
Certification: Databricks Certified Machine Learning Professional
Certification Full Name: Databricks Certified Machine Learning Professional
Certification Provider: Databricks
Exam Code: Certified Machine Learning Professional
Exam Name: Certified Machine Learning Professional
Product Screenshots
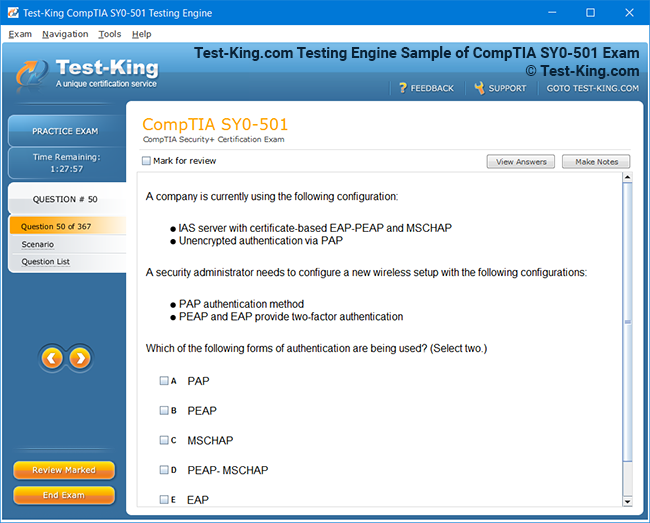
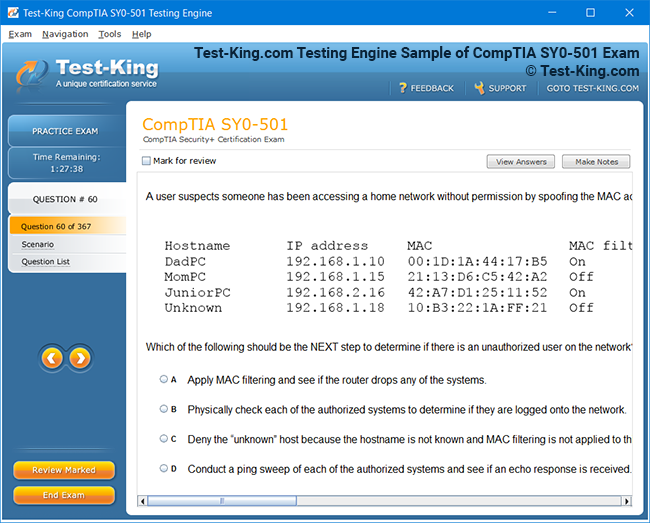
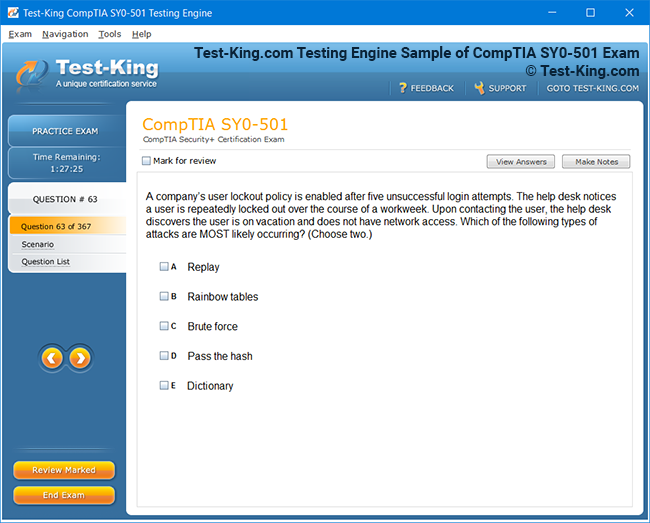
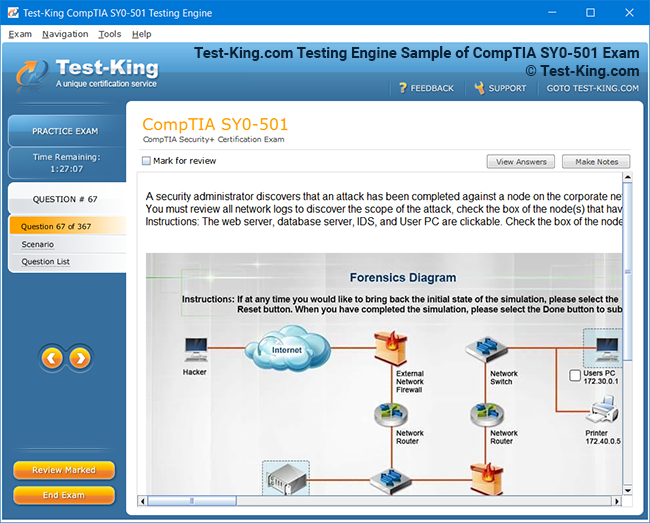
Prepare for Databricks Machine Learning Professional Certification Exam
Databricks has emerged as a transformative platform for data engineering, big data analytics, and machine learning operations, providing a seamless environment for developing, deploying, and managing machine learning models in production. It integrates multiple functionalities, enabling data scientists, engineers, and analysts to orchestrate complex workflows while leveraging the distributed computational prowess of Spark for accelerated processing. Unlike conventional frameworks, Databricks emphasizes end-to-end automation and operational efficiency, which allows organizations to bridge the gap between experimentation and deployment while maintaining high standards of reproducibility and scalability.
Understanding Databricks and Machine Learning Capabilities
At the core of Databricks lies the capability to track experiments, version models, and maintain a comprehensive lifecycle management system for machine learning assets. By capturing all relevant metadata, parameters, and metrics, the platform facilitates a holistic understanding of model behavior over time. Experimentation becomes more structured and reproducible as practitioners can compare model versions, assess performance on diverse datasets, and determine the precise influence of hyperparameters or data transformations. This environment is particularly beneficial in production, where reproducibility and reliability are crucial for operational stability.
Developing machine learning models in Databricks involves an extensive repertoire of libraries and frameworks, ranging from traditional statistical tools to modern deep learning architectures. The platform leverages Spark’s distributed architecture to accelerate model training, allowing computationally intensive tasks to be executed efficiently across large datasets. This distributed paradigm is particularly advantageous when dealing with high-dimensional data or iterative model tuning processes that would otherwise be prohibitively slow on single-node systems. Moreover, the combination of Spark’s parallelism and Databricks’ optimized execution environment reduces latency and improves the throughput of model experimentation cycles, enabling rapid iteration and testing.
Databricks also emphasizes the automation of workflows, which encompasses the scheduling of training tasks, deployment of new model versions, and continuous monitoring of live models. Automation mitigates the risk of human error, ensures consistency across environments, and accelerates the delivery of machine learning solutions to production. This automation is complemented by integration with CI/CD pipelines, enabling machine learning projects to adopt software engineering best practices such as testing, version control, and staged deployments. By embedding machine learning pipelines within automated workflows, teams can achieve higher efficiency and maintain compliance with organizational or regulatory requirements, particularly in sectors like finance, healthcare, and manufacturing where model governance is critical.
Experiment tracking is another essential facet of Databricks’ machine learning ecosystem. MLflow, integrated within the platform, allows users to log parameters, metrics, models, and artifacts both manually and programmatically. This ensures that every experiment is meticulously documented, facilitating audits, comparisons, and iterative improvement. Users can log model inputs, outputs, and performance metrics, creating a robust repository of experiment data that supports evidence-based decision-making. Advanced tracking capabilities include the use of model signatures, input examples, nested runs, and autologging with hyperparameter optimization, which collectively provide a sophisticated framework for monitoring model evolution and ensuring reproducibility. Artifacts such as visualizations, SHAP plots, feature data, and metadata can also be captured, offering insights into model behavior and interpretability.
The management of machine learning models extends beyond experimentation, encompassing lifecycle management and deployment considerations. Databricks enables the creation of custom model classes that incorporate preprocessing logic and contextual information, ensuring that models are not only trained but also properly contextualized for downstream usage. By utilizing MLflow flavors, including the pyfunc flavor, practitioners can standardize model formats, simplify deployment, and maintain compatibility across diverse environments. Models can be registered in a Model Registry, where they are assigned metadata, tracked through stages, and transitioned or archived as needed. This registry facilitates a structured approach to model governance, allowing teams to manage multiple versions simultaneously and maintain a clear history of changes.
Automation of the model lifecycle is a crucial aspect for organizations seeking operational efficiency. Databricks Jobs and Model Registry Webhooks allow teams to automate testing, deployment, and monitoring processes, reducing manual intervention and streamlining workflows. Job clusters offer performance benefits compared to all-purpose clusters, optimizing resource usage during critical tasks such as model retraining or batch scoring. Webhooks can be configured to trigger Jobs when models transition between stages, enabling responsive and context-aware automation. This integration of automation into the lifecycle of machine learning models supports the principles of continuous integration and continuous delivery, ensuring that updates are tested, validated, and deployed systematically.
Deploying machine learning models in production requires careful consideration of the nature of the task and the required response time. Batch deployment is suitable for scenarios where predictions can be precomputed and stored for later access. This method is efficient for processing large volumes of data and allows predictions to be queried with minimal computational overhead. Databricks facilitates batch scoring through the score_batch operation, enabling rapid evaluation of large datasets while leveraging optimizations such as z-ordering and partitioning to enhance read performance. Streaming deployment, on the other hand, addresses use cases where continuous inference is required on incoming data streams. Structured Streaming allows for handling of out-of-order data and integration of complex business logic, ensuring that real-time insights are accurate and timely. Pipelines initially designed for batch processing can be converted to streaming pipelines, providing flexibility and scalability in dynamic environments. Real-time deployment caters to situations requiring immediate predictions for small numbers of records or latency-sensitive tasks. This mode leverages just-in-time computation of features and model serving endpoints, ensuring rapid and reliable responses. Cloud-provided RESTful services are often employed to facilitate production-grade deployments, enabling seamless integration with external applications and systems.
Monitoring deployed models is a vital practice to maintain their efficacy over time. Databricks provides tools to monitor for drift, including label drift, feature drift, and concept drift. Feature drift occurs when the statistical distribution of input features changes over time, while label drift arises when the distribution of the target variable evolves. Concept drift represents a more complex phenomenon where the relationship between inputs and outputs changes, potentially degrading model performance. Detecting these drifts requires statistical and analytical methods. Summary statistics can be used for numeric and categorical feature drift, but more robust techniques such as Jensen-Shannon divergence, Kolmogorov-Smirnov tests, or chi-square tests provide deeper insight into distributional changes. Comprehensive drift monitoring enables teams to identify when retraining and redeployment are necessary, ensuring models remain accurate and reliable on fresh data.
Practical experience within Databricks reinforces theoretical understanding. Hands-on exercises, including reading and writing Delta tables, managing feature stores, logging MLflow experiments, and implementing lifecycle automation, are instrumental in preparing for the machine learning professional certification. Exercises focused on deploying models in batch, streaming, and real-time modes enhance familiarity with real-world scenarios, enabling practitioners to address challenges they are likely to encounter in production. Logging artifacts, evaluating model performance, and monitoring for drift all contribute to a deeper comprehension of operational practices, which is indispensable for certification success.
The Databricks Machine Learning Professional certification is designed to validate proficiency in these domains. The examination assesses the ability to manage experiments, implement lifecycle automation, deploy models effectively, and monitor their performance over time. Candidates must demonstrate an understanding of end-to-end machine learning workflows, from experimentation to production, emphasizing reproducibility, scalability, and operational rigor. Familiarity with MLflow, Delta tables, Feature Stores, automated jobs, webhooks, and deployment strategies is essential for success. Practical application of these tools and concepts, combined with theoretical knowledge, forms the cornerstone of effective preparation for the certification.
During preparation, it is crucial to understand the nuances of data management within Databricks. Delta tables provide a robust mechanism for storing, updating, and retrieving structured datasets, offering transactional guarantees and schema enforcement that are particularly valuable in machine learning pipelines. Historical data versions can be accessed to reproduce past experiments or analyze model behavior under different conditions. Feature Stores provide a centralized repository for reusable features, simplifying the integration of data into machine learning models and enhancing collaboration among teams. Understanding how to create, overwrite, merge, and read from these stores is vital for efficient experimentation and production readiness.
Experiment tracking within MLflow forms the backbone of reproducible machine learning. By capturing parameters, metrics, models, and artifacts, MLflow provides transparency and traceability, which are critical for evaluating model performance over time. Nested runs and autologging extend the capabilities of MLflow, allowing automated capture of hyperparameter tuning experiments and ensuring that complex workflows are adequately documented. Logging visualizations, feature importance plots, and other artifacts adds an interpretive layer, helping stakeholders comprehend model behavior and making results actionable for business decisions.
Lifecycle management ensures that models are consistently managed from training through deployment. MLflow flavors and custom model classes provide flexibility in packaging models with preprocessing logic and metadata, facilitating seamless deployment across diverse environments. The Model Registry supports version control, stage transitions, and metadata annotation, enabling structured governance of machine learning assets. Automated testing and integration with CI/CD pipelines allow models to be reliably promoted from staging to production, reducing risk and ensuring operational continuity. Webhooks and Jobs offer responsive automation, triggering workflows based on stage changes or other events, and optimizing computational resources through the use of dedicated clusters.
Deployment strategies in Databricks are versatile, accommodating batch, streaming, and real-time paradigms. Batch deployments allow large-scale computation and storage of predictions for later querying, while streaming deployments handle continuous data flows and require real-time computation of predictions. Real-time deployments are optimized for immediate responses, leveraging serving endpoints and just-in-time feature computation to support latency-sensitive applications. Each deployment mode presents distinct challenges, from handling out-of-order data to optimizing query performance, which practitioners must understand to ensure efficient and reliable operation.
Monitoring remains a pivotal component in maintaining model performance. Drift detection, through statistical tests and summary measures, ensures that models continue to perform accurately in dynamic environments. Detecting label, feature, and concept drift allows teams to intervene when necessary, retraining models and updating deployment pipelines to maintain predictive accuracy. A well-monitored model lifecycle enhances organizational confidence, enabling data-driven decision-making with minimal disruption from evolving data distributions.
In preparation for the Databricks Machine Learning Professional certification, combining theoretical knowledge with hands-on experience in managing Delta tables, tracking experiments with MLflow, orchestrating model lifecycles, deploying models across various paradigms, and monitoring performance underpins a robust foundation for success. The comprehensive understanding of these components ensures that candidates are well-equipped to tackle real-world machine learning challenges and demonstrates mastery of the operational and analytical capabilities of Databricks.
Data Management, Experiment Tracking, and Advanced Workflows
Databricks provides an extensive environment that enables meticulous management of data, experimentation, and machine learning workflows. At the heart of its utility lies the capacity to handle Delta tables, which act as highly reliable storage constructs supporting versioned datasets with transactional integrity. Reading and writing to these tables is seamless, allowing data practitioners to access structured data efficiently and maintain historical records for analysis and reproducibility. The capability to view historical snapshots of tables and load previous versions enhances experiment repeatability, enabling practitioners to evaluate model performance under varying conditions and data scenarios without the risk of inconsistency. The orchestration of feature stores further complements this ecosystem by allowing the creation, merging, overwriting, and reading of feature tables. Feature stores serve as centralized repositories where features are curated, standardized, and shared, reducing redundancy and improving collaboration across teams. They also allow for the integration of features into machine learning workflows efficiently, ensuring that training and inference processes are consistent and accurate.
Tracking machine learning experiments is an indispensable part of Databricks’ operational framework. Using MLflow, users can capture all relevant experiment details, including parameters, metrics, models, and artifacts. This tracking can be conducted both manually and programmatically, providing flexibility depending on the workflow and complexity of the experiments. Manually logging details allows practitioners to annotate experiments with qualitative insights and observations, while programmatic logging ensures automated capture of iterative runs, particularly in scenarios involving hyperparameter tuning or repeated model training. Through this logging, users establish a detailed provenance of experiments, enabling comparisons across different configurations, evaluation of model performance trends, and informed decision-making on subsequent experimentation. Artifacts logged in these workflows can include visualizations, feature distributions, performance metrics, and other analytical outputs that provide interpretability and facilitate communication with stakeholders.
Advanced experiment tracking in Databricks builds upon foundational logging by incorporating model signatures, input examples, and nested runs. Model signatures describe the expected schema of inputs and outputs for a model, ensuring consistency and preventing errors during deployment. Input examples provide concrete data instances that serve as references for validating model behavior and verifying transformations applied during preprocessing. Nested runs allow for hierarchical tracking of experiments, capturing dependencies between sub-experiments and overarching workflows. Autologging, a feature integrated with MLflow, automates the capture of parameters, metrics, and artifacts during model training, including scenarios involving hyperparameter optimization with tools such as Hyperopt. This reduces the cognitive and operational burden on practitioners while enhancing reproducibility and standardization across workflows. Additionally, artifacts like SHAP plots, custom visualizations, feature distributions, and images can be logged alongside metadata, providing comprehensive insights into model interpretability, fairness, and feature importance.
In practical terms, efficient data management and experiment tracking in Databricks enable rapid iteration of machine learning workflows. By maintaining Delta tables and feature stores, practitioners can ensure that experiments are reproducible and that model training leverages consistent and high-quality data. Tracking experiments with MLflow ensures transparency, traceability, and accountability, which are critical in production environments where model decisions can have significant consequences. The integration of advanced tracking techniques allows teams to manage complex workflows with multiple interdependent experiments, facilitating exploration while maintaining control over data lineage and model evolution.
Preprocessing logic is another critical aspect of experimentation that impacts model performance and operational efficiency. By embedding preprocessing steps within custom model classes, practitioners ensure that transformations are applied consistently during both training and inference. This includes scaling, encoding, normalization, or other feature engineering operations essential to model accuracy. Databricks supports the use of MLflow flavors, including the pyfunc flavor, which standardizes model formats and enables seamless deployment across environments. Including preprocessing logic within these models enhances reproducibility, ensures that predictions remain consistent, and simplifies operationalization by encapsulating all necessary transformations within the model artifact itself.
The management of machine learning models extends to the lifecycle phase, where models are registered, versioned, and annotated with metadata in the Model Registry. Registering a new model or a new model version allows teams to maintain a structured inventory of assets, track performance over time, and coordinate deployment workflows efficiently. Metadata associated with models, such as performance metrics, descriptive tags, and business context, provides additional insights that facilitate evaluation, monitoring, and comparison across versions. Understanding and managing model stages—such as development, staging, production, or archived—is essential for operational rigor. Transitions between stages, archiving outdated versions, and deletion of obsolete models are all part of maintaining a clean, organized, and compliant model repository.
Automation of model lifecycle processes further elevates operational efficiency. Databricks allows the integration of Webhooks and Jobs to automate the promotion of models across stages, execution of testing pipelines, and monitoring of model performance. Automated testing ensures that new models or versions meet predefined quality thresholds before deployment, reducing risk and improving reliability. Job clusters, as opposed to all-purpose clusters, offer optimized performance for specific tasks, enhancing computational efficiency and resource utilization. By linking Webhooks with Jobs, teams can establish responsive and event-driven workflows that trigger actions when models change state, ensuring timely intervention and consistent operations. These workflows enable organizations to adopt continuous integration and continuous delivery principles within their machine learning pipelines, maintaining agility and robustness.
Deploying models efficiently requires an understanding of the appropriate deployment paradigm for different scenarios. Batch deployment is suitable for scenarios where large-scale predictions can be precomputed and stored, enabling downstream systems to query these predictions efficiently without incurring real-time computational overhead. Batch scoring leverages optimizations such as data partitioning and indexing strategies to enhance retrieval performance. Streaming deployment, often implemented with Structured Streaming, supports continuous inference on incoming data, handling complexities such as out-of-order arrivals, time windows, and dynamic transformations. This approach ensures that insights are delivered promptly in contexts where data flows continuously and decisions must be made in near real time. Real-time deployment addresses scenarios requiring immediate predictions, often for a small number of records or latency-sensitive use cases. By integrating just-in-time computation of features and deploying models via serving endpoints, practitioners can ensure rapid and reliable predictions for operational decision-making.
Monitoring the deployed models is essential to maintain their predictive performance over time. Drift detection plays a pivotal role in this monitoring, helping teams identify when the statistical properties of data or the relationships captured by models have changed. Label drift refers to changes in the distribution of the target variable, whereas feature drift occurs when input features evolve over time, potentially affecting model accuracy. Concept drift represents the more subtle scenario in which the mapping between inputs and outputs changes, potentially leading to degraded model performance. Detecting and measuring drift involves statistical techniques and monitoring workflows that capture changes in distributions, trends, and relationships. Summary statistics provide a straightforward approach for monitoring numeric or categorical features, while more sophisticated techniques such as divergence measures, Kolmogorov-Smirnov tests, or chi-square tests offer robust detection of shifts in data distributions. Comprehensive drift monitoring allows teams to determine when retraining is necessary, ensuring that models remain effective and relevant in dynamic environments.
Practical exercises and hands-on activities are integral to mastering experimentation and data management in Databricks. Working with Delta tables, creating and managing feature stores, logging experiments with MLflow, and implementing nested and automated tracking workflows deepen understanding and improve operational skills. Experimenting with preprocessing logic, model registration, lifecycle automation, and deployment scenarios provides real-world context that reinforces theoretical knowledge. By engaging with these activities, practitioners build intuition about the interactions between data, models, and operational workflows, preparing them for both certification assessments and actual production challenges.
From an exam preparation perspective, the Databricks Machine Learning Professional certification evaluates a candidate’s ability to manage and monitor experiments, apply preprocessing logic, register and version models, and deploy models efficiently. Understanding the full spectrum of experimentation workflows, including advanced tracking and automation, is crucial. Familiarity with Delta tables, feature stores, MLflow logging, nested runs, autologging, model signatures, input examples, and artifacts ensures that candidates can demonstrate operational competence and theoretical mastery. Integrating practical experience with conceptual understanding enables learners to navigate complex workflows, maintain reproducibility, and deploy models with confidence.
In addition to the fundamental workflows, Databricks encourages practitioners to cultivate a mindset of continuous improvement and experimentation. This involves iterating on model designs, evaluating feature transformations, tuning hyperparameters, and analyzing the impact of each change systematically. By combining meticulous record-keeping with advanced logging and automation, teams can develop a culture of transparency and accountability, which is indispensable for high-stakes machine learning projects. Experimentation in Databricks is not merely about achieving higher accuracy; it is about understanding the underlying dynamics of models, data, and workflows to make informed decisions and maintain operational excellence.
The interplay between data management and experiment tracking is particularly significant in production-oriented machine learning. Efficient use of Delta tables and feature stores ensures data integrity, reduces redundancy, and streamlines feature engineering. MLflow facilitates a robust and structured approach to experiment documentation, allowing for granular tracking of parameters, metrics, and model artifacts. Advanced features such as nested runs, autologging, and artifact management enhance this capability, providing a comprehensive overview of experiments while maintaining reproducibility and interpretability. This combination of structured data management and rigorous tracking forms the backbone of operationally robust machine learning workflows within Databricks.
Preprocessing Logic, Model Management, and Automated Workflows
In the realm of machine learning, the orchestration of models from conceptualization to deployment requires meticulous attention to preprocessing logic, lifecycle management, and automated workflows. Databricks offers an integrated environment where these elements converge, allowing practitioners to construct robust, reproducible, and operationally efficient machine learning systems. Preprocessing is not merely a preliminary step; it forms the cornerstone of model reliability and accuracy. Embedding preprocessing logic directly into custom model classes ensures that transformations such as normalization, scaling, encoding, and feature engineering are consistently applied both during training and inference. This approach mitigates the risk of data inconsistencies and guarantees that models behave predictably across diverse environments. Databricks supports this practice through its MLflow integration, enabling models to encapsulate preprocessing steps along with metadata, making them self-sufficient artifacts ready for deployment.
MLflow flavors, including the pyfunc flavor, offer additional versatility by standardizing the format of models, allowing them to be deployed across multiple platforms without compatibility issues. By maintaining a consistent schema for input and output, models packaged with these flavors enhance reproducibility, simplify operationalization, and reduce the likelihood of runtime errors. The inclusion of preprocessing logic within these flavors ensures that all transformations, validations, and feature manipulations are embedded within the model artifact itself, streamlining the transition from experimentation to production. This embedded logic becomes particularly valuable when models are deployed at scale, where manual preprocessing or environment-dependent transformations could introduce errors or inconsistencies.
Model management in Databricks revolves around the Model Registry, a centralized repository where models are registered, versioned, and annotated with metadata. The registry provides a structured framework for maintaining multiple model versions, tracking their evolution, and ensuring traceability across the lifecycle. Registering a model or a new model version allows teams to preserve historical performance records, compare different configurations, and manage stage transitions systematically. Metadata associated with each model, including descriptive tags, performance metrics, and contextual notes, enriches the registry by providing insight into the operational and analytical characteristics of the model. This facilitates informed decision-making when promoting models to production or archiving outdated versions. The concept of model stages, such as development, staging, production, and archived, provides a framework for operational governance, enabling teams to monitor model readiness and implement controlled transitions between stages.
Automation plays a pivotal role in model lifecycle management, ensuring that workflows are efficient, reliable, and minimally dependent on manual intervention. Databricks Jobs and Model Registry Webhooks allow teams to orchestrate automated actions such as testing, validation, and deployment when specific events occur. Jobs can be configured to execute on job clusters, which provide optimized performance compared to all-purpose clusters, enabling efficient resource utilization for computationally intensive tasks. Webhooks serve as triggers that respond to changes in model state, such as the promotion of a model from staging to production, ensuring timely execution of dependent workflows. This event-driven automation facilitates continuous integration and continuous delivery practices within machine learning pipelines, reducing operational overhead and enhancing reliability.
Automated testing within the model lifecycle is essential to verify that new models or updated versions meet predefined quality standards before deployment. Testing can encompass a variety of checks, including performance evaluation on holdout datasets, validation of preprocessing logic, and assessment of model robustness under edge-case scenarios. Integrating these tests into automated pipelines ensures that only models meeting rigorous standards progress to production, minimizing risk and maintaining operational integrity. The combination of automated testing, lifecycle automation, and event-driven workflows allows teams to maintain agility while ensuring consistency and compliance across all stages of model management.
The orchestration of model transitions and stage management is a critical aspect of operational control. Models in Databricks can transition between stages such as development, staging, and production based on performance criteria, business requirements, or regulatory considerations. Automated workflows can monitor these transitions and trigger corresponding Jobs, ensuring that downstream systems and processes respond appropriately. Archiving older model versions preserves historical records while preventing confusion and ensuring clarity in production environments. Deleting obsolete models, when necessary, maintains a clean registry and prevents resource bloat. The combination of stage management, automated triggering, and lifecycle orchestration provides a comprehensive framework for maintaining operational rigor and governance.
Practical exercises in Databricks reinforce these concepts by allowing practitioners to engage directly with preprocessing logic, model registration, and lifecycle automation. Building custom model classes that encapsulate feature engineering, registering multiple model versions, annotating metadata, and implementing automated Jobs and Webhooks creates a realistic simulation of production workflows. This hands-on experience enables practitioners to understand the interplay between data, models, and operational workflows, while fostering an appreciation for reproducibility, scalability, and operational reliability.
Deploying models effectively requires understanding the nuances of different deployment paradigms. Batch deployment is suitable for large-scale predictions where precomputation and storage allow downstream querying without real-time computational demands. Databricks optimizes batch deployments through efficient data partitioning, indexing, and the use of precomputed score operations. This approach reduces latency and ensures that predictions are accessible for analysis and decision-making in a timely manner. Streaming deployment, conversely, supports continuous inference on dynamic data streams. Structured Streaming allows for handling complex business logic, out-of-order data, and time-based aggregation, ensuring that insights are delivered promptly and reliably. Transitioning batch pipelines to streaming workflows provides operational flexibility, enabling teams to adapt to evolving data ingestion patterns and business requirements.
Real-time deployment is reserved for scenarios where rapid predictions are crucial, often involving latency-sensitive decision-making or small-scale inference tasks. Real-time deployment leverages just-in-time computation of features, model serving endpoints, and optimized computational resources to deliver immediate results. Cloud-based RESTful services facilitate these deployments by providing scalable, production-grade infrastructure capable of handling multiple concurrent requests while maintaining low latency. Integrating preprocessing logic, automated lifecycle workflows, and deployment pipelines ensures that real-time models operate consistently and reliably, providing confidence in operational decision-making.
Monitoring and maintaining deployed models remains a critical responsibility to ensure sustained performance. Drift detection is a fundamental aspect of monitoring, allowing teams to identify when models are exposed to shifts in data distribution or conceptual relationships. Label drift occurs when the distribution of the target variable changes over time, potentially impacting predictive accuracy. Feature drift arises when input features evolve, altering the underlying relationships captured by the model. Concept drift, a more intricate phenomenon, reflects changes in the functional relationship between inputs and outputs, often requiring model retraining or recalibration. Monitoring tools within Databricks enable practitioners to assess these shifts using statistical measures, divergence metrics, and robust testing methodologies. Techniques such as Jensen-Shannon divergence, Kolmogorov-Smirnov tests, and chi-square tests provide quantitative assessments of drift, facilitating timely intervention to preserve model integrity.
Practical exercises in lifecycle management reinforce theoretical knowledge, allowing practitioners to experience firsthand the processes of registering models, tracking performance, automating workflows, and responding to drift. Engaging with these tasks develops a nuanced understanding of how preprocessing, deployment, automation, and monitoring interconnect within operational machine learning workflows. Experimenting with lifecycle automation, Webhooks, Jobs, and stage management strengthens the ability to maintain reproducible, scalable, and reliable model pipelines.
Databricks emphasizes reproducibility and operational rigor in managing machine learning models. By embedding preprocessing logic within models, utilizing MLflow flavors, registering models systematically, and automating workflows, practitioners can maintain a consistent and efficient operational environment. Monitoring deployed models for drift, evaluating performance against historical metrics, and implementing corrective actions are essential practices for sustaining high-quality predictions. Hands-on experience with these processes ensures that candidates are well-prepared for certification assessments and capable of managing production-level machine learning systems.
Effective model lifecycle management in Databricks requires balancing experimentation, operational automation, and monitoring. Preprocessing logic ensures consistency, MLflow integration supports reproducibility, and the Model Registry provides structured governance. Automated Jobs and Webhooks facilitate event-driven workflows, while robust drift detection maintains performance over time. By mastering these interconnected aspects, practitioners develop the skills necessary to construct operationally sound, scalable, and maintainable machine learning pipelines.
Understanding these workflows also underscores the importance of practical engagement. Creating custom models, embedding preprocessing, registering multiple versions, annotating metadata, configuring automated Jobs, and monitoring deployed models form an integrated framework for managing the end-to-end lifecycle of machine learning models. Each component contributes to operational efficiency, reproducibility, and reliability, which are essential for success in real-world applications and certification evaluation.
Batch, Streaming, and Real-Time Deployment Strategies
Deploying machine learning models requires a nuanced understanding of different operational environments, each with its own constraints and advantages. Databricks provides a versatile platform that accommodates batch processing, streaming, and real-time inference, enabling practitioners to address diverse production requirements. Batch deployment is the most common approach for large-scale prediction tasks where precomputing and storing results are feasible. In this paradigm, models process large datasets in parallel, generating predictions that are saved for later access. Batch deployment optimizes computational efficiency, allowing teams to process millions of records without the overhead of real-time computation. Data partitioning and indexing strategies enhance the performance of batch operations, ensuring that queries against precomputed predictions are fast and scalable. The ability to load registered models seamlessly for batch scoring simplifies the operational workflow, allowing teams to maintain consistency across multiple deployments and data sources.
Streaming deployment addresses scenarios where continuous, near-real-time inference is required on incoming data streams. Structured Streaming, a cornerstone of Databricks’ streaming capabilities, allows models to process data incrementally while handling challenges such as late-arriving data, time windowing, and dynamic transformations. Continuous inference in a streaming environment ensures that insights are timely, enabling operational systems to respond immediately to changing conditions. Streaming pipelines often originate from batch pipelines, which can be converted to streaming workflows to accommodate evolving business needs. Handling out-of-order data, integrating complex business logic, and maintaining stateful transformations are critical components of successful streaming deployment. These capabilities allow organizations to build predictive systems that operate reliably under fluctuating data volumes and velocity, ensuring that models remain effective in dynamic environments.
Real-time deployment caters to use cases requiring immediate predictions, often with low latency requirements or a small number of records. Just-in-time computation of features ensures that models receive up-to-date information at the moment of inference, enhancing predictive accuracy and operational relevance. Real-time deployments often leverage model serving endpoints, which allow multiple stages of a model, such as production and staging, to coexist and respond to queries simultaneously. Cloud-based RESTful services provide scalable, resilient infrastructure for these endpoints, ensuring that real-time predictions are delivered consistently even under high concurrency. This deployment paradigm is essential for applications such as fraud detection, recommendation engines, dynamic pricing, and operational decision support, where delayed predictions could result in financial or operational losses.
Batch deployments can benefit from strategic optimizations such as partitioning and z-ordering, which reduce data access times and enhance throughput. Partitioning on common columns allows queries to target specific subsets of data, minimizing unnecessary computation. Z-ordering optimizes the layout of data on disk, improving read efficiency and decreasing latency for batch scoring operations. By combining these strategies with the score_batch operation, teams can achieve significant performance improvements while maintaining accuracy and consistency in predictions. Batch deployment is particularly suited for scenarios where predictions are required periodically, such as nightly scoring, end-of-day reporting, or aggregated insights for operational dashboards.
Streaming pipelines provide continuous inference and require careful attention to processing semantics. Structured Streaming supports exactly-once processing, watermarking, and stateful aggregations, which ensure that predictions are accurate even in the presence of late-arriving or duplicate data. Complex business logic can be embedded directly into streaming pipelines, allowing models to interact with rules, thresholds, and dynamic calculations in real time. The ability to convert batch pipelines into streaming workflows adds operational flexibility, enabling teams to adapt to real-time requirements without rebuilding their entire infrastructure. Continuous predictions can be stored in time-based prediction stores, providing a historical record of model outputs that can be used for analysis, monitoring, and auditing purposes.
Real-time deployments emphasize immediacy and accuracy in scenarios where latency is critical. Serving endpoints allow models to respond to queries with minimal delay, while just-in-time feature computation ensures that the input data is fresh and relevant. These deployments often coexist with batch and streaming systems, providing a layered approach to inference that balances computational efficiency with responsiveness. Real-time predictions are particularly valuable for interactive applications, operational decision-making, and event-driven systems where immediate insights can influence outcomes. Cloud infrastructure supporting real-time deployments offers scalability, fault tolerance, and integration with external applications, ensuring that production-grade models operate reliably under varying loads.
Monitoring deployed models is essential to ensure sustained performance across all deployment paradigms. Drift detection helps practitioners identify changes in data distributions, feature relevance, or conceptual relationships that may impact model accuracy. Label drift occurs when the distribution of the target variable changes, potentially affecting predictive reliability. Feature drift reflects changes in the statistical properties of input features, which may necessitate recalibration or retraining. Concept drift represents shifts in the functional relationship between inputs and outputs, requiring more sophisticated interventions to maintain model efficacy. Detection methods include summary statistics for numeric and categorical features, as well as more robust techniques such as Jensen-Shannon divergence, Kolmogorov-Smirnov tests, and chi-square tests. By identifying drift proactively, teams can implement corrective actions, retrain models, and update deployment pipelines to maintain operational relevance.
The interplay between deployment strategies and monitoring practices is critical for operational excellence. Batch deployments allow for large-scale predictions with minimal computational overhead, streaming pipelines provide near-real-time insights on dynamic data, and real-time endpoints deliver immediate predictions for latency-sensitive applications. Monitoring these deployments ensures that models remain accurate and reliable, regardless of the frequency, volume, or velocity of the data. Effective monitoring also supports compliance, governance, and transparency, allowing organizations to maintain accountability in production machine learning workflows.
Hands-on practice with deployment scenarios reinforces theoretical knowledge and operational skills. Implementing batch scoring pipelines, converting them to streaming workflows, and configuring real-time endpoints provide a comprehensive understanding of the deployment landscape in Databricks. Monitoring model performance, detecting drift, and applying corrective measures offer practical experience that mirrors real-world challenges. These exercises develop proficiency in orchestrating complex deployments while maintaining reproducibility, accuracy, and efficiency. They also prepare practitioners for certification assessments by demonstrating mastery of operational workflows and deployment strategies.
Batch, streaming, and real-time deployments each present unique challenges and require specialized knowledge. Batch deployments emphasize scalability, partitioning, and efficient storage. Streaming workflows demand expertise in incremental processing, state management, and handling dynamic data flows. Real-time inference requires knowledge of low-latency infrastructure, just-in-time computation, and endpoint management. Understanding the trade-offs, advantages, and limitations of each approach allows practitioners to design deployment strategies that are tailored to specific business needs and operational constraints.
Automated workflows and lifecycle integration further enhance the deployment process. By linking model transitions in the Model Registry to Jobs and Webhooks, teams can automate scoring pipelines, retraining tasks, and monitoring alerts. These integrations ensure that predictions are generated consistently, models are retrained as needed, and operational anomalies are addressed promptly. Automation reduces manual intervention, mitigates risk, and maintains continuity in production workflows. Combining automated workflows with robust deployment practices creates a resilient infrastructure that supports continuous machine learning operations at scale.
Feature computation is integral to all deployment paradigms. In batch deployments, features are often precomputed and stored, reducing computational demands during scoring. In streaming and real-time scenarios, features may need to be computed just-in-time to ensure that predictions reflect the most current data. Embedding preprocessing logic within models ensures that feature transformations are applied consistently across deployments, enhancing accuracy and reproducibility. This approach also simplifies operational workflows, reducing the risk of errors and inconsistencies when models transition between different deployment environments.
Operational monitoring extends beyond drift detection. Logging predictions, tracking feature distributions, evaluating performance metrics, and capturing anomalies provide a holistic view of model behavior in production. These practices enable teams to identify deviations from expected outcomes, assess model reliability, and maintain confidence in predictive systems. Monitoring strategies should be aligned with deployment paradigms, with batch scoring pipelines emphasizing aggregate evaluation, streaming workflows focusing on temporal trends, and real-time endpoints highlighting instantaneous performance.
Deployment strategies in Databricks are designed to be adaptable and scalable. Models can transition seamlessly from experimentation to batch, streaming, or real-time environments without requiring extensive reengineering. Preprocessing logic, MLflow integration, automated workflows, and monitoring tools collectively provide a framework that supports operational excellence across deployment paradigms. This versatility ensures that organizations can respond to evolving business requirements, maintain high predictive accuracy, and achieve operational efficiency in diverse production contexts.
Hands-on engagement with deployment scenarios enhances both practical skills and conceptual understanding. Practitioners gain experience configuring batch scoring, designing streaming pipelines, implementing real-time endpoints, and monitoring model performance. These exercises cultivate familiarity with the operational intricacies of machine learning systems, including latency management, feature computation, state handling, and drift detection. By actively deploying and monitoring models, practitioners develop confidence in their ability to manage production-grade machine learning workflows effectively.
Understanding the interactions between deployment strategies, preprocessing logic, automation, and monitoring is essential for operational proficiency. Each deployment paradigm presents unique considerations, but all share the need for consistent feature handling, model versioning, reproducibility, and performance evaluation. Databricks provides the tools and infrastructure to integrate these elements into cohesive workflows that support continuous machine learning operations. Practitioners who master these interactions are equipped to design and maintain predictive systems that are both scalable and reliable, meeting the demands of complex production environments.
Drift Detection, Monitoring, and Comprehensive Model Oversight
Ensuring that machine learning models continue to perform accurately in production requires continuous monitoring, comprehensive drift detection, and an overarching framework for maintaining model integrity. Databricks provides a robust environment for managing these challenges, enabling practitioners to track model behavior, detect deviations in data patterns, and implement corrective actions to preserve predictive accuracy. Monitoring is not merely a reactive practice; it represents a proactive strategy to ensure that models adapt to evolving data distributions, operational changes, and business requirements. By embedding monitoring into the machine learning lifecycle, teams can achieve greater reliability, reproducibility, and resilience in their predictive systems.
Drift detection is a fundamental aspect of monitoring deployed models. Feature drift occurs when the statistical distribution of input variables changes over time, potentially reducing the effectiveness of a model that was trained on historical data. Label drift arises when the distribution of the target variable shifts, which can undermine the assumptions underlying model predictions. Concept drift represents a more complex scenario where the relationship between inputs and outputs evolves, necessitating retraining or recalibration to maintain accuracy. Detecting these drifts requires statistical techniques, analytical frameworks, and continuous observation of model behavior. Practitioners must be able to discern subtle changes in data distributions and identify scenarios in which intervention is necessary to maintain operational performance.
Monitoring solutions in Databricks employ a variety of methods to detect drift and ensure model efficacy. Summary statistics, such as mean, median, mode, and variance, provide a straightforward approach for numeric feature monitoring, while mode, unique values, and missing value counts offer insight into categorical feature stability. These methods allow teams to detect anomalies and deviations in feature distributions efficiently. However, more robust approaches are often required for production-grade monitoring. Techniques such as Jensen-Shannon divergence, Kolmogorov-Smirnov tests, and chi-square tests provide rigorous statistical measures to quantify differences between historical and current data distributions. These tools allow practitioners to detect both gradual and abrupt changes, ensuring timely interventions to mitigate the impact of drift.
Implementing comprehensive drift detection requires integrating these statistical techniques into automated workflows. By monitoring feature and label distributions continuously, teams can identify shifts that may compromise model predictions. Automated alerts can trigger retraining pipelines, notifying stakeholders when models require updates. Incorporating drift detection into the broader lifecycle ensures that models remain relevant and accurate over time. This approach not only preserves predictive performance but also maintains operational confidence in the decisions informed by machine learning systems.
Retraining models in response to detected drift is a critical operational consideration. When feature or concept drift is identified, models may no longer reflect the underlying relationships present in new data. Databricks allows practitioners to retrain models using updated datasets, incorporating both historical and recent observations to improve generalization and performance. Retraining workflows can be automated, leveraging jobs, webhooks, and cluster resources to ensure that updated models are deployed efficiently. Evaluating the performance of retrained models on recent data ensures that updates provide tangible improvements, avoiding unnecessary interventions or resource expenditure. This iterative process of monitoring, retraining, and evaluation is essential for sustaining model efficacy in dynamic environments.
Comprehensive monitoring also encompasses the evaluation of model predictions over time. Tracking performance metrics, analyzing residuals, and observing deviations from expected behavior provide insights into operational effectiveness. These evaluations can identify emerging patterns, anomalies, or systemic issues that may affect predictive outcomes. By coupling performance monitoring with drift detection, practitioners can maintain a holistic view of model behavior, ensuring that both input distributions and predictive outputs remain aligned with operational requirements. This dual approach facilitates early intervention and prevents degradation of model reliability, which is critical for maintaining trust in production systems.
Practical applications of monitoring solutions involve combining statistical analysis with operational workflows. By observing numeric and categorical feature distributions, tracking performance over time, and applying rigorous statistical tests, teams can identify scenarios in which drift is likely to occur. Monitoring pipelines can be configured to log relevant metrics, generate alerts, and trigger retraining or corrective actions automatically. These workflows integrate seamlessly with the broader model lifecycle, ensuring that monitoring, experimentation, deployment, and retraining operate cohesively. Practitioners gain experience in designing monitoring strategies that are both proactive and responsive, enabling them to maintain high-quality predictive systems over time.
Feature drift often occurs gradually, as data collected in operational environments may evolve due to changes in user behavior, external conditions, or business processes. Label drift may result from shifts in business objectives, policy adjustments, or changes in the underlying distribution of outcomes. Concept drift can be subtler, reflecting alterations in the relationships between features and target variables, potentially caused by evolving patterns, unobserved external factors, or complex interactions within the system. Recognizing these patterns requires continuous vigilance and robust analytical tools, as undetected drift can compromise decision-making, reduce confidence in model outputs, and erode the value of machine learning initiatives.
Incorporating drift detection into automated workflows enhances operational efficiency and resilience. Databricks allows for the creation of monitoring pipelines that continuously assess feature distributions, target variable stability, and predictive performance. Alerts can be configured to notify data teams when metrics exceed predefined thresholds, prompting immediate investigation and potential intervention. Integrating these pipelines with retraining workflows ensures that models adapt quickly to evolving data, maintaining their relevance and predictive capability. This proactive monitoring strategy reduces operational risk, enhances model robustness, and supports informed decision-making in dynamic environments.
Monitoring solutions also extend to the evaluation of artifacts generated during the experimentation and deployment phases. Visualizations of feature distributions, residual plots, and model interpretation outputs provide contextual understanding of model behavior. These artifacts complement quantitative drift detection by offering intuitive insights into how features influence predictions and where deviations may arise. By incorporating visual and analytical monitoring into operational workflows, teams can communicate model performance and drift assessments effectively to stakeholders, fostering transparency and trust in machine learning systems.
The integration of batch, streaming, and real-time deployments with monitoring workflows creates a resilient operational ecosystem. Batch deployments benefit from aggregated drift assessments and periodic evaluations of large datasets, while streaming deployments allow for continuous observation of dynamic data flows. Real-time endpoints require instantaneous monitoring of predictions and input features to ensure immediate intervention when anomalies are detected. Together, these deployment strategies, combined with comprehensive monitoring and drift detection, provide a layered approach that maintains model accuracy and operational reliability under varying conditions.
Practical engagement with monitoring pipelines strengthens both theoretical understanding and operational skills. By observing feature drift, label drift, and concept drift, configuring automated alerts, and integrating retraining workflows, practitioners gain first-hand experience in maintaining high-quality machine learning models. These activities cultivate a deep comprehension of the interplay between data dynamics, model behavior, and operational interventions. Practitioners also learn to prioritize monitoring efforts, balancing computational resources with the need for timely detection and response, ensuring that models continue to provide actionable insights in production environments.
Monitoring is not limited to drift detection alone; it encompasses a holistic assessment of the machine learning ecosystem. Performance metrics such as accuracy, precision, recall, F1 score, and area under the curve provide insight into the efficacy of models over time. Observing trends, deviations, and anomalies in these metrics complements drift detection by highlighting potential operational issues. Combining performance evaluation with statistical monitoring of input features and targets ensures a comprehensive understanding of model health, enabling teams to implement targeted interventions that maintain predictive quality and operational integrity.
The operationalization of monitoring solutions benefits from automation and integration with existing workflows. Databricks allows teams to design event-driven monitoring pipelines, leveraging Jobs and Webhooks to trigger retraining, notifications, or additional analysis when drift or performance deviations are detected. Automation reduces the risk of delayed interventions, mitigates human error, and ensures that operational processes remain consistent and reliable. These integrated workflows enable continuous oversight of machine learning models, providing confidence that predictive systems remain accurate, robust, and aligned with business objectives.
By embedding monitoring, drift detection, and automated intervention into the model lifecycle, organizations achieve a resilient and adaptive machine learning infrastructure. Continuous observation, coupled with responsive workflows, ensures that models remain accurate and relevant even as operational conditions evolve. This approach fosters operational confidence, enhances reproducibility, and maximizes the value of machine learning initiatives by maintaining high standards of predictive performance. Teams gain the ability to identify and address issues proactively, ensuring that models continue to deliver meaningful insights across diverse operational contexts.
Practical experience with monitoring workflows also reinforces the conceptual understanding of model behavior and operational challenges. Configuring pipelines to assess feature distributions, track predictive performance, detect drift, and trigger retraining allows practitioners to develop intuition about the interactions between data, models, and operational environments. This hands-on engagement enhances problem-solving skills, encourages proactive intervention, and prepares individuals for managing production-grade machine learning systems effectively. By integrating theoretical knowledge with practical execution, teams can maintain a high level of operational rigor and resilience.
Embedding monitoring practices within a broader operational framework also emphasizes transparency, accountability, and governance. Documenting monitoring results, drift assessments, retraining actions, and performance evaluations provides a comprehensive record of model operations. This documentation supports audits, regulatory compliance, and organizational oversight, ensuring that stakeholders understand the decision-making processes driven by machine learning systems. Maintaining clear records of model behavior, interventions, and performance ensures that operational teams can respond effectively to both routine and exceptional scenarios, reinforcing confidence in predictive outcomes.
The combination of drift detection, performance monitoring, automated workflows, and operational governance forms a comprehensive framework for sustaining machine learning models. By continuously observing feature and label distributions, evaluating model performance, and integrating retraining workflows, organizations can maintain predictive accuracy and operational relevance. Practitioners equipped with these skills are prepared to manage the complexities of dynamic production environments, ensuring that machine learning systems deliver consistent and reliable insights over time. This holistic approach emphasizes the importance of proactive monitoring, structured interventions, and continuous evaluation in sustaining high-quality models.
Monitoring solutions and drift detection are crucial components of the Databricks Machine Learning Professional certification. The examination assesses a candidate’s ability to implement these practices effectively, demonstrating operational proficiency, analytical acumen, and practical experience. Understanding the interplay between monitoring, retraining, and performance evaluation ensures that candidates can manage production-grade machine learning systems with confidence. Mastery of these concepts equips practitioners to address real-world challenges, maintain operational resilience, and achieve sustained predictive performance in diverse applications.
Conclusion
In sustaining machine learning models in production demands a comprehensive and integrated approach to monitoring, drift detection, and operational oversight. Databricks provides a versatile environment that supports batch, streaming, and real-time deployments, enabling practitioners to deploy models effectively and observe their behavior continuously. Feature drift, label drift, and concept drift are critical considerations, requiring robust statistical methods and proactive intervention. Automated workflows, integrated with monitoring pipelines, enhance operational efficiency and ensure timely retraining and corrective actions. By combining performance evaluation, statistical monitoring, and operational governance, organizations can maintain high standards of predictive accuracy, reproducibility, and resilience. Hands-on experience with monitoring workflows, drift detection, and automated interventions reinforces theoretical understanding and operational skills, preparing practitioners for both certification assessments and the management of production-grade machine learning systems. The holistic integration of these practices ensures that models continue to deliver reliable, actionable insights, maximizing the value of machine learning initiatives across evolving business and operational landscapes.
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Top Databricks Exams
- Certified Data Engineer Associate - Certified Data Engineer Associate
- Certified Data Engineer Professional - Certified Data Engineer Professional
- Certified Generative AI Engineer Associate - Certified Generative AI Engineer Associate
- Certified Data Analyst Associate - Certified Data Analyst Associate
- Certified Machine Learning Professional - Certified Machine Learning Professional
- Certified Machine Learning Associate - Certified Machine Learning Associate
- Certified Associate Developer for Apache Spark - Certified Associate Developer for Apache Spark
Databricks Certifications
- Apache Spark Developer Associate
- Databricks Certified Data Analyst Associate
- Databricks Certified Data Engineer Associate
- Databricks Certified Data Engineer Professional
- Databricks Certified Generative AI Engineer Associate
- Databricks Certified Machine Learning Associate
- Databricks Certified Machine Learning Professional
