
Exam Code: A00-211
Exam Name: SAS Base Programming for SAS 9
Certification Provider: SAS Institute
Corresponding Certification: SAS Certified Base Programmer for SAS 9
A00-211 Exam Product Screenshots
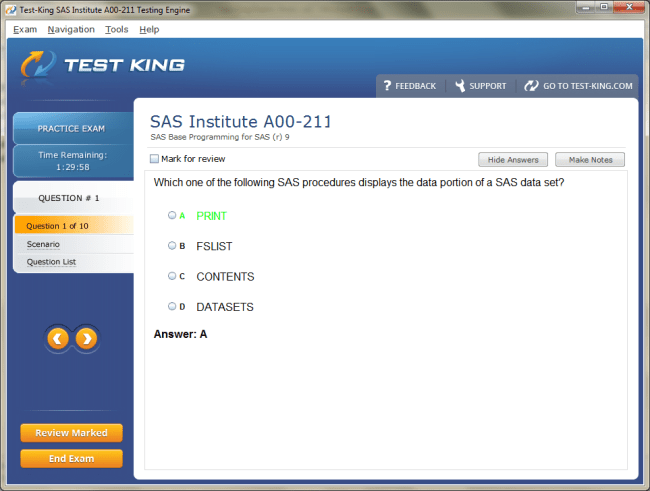
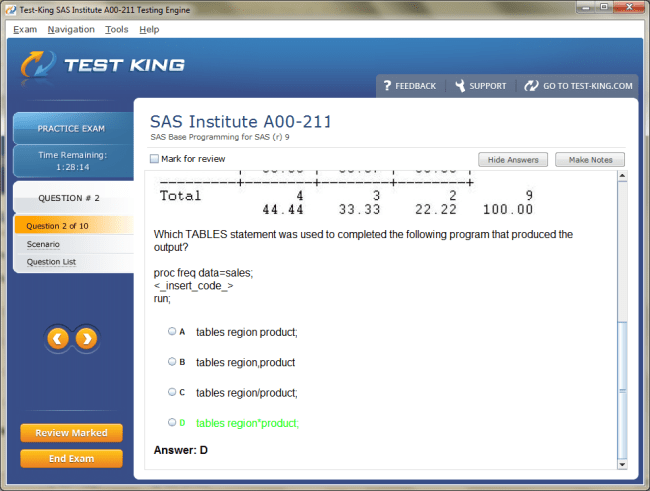
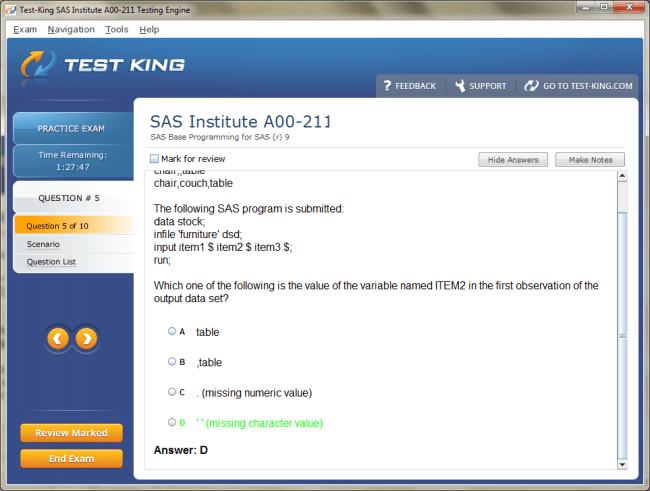
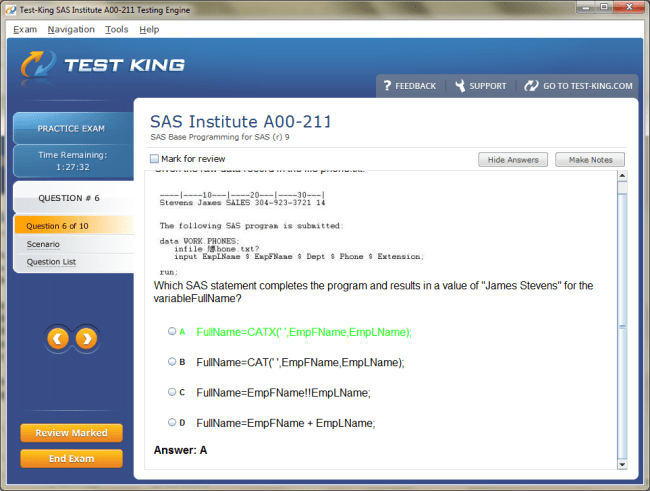
Product Reviews
The hottest exam engine
"Test king A00-211 exam engine is absolutely the hottest test tool for a long time. Test king SAS Institute A00-211 exam engine is reengineering the corporation between information and technology. Million of students trusted test king SAS A00-211 exam engine for their success, I think you should be one too.
Desmond Bishop"
Helps you to face major challenges
"i always find trouble in finding a connection between my labs and practical work. But test king A00-211 exam engine with its unique way of explaining the material solved my problem. I can now face the real world scenarios by keeping the preparation lab i experienced at test king SAS Institute A00-211 . Test king SAS A00-211 preparation labs, you are stunning.
Maria Kinsey"
Committed to unmatched performance
"Test king A00-211 exam engine is committed to give only the best. Test king SAS Institute A00-211 exam engine and the team behind it is working very to make you perform well. Test king SAS A00-211 exam engine is your key to success.
Kathie Julian"
Why test king is important
"Test king A00-211 exam engine is important in enhancement of skills and developing new ideas to show an outstanding result. Test king SAS Institute A00-211 audio exam is also very important because of its portability advantage offered by no one else. Trust test king SAS A00-211 exam engine and see the amazing change in your life.
William Patrick"
Test king Is always bringing improvement
"My friend was worried about his grades because he was not able to prepare well because of his job. Then i suggested him to use test king A00-211 exam engine for his convenience. He saved a lot of his time through test king SAS Institute A00-211 exam engine during his exam preparation and never compromised on the quality as well. Now my friend has got 80% marks just because of test king SAS A00-211 exam engine. thank you very much test king.
Alfred Tim"
Test king exam engine
"These days I am jobless and I have presented myself to the various boards of inverviewers but could not get a job. Every one said that your qualification is lesser than your job requirement. Then my cousin advised me that I should enhance my qualification first then seek a job. Finally I did pay heed to his advice and started exam preparation for A00-211 exam. For that purpose I bought test king exam engine which is, no doubt, very conducive to SAS Institute A00-211 exam preparation. It is concise, easy to understand and highly relevant to the actual exam questions. I practiced exam questions test king exam engine and passed my SAS A00-211 exam comfortably. Now I am, by the Grace of God, doing a job also in a very big organization.
Fernandes"
(I passed) All Four On First Attempt!! With My Lowest Score Being 81!!, Wow
"I am here to share my amazing success story. I passed SAS Institute exam with score of 81 out of 4 exams.Everyone was shocked to see the result of a dull student like me.This magic has been done by test king. I have passed my SAS Institute a00-211 exam so easily. Thanks a lot testking. -
James Ronald"
Test king study guide
"I reckon that those students who consider A00-211 exam very tough must have not bought test king study guide otherwise they would have a different perception. Test king study guide has been designed and developed according to the requirement of SAS Institute A00-211 exam. Therefore, all the questions and answers given in the study guide are very much relevant to the actual SAS A00-211 exam hence students easily tackle those questions presented in the real examination.
Wallace"
Your Study Guide Materials Are Very Effective
"Hey everyone I am a big promoter of Testking study guides and simulation. With the help of SAS Institute study guide I got 90% in SAS Institute a00-211 exam. This was like a dream coming true.Test kinn has wonderful mechanism of explanaing all the problems.I am will soon go for another exam. Thanks a lot.
Jones Hall"
Certification is now fun for me
"Testking made certification a complete fun for me. I have purchased my first SAS Institute study guide from here and I passed SAS certification with flying grades and now I will soon go for another.
- James Miller"
Passing a certification is no more a difficult thing
"With the help of testking's study guides and lab simulations for SAS Institute certification it is no more difficult. Just the way I passed SAS exam in one go and I am planning to go for another certification.
- David Moore"
Not only did I finish the test in 3 hours, but I got a 95%
"Wow that's really amazing I have passed my SAS Institute certification and got the SAS Institute a00-211 certification in just a month's preparation. Thanks a lot testking as I got this with the help of your SAS Institute practice exams.
- Robert Walker"
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Mastering DATA and PROC Steps: Core of the SAS Base Programming A00-211 Exam
The architecture of SAS Base Programming hinges upon the harmony between DATA and PROC steps, an alliance that shapes the foundation of data handling and statistical inference. Those preparing for the SAS Base Programming for SAS 9 certification often realize early that without a deep and intuitive comprehension of aforementioned components, success becomes elusive tangible yet elusive. The DATA step is responsible for data preparation, transformation, and creation of new data structures, whereas the PROC step orchestrates analytical and reporting capabilities. This — these two forces govern almost every operation conducted within the SAS environment, whether developing an analytic pipeline, importing clinical trial results, examining insurance policy metrics, evaluating healthcare outcomes, or refining business intelligence. Understanding these steps demands not only memorization but the cultivation of reasoning and discernment in how SAS processes data sequentially, how the Program Data Vector operates behind the scenes, and why execution flows from raw data to final insight.
Understanding the Foundation and Evolution of DATA and PROC Steps
Many individuals first encounter SAS as a tool renowned in industries such as finance, healthcare, pharmaceuticals, and government entities. There is immediate attraction to its reliability in handling enormous datasets, especially when the stakes involve regulatory compliance, therapeutic research, actuarial risk, or economic forecasting. Yet beneath the surface of the software interface lies the true essence of SAS Base Programming, which is the symbiotic use of DATA and PROC to manipulate, refine, and analyze data. To truly prepare for the SAS A00-211 exam, one must penetrate beyond superficial familiarity and enter the conceptual mechanics: how a DATA step initializes, how it compiles and executes, how variables originate from input sources, and how PROC steps depend entirely on the outcomes of prior DATA steps.
When beginning to study this phenomenon, many learners wonder why the SAS language is designed to separate these two fundamental operations. The reason is precision and modularity. SAS distinguishes data preparation from data analysis, thus empowering programmers to refine raw data before any summary, statistical test, or reporting method is attempted. The DATA step is where grit and creativity are applied. This step extends beyond mere movement of numbers; it is where missing values are addressed, new variables emerge through logic or calculation, and data sources are combined from disparate files or libraries. This process mirrors the work of a sculptor chiseling a block of marble before it becomes a masterpiece. On the other hand, PROC steps resemble the gallery exhibition, where the sculpted product is admired, interpreted, and given meaning. PROC enables descriptive statistics, frequency analysis, report generation, sorting of records, or complex analytics like regression and analysis of variance. Together, they create an everlasting dynamic, much like the interplay between preparation and performance.
To comprehend DATA steps, one must start with the conceptual basis of how SAS reads and writes. The moment a DATA step begins, SAS enters a compilation phase, constructing a blueprint of what must occur. Then, it transitions into execution, where each observation passes through the Program Data Vector, also called PDV. This temporary memory space houses variable values, tracks missing data, and updates record by record. Without seeing actual code, one can still envision the PDV as a sheet of canvas where each brushstroke adds variables, assigns values, or performs calculations. The KEY aspect is recognizing that the DATA step executes iteratively, operating on one observation at a time until reaching the end of the input source. This sequential rhythm is central to mastery. Those who falter on the exam often do so because they misunderstand how DATA step looping, automatic variables, or conditional logic influence the final dataset.
PROC steps, while seemingly straightforward, require equal mindfulness. They do not modify data in the same manner as DATA steps but instead read the prepared datasets and apply analytical or reporting procedures. Each PROC step is a request, asking SAS to perform a predefined operation on specified data. For example, when individuals need to determine average sales across various regions, or establish frequency of certain medical symptoms among patient groups, they instinctively turn to a PROC. Yet PROC steps rely wholly on the dataset built beforehand. If the DATA step contains errors, misaligned values, truncation of character variables, or flawed logic, the PROC step cannot redeem these foundational mistakes. Therefore, both steps must be internally consistent, like gears in a clock. One poorly formed gear, and the entire mechanism falters.
Another element of understanding this dual system is recognizing how SAS reads from external sources, whether they are spreadsheets, text files, databases, or proprietary formats. In professional environments, data is rarely pristine. It may contain inconsistent delimiters, unconventional date formats, truncated numeric values, or extraneous symbols. The DATA step becomes a sanctuary for rectifying aberrations. It is here that values are sanitized, character strings are parsed, and missing information is handled using conditional logic. Such meticulous processing is the difference between credible analysis and misleading conclusions. The SAS Base Programming exam places great emphasis on whether a candidate can envision how raw data flows into a DATA step, undergoes transformation, and emerges ready for analysis in PROC steps. The examiners are not only evaluating memory but also the capacity to reason through scenarios, such as: when multiple data sources contain different identifiers, how does one merge them conceptually? Or when observations contain repeated entries, how does one conceptually remove duplicates without direct syntax? These are not questions to be answered with code yet require clear thinking rooted in DATA step logic.
Invariably, the journey from raw data to refined analysis encapsulates numerous challenges. Candidates preparing for certification often embark on practice exercises where they simulate real-world scenarios. Imagine a scenario where health researchers aggregate data from several clinics. Each clinic files patient data separately, with variations in date formats, patient identifiers, and diagnostic codes. The task is to consolidate this disparate cluster into a coherent analytic dataset to evaluate treatment efficacy. In SAS, this entire conceptual process begins in a DATA step. First, sources are read; second, formats are standardized; third, irrelevant variables are dropped; fourth, new variables are generated to encapsulate deeper meaning such as age groups or risk levels; lastly, the refined dataset is saved. Only when this data is primed does a PROC step become useful, performing tasks like statistical summaries, determination of means, medians, percentiles, or generation of output listing regional health patterns. Candidates must be able to articulate this whole journey in a cohesive manner.
To cultivate a deeper perspective, it helps to trace the historical evolution of SAS and why its creators bifurcated data management and procedural analysis. SAS originated at North Carolina State University to assist agricultural researchers in analyzing crop data. This need demanded a system that could read data from punch cards or fixed-format files, manipulate values efficiently, and then apply statistical procedures. The two-step paradigm was born out of necessity, not fashion. Over decades, as SAS expanded into global industries, the separation between DATA and PROC proved beneficial for clarity, modularity, and error resolution. This historical lineage explains why the exam tests conceptual grounding and not mere syntax memorization.
Beyond the architecture and historical background lies the essential matter of efficiency and performance. When executing a DATA step on massive datasets, SAS processes record by record. A poorly conceptualized DATA step, such as one that performs redundant calculations or mismanages conditional flows, can waste processing time. Similarly, a PROC step applied on unrefined data can produce inaccurate or incomplete results. Thus, efficiency is not only measured in speed but in accuracy and clarity of thought. The certification exam subtly measures this by asking conceptual questions, such as how SAS handles datasets of differing lengths during a conceptual merge, or what happens when conditional logic in a DATA step excludes certain observations. The successful candidate can describe the internal workings without referencing explicit syntax.
The notion of input and output is another domain where DATA and PROC steps influence one another. In the DATA step, input refers to reading structured or unstructured data from storage, while output refers to writing processed data into new datasets. But output can also imply generating intermediate datasets that feed into the subsequent PROC step. In the PROC step context, input refers to an existing dataset, while output is usually analytical results, summary statistics, or externally rendered reports. Being able to articulate the difference between these interpretations of input and output, without code or a table, reflects strong command of SAS Base Programming principles.
Another critical theme is variable handling. Variables can be numeric or character. In the DATA step, variables emerge through reading from raw files or assignment via expressions, functions, or conditional mechanisms. Some variables are automatically created by SAS, such as a counter for observation number or a flag that indicates end-of-file. Understanding how these automatic variables behave provides a conceptual advantage in the exam because many questions subtly rely on knowledge of behind-the-scenes processes. If a dataset has missing values, SAS represents them differently for numeric and character variables. If a calculation involves a missing value, the result may propagate missingness. These behind-the-scenes rules of variable propagation and retention form a thin but crucial layer of understanding between novice and master.
Data cleansing, though intangible here without code, can still be articulated. It involves identifying anomalies, like extra spaces in character values, negative age values, inconsistent product codes, or dates that do not correspond to valid calendar formats. The DATA step becomes a laboratory where these anomalies are neutralized. For example, dates can be conceptually interpreted and standardized by describing how SAS reads them as numeric representations of days since a base date and can be reformatted once consistent. These transforms are executed within the DATA step domain and prepare the soil for PROC analysis to blossom.
The merging and combining of data represents another conceptual domain. When two datasets need to be combined side-by-side or appended, the DATA step provides the theoretical framework. Observation matching may occur based on unique identifiers or keys. If no matching occurs, certain records might be excluded or included depending on the logic imagined. The exam often tests whether the candidate understands how SAS conceptualizes merging: by aligning observations based on common variable names and processing them sequentially. Without writing any syntax, one must still be able to describe the flow: SAS reads the first dataset, then attempts to match observations from the second dataset based on key variables, then constructs a composite observation in the PDV, then writes the result to an output dataset. This mental cinema is part of the mastery expected.
Once the data has been sculpted, PROC steps perform operations like sorting, generating summary statistics, frequencies, or printing data content in reports. Conceptualizing these procedures involves picturing them as specialized tools, each designed for a specific objective. Even though we avoid code, one can imagine telling SAS: take this prepared dataset, sort it by region, compute the mean of salary, count the number of policyholders by category, or display the first hundred observations in a structured report. These are actions, not syntaxes. They transform data into insight. But remember, PROC does not alter data permanently; it reads and produces results unless explicitly instructed otherwise. Thus, clarity of mind regarding differences between temporary and permanent effects in both steps is frequently examined in certification.
Error awareness is indispensable. Candidates often ponder why certain values disappear silently, why some variables do not appear in expected output, or why a PROC step yields strange statistics. Most of the time, the answer lies in the preceding DATA step. Logical errors—such as forgetting to include conceptual rules for missing values, misunderstanding default variable lengths in concept, or failing to envision how SAS reads each row—can sabotage the intended result. PROC steps merely reveal the consequences. Therefore, analytical foresight and theoretical debugging skills are vital for exam proficiency. One should be able to reason, if a dataset contains more variables than expected, perhaps it is due to extraneous information not being conceptually removed during the DATA step. If the results display unexpected totals, perhaps certain records were excluded by a misinterpreted conditional concept. Such reflective thinking is indispensable.
As preparation deepens, learners begin to see patterns. They discover that DATA steps are like assembling the pieces of a mosaic, while PROC steps are akin to stepping back and interpreting the image. The SAS Base Programming exam does not expect perfect memory of every function but does expect a mental schema: how information flows, how transformation occurs, and how analysis depends on the foundation laid before. Within this schema arises another notion: sequencing. SAS processes steps in the order in which they are written. First come DATA steps to build or modify datasets, then PROC steps to analyze or report. If multiple DATA steps are presented, each creates a new or updated dataset. If multiple PROC steps are used, each performs an isolated request. Recognizing this temporal flow helps avoid conceptual chaos.
Lastly, think of the SAS environment not as a static platform but as a realm of logical sequences, choices, and consequences. Whether entities are dealing with epidemiological data, telecommunication usage records, academic scores, or logistics data, the methodology remains consistent. DATA steps clean and shape, PROC steps illuminate and reveal. Behind every statistical result lies a well-structured conceptual approach that likely began with a DATA step. Preparing for the SAS Base Programming for SAS 9 exam involves immersing oneself into this paradigm until it becomes second nature, until one can mentally process how data travels through the Program Data Vector and how PROC steps extract meaning from what has been shaped. Mastery does not stem from memorizing isolated commands but from understanding this fluid, dynamic procession of logic.
The Evolving Dynamics Within the DATA Step and Its Impact on PROC Interpretation
When moving deeper into the foundation of SAS Base Programming for SAS 9, it becomes essential to understand how the internal processing of a DATA step influences every choice that follows within a PROC step. These two components are inseparable, yet the complexity of the DATA step can drive the behavior of analysis in ways that are not always immediately visible. When preparing for the SAS Base Programming exam, one must begin to uncover the invisible mechanism that powers each observation, how variables emerge through expressions, how conditional logic influences dataset structure, and how everything eventually becomes the raw material that a PROC step can investigate. As the DATA step initiates, the system approaches the code in two stages: a preparation stage where the entire logic is read and mapped, and an execution stage where data from source files is actually processed, observation by observation. The method behind this comes from an established processing environment that records names of datasets, variable names, variable types, and any decision-making steps. This is often referred to as the compile-and-execute cycle, though the names are less important than the understanding of the mental dance taking place. The environment through which each record passes is known as the program data vector, which behaves as a mental table of variables and data that is repeatedly filled, examined, and cleared one row at a direction. Even without writing any code, one can imagine the process becoming like a lantern that shines on one record at a time, illuminating it with rules and transforming it into a coherent output before the lantern moves on to the next part of the data.
Within this careful movement, some variables will appear without the human declaring them. These appear as a product of the system itself. As each observation is processed, a counter increases, also a tracker for whether the end of the data has been reached. These variables play a significant part in the internal processing but rarely feature in the final analytic output. They exist to help this mental lantern keep track of its position. When planning for the exam, one must be able to describe how these numbers behave, how they change as more observations are read, and how they influence decision-making in the logic of the DATA step. If a condition appears that is meant to filter only certain rows, the internal instructions need to decide whether the current observation is ready to be saved or discarded. Because of this, the system will not add every record to the final dataset unless no conditions intervened. This means that the size and shape of the data at the beginning of a procedure is often affected by decisions made in the unseen steps that happened during the data preparation.
Sometimes, the data that exists before transformation is not clean, and nature of the DATA step becomes to convert messy information into consistent material. If values in a column are outdated or if a date is written with an unusual pattern, the data preparation process must use a series of logical decisions to correct or refine the information. When this is done by hand, but as a thought process and not by code, one should picture the situation of sorting text values into real names, adjusting numbers into meaningful units, and recognizing when missing values should be treated as unknown or unreported. Because SAS internally behaves with rules around missing data, when a number is absent, it treats it differently than when text is absent. If this is not known, then the behavior of the system can become confusing. For example, when a function tries to combine a numeric value with an empty space, the result can become empty, because the absence of numeric data is a problem that spreads to any calculation it touches. But if the empty value exists in a text field, then it is simply represented as no content, and the software manages the two types differently because of language of programming.
This theme of variables and how they are treated continues throughout the creation of datasets. If two or more sources of data need to be combined, the logic must decide how the records are matched, what happens if some observations do not have a match, and which fields are kept, removed, or renamed. When these two streams of information come together, the system must align them by a certain rule. This is also a topic commonly seen in the exam: what happens if two files are joined by one common variable, but the names in one dataset do not match the names in the other? And what if the common variable is missing from the second dataset? This can result in partial records, where some data is present while some space remains empty. The outcome of this process will determine whether the subsequent procedure can properly perform calculations, summaries, or sorting. If the investigator forgets to prepare, then the analytic part of the process can misinterpret the information.
One of the most interesting aspects of the DATA step is the concept of conditional decision-making. For example, if a measurement is above a certain value, the system might need to put the observation in a new category. It will create a new variable to display that the measurement belongs to a certain group. Without needing to write actual code, this can be represented when we think about data from a hospital where patients are sorted by age into minor, adult, and senior. The system needs to check each row, decide which age group it belongs to, and then assign the proper label. This logic is not only used for grouping but can also be used for removing records, renaming fields, and creating new columns. When the software has processed all of these considerations, we then arrive at the final dataset that any analytic procedure will rely on. If no data were checked at the moment of preparation, nothing in the analytic part of the procedure will be able to function. The two cannot be separated.
Another important aspect is understanding the concept of how the dictionary of the software behaves. This concept is sometimes used in preparing for the exam, as it requires one to know how the software remembers names of variables, types of data, and lengths. If a piece of data appears that is longer than the expected length, part of it might be forgotten. If no one has planned for this, the system truncates. This can cause the actual information to seem different than how it was originally. This part of the process influences the quality of the final analytic result. If values are cut off and split into distorted forms, the analytic part of the software will not be able to produce accurate details. Because of this, one must be careful and thoughtful during the data preparation part of the work.
The next stage is to consider the impact of all these internal decisions when the analytic side—the procedure step—begins. When the software no longer constructs data but instead begins to examine, count, sort, or deduce, it is influenced by what has already been prepared within the unseen pre-analytic phase. If inconsistencies appear between how the data should be structured and how it is actually structured, then the analytic part of the process still tries to produce something, but the conclusions will not reflect the truth. If the data has too many missing parts because of errors in logic, then the median, mean, or summary will also be influenced. If duplicates have not been removed, then the frequencies may show inflated counts. If the input data is sorted in a different order than expected, then the reporting procedure may cause the result to appear differently. The entire chain of operations must be observed, not just a single part.
Because the certification exam tests understanding of these connections, one must be able to speak through the flow of how data moves in each step. If an analyst receives data from the education sector, and the goal is to calculate the average score for each student, then first the system must check if every student record appears only once. If a student has taken multiple exams, the data must be grouped in a mental staging area to ensure the calculation knows how to treat the multiple results. Then, the analytic part of the software can measure the average per student. If the student has only one record, the average is simply the same as the value. If there are two, then the system must combine and calculate. This action is part of a procedure that relies entirely on data being properly sorted and organized beforehand.
It is also useful to think about how these steps are commonly used in real organizations. In industries like banking, data may be processed to detect fraud. The software can check each transaction, look for patterns of spending, match names and addresses, and decide whether the activity appears suspicious. Without strong preparation in the observed stage, none of the calculations would be able to detect whether the behavior is common or unusual. The software is not actually doing any magic. It must have a coherent data structure to read and analyze. The same often applies in healthcare. If a hospital needs to calculate the average time a patient spends in a department, the system must first gather timestamps from different parts of the patient's journey. It must understand both the starting and the ending moments. If any information is not present in the data preparation phase, then it becomes impossible to calculate. The same story plays out in politics, marketing, or environmental research. Without preparation, analysis fails.
Another key part of this journey is the concept of the relationship between different steps. When the system is finished with the analytic part, it can sometimes send data onward to new steps of observation and preparation, and the cycle will continue. This happens when a company needs successive reporting, farming of data, and adjustment before exploration. If the value in the software becomes too large, too complex, or too messy, then the process must start again. This is how complex data environments do not come from a single thought but instead require repeated viewing, adjustment, and inspection. This is where the experience and professional skills come in, since reacting to the previous analytic results and preparing for the next part of responsibility is a constant part of this method. The certification exam is a simplified environment where steps are discussed more as a process and less about specific outcomes. Nevertheless, the two parts—preparation and analysis—drive the entire process.
As understanding becomes deeper, the concept of efficiency becomes more relevant. When the system begins the analytical stage, it reads data row by row. If there is a huge volume of data because no one has removed the data that is not needed, then the process becomes slower. This is why the exam often includes questions about the need to filter and organize early, so the analytic step would not spend time on irrelevant information. The better prepared the data, the faster and more accurate the analytic part can function. This leads to a higher quality result. If the software must continuously re-read the whole dataset to answer a question, the process becomes slow. If the data is cleaned and sorted from the beginning, then part of this effort is reduced. Because of these insights, we can see that the two steps of the software work together for speed.
Yet, efficiency is not only about speed. It is also about predictability. When data is prepared correctly, the resulting analytic procedure will deliver consistent results. If the rules are not clear, if bits of information remain from previous operations, then the analytic part of the system can behave unpredictably. For example, if one forgets to restart the staging area while moving between data sources, then accidental variables can influence the number of rows. Since the system keeps the data in a mental map of variables, which is known as the result environment, previous values can interrupt the new calculation. When the data begins to show inconsistent information, it takes more time to understand and fix. Therefore, maintaining a clear cycle of preparation and analysis is a significant part of not only programming but also of classroom teaching.
As the learning of these ideas grows, it becomes clear that even though the software is only seen as two behaviors, there is a chain of invisible steps. The process is compiled, then sourced, then read, then cleaned, then examined, then sorted. The output is a new product. But the process is never as simple as one or two actions. Because of this, the certification exam requires candidates to show a very specific understanding of how the software reads every single stage, how this reading influences the variables, and how this influences the next tools. It also requires awareness of the software's ability to handle mistakes. If the data in one part of the software is not consistent, it may crash or reject. If the procedure part is meant to calculate average sales and there is only text and no numbers, it will not work. Recognizing this connection is a part of the professional learning.
The role of naming is also essential. If data is prepared for the analytic part, one must ensure that the internal system uses appropriate data types. The difference between text and numbers has already been explained, but the concept of type within operations must be remembered. If a name is seen by the software as a number, then one cannot search for text. If a description is seen as text, one cannot perform a calculation. This is why the two steps must be connected, and why exam questions often revolve around errors caused by misunderstanding of data types. When speaking about these moments, it becomes logical that to understand the software, one must understand how it interprets data, and that is why learning the internal sequence of events is crucial.
Once this concept is truly understood, one can see the difference between humorous expectation and actual process. Many believe that the procedure step will magically answer all questions, but without correct preparation, the software cannot produce anything. Within this world, the reason the programming step exists is because without analysis, there is no reflection. Without preparation, there is no source. They must exist together, but first, one must come before the next. Knowing this is the beginning of mastering this software for both academic and professional reasons.
Within many sectors, this software is used for quality checks, reporting, and calculation. Some display data for researchers, some for financial analysts, some for doctors, and some for advertisers. The flexibility of the tools is what gives it power. You do not need actual formulas when you understand that the process must be followed. In certification exams, you do not need actual code when you can speak the steps and show your understanding of how data must travel. This is what professional education means.
As the final part of this continuation, it becomes clear that if the software did not have the two stages, learning would be easier, but the work would be incomplete. Data must be observed, cleaned, sorted, combined, and examined. In hospitals, in banks, in universities, and in business, this movement is the same. Within the exam, many are not trying to do the whole process for real, but instead learning to speak and understand. This is why one must be careful with source, type, and concept. It is about knowing why the process exists, not only about how. And once this begins to make sense, then the steps become simpler, and the answer becomes visible.
The Intricacies of Data Handling and Transformation in the DATA Step
The realm of SAS Base Programming for SAS 9 is profoundly shaped by the intricate interplay between data preparation and procedural analysis. Central to this experience is the DATA step, which serves as the crucible where raw information is transformed into a coherent, analyzable form. Understanding this transformation is essential not only for professional application but also for certification success. The DATA step embodies a dynamic process, one that reads each observation, evaluates conditions, manipulates values, and constructs variables that will ultimately feed the procedural operations. Even without explicit programming, the conceptual workflow involves recognizing how data flows from its original source, through a series of logical transformations, into a structure that a PROC step can effectively utilize.
When envisioning this process, one must consider the mental operations performed on every observation. Each record passes through an internal workspace, a conceptual environment known as the program data vector, where values are temporarily stored, evaluated, and potentially transformed. This workspace ensures that every variable, whether numeric or character, undergoes a consistent and repeatable sequence of logic. Variables that are automatically created, such as observation counters or end-of-file indicators, exist not for the final output but to orchestrate this internal rhythm. Observations that do not meet specified conditions are excluded from the final dataset, a process that underscores the critical importance of precise conceptual reasoning. One must visualize how a misapplied condition could inadvertently remove or retain records, thereby affecting subsequent analytical procedures.
The DATA step is also the arena in which complex data transformations occur. Raw information often contains anomalies such as missing values, inconsistent formatting, or conflicting identifiers. Conceptually, one must imagine each of these issues being addressed sequentially. Textual variables may require trimming of extraneous spaces, standardization of case, or the harmonization of abbreviations. Numeric variables may need adjustments to units or scaling to ensure consistency. Missing values must be identified and treated according to logical rules, whether by imputation, categorization, or deliberate retention as indicators of absence. These decisions shape the dataset’s integrity and directly influence the outcomes of PROC operations, which rely entirely on the prepared data.
Another aspect of the DATA step that demands attention is the creation of new variables. These variables often encapsulate deeper meaning or derived metrics, and their conceptual genesis is rooted in logical conditions and arithmetic transformations. For instance, in a healthcare dataset, patient age may be categorized into groups, or risk scores may be computed based on combinations of diagnostic codes and laboratory values. Such derived variables do not exist in the raw data; they are artifacts of careful conceptual processing. Recognizing the significance of these variables, how they are generated, and how they interact with existing fields is vital for understanding the broader flow from preparation to analysis.
Merging and combining datasets introduces further complexity. When two datasets need to be integrated, a conceptual framework is required to determine how observations align. Matching occurs based on identifiers, and the system must resolve instances where keys are missing or inconsistent. Records that do not find a match may be discarded or retained according to logical criteria. One must also consider the harmonization of variable names, types, and lengths, ensuring that the resulting dataset maintains coherence. The DATA step thus functions as both a sculptor and a curator, shaping raw material into a structured collection of observations suitable for analysis.
The sequencing of operations within the DATA step is equally important. Transformations, conditional logic, and variable creation occur in a meticulously ordered flow, where each observation is processed in turn. Understanding this sequential nature is critical for anticipating the behavior of datasets. For example, a transformation applied to a variable early in the process affects all subsequent operations that reference that variable. Conditional filtering influences which observations proceed to further calculations. This cascading effect illustrates why conceptual clarity in the preparation stage is indispensable: PROC steps rely on the resulting dataset to be logically consistent and complete.
PROC steps, while seemingly distinct from the DATA step, are deeply intertwined with its outcomes. Procedures read the dataset prepared in the DATA step and apply analytical or reporting functions. Conceptually, PROC steps can be viewed as specialized lenses through which the dataset is examined, summarized, and interpreted. Whether performing frequency counts, computing descriptive statistics, generating reports, or conducting more complex analyses, the accuracy and relevance of PROC outputs are contingent upon the fidelity of the data constructed in the preceding step. Errors or inconsistencies that were not addressed during data preparation propagate through PROC steps, potentially yielding misleading or incomplete results.
An additional layer of complexity arises when considering automatic variables. These variables, which SAS generates internally, play a pivotal role in tracking observation numbers and the progression of data through the DATA step. Conceptual understanding of these automatic variables is essential, as they influence both the internal processing and the final dataset composition. Observations that are conditionally excluded do not increment counters in the same way as retained observations, which can subtly impact downstream analyses. The interplay between these implicit mechanisms and explicit transformations exemplifies the sophisticated logic underlying SAS Base Programming.
Data cleansing, a fundamental activity within the DATA step, involves the systematic identification and correction of anomalies. Conceptually, one must anticipate inconsistencies such as misaligned categorical values, duplicated records, out-of-range numbers, and inconsistent date formats. Each issue requires a distinct logical resolution. Textual inconsistencies may necessitate harmonization of spelling variants or capitalization, while numeric anomalies may require scaling or transformation. Dates, often represented in diverse formats across multiple sources, must be standardized to enable coherent temporal analyses. The preparation of data thus becomes a multidimensional process, balancing precision, completeness, and interpretability.
Derived variables further enrich the dataset, providing new dimensions of insight. Conceptually, these variables often combine multiple existing fields into a composite measure, capture conditional logic, or represent categorical groupings. For example, in a retail dataset, a variable representing customer segments might be derived from purchase frequency, monetary value, and product diversity. In a clinical dataset, a severity score might be computed from multiple laboratory and diagnostic measures. Understanding how these derived variables interact with the original data is crucial, as they can significantly influence PROC outputs, whether in summary statistics, sorting, or reporting.
Merging datasets introduces additional conceptual challenges. Aligning observations based on identifiers requires careful consideration of matching rules, treatment of missing keys, and reconciliation of conflicting values. Observations that lack corresponding matches may be omitted or retained according to logical specifications, while variable names and types must be harmonized to maintain dataset integrity. Conceptually, this process resembles assembling a mosaic from disparate pieces, where each piece must be carefully aligned to contribute meaningfully to the whole. The resulting dataset forms the foundation upon which PROC steps operate, and any misalignment or inconsistency can compromise subsequent analyses.
Conditional logic within the DATA step serves as a powerful mechanism for controlling the flow of data. Observations may be included or excluded based on complex criteria, variables may be transformed only under certain conditions, and new variables may be created to capture specific patterns. Conceptually, this logic resembles a network of decision nodes, where each observation traverses a unique path based on its attributes. Understanding these pathways is critical for predicting the composition of the final dataset and anticipating how PROC steps will interact with the prepared data.
Efficiency and performance considerations are also embedded within the DATA step. Processing large datasets requires careful conceptual planning to minimize unnecessary operations, avoid redundant calculations, and streamline conditional logic. Well-prepared data reduces computational overhead in PROC steps, ensuring faster and more accurate analytical outcomes. Conceptually, this involves anticipating potential bottlenecks, optimizing the sequence of transformations, and ensuring that only relevant observations and variables are carried forward for analysis.
The interaction between the DATA and PROC steps extends to error detection and mitigation. Conceptually, the DATA step functions as a gatekeeper, identifying anomalies, inconsistencies, and potential sources of analytical error. PROC steps then expose these issues through summary statistics, frequencies, or reporting outputs. Understanding this interplay enables analysts to anticipate errors, interpret PROC results critically, and refine the DATA step to achieve accurate and meaningful outputs. The conceptual framework emphasizes the importance of foresight, logical rigor, and systematic preparation.
In practical applications, these principles manifest across diverse industries. Healthcare analysts rely on DATA steps to consolidate patient records, standardize diagnostic codes, and compute derived measures before procedural analysis. Financial analysts prepare transaction data, reconcile accounts, and generate summary indicators to inform reporting procedures. Educational institutions aggregate student performance data, create composite scores, and analyze distributions to identify trends. In each context, the conceptual mastery of the DATA step informs the efficacy of PROC operations, ensuring that analytical outputs are both accurate and actionable.
Automatic variables continue to play a subtle but essential role in this process. Observation counters, end-of-file indicators, and other internally generated markers influence the sequencing, retention, and transformation of data within the DATA step. Conceptual awareness of these variables allows analysts to anticipate how observations are processed, how conditional logic interacts with dataset composition, and how derived variables are computed. This understanding is particularly relevant for the SAS Base Programming exam, where candidates are expected to reason through data flow and procedural outcomes without relying on explicit code.
Data cleansing strategies extend beyond the identification of anomalies to encompass systematic harmonization and transformation. Textual inconsistencies, numeric discrepancies, and temporal misalignments must be addressed in a manner that preserves data integrity and analytical relevance. Derived variables further enrich the dataset, enabling nuanced insights and facilitating procedural analyses. Merging datasets introduces additional considerations, requiring alignment of identifiers, reconciliation of variable types, and resolution of missing or conflicting information. Conditional logic guides the inclusion, exclusion, and transformation of observations, shaping the dataset into a form suitable for accurate and meaningful PROC operations.
Efficiency, error detection, and practical application converge within this conceptual framework. Large datasets demand streamlined processing, logical consistency, and strategic preparation to ensure that PROC steps produce reliable results. Errors originating in the DATA step propagate through subsequent analyses, emphasizing the critical importance of thorough preparation, logical foresight, and systematic verification. Conceptual mastery of these processes equips analysts to navigate complex datasets, anticipate challenges, and derive meaningful insights across diverse domains.
Understanding the DATA step as a dynamic, multi-layered process reveals the intricate architecture underpinning SAS Base Programming. Each observation traverses a conceptual workflow encompassing variable creation, transformation, cleansing, and alignment. Derived variables capture deeper meaning, conditional logic governs observation flow, and automatic variables orchestrate internal sequencing. The resulting dataset forms the foundation upon which PROC steps operate, enabling accurate, efficient, and insightful analyses. Conceptual clarity in these processes is essential for both certification success and professional competence, providing the analytical framework necessary to navigate complex data environments, interpret procedural outcomes, and make informed decisions based on meticulously prepared datasets.
The synergy between the DATA and PROC steps is further illustrated through practical applications. In healthcare, finance, education, and business analytics, the integrity of PROC outputs is directly contingent upon the meticulous preparation of data within the DATA step. Each transformation, conditional evaluation, and derived variable contributes to a coherent dataset, ensuring that procedural analyses reflect accurate and meaningful insights. Conceptual mastery of these processes empowers analysts to anticipate challenges, optimize workflow efficiency, and interpret results critically, fostering a comprehensive understanding of SAS Base Programming principles that extends beyond certification and into professional practice.
Understanding PROC Steps and Their Interdependence with the DATA Step
In the domain of SAS Base Programming for SAS 9, the procedural steps represent the analytic culmination of meticulous data preparation. While the DATA step constructs and organizes datasets, the PROC step functions as the analytical lens, enabling the exploration, summarization, and interpretation of the meticulously prepared data. The two are inextricably linked, forming a continuum that begins with conceptual data ingestion and transformation and extends into procedural analysis, reporting, and insight generation. Mastery of the procedural step requires a sophisticated understanding of how it interacts with the datasets generated by preceding operations, the limitations imposed by missing or inconsistent data, and the conceptual expectations of the examination environment.
The procedural step in SAS is designed to perform predefined analytic and reporting tasks on datasets created in the DATA step. Conceptually, one must understand that the PROC step does not generate new raw data; rather, it interprets, summarizes, and displays the data that has been curated. Each PROC operation reads the dataset sequentially, applies internal algorithms to compute statistics or sort observations, and produces results in a format intended for interpretation. The success of these operations is contingent upon the conceptual integrity of the dataset: variables must be appropriately formatted, observations correctly aligned, and missing values accounted for. If the preparation stage is flawed, the PROC output will reflect these deficiencies, highlighting the critical interplay between preparation and analysis.
Sorting represents one of the foundational procedural operations. Conceptually, sorting involves arranging observations in a dataset according to specified criteria, which may involve one or multiple variables. In practice, this could be akin to ordering patient records by age, organizing sales data by region, or arranging academic performance by test scores. The sorted dataset does not alter the underlying values but provides a structured sequence that facilitates subsequent analyses, such as calculating cumulative sums, deriving percentiles, or generating orderly reports. Understanding the logic behind sorting, including ascending and descending conceptual orders, is fundamental for anticipating how subsequent procedures will process the organized data.
Another common operation within procedural steps is summarization. Summarization encompasses the calculation of descriptive statistics such as means, medians, counts, and frequencies, all derived from the structured dataset. Conceptually, summarization requires an understanding of how the software interprets each variable, handles missing values, and aggregates observations. For instance, when computing averages, the system must consider only valid numeric entries, exclude missing values, and potentially group observations according to categorical distinctions established in the DATA step. This interplay between variable integrity and summarization underscores why meticulous preparation is essential for meaningful PROC output.
Frequency analysis represents another crucial concept. Frequencies provide insights into the distribution of categorical variables within a dataset, revealing patterns, anomalies, and trends. Conceptually, calculating frequencies involves counting occurrences of each unique value, understanding the relationships between categories, and interpreting the relative proportions. For example, in a clinical dataset, frequency analysis might reveal the distribution of patients across diagnostic categories, age groups, or treatment plans. The accuracy of such analyses depends entirely on the integrity of the dataset created in the DATA step: duplicated, missing, or misaligned observations will distort the frequencies, highlighting the interdependence of preparation and analysis.
Procedural reporting also encompasses more complex analytical functions. These include summarizing grouped data, calculating cross-tabulations, and producing outputs that reveal relational patterns among variables. Conceptually, these operations extend the analytical capacity beyond simple statistics, requiring an understanding of how the software internally structures groupings, applies computations to each subgroup, and synthesizes the results into coherent outputs. For instance, generating a cross-tabulation of product sales by region and customer segment necessitates recognizing how each observation aligns with the designated categories and ensuring that derived variables or categorical groupings are consistent and accurate.
The conceptual relationship between the DATA and PROC steps becomes particularly evident when handling derived variables. Derived variables, created during the DATA step, often form the basis for PROC analysis. These variables may encapsulate conditional logic, computed scores, or categorical groupings that enable meaningful summaries. Understanding how these variables interact with procedural operations is essential: if a derived variable is misaligned or incorrectly calculated, the PROC output will be misleading. The mental model of this interaction involves visualizing the DATA step as a preparatory workshop, where raw and transformed observations are arranged into a coherent structure, and the PROC step as an analytical observatory, interpreting the curated landscape of data.
Merging and concatenating datasets also influence procedural outcomes. When datasets are combined during preparation, the resulting structure impacts how PROC operations interpret, summarize, and report the information. Conceptually, merging involves aligning observations based on common identifiers, reconciling variable types, and handling missing or unmatched entries. Concatenation, on the other hand, involves appending datasets to extend the observation set. Each of these operations shapes the dataset’s architecture, which in turn determines the reliability and accuracy of procedural analyses. Misalignment, inconsistent variable naming, or overlooked missing values can propagate errors into PROC outputs, reinforcing the importance of thorough conceptual preparation.
Conditional processing within procedural steps further illustrates the interdependence of preparation and analysis. Procedures may apply filters, groupings, or computations selectively, contingent upon the attributes of observations. Conceptually, this involves envisioning a series of conditional gates through which each observation passes, determining inclusion, aggregation, or categorization. For example, a dataset of sales transactions may be analyzed to compute total revenue only for transactions above a certain value or within a specified date range. The procedural output reflects these conceptual decisions, emphasizing the necessity of understanding the logical frameworks established during the DATA step.
Efficiency considerations are equally critical. Procedural steps must operate on well-prepared datasets to minimize computational overhead and ensure accurate results. Conceptually, efficiency is influenced by the size of the dataset, the complexity of derived variables, and the presence of unnecessary or redundant observations. A dataset that has been carefully filtered, sorted, and cleansed allows procedures to execute more rapidly and produce consistent, interpretable outputs. Conversely, datasets that are cluttered, inconsistent, or poorly structured can cause procedural steps to behave unpredictably, delay analysis, or generate misleading results.
Automatic variables, created during the DATA step, also affect procedural operations. Observation counters, end-of-file indicators, and other internally generated markers influence how datasets are processed, aggregated, and interpreted. Conceptually, these variables serve as internal guides, ensuring that each observation is evaluated, grouped, or counted appropriately. Understanding their influence enables analysts to anticipate procedural behavior, identify potential sources of error, and refine data preparation strategies to support accurate and efficient analyses.
Data integrity remains a central theme throughout procedural analysis. The conceptual model emphasizes that procedural outcomes are only as reliable as the datasets they interpret. Inconsistent values, missing data, and misaligned observations introduced during preparation will inevitably affect the accuracy of summaries, frequencies, and reports. Therefore, mastery involves not only understanding procedural operations but also maintaining vigilance over the integrity of the datasets that feed into these operations. This vigilance includes anticipating how derived variables interact with raw data, ensuring consistent variable types and lengths, and verifying the completeness of observations.
In practical applications, the conceptual interplay between DATA and PROC steps manifests across diverse industries. Healthcare analysts may summarize patient outcomes, calculate treatment efficacy, or generate frequency distributions of diagnostic categories. Financial analysts may compute transaction summaries, analyze account balances, or produce reports by customer segments. Educational institutions may evaluate test scores, aggregate student performance metrics, or identify trends across demographics. In each case, the quality of procedural outputs is inextricably linked to the thoroughness and accuracy of preceding data preparation.
Conditional and grouped analyses further illustrate procedural sophistication. Summarization within groups allows analysts to compute statistics specific to categories, such as average sales per region, median patient age by treatment type, or distribution of test scores by class. Conceptually, this requires understanding how the software partitions the dataset, applies computations within each partition, and synthesizes the results. Misalignment or errors in grouping during preparation can distort these outputs, highlighting the necessity of precise conceptual reasoning and meticulous dataset structuring.
Visualization and reporting operations, while procedural in nature, also depend upon conceptual data integrity. The organization, completeness, and consistency of variables dictate how effectively reports communicate insights. Summaries, counts, and frequencies are only meaningful if the underlying observations are accurate, complete, and correctly aligned. The procedural step functions as the interpretive layer, revealing patterns, trends, and anomalies that were implicitly embedded in the dataset during preparation. Analysts must therefore maintain a dual focus: ensuring data integrity while leveraging procedural tools to extract and convey insights.
Efficiency, error detection, and predictive reasoning converge in advanced procedural operations. Large datasets demand careful conceptual planning, logical consistency, and strategic filtering to ensure that procedures execute effectively and produce accurate results. Conceptual mastery allows analysts to anticipate errors, adjust preparation strategies, and optimize procedural performance. This mental model extends beyond technical execution, fostering an analytical mindset capable of navigating complex datasets, interpreting results critically, and applying insights across diverse professional contexts.
The relationship between derived variables and procedural analysis exemplifies the nuanced interplay of preparation and interpretation. Derived variables, often representing composite measures, categorical groupings, or conditional transformations, form the foundation for many procedural computations. Understanding their conceptual origin, interactions with other variables, and potential influence on procedural outputs is crucial for accurate and meaningful analysis. Misunderstandings at this stage can propagate through procedures, affecting summaries, frequencies, and reports, underscoring the importance of comprehensive conceptual mastery.
Finally, the procedural step functions as a conduit for transforming meticulously prepared data into actionable insights. Summarization, frequency analysis, sorting, grouping, and reporting all rely on the integrity, structure, and conceptual soundness of the dataset produced in the DATA step. Analysts must maintain awareness of the invisible interdependencies between preparation and analysis, recognizing how variable types, missing values, derived measures, and observation alignment influence procedural outcomes. Mastery of this conceptual framework equips candidates for the SAS Base Programming exam, enabling them to reason through complex data scenarios, anticipate potential pitfalls, and produce accurate, insightful results across diverse analytical contexts.
Identifying, Understanding, and Correcting Errors in DATA and PROC Steps
The efficacy of SAS Base Programming for SAS 9 is inextricably linked to the precision and foresight applied during both data preparation and procedural analysis. Errors, whether subtle or overt, can propagate through the DATA and PROC steps, undermining the accuracy of results and the integrity of decision-making. A conceptual understanding of how errors manifest, how they interact with the program data vector, and how procedural steps respond is essential for both professional application and certification readiness. The flow from raw data to analytical insight is vulnerable to multiple forms of logical inconsistencies, variable mismanagement, and observational anomalies, each of which requires careful attention, anticipation, and resolution.
Data entry inconsistencies represent one of the most common sources of errors. When datasets originate from disparate sources, values may be recorded in differing formats, units, or representations. Conceptually, the DATA step functions as the initial line of defense, transforming, standardizing, and harmonizing these values to ensure compatibility. For example, numeric entries recorded in multiple scales require logical conversion to a unified unit, while text entries must be normalized for capitalization, abbreviation, and spacing. The program data vector tracks each observation sequentially, applying logical rules and storing intermediate results. Awareness of these transformations enables the analyst to anticipate how variations in the raw data may influence derived variables, filtering conditions, and subsequent procedural analyses.
Missing values introduce another layer of complexity. The manner in which SAS interprets absent numeric or character data differs conceptually and operationally. Numeric missing values propagate through arithmetic operations, often resulting in undefined outcomes if not properly addressed. Character missing values, while less disruptive in calculations, can lead to misalignment or misclassification in grouping or conditional logic. Conceptual mastery involves predicting how missing values will influence the final dataset, how derived variables may be affected, and how PROC steps will interpret these gaps. For instance, summarization procedures will ignore missing numeric values, but failure to recognize their presence during dataset construction can skew interpretations of central tendencies, distributions, and aggregated counts.
Logical errors within conditional statements are another critical consideration. During the DATA step, conditional logic governs which observations are retained, transformed, or assigned new variables. Conceptually, analysts must visualize the decision pathways for each observation, understanding that a misapplied condition may inadvertently exclude necessary data or include unintended entries. This requires careful attention to the sequencing of conditional checks, the interaction between overlapping conditions, and the cumulative effect on the program data vector. Errors at this stage propagate directly to PROC outputs, potentially producing misleading frequencies, incorrect summaries, or misrepresentative groupings.
Variable mismanagement also constitutes a frequent source of errors. Variables may be inadvertently overwritten, truncated, or misclassified. Numeric variables may be interpreted as character or vice versa, and the system’s automatic handling of variable lengths can truncate or pad data unexpectedly. Conceptually, understanding how SAS assigns memory space, tracks variable properties, and applies implicit rules is critical for avoiding these errors. Derived variables, which often carry complex calculations or conditional logic, are particularly vulnerable to errors if their dependencies or transformations are misaligned. Procedural outputs rely on these variables for accurate reporting, aggregation, and analysis, underscoring the interdependence of meticulous preparation and procedural integrity.
Merging and concatenating datasets further complicate error management. When combining datasets, unmatched observations, inconsistent variable types, or duplicate identifiers can produce unintended results. Conceptually, merging requires anticipating how each observation aligns, identifying potential mismatches, and resolving conflicts through logical rules or prioritization. Concatenation extends the observation set and demands awareness of variable consistency across datasets. Failure to address these conceptual considerations can result in skewed PROC outputs, inaccurate counts, or misclassified summaries. A profound understanding of these interactions enhances the reliability of analytical procedures and underpins the capacity to reason through complex data scenarios.
Efficiency and performance considerations intersect with error detection. Large datasets exacerbate the impact of errors, as inconsistencies and misalignments can multiply and magnify inaccuracies. Conceptually, optimizing the DATA step to filter irrelevant observations, streamline transformations, and harmonize variables reduces the likelihood of procedural errors. PROC steps operating on well-prepared datasets execute more efficiently, produce consistent outputs, and minimize the risk of misinterpretation. Awareness of these principles informs not only practical application but also certification readiness, where exam questions often evaluate the candidate’s ability to anticipate and mitigate errors conceptually.
The role of automatic variables in error management is equally significant. These internally generated markers, such as observation counters and end-of-file indicators, guide the sequential processing of observations. Conceptual understanding of their behavior enables analysts to anticipate how excluded observations, conditional transformations, or iterative processes influence dataset composition. For example, a misalignment in observation tracking may result in procedural summaries reflecting fewer or more observations than intended, affecting frequencies, sums, and derived metrics. Recognizing these nuances reinforces the necessity of conceptual precision during dataset preparation.
Data cleansing strategies serve as preventive measures against logical and procedural errors. Analysts must conceptualize the identification of anomalies, the resolution of inconsistencies, and the harmonization of disparate values. This process includes standardizing text fields, converting numeric scales, rectifying missing entries, and ensuring alignment of variable types. Derived variables must be validated for accuracy, consistency, and appropriateness for intended PROC operations. Conceptually, data cleansing is not merely a mechanical task but a cognitive exercise in anticipating potential pitfalls, understanding interdependencies, and ensuring the coherence of the dataset as a foundation for analytical operations.
Conditional transformations exemplify the subtlety of error management. Each observation may traverse unique logical pathways, influenced by multiple criteria and sequential evaluations. Conceptually, analysts must visualize these pathways, anticipate how overlapping conditions interact, and recognize the implications for dataset composition. Misapplied conditional logic can propagate errors that compromise PROC outputs, such as inaccurate groupings, incorrect summaries, or misleading frequencies. Mastery involves a nuanced understanding of how observations are filtered, transformed, and aggregated conceptually, enabling proactive error mitigation.
Procedural operations themselves serve as diagnostic tools for identifying residual errors. Summarization, frequency analysis, and sorting reveal inconsistencies, anomalies, and unexpected distributions. Conceptually, analysts interpret PROC outputs to detect potential issues in the underlying dataset. For example, unexpected frequency distributions may indicate misclassified observations, while unusual summaries may suggest overlooked missing values or incorrect derivations. By reasoning through procedural outputs, analysts can trace errors back to their conceptual origins in the DATA step, refine preparation strategies, and ensure the reliability of subsequent analyses.
The interplay between dataset integrity and procedural accuracy is evident in practical applications. In healthcare, for example, patient records must be accurately consolidated, cleaned, and transformed to ensure valid procedural summaries of treatment outcomes. Financial analysts rely on precise transaction data to generate accurate summaries, trends, and reports. Educational institutions must harmonize student performance records to produce meaningful metrics and identify trends. In each context, the precision and foresight applied during dataset preparation directly influence the validity and interpretability of procedural results.
Conceptual understanding of error propagation enhances both efficiency and analytical confidence. By anticipating potential inconsistencies, aligning variables, and ensuring logical coherence, analysts reduce the likelihood of procedural errors and increase the reliability of insights. Awareness of automatic variables, observation sequencing, and conditional pathways allows for proactive management of complex datasets. This mental framework supports both professional application and exam readiness, fostering the ability to reason through data challenges without relying on explicit code.
Derived variables, conditional logic, and merging operations represent focal points for potential errors. Conceptually, each derived variable must be validated for correctness, alignment, and interpretability. Conditional transformations must be scrutinized for unintended exclusions or inclusions. Merging operations must consider unmatched observations, variable consistency, and identifier alignment. Procedural outputs depend on these considerations for accurate computation, summarization, and reporting. Mastery of these conceptual interdependencies is essential for both certification and professional practice, ensuring that data-driven decisions are grounded in reliable, logically coherent datasets.
Efficiency in error management extends beyond accuracy to encompass performance. Datasets that are thoroughly prepared, cleansed, and harmonized allow PROC steps to execute efficiently, reducing computational overhead and minimizing the potential for cascading errors. Conceptual planning of transformations, conditional logic, and derived variables optimizes both preparation and analysis, enhancing the overall effectiveness of SAS Base Programming. This strategic approach underscores the importance of understanding not only individual operations but also the holistic flow from raw data to analytical insight.
In practical applications, the consequences of neglecting conceptual error management can be significant. Inaccurate financial reporting, misrepresented patient outcomes, flawed academic assessments, or misleading business intelligence can result from overlooked inconsistencies, improper variable handling, or misapplied conditional logic. Conceptual mastery of error sources, propagation, and mitigation strategies equips analysts to prevent these outcomes, ensuring the reliability, accuracy, and interpretability of procedural outputs.
In preparation for the SAS Base Programming exam, candidates must demonstrate the ability to reason through potential errors conceptually, anticipate their impact on procedural outputs, and articulate strategies for mitigation. This involves understanding variable behavior, conditional logic, observation sequencing, automatic variables, derived metrics, and dataset integrity. The capacity to mentally trace data through the program data vector, predict procedural behavior, and identify potential pitfalls reflects a profound grasp of SAS Base Programming principles.
Ultimately, mastery of error management in SAS involves a dual focus on prevention and detection. The DATA step serves as the primary locus of preparation, ensuring that observations are accurate, variables are consistent, and derived measures are valid. The PROC step functions as both an analytical tool and a diagnostic lens, revealing residual inconsistencies and validating the integrity of transformations. Conceptual clarity in these processes empowers analysts to anticipate errors, optimize workflow, and ensure the accuracy and reliability of outputs. This integrated approach underpins both professional competence and examination success.
Understanding and addressing errors is not a peripheral concern but a central tenet of effective SAS Base Programming. By conceptualizing data preparation, transformation, and analysis as an interconnected continuum, analysts can anticipate inconsistencies, manage derived variables, and ensure that procedural outputs faithfully represent the underlying information. This mental framework supports not only practical applications across diverse industries but also the cognitive rigor required for certification, emphasizing foresight, precision, and logical coherence in every stage of data handling and analysis.
Conclusion
Mastery of DATA and PROC steps requires meticulous attention to error management, logical precision, and conceptual clarity. Analysts must navigate the intricate interplay between preparation and analysis, anticipate potential inconsistencies, and ensure that both datasets and procedural operations reflect accurate, coherent, and meaningful representations of the underlying information. This approach fosters both professional efficacy and examination readiness, establishing a foundation for reliable, insightful, and impactful data-driven decisions.

