalization, alignment, and cross-source correlation. Exercises that incorporate heterogeneous data, simulate delayed event indexing, or include irregular patterns enhance problem-solving agility and build confidence in handling complex environments.
Insufficient exposure to performance-related troubleshooting is also a frequent pitfall. Candidates may construct searches or dashboards that function correctly on small datasets but falter under high-volume conditions due to inefficient SPL commands, unoptimized searches, or resource-heavy visualizations. Understanding the impact of command sequencing, filtering strategies, search acceleration, and indexing structures on performance is crucial. Practical exercises that measure execution time, optimize queries, and refine dashboards cultivate both efficiency and technical foresight.
Mismanaging the investigation of field extractions and knowledge objects is another common error. In real-world scenarios, field extractions may fail due to inconsistent event formatting, multi-line events, or unexpected delimiters. Similarly, calculated fields, event types, and tags can propagate errors if dependencies are misunderstood. Candidates who neglect iterative testing and validation often miss subtle issues that compromise analytical outcomes. Hands-on practice that explores edge cases, error handling, and dependency tracing strengthens troubleshooting proficiency and ensures reliability in scenario-based exercises.
A subtle but impactful mistake is ignoring temporal anomalies during scenario practice. Events may arrive out of order, span multiple time zones, or exhibit gaps in indexing. Candidates who do not account for these temporal irregularities may produce incorrect aggregations, misleading trends, or misaligned dashboards. Exercises that simulate time-based challenges, including historical data analysis, delayed event arrival, and irregular timestamps, foster awareness of temporal intricacies and refine analytical techniques.
Candidates also often overlook multi-stage troubleshooting. Complex scenarios frequently require stepwise analysis: identifying the failing component, isolating contributing factors, and adjusting searches, fields, or knowledge objects sequentially. Treating problems as monolithic or attempting to resolve them in a single step can lead to confusion and inefficiency. Practicing a modular troubleshooting approach, where each component is tested and validated independently before reintegration, improves clarity, reduces errors, and develops analytical rigor.
Another prevalent oversight is insufficient exposure to dashboard and visualization troubleshooting. Dashboards may fail to render panels correctly, display inconsistent metrics, or slow down due to suboptimal searches or unfiltered data. Candidates who do not practice iterative dashboard testing may be unprepared for questions requiring rapid correction or optimization under exam conditions. Exercises that involve debugging panel queries, validating knowledge object inputs, and optimizing refresh intervals enhance both speed and accuracy.
Many aspirants neglect real-world alerting and reporting exercises. Alerts may fail to trigger due to incorrect search syntax, misconfigured time ranges, or overlooked dependencies. Reports may produce incomplete summaries if aggregation methods, filters, or knowledge object linkages are misapplied. Candidates who do not simulate these operational scenarios lack the practical intuition needed to anticipate, diagnose, and resolve failures. Repeated practice in alert creation, report scheduling, and event correlation strengthens problem-solving agility and prepares learners for nuanced exam questions.
Failure to practice collaborative troubleshooting is another common mistake. Real-world Splunk environments often involve multiple users, shared knowledge objects, and interdependent dashboards. Errors can arise from conflicting configurations, inconsistent naming conventions, or uncoordinated searches. Candidates who train exclusively in isolation may be unprepared for scenarios requiring an understanding of collaborative dependencies and cross-user interactions. Engaging in exercises that simulate multi-user environments, shared dashboards, and overlapping knowledge objects develops foresight and prepares learners for complex problem-solving.
A subtle but frequent error is underestimating the importance of anomaly detection and outlier handling during scenario practice. Real-world data frequently contains missing values, outliers, or irregular event patterns. Candidates who do not practice identifying, isolating, and accommodating anomalies may produce inaccurate analyses or fail to capture critical insights. Exercises that incorporate irregular datasets, noise, and unexpected patterns enhance analytical acuity and troubleshooting skill.
Some candidates also fail to integrate SPL optimization into troubleshooting practice. Searches may be functionally correct but inefficient, producing slow results or overloading system resources. Candidates must develop an intuition for balancing correctness with efficiency, refining search commands, leveraging summary indexing, and selectively including fields. Practicing optimization alongside functional verification ensures searches remain both accurate and performant under exam-like conditions.
Another common oversight is neglecting the interplay between statistical functions and real-world data variability. Commands such as stats, eventstats, and timechart behave differently depending on the volume, distribution, and quality of data. Candidates who practice only with ideal datasets may be unprepared for irregular distributions, missing values, or multi-source aggregation. Exercises that simulate these conditions strengthen adaptability and ensure statistical outputs remain reliable across diverse scenarios.
Many aspirants fail to simulate failure recovery scenarios. Real-world Splunk usage involves dealing with search failures, indexing delays, and knowledge object misconfigurations. Candidates who do not practice recovery strategies, such as incremental correction of searches, validation of dependent objects, or field reprocessing, may struggle when confronted with complex exam questions. Systematic exposure to error recovery fosters confidence and reduces reaction time under pressure.
A further error is overlooking the documentation and logging of troubleshooting procedures. Candidates who do not record their findings, search iterations, or validation steps may forget critical insights, repeat mistakes, or misinterpret outcomes. Maintaining meticulous notes during scenario practice enhances retention, clarifies thought processes, and creates a reference framework for complex problem-solving.
Another subtle mistake is ignoring the integration of scenario practice with knowledge object dependencies. Event types, calculated fields, and tags may interact in unexpected ways during complex searches or dashboards. Candidates who fail to explore these interactions in real-world exercises risk producing inconsistent or incomplete analyses. Practicing end-to-end workflows that incorporate multiple knowledge objects fosters systemic understanding and analytical dexterity.
Neglecting user simulation is another prevalent oversight. Candidates often practice in idealized conditions without considering user interactions, input variability, or decision-making processes. Real-world dashboards, alerts, and reports are utilized by diverse audiences with differing expectations. Exercises that simulate user-driven exploration, interactive filtering, and ad hoc search requests develop practical insights and ensure preparedness for exam scenarios that require adaptability.
Failure to practice scenario-based event correlation is another frequent misstep. Candidates may understand the mechanics of transaction commands, joins, and statistical aggregation but fail to apply them to complex, multi-event patterns. Real-world exercises that involve correlating disparate events, detecting sequences, or identifying anomalies strengthen problem-solving skills and reinforce the practical application of advanced SPL concepts.
Another overlooked aspect is the iterative refinement of solutions. Candidates may produce a search, dashboard, or report that is superficially correct but fail to optimize, validate, or adapt it for edge cases. Practicing iterative improvement, where solutions are tested, refined, and validated repeatedly, fosters precision, efficiency, and resilience—skills indispensable for both exam success and professional competence.
Time management during scenario practice is also critical. Candidates who do not allocate sufficient time to analyze, test, and refine complex scenarios may develop incomplete solutions or overlook errors. Structured practice sessions with realistic constraints cultivate speed, focus, and systematic problem-solving under pressure.
Finally, many aspirants underestimate the compounding benefits of integrated scenario practice. Combining SPL command mastery, statistical functions, field extractions, knowledge objects, dashboards, and troubleshooting exercises into cohesive simulations mirrors the demands of the exam and real-world usage. Candidates who neglect this holistic approach often face fragmented understanding and reduced analytical agility. Integrating these elements ensures a robust foundation of both theoretical knowledge and practical expertise.
Conclusion
Through consistent engagement with real-world scenarios, iterative troubleshooting, performance optimization, multi-source integration, and systematic validation, candidates develop the nuanced expertise required to excel in the Splunk Core Certified Advanced Power User exam. Scenario-based practice fosters analytical agility, problem-solving dexterity, and confidence in handling complex, dynamic data environments. By cultivating these habits, aspirants not only improve exam readiness but also enhance their capability to leverage Splunk effectively in operational and analytical contexts.
The ability to navigate unexpected challenges, diagnose errors, and iteratively refine solutions is what distinguishes advanced users from those who rely solely on theoretical knowledge. Engaging deeply with practical scenarios develops intuition, resilience, and a problem-solving mindset that is essential for both professional excellence and certification success. Candidates who invest in comprehensive, scenario-based preparation gain a strategic advantage, ensuring that they are capable of responding adeptly to any analytical challenge presented in the exam or in real-world applications.

