
Exam Code: C2090-424
Exam Name: InfoSphere DataStage v11.3
Certification Provider: IBM
Corresponding Certification: IBM Certified Solution Developer - InfoSphere DataStage v11.3
Product Screenshots
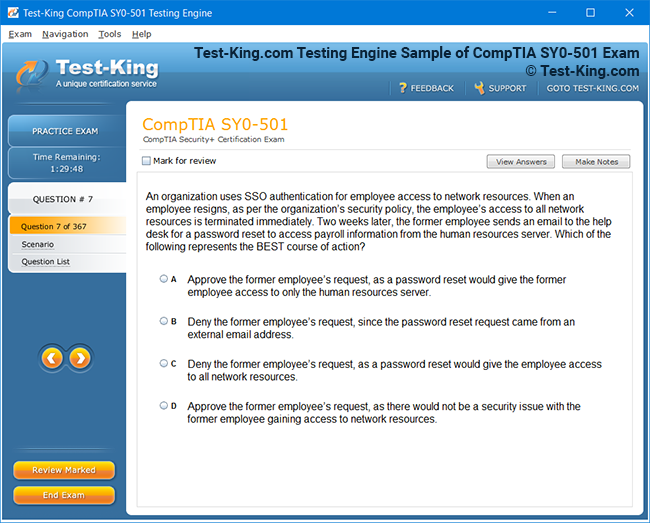
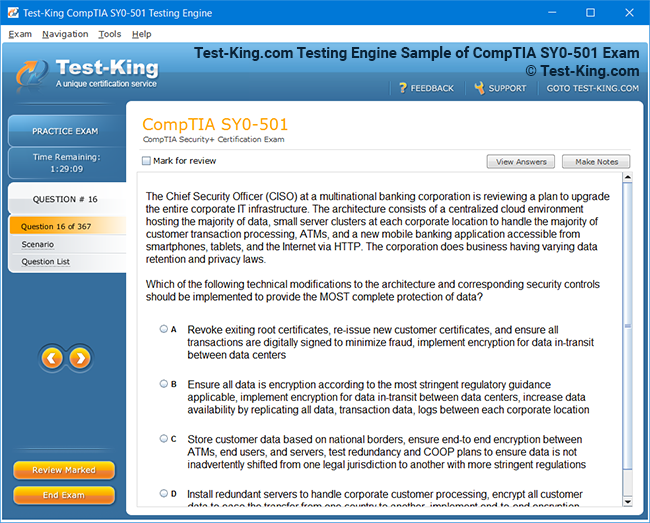
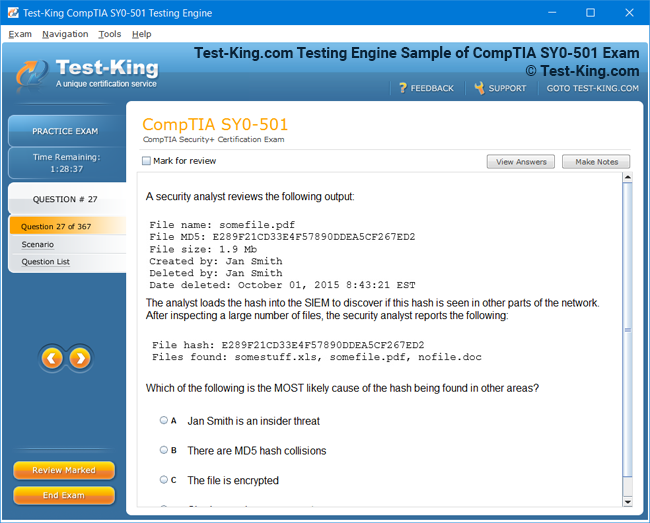
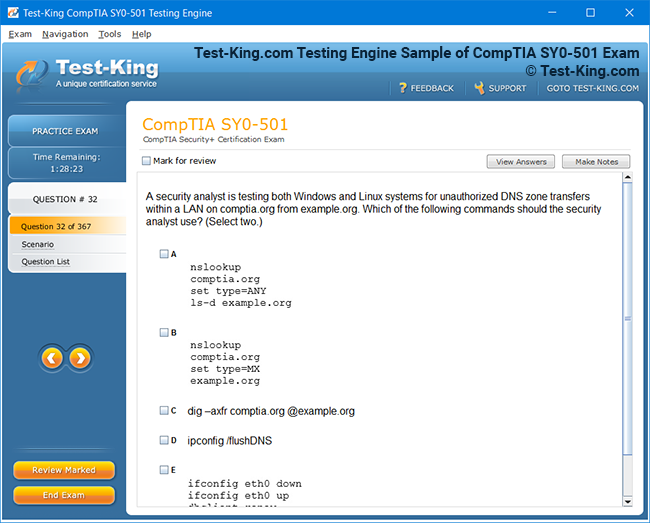
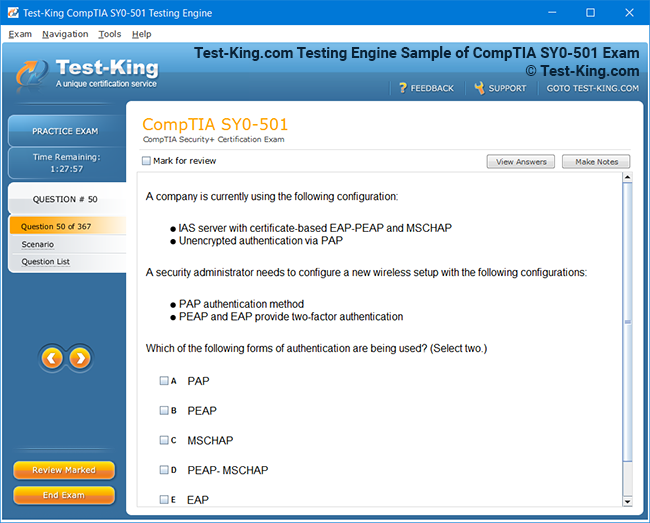
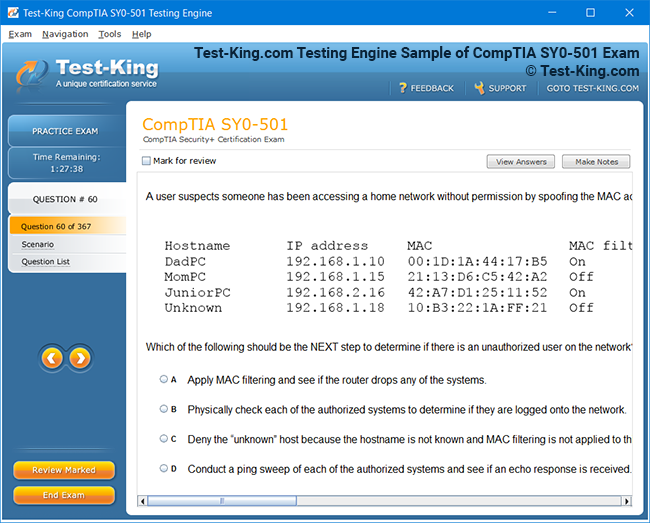
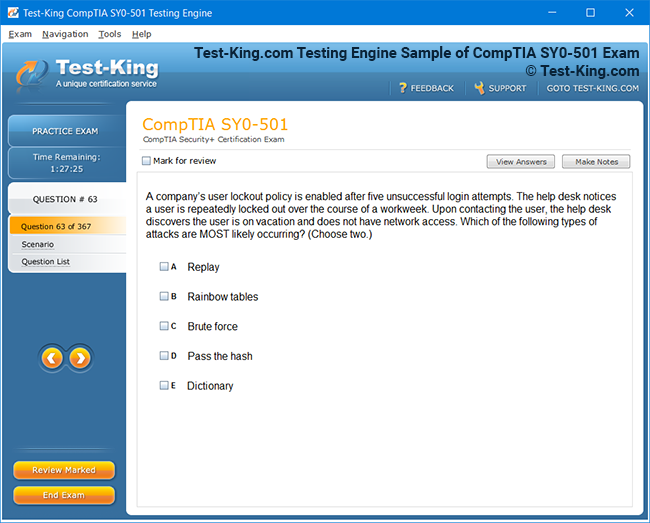
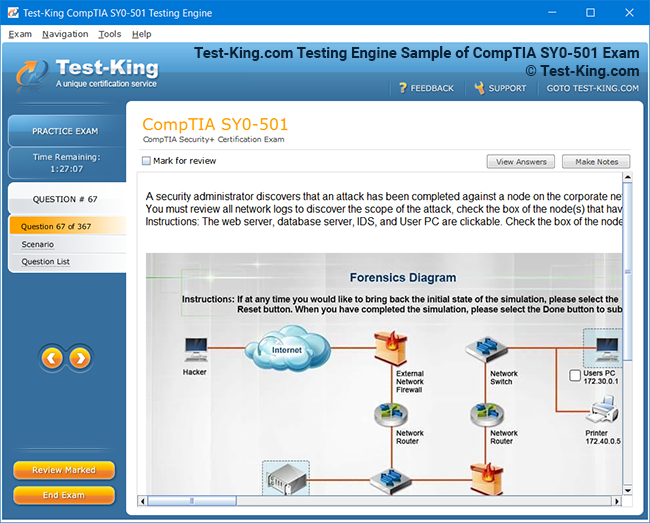
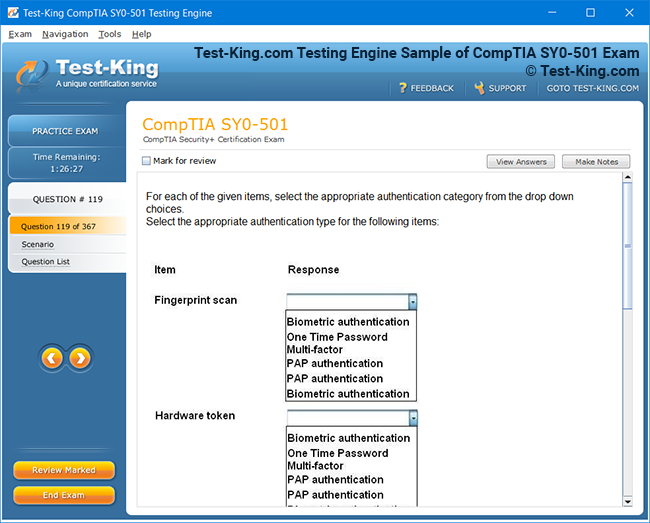
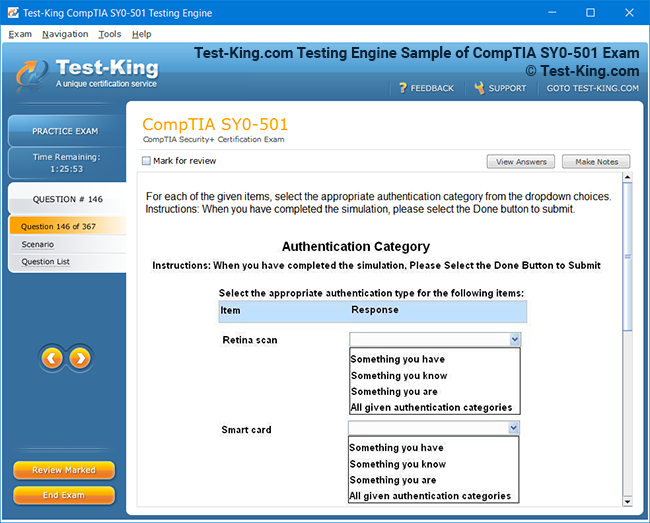
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Top IBM Exams
IBM C2090-424 Practice Questions and Exam Insights for InfoSphere DataStage v11.3
The IBM C2090-424 examination, also known as the InfoSphere DataStage v11.3 certification test, is an intricate and intellectually demanding credential designed for professionals who wish to validate their mastery of IBM’s data integration platform. This examination evaluates how well candidates understand the architecture, configuration, and operational dynamics of InfoSphere DataStage, including their capability to manage, design, and optimize data flow solutions in enterprise-scale environments. The certification is particularly relevant for data engineers, ETL specialists, and information integration architects who aspire to demonstrate a strong command of IBM’s data management ecosystem.
Understanding the IBM C2090-424 Exam Framework and Objectives
The essence of the IBM C2090-424 examination lies not merely in memorizing functions or commands, but in comprehending the entire structural logic behind the InfoSphere DataStage v11.3 environment. The exam demands a solid grasp of both conceptual understanding and technical precision. It measures one’s ability to build parallel jobs, configure metadata repositories, and orchestrate end-to-end data movement pipelines that comply with complex business requirements. Candidates are expected to exhibit practical dexterity in designing, executing, and troubleshooting data integration workflows that align with modern data governance standards. Unlike general software exams that emphasize syntax, this one delves deep into operational intelligence—how data is extracted, transformed, and loaded efficiently within large distributed ecosystems.
Within the InfoSphere DataStage v11.3 framework, the candidate must recognize the symphony between the Designer, Director, and Administrator components. The Designer is primarily used for constructing and testing jobs, where the intricate process of linking data stages through nodes defines how information traverses from source to target. The Director, on the other hand, supervises job execution, providing insight into performance metrics, log management, and runtime analysis. The Administrator maintains the overall project configuration, user permissions, environment variables, and resource allocation. The IBM C2090-424 exam expects candidates to not only understand what these tools do but also to interpret when and how to employ them for maximum efficiency. For example, a question might describe a situation where a job fails intermittently during high-volume loads, and the examinee must infer whether it is a configuration, partitioning, or environmental issue. Such inquiries are crafted to test both analytical acuity and applied experience.
The exam structure embodies a combination of scenario-based and knowledge-based questions, reflecting real-life data integration challenges. While IBM does not publicly reveal the number of questions or passing score, past examinees often note that the duration of the test requires meticulous time management. Each question integrates multiple concepts, often embedding subtle clues within descriptive statements. A scenario might discuss a parallel job that reads from multiple sequential files and applies a transformer stage before loading into a target database. The candidate would then need to deduce the correct stage type, data partitioning strategy, or job parameter configuration that ensures optimal throughput without data loss. This approach makes the C2090-424 a genuine evaluation of data integration reasoning rather than rote learning.
InfoSphere DataStage v11.3 is built upon the foundation of IBM Information Server, which is a multifaceted data management platform designed to consolidate, cleanse, and transform data from diverse systems. Within the IBM C2090-424 context, understanding this ecosystem is essential. The Information Server architecture embodies layers that manage metadata, security, connectivity, and operational orchestration. The metadata repository acts as the semantic backbone, enabling consistent data interpretation across jobs and projects. Security is woven throughout the system, ensuring controlled access through roles, privileges, and authentication mechanisms. Connectivity modules allow seamless integration with various databases, file systems, and external data sources. The operational layer orchestrates job execution through high-performance parallel engines, managing data partitioning and resource distribution. The exam intricately assesses comprehension of these layers and how they interconnect to form a cohesive, scalable data integration infrastructure.
A common conceptual inquiry embedded in the exam narrative might revolve around the essence of parallel processing within InfoSphere DataStage. IBM’s parallel framework enables data to be divided across multiple nodes for simultaneous processing, which significantly enhances speed and efficiency when handling voluminous datasets. A subtle twist in such a question might challenge candidates to determine how to balance resource utilization and job design to prevent skewed data partitions. To answer effectively, one must possess an intuitive understanding of how partitioning methods such as round-robin, hash, and range distribute data during runtime. The exam often disguises these topics within case-like narratives, compelling the examinee to interpret the underlying issue before identifying the correct solution.
Another thematic dimension of the IBM C2090-424 exam concerns the lifecycle of DataStage projects. A project begins with job creation in the Designer, followed by validation, compilation, and deployment. Understanding how jobs are organized within projects and how they interact with shared containers, parameters, and environmental settings forms a crucial layer of the examination. For instance, one might encounter a question describing a project that exhibits inconsistent variable behavior across different jobs. The candidate would need to discern whether the inconsistency originates from parameter set mismanagement, improper environment variable referencing, or default configuration overrides. The ability to interpret subtle contextual hints like this demonstrates both practical insight and technical maturity.
DataStage jobs are often the heart of the IBM C2090-424 exam scenarios. A job, at its core, represents a workflow that transforms data from a source to a target through a series of interconnected stages. Each stage performs a distinct function—reading, filtering, transforming, or writing data. The exam might explore how to optimize these stages to enhance throughput and maintain data integrity. For example, the Transformer stage is a frequent subject of inquiry. Candidates are expected to know how to manipulate derivations, expressions, and constraints within it. A typical narrative could involve a business rule requiring multiple conditional transformations within a single job. The examinee would need to deduce the appropriate stage configuration that avoids redundant computations while maintaining clarity in logic. Such tasks assess one’s capacity to blend analytical thought with efficient design principles.
The IBM C2090-424 exam also tests comprehension of job sequencing. Job sequences are orchestration constructs that define how multiple jobs are executed in a coordinated manner. They incorporate stages like job activity, condition, exception handling, and notification. In a practical situation described within an exam question, a sequence might fail due to dependencies or unhandled exceptions. The examinee must infer the correct remedial step, such as modifying the sequence to include appropriate triggers or error handlers. Mastery of this concept reveals the candidate’s ability to manage complex workflows within enterprise environments where automation and dependency control are paramount.
Another essential dimension evaluated by the IBM C2090-424 examination is metadata management. Metadata is the descriptive information that defines the structure, semantics, and lineage of data within the InfoSphere ecosystem. Candidates are expected to understand how metadata repositories facilitate consistency and governance. The exam may describe a scenario where inconsistent column definitions across jobs lead to runtime anomalies. The examinee must deduce that maintaining a central metadata repository helps harmonize such discrepancies. In another context, the question might explore lineage tracing, asking how to identify the origin and transformation path of a specific data element within a pipeline. These narratives reinforce the significance of metadata as the backbone of reliable data integration.
Performance optimization and resource management are also interwoven into the IBM C2090-424 examination fabric. InfoSphere DataStage provides multiple configuration options that influence job efficiency, including buffer sizes, node allocation, and parallelism settings. A narrative might illustrate a situation where a job exhibits intermittent slowdowns. The candidate would need to infer whether the issue stems from resource contention, improper partitioning, or suboptimal stage configuration. Recognizing such nuances demands both theoretical knowledge and experiential insight. IBM’s intention in designing such questions is to ensure that certified professionals are capable of sustaining high-performance data integration in real-world production environments.
Environmental configuration and variable handling are another frequent theme. Environment variables govern how jobs behave under different runtime conditions. They control aspects such as file paths, database connections, and default parameters. A subtle yet intricate question might describe a project that fails when deployed on a new server despite working flawlessly in the development environment. The underlying cause might relate to environmental variable inconsistencies, and the examinee would need to determine how to align configurations across environments. This reflects a deeper understanding of how InfoSphere DataStage operates within diverse infrastructural contexts.
Security considerations also play a pivotal role in the IBM C2090-424 examination. InfoSphere DataStage v11.3 integrates with IBM Information Server security framework to manage authentication and authorization. Candidates must comprehend how roles, privileges, and access control lists interact to safeguard project assets. A narrative could describe a scenario where a user cannot access a specific project component despite having design privileges. The correct inference might involve missing operational permissions or inherited access restrictions. Such inquiries ensure that certified professionals can uphold governance and compliance standards in multi-user environments.
An often-overlooked yet vital aspect of the exam involves troubleshooting and debugging methodology. When a job encounters a runtime failure, understanding the log details and interpreting error messages are crucial skills. The IBM C2090-424 examination may include scenarios that describe specific error patterns such as data truncation, deadlocks, or missing links. The examinee must decipher the cause by correlating the log information with the job’s design. For instance, if a transformer stage indicates type conversion issues, the professional must determine whether the problem lies in metadata mismatches or improper data type handling. This skill embodies the diagnostic intelligence required of any proficient DataStage developer.
The InfoSphere DataStage v11.3 environment supports both sequential and parallel job designs. Sequential jobs are linear and straightforward, suitable for smaller data volumes, while parallel jobs leverage multiple nodes for high-performance execution. The IBM C2090-424 exam evaluates understanding of when to apply each model. A descriptive question might narrate a business scenario requiring data consolidation from multiple heterogeneous sources within a constrained time window. The examinee must reason that a parallel job is more suitable, ensuring efficient partitioning and concurrent processing. The question might then subtly probe knowledge of partitioning techniques or data skew prevention mechanisms. Such layered inquiry demands not only theoretical comprehension but strategic decision-making aligned with enterprise needs.
The administrative dimension of InfoSphere DataStage also features prominently within the IBM C2090-424 certification test. The Administrator client provides functionalities for creating projects, defining users, and managing environment configurations. It also facilitates monitoring job status, controlling resource usage, and handling project-level backups. A scenario may describe a project migration between development and production servers. The examinee must identify the appropriate administrative steps, including exporting the project, validating configurations, and ensuring environmental parity. Such administrative literacy ensures that certified professionals can sustain and scale data integration operations reliably.
From a pedagogical standpoint, the IBM C2090-424 examination encourages deep conceptual immersion rather than surface familiarity. Many candidates underestimate the integrative nature of the questions, expecting isolated technical trivia. Instead, IBM’s evaluative design weaves multiple knowledge strands into each inquiry. For example, a single question might touch upon partitioning, environmental configuration, job design, and error management simultaneously. To navigate such complexity, candidates must cultivate an interconnected understanding of how InfoSphere DataStage operates as a unified ecosystem. It is this holistic grasp that differentiates an adept practitioner from a mere technician.
Practice and experiential learning are indispensable in preparing for this certification. Those who have worked extensively with InfoSphere DataStage in real projects find the exam’s contextual depth familiar. However, even experienced professionals benefit from structured revision that revisits core architectural principles and recent enhancements in version 11.3. The parallel engine, metadata management enhancements, and performance tuning improvements introduced in this version are often focal points in the exam. Engaging with practice scenarios that simulate authentic data movement challenges helps solidify understanding. Instead of focusing on rote question memorization, candidates should invest in dissecting why certain configurations succeed while others falter under specific workloads.
Consider an example scenario aligned with typical IBM C2090-424 inquiries. Suppose an enterprise must integrate customer data from multiple regional systems into a unified data warehouse. The task involves handling disparate file formats, inconsistent encodings, and large volumes of transactional updates. The challenge is to design a DataStage job that ensures data accuracy, maintains referential integrity, and completes within tight time constraints. The ideal solution might involve parallel extraction from sources, centralized transformation through a combination of lookup and join stages, and efficient loading into the target using balanced partitioning. When analyzing such a scenario, a candidate must demonstrate both architectural foresight and operational pragmatism—qualities that IBM deliberately measures through its exam design.
The IBM C2090-424 examination also tests the candidate’s ability to align technical execution with organizational data strategies. InfoSphere DataStage is not just a tool for data movement but a component of a broader governance and analytics ecosystem. Understanding how it interacts with metadata services, information governance catalogs, and external orchestration systems reflects an advanced level of proficiency. In one of the descriptive narratives within the exam, a candidate might need to evaluate the impact of metadata updates on dependent jobs or determine how lineage information propagates through interconnected systems. These subtleties mirror the complexity of enterprise data ecosystems and test whether a professional can think beyond isolated technical tasks.
Another recurring theme is the handling of source and target system diversity. InfoSphere DataStage supports integration with a vast array of platforms, from relational databases and data warehouses to cloud-based storage and mainframe systems. A question may describe a heterogeneous environment involving Oracle, DB2, and Hadoop, requiring the candidate to determine the appropriate connectivity configurations and transformation strategies. Such inquiries assess the candidate’s adaptability and cross-platform comprehension, ensuring that certified individuals can manage multi-environment data landscapes efficiently.
Throughout the IBM C2090-424 examination, precision in terminology and conceptual clarity are paramount. The exam assumes that the candidate can distinguish between seemingly similar but contextually distinct elements, such as stages versus links, parameters versus variables, or project settings versus environment configurations. Misinterpreting these nuances can lead to incorrect answers even when the general idea is understood. Therefore, careful reading and logical inference play as significant a role as technical expertise. This intertwining of linguistic subtlety and technical depth exemplifies the intellectual rigor IBM expects of its certified professionals.
Ultimately, the IBM C2090-424 examination serves as a crucible of professional validation, ensuring that those who earn the credential possess both theoretical mastery and practical dexterity. The InfoSphere DataStage v11.3 certification extends beyond a mere badge of competence; it symbolizes an ability to orchestrate data with precision, maintain operational integrity, and align technology with business imperatives. To succeed, candidates must cultivate analytical insight, experiment within real environments, and approach each exam narrative as a microcosm of enterprise data integration reality.
Deep Dive into InfoSphere DataStage Architecture and Core Components
InfoSphere DataStage v11.3 represents a sophisticated data integration platform that harmonizes the complexities of enterprise data ecosystems into a cohesive workflow engine. The IBM C2090-424 examination probes deeply into the architecture, demanding that candidates demonstrate a profound understanding of the underlying structural and operational design. Central to this evaluation is the candidate’s familiarity with the layered architecture, which consists of the metadata repository, the parallel execution engine, client interfaces, and the integration with external systems. Knowledge of these core components allows professionals to design, monitor, and troubleshoot workflows efficiently, ensuring that data flows seamlessly across heterogeneous environments.
At the heart of InfoSphere DataStage lies the metadata repository, which functions as the central nervous system of the platform. This repository maintains definitions for data structures, stage properties, job parameters, and project configurations. During the examination, candidates may encounter scenarios that require interpreting metadata inconsistencies or ensuring that transformations comply with established enterprise standards. For instance, a question could describe a situation where multiple jobs rely on a shared container with evolving schema definitions. The examinee must understand that any misalignment in metadata can cascade into runtime errors or data inconsistencies, highlighting the criticality of rigorous metadata governance.
The parallel execution engine is another fundamental component that often appears implicitly in IBM C2090-424 narratives. This engine enables DataStage to process massive volumes of data by dividing tasks across multiple processing nodes, orchestrating concurrent execution, and minimizing latency. Candidates are expected to grasp the nuances of partitioning strategies, such as round-robin, hash, and range partitioning, which influence load balancing and throughput. In a practical scenario, the exam may describe a job that exhibits skewed performance, where certain nodes are overburdened while others remain underutilized. The correct inference requires recognizing how to adjust partitioning methods or modify stage configurations to achieve equitable distribution, demonstrating an understanding that bridges theory and pragmatic performance considerations.
The Designer client interface embodies the creative and technical fulcrum of DataStage operations. It allows professionals to construct, test, and debug jobs using an intuitive visual environment. Jobs consist of stages interconnected by links that define the flow of data. The IBM C2090-424 examination often presents descriptive scenarios where a complex job includes multiple transformers, lookup stages, and joins. Candidates are expected to identify the optimal configuration for these stages, taking into account factors such as data volume, processing order, and error handling. One illustrative narrative could involve a job that transforms customer transaction data from multiple sources, requiring the application of conditional logic to maintain accuracy while optimizing performance. In such cases, understanding stage-specific properties and how they interact with the broader job architecture becomes crucial.
The Director client complements the Designer by offering operational oversight. It facilitates job execution monitoring, error logging, and performance analysis. Candidates are frequently challenged with scenarios where a job fails during execution, accompanied by log messages indicating specific errors or warnings. In these situations, the examinee must analyze the logs to discern whether the problem originates from incorrect stage configurations, environmental discrepancies, or resource limitations. For example, a scenario might describe intermittent failures during a high-volume load, prompting the candidate to deduce that buffer sizes, partitioning, or node allocation adjustments are necessary to resolve the issue. This evaluative style ensures that certified professionals possess both analytical acumen and practical troubleshooting expertise.
The Administrator client embodies governance and configuration management within InfoSphere DataStage. It oversees project-level settings, user privileges, environment variables, and deployment protocols. A common exam narrative may describe an organization migrating projects from development to production, necessitating careful alignment of environment configurations to prevent runtime errors. Candidates are expected to identify steps such as exporting projects, validating parameter sets, and verifying environment variables. Misalignment in any of these areas can compromise job execution, emphasizing the need for meticulous administrative practices. The IBM C2090-424 examination evaluates not just familiarity with the Administrator interface but also the candidate’s capacity to anticipate operational pitfalls and ensure consistency across environments.
Job sequencing, although orchestrated through the same architecture, introduces additional complexity. Sequences manage dependencies, conditional execution, and exception handling across multiple jobs. A question might illustrate a scenario where a sequence fails due to a misconfigured condition or unhandled exception. The examinee must interpret the sequence logic and recommend modifications to achieve desired operational behavior. For example, incorporating appropriate triggers or error handling stages may prevent cascading failures, reflecting the candidate’s ability to integrate architectural knowledge with procedural intelligence.
Within the parallel execution paradigm, buffer management and stage optimization are essential concepts. DataStage allows customization of buffer sizes, record counts, and node assignments to maximize throughput. Candidates may encounter scenarios where performance bottlenecks occur despite correctly configured jobs. The examination often probes the examinee’s ability to diagnose such issues, considering memory allocation, data skew, and stage-specific optimizations. For instance, a job involving a large transformer stage could encounter memory contention, necessitating the adjustment of parallel options or splitting the job into smaller, manageable components. The nuanced understanding of how these components interact underpins the platform’s operational efficiency and forms a recurring theme in IBM C2090-424 evaluations.
Another core aspect tested by the IBM C2090-424 exam is the integration with external systems. DataStage supports a wide array of source and target platforms, including relational databases, mainframes, cloud storage, and enterprise data warehouses. The candidate must comprehend connectivity protocols, schema mapping, and data type conversions. For example, a scenario might describe integrating data from an Oracle database and a Hadoop cluster into a unified target, requiring careful consideration of transformations, encoding formats, and performance constraints. The examinee must determine the appropriate connector, stage configuration, and partitioning strategy to maintain both accuracy and efficiency, demonstrating an applied understanding of multi-system orchestration.
Error handling and recovery mechanisms are deeply intertwined with the architectural fabric. DataStage provides facilities for capturing, logging, and responding to errors within both individual jobs and sequences. An exam scenario may detail a workflow encountering repeated failures due to invalid input or transformation anomalies. The candidate is expected to propose corrective measures, such as implementing reject links, modifying transformer logic, or adjusting job parameters. This type of inquiry evaluates the examinee’s ability to anticipate failure modes, diagnose root causes, and apply architectural knowledge to mitigate operational disruptions.
The concept of parameterization also features prominently within the examination framework. Parameters enable dynamic job behavior, allowing variables such as file paths, database connections, and thresholds to be defined at runtime. A candidate might encounter a situation where a job behaves inconsistently across development and production environments. The correct resolution involves verifying that parameters are accurately defined, propagated, and referenced within the job design. Such scenarios underscore the interconnectedness of architectural comprehension, operational prudence, and effective use of platform features.
Security and governance constitute another intricate layer of the InfoSphere DataStage architecture. IBM’s platform incorporates robust role-based access controls, enabling granular management of user privileges and project-level operations. The examination may describe a scenario where a user is unable to access a specific job component despite holding administrative permissions. The examinee must reason through inherited roles, operational restrictions, and project-level security settings to identify the underlying issue. This reflects the broader enterprise requirement for controlled access, auditability, and compliance with regulatory frameworks, emphasizing that certified professionals are equipped to manage both technical and governance aspects.
Data lineage and impact analysis are subtle yet significant components of architectural understanding. InfoSphere DataStage maintains metadata that traces data from source to target, including transformations applied at each stage. A candidate may be presented with a scenario requiring identification of dependencies for a specific data element. Understanding how lineage information propagates across jobs, sequences, and projects allows the examinee to predict impacts of schema changes, transformation updates, or job modifications. This analytical capability ensures that certified practitioners can maintain system integrity while implementing changes in complex enterprise environments.
Performance tuning extends beyond node allocation and buffer management, encompassing thoughtful job design choices. Candidate scenarios may involve optimizing multiple parallel pipelines, reducing data skew, and minimizing redundant transformations. The examination often tests the ability to evaluate trade-offs, such as choosing between a centralized versus distributed transformation approach, based on data volume and system constraints. The nuanced understanding of these architectural considerations equips professionals to design resilient, high-performance data integration solutions.
Environmental management is a recurrent theme in IBM C2090-424 questions. InfoSphere DataStage allows definition of environment variables, project settings, and shared configurations that influence job behavior across development, testing, and production landscapes. Scenarios may describe a job that functions correctly in one environment but fails in another. The candidate must infer that discrepancies in environment variable definitions or project-level configurations are likely contributors. Recognizing the interplay between architecture and operational environments demonstrates advanced expertise that extends beyond mere tool proficiency.
Operational monitoring and logging are also intricately tied to the platform’s architecture. Director and Administrator clients provide insights into job execution metrics, error logs, and performance statistics. Candidates may encounter exam scenarios depicting subtle anomalies, such as intermittent job failures or unexpected throughput reductions. The examinee is expected to interpret log entries, identify the root cause, and recommend adjustments in job design, resource allocation, or environmental configuration. This evaluative approach reinforces the examination’s emphasis on applied understanding over theoretical recall.
Integration with IBM’s broader Information Server suite is another architectural consideration frequently reflected in the C2090-424 narratives. InfoSphere DataStage interacts with metadata repositories, governance catalogs, and quality management tools to ensure data consistency and compliance. A scenario might require evaluating how a change in the metadata repository affects dependent jobs or determining the correct approach to synchronize project configurations across environments. Such questions gauge the candidate’s holistic understanding of how DataStage fits within the enterprise data ecosystem.
The examination often includes scenarios emphasizing scalability. InfoSphere DataStage v11.3 supports processing increasingly large data volumes through parallelism and distributed resources. Candidates are expected to recognize how architectural choices impact scalability, such as the decision to employ a parallel job instead of a sequential design, or to partition data based on hash keys to avoid skewed workloads. Understanding these subtleties ensures that certified professionals can anticipate performance challenges and implement sustainable data integration strategies.
Practical exercises in the examination encourage analytical reasoning. For instance, a narrative may describe a job that intermittently truncates data during high-volume execution. The examinee must assess the interplay between stage configuration, metadata definitions, and parallelism options to identify a solution that ensures data integrity. Such inquiries reinforce the necessity of intertwining architectural comprehension with hands-on problem-solving skills, demonstrating that the IBM C2090-424 certification measures both knowledge and applied proficiency.
The interdependence of stages, links, sequences, and parameters exemplifies the intricate nature of InfoSphere DataStage architecture. The examination evaluates how candidates manage these interactions to maintain robust, efficient, and accurate data workflows. Scenarios may describe complex workflows where transformations depend on dynamically generated input, requiring candidates to adjust job designs, parameter references, and sequence logic to ensure seamless execution. This layered questioning style reflects the sophistication of enterprise data operations and tests candidates’ ability to navigate real-world challenges.
Understanding error propagation within parallel jobs is another recurring theme. A scenario might present a job that produces incorrect results when processing a subset of data due to data skew or buffer misalignment. The examinee must reason through the architectural mechanisms that influence data distribution, identify potential sources of skew, and propose modifications to partitioning or stage design. This demands both theoretical knowledge and practical insight into the operational nuances of parallel execution.
The examination also probes candidate understanding of project-level organization. InfoSphere DataStage projects encapsulate jobs, sequences, containers, and shared resources, facilitating collaborative development, version control, and environment-specific configurations. Scenarios may describe a project that behaves inconsistently due to conflicting shared container definitions or misaligned parameter sets. The candidate must evaluate the architecture holistically to reconcile these discrepancies and maintain consistency across workflows.
In addition to technical proficiency, IBM C2090-424 evaluates the candidate’s ability to integrate architectural knowledge into strategic decision-making. Scenarios often involve trade-offs between performance, maintainability, and scalability. A job may need to process high-volume, heterogeneous data sources while minimizing system load and ensuring accurate transformation. The examinee must design solutions that align with architectural best practices, demonstrating an understanding that extends beyond superficial task execution to encompass enterprise-wide operational efficiency.
By emphasizing metadata management, parallel execution, client interfaces, administrative oversight, job sequencing, and environmental alignment, the IBM C2090-424 examination ensures that certified professionals possess a comprehensive mastery of InfoSphere DataStage architecture. The narratives encourage examinees to synthesize knowledge across components, understand interdependencies, and anticipate operational challenges. Practical application is consistently tested through scenario-based questions that reflect authentic enterprise data integration problems, requiring both analytical reasoning and hands-on insight.
Working with DataStage Stages, Links, and Data Flow Design
The InfoSphere DataStage v11.3 environment is a robust platform engineered for seamless extraction, transformation, and loading of complex datasets. Within the IBM C2090-424 certification examination, a significant emphasis is placed on the candidate’s ability to understand the intricacies of stages, links, and the design of data flow. DataStage stages act as processing nodes, performing distinct operations such as transformation, aggregation, lookup, and data quality enforcement, while links serve as conduits facilitating the passage of data between these stages. Mastery of how stages interact with each other, how data flows through the links, and how the overall job architecture impacts performance is essential for success on the exam.
DataStage stages are diverse, encompassing categories such as sequential file stages, transformer stages, lookup stages, join stages, and aggregator stages, among others. Each stage is designed to perform a unique function within the data flow pipeline. Candidates are expected to grasp not only the functionality of each stage but also its optimal usage in varied scenarios. For instance, the transformer stage is a versatile node that allows conditional transformations, derivations, and derivation rules. A scenario presented in the examination might describe a job that requires multiple conditional transformations of customer transaction data. The examinee must determine the most efficient use of transformer derivations to maintain data integrity while optimizing throughput. Understanding stage-specific properties and their interactions is crucial, as improper configuration can lead to data loss or performance degradation.
Links in DataStage are equally critical, acting as pathways through which data moves from one stage to another. They carry not only the data itself but also associated metadata, ensuring that transformations and aggregations are contextually accurate. During the IBM C2090-424 examination, a scenario might illustrate a job where data is being inconsistently routed between stages, resulting in missing or duplicated records. The candidate must analyze the job design to identify whether the issue stems from incorrect link configuration, stage incompatibility, or partitioning errors. Recognizing the significance of links and their metadata propagation is vital for designing reliable data flows.
Job design in InfoSphere DataStage revolves around orchestrating stages and links to achieve the desired transformation objectives efficiently. The examination often presents complex scenarios involving multiple source systems, diverse data formats, and conditional processing rules. A typical scenario might require integrating customer data from relational databases, sequential files, and external APIs, applying transformations to standardize formats, calculating derived metrics, and finally loading the consolidated data into a warehouse. The candidate must design a job that not only accomplishes these tasks accurately but also maintains high performance and scalability. This requires careful consideration of stage selection, link configuration, parallel processing options, and parameterization.
Transformer stages are frequently emphasized in the examination, given their versatility and complexity. They allow conditional derivations, function application, and column manipulation within the data flow. A scenario may describe a job where transactional data must be categorized based on multiple conditions such as transaction amount, geographic region, and customer type. The examinee is expected to determine the correct derivations and constraint rules to apply within the transformer, ensuring that each record is processed accurately and efficiently. Such inquiries test both conceptual understanding and the practical ability to implement transformations that adhere to enterprise data standards.
Lookup stages are another focal point, enabling the enrichment of data by referencing external datasets. In a typical examination narrative, a job might require augmenting transactional records with customer demographic information stored in a separate database. The candidate must configure the lookup stage to handle unmatched records gracefully, select appropriate join types, and optimize performance for large datasets. Mastery of lookup stage options, such as handling multiple reference datasets and implementing default values, is often tested to ensure the examinee can manage complex data integration scenarios.
Join stages consolidate data from multiple input streams based on key columns. During the examination, a scenario may present a job where data from several operational systems must be merged to generate a comprehensive reporting dataset. The candidate is expected to select the correct join type, configure the stage to handle null values or duplicates appropriately, and ensure that the merged output aligns with business rules. Understanding the nuances of join behavior, including inner, left outer, and full outer joins, is essential to maintain data accuracy and prevent runtime anomalies.
Aggregator stages perform computations over groups of data, such as sums, averages, and counts. A scenario could involve calculating regional sales totals from transactional data sourced from multiple systems. The examinee must determine how to configure the aggregator stage to group records correctly, apply the appropriate aggregate functions, and handle exceptions or missing data. Misconfiguration can lead to incorrect aggregates or performance bottlenecks, demonstrating the importance of precise stage setup and a thorough understanding of the underlying logic.
Sequential file stages are often introduced in scenarios involving file-based data integration. Candidates must comprehend how to read and write delimited, fixed-width, and hierarchical files. An example narrative might describe a job ingesting CSV files with inconsistent encodings, requiring transformations to normalize character sets and eliminate formatting errors before further processing. The examinee is expected to configure the sequential file stages correctly, ensuring that data integrity is maintained and downstream stages receive clean and accurate inputs. Mastery of file stage properties, such as record delimiters, column definitions, and error handling options, is crucial for successful job execution.
Job sequencing integrates multiple jobs into coherent workflows, orchestrating execution order, conditional logic, and error handling. The examination frequently presents scenarios where job dependencies must be managed meticulously. For instance, a sequence may involve executing a series of ETL jobs where downstream processing depends on successful completion of upstream jobs. The candidate must configure triggers, failure handling, and conditional execution logic to ensure that the sequence behaves as intended. Understanding sequence stages, such as job activity, decision, and notification stages, is key to managing complex, multi-job orchestrations effectively.
Partitioning and parallelism directly influence data flow performance in multi-stage jobs. Candidates are expected to comprehend how data partitioning strategies, such as hash, round-robin, and range, impact load balancing and processing efficiency. A scenario might describe a job processing millions of records per hour, with certain partitions experiencing data skew leading to performance degradation. The examinee must adjust partitioning methods or redesign stage interactions to alleviate the skew and optimize throughput. Understanding how parallelism interacts with stage types and link configurations is critical to achieving high-performance data integration.
Error handling in stages and links is a recurring theme in the examination. Candidates may be presented with scenarios where jobs encounter invalid data, failed lookups, or constraint violations. The examinee must determine how to implement reject links, conditional processing, or error notifications to ensure that the job continues processing valid data while logging exceptions for review. Such scenarios test the candidate’s ability to integrate error handling into the job design proactively rather than reactively.
Parameterization of stages and links enhances job flexibility and reusability. In the examination, a scenario may involve a job that processes data from multiple environments, such as development, testing, and production. The candidate must utilize parameters to dynamically define file paths, database connections, and thresholds, ensuring that the job can execute seamlessly across environments. This requires understanding how parameters propagate through stages, links, and sequences, and how they interact with job-level and project-level configurations.
Data transformation logic often involves complex calculations, string manipulations, and conditional branching. A scenario might require deriving new columns based on multiple existing fields, applying business rules, or aggregating values conditionally. Candidates are expected to implement these transformations efficiently within transformer or aggregator stages, ensuring data accuracy and computational efficiency. The examination may test subtle nuances, such as handling null values, applying nested conditional logic, or optimizing derivation expressions to reduce processing time.
Link metadata propagation is an important concept that ensures data consistency across stages. Candidates must understand how column names, data types, and attributes are inherited or transformed as data moves through links. A scenario may illustrate a job failing due to a type mismatch between connected stages. The examinee must analyze the link metadata, identify the discrepancy, and implement corrective actions, demonstrating attention to detail and comprehension of data lineage within job design.
Stage optimization is frequently evaluated, emphasizing efficient use of resources and minimizing processing bottlenecks. Candidates might encounter scenarios where multiple transformer stages are chained together, leading to increased memory consumption and reduced performance. The examination expects the candidate to propose design alternatives, such as consolidating derivations or restructuring stage sequences, to enhance execution efficiency. Understanding the balance between readability, maintainability, and performance is essential for high-quality job design.
Handling heterogeneous data sources is a recurrent scenario type. Jobs often need to integrate data from relational databases, flat files, XML sources, and web services. Candidates must determine appropriate stages and configurations to standardize, validate, and transform data effectively. A typical narrative may describe inconsistencies in source data formats, requiring the candidate to apply conditional transformations and data cleansing operations to achieve uniform output. Mastery of stage capabilities in addressing source diversity is a critical skill assessed by the examination.
Testing and debugging are integral to job design and are commonly reflected in IBM C2090-424 narratives. Candidates may be asked to identify reasons for job failures based on described behaviors, log excerpts, or runtime observations. For example, a job producing incomplete data may involve misconfigured stages, incorrect link connections, or parameter errors. The examinee must interpret the scenario, trace the data flow, and recommend adjustments, demonstrating a practical approach to problem-solving within the architectural constraints of DataStage.
Scalability considerations also influence stage and link configuration. Jobs must be designed to accommodate increasing data volumes without compromising performance. A scenario may depict a job performing well under small datasets but failing or slowing significantly with larger volumes. The candidate must identify design improvements, such as parallelizing specific stages, optimizing partitioning, or implementing staged transformations, to maintain consistent performance. These inquiries test the candidate’s ability to anticipate operational challenges and apply architectural principles to scalable solutions.
Integration with IBM Information Server components enhances job design and execution. A scenario might involve a DataStage job interacting with the metadata repository, governance tools, or quality services to ensure consistent and accurate data transformations. Candidates must understand how stages, links, and job sequences interact with these components, ensuring that workflows are aligned with enterprise standards and maintain traceable lineage. This integration emphasizes the holistic nature of job design beyond isolated stage functionality.
Complex transformations often require nested conditional logic, multiple lookups, or iterative calculations. A scenario may describe a job calculating customer lifetime value by combining transactional, demographic, and behavioral data. The candidate must determine the optimal combination of transformer and lookup stages, design efficient derivations, and ensure that intermediate results are correctly propagated through links. Such exercises highlight the need for strategic thinking, careful planning, and meticulous attention to data dependencies within job design.
Maintaining data quality throughout the flow is a critical consideration. Jobs must incorporate validation stages, error handling, and cleansing operations to prevent inaccurate or inconsistent data from propagating downstream. A scenario may describe detecting anomalies in input datasets, such as duplicate records, missing values, or out-of-range entries. The examinee must design stages and links that identify, segregate, or correct such anomalies, demonstrating both technical proficiency and an understanding of data stewardship.
Advanced job design considerations, such as job modularization and reusable containers, are also tested. Candidates might encounter a scenario where repetitive transformations are required across multiple jobs. The correct approach involves creating shared containers or parameterized modules to standardize logic, reduce redundancy, and facilitate maintenance. The examination evaluates not only knowledge of technical capabilities but also the candidate’s ability to implement best practices that enhance operational efficiency and maintainability.
Finally, understanding the end-to-end impact of stage and link configuration is central to the IBM C2090-424 examination. Candidates must reason through the complete data flow, anticipate potential bottlenecks or errors, and optimize job design for performance, accuracy, and scalability. Scenarios frequently integrate multiple stages, complex links, and conditional sequences, requiring the examinee to synthesize knowledge across the DataStage environment and apply it to realistic enterprise situations.
Advanced Parallelism, Performance, and Tuning Strategies
InfoSphere DataStage v11.3 offers a sophisticated parallel processing architecture that enables the efficient movement, transformation, and integration of vast volumes of enterprise data. Within the IBM C2090-424 certification examination, advanced concepts surrounding parallelism, performance optimization, and tuning strategies are examined extensively. Candidates must demonstrate an intimate understanding of how parallel jobs distribute data, manage resources, and maintain high throughput while ensuring accuracy and reliability. This evaluation is designed not only to assess technical knowledge but also to gauge practical problem-solving capabilities in real-world enterprise scenarios.
Parallelism in DataStage refers to the platform’s ability to execute multiple operations concurrently across one or more processing nodes. A typical scenario in the examination may describe a job that reads millions of records from a database, performs transformations, and loads the data into a target system within a constrained time window. The candidate must determine the optimal parallelism strategy, considering factors such as partitioning methods, node allocation, and stage-specific parallel options. Understanding how different partitioning approaches, such as hash, range, and round-robin, influence data distribution and workload balance is crucial to prevent bottlenecks and maximize performance.
Partitioning data efficiently is fundamental to parallel processing. Candidates may encounter a scenario where uneven data distribution causes certain nodes to process disproportionately large subsets, resulting in skew and reduced throughput. The examinee must analyze the job design, identify the root cause of skew, and implement corrective measures, such as adjusting partitioning keys or redistributing data using specialized stages. The ability to anticipate and mitigate data skew reflects a deep comprehension of parallel job dynamics and is a recurring theme in IBM C2090-424 evaluation narratives.
Pipeline parallelism is another critical consideration. It allows multiple stages within a job to process different segments of data simultaneously. For example, a scenario might describe a job where an upstream transformation stage produces output that is immediately consumed by a downstream aggregation stage. The examinee must understand how pipeline parallelism can accelerate processing while avoiding excessive memory consumption or contention between stages. Proper tuning of buffer sizes, commit intervals, and stage options is required to ensure optimal utilization of system resources without compromising data integrity.
Node allocation and resource management are central to achieving high-performance parallel execution. Candidates are expected to comprehend how nodes interact within the DataStage environment, how workload is distributed across them, and how node-specific configurations affect job execution. A scenario could involve a job performing inconsistently due to insufficient memory allocation on certain nodes. The examinee must propose adjustments to node configuration, such as increasing available memory, modifying stage buffer sizes, or redistributing data to balance the load. Such narratives test the candidate’s ability to align architectural knowledge with operational efficiency.
Buffer management is a nuanced yet essential aspect of performance tuning. DataStage jobs process data in memory buffers, and inadequate buffer sizes can result in disk spooling, slower execution, or even job failures. In an exam scenario, a candidate might be asked to resolve a situation where large data transformations cause intermittent memory contention. The correct approach involves adjusting buffer allocations at the stage or job level, considering data volume, stage complexity, and node capacity. Understanding how buffer management interacts with parallel execution ensures that jobs maintain both speed and reliability.
Performance monitoring and analysis form a critical part of the examination. Candidates may be presented with logs, performance metrics, or descriptions of job behavior indicating suboptimal throughput, high CPU usage, or delayed execution. The examinee must interpret these indicators to identify the root causes, whether they stem from stage configuration, partitioning inefficiencies, or node resource contention. For instance, an analysis might reveal that a transformer stage is disproportionately consuming CPU cycles due to complex derivations. Addressing such inefficiencies requires restructuring derivations, consolidating operations, or applying stage-specific optimization techniques.
Job design significantly impacts parallel performance. A scenario may describe a job with multiple chained transformer stages that create excessive memory usage and stage-level contention. The candidate must determine whether to consolidate derivations, split the job into smaller modular jobs, or adjust stage options to enhance parallelism. Such exercises test the ability to balance maintainability, performance, and operational complexity, reflecting real-world challenges in enterprise ETL workflows.
The IBM C2090-424 examination frequently evaluates candidates’ understanding of stage-level tuning. Each stage in a parallel job has configurable properties that influence performance, including cache sizes, degree of parallelism, and execution order. For example, an aggregation stage processing millions of records may perform suboptimally due to insufficient partitioning or improper buffer allocation. The examinee must recognize the implications of these settings and adjust them to achieve optimal throughput. Scenarios may involve identifying which stages benefit most from parallelism or restructuring stage connections to reduce data transfer overhead.
Handling large-scale data transformations requires careful consideration of data distribution and computation strategies. A typical scenario might involve calculating complex metrics across terabytes of transactional data, where performance bottlenecks occur at join or transformer stages. Candidates must analyze how parallel execution distributes data, evaluate whether stage-level adjustments or partitioning refinements are necessary, and propose solutions that maintain accuracy while improving speed. This combination of analytical and practical skills demonstrates the candidate’s ability to manage high-volume ETL operations effectively.
The examination also emphasizes environmental factors affecting parallelism. Candidates may encounter scenarios where jobs behave differently in development and production due to variations in node capacity, memory allocation, or system load. Understanding how environmental differences influence parallel execution is critical to diagnosing performance issues and ensuring consistency across deployments. For example, a job that runs efficiently on a development server with limited data may encounter memory contention or skew when scaled to production, requiring careful tuning and partitioning adjustments.
Data skew is a persistent challenge in parallel processing. A scenario could involve a job where certain partitions receive disproportionately large numbers of records, leading to uneven processing times. Candidates must determine appropriate corrective measures, such as selecting alternative partitioning keys, implementing data sampling, or redistributing data across nodes. Recognizing the interplay between partitioning, stage configuration, and node resource utilization is essential for achieving balanced parallel execution and is a recurrent theme in IBM C2090-424 evaluation.
The interplay between parallelism and job sequences is another consideration. Candidates may be presented with scenarios where multiple parallel jobs are orchestrated in a sequence, with interdependencies affecting execution efficiency. The examinee must design sequences that preserve parallelism advantages while coordinating dependencies, handling errors, and ensuring accurate data flow. This requires understanding both the architectural principles of DataStage parallel execution and the practical implications of orchestrating multi-job workflows.
Job parameterization contributes to performance tuning by enabling dynamic configuration of stages, buffers, and parallel options. A scenario might describe a job processing variable data volumes across different environments, necessitating adaptive buffer sizing or partitioning strategies. The examinee must determine how to utilize parameters effectively to adjust execution properties without manual intervention, ensuring consistent performance across varying conditions. This reflects a broader requirement for flexibility and operational resilience in high-volume ETL environments.
Optimization strategies also encompass minimizing data movement between nodes. Candidates may be asked to evaluate scenarios where excessive data transfer causes performance degradation. Solutions could involve redesigning stage connections, applying local processing where possible, or implementing partitioned joins to reduce inter-node communication. Understanding how data locality affects parallel execution is fundamental to achieving high performance in large-scale DataStage jobs.
Advanced transformations, such as nested lookups, complex aggregations, or conditional derivations, further test parallel execution comprehension. A scenario may describe a job where complex transformer operations create contention on specific nodes, causing imbalanced performance. The examinee must analyze whether restructuring transformations, optimizing lookup configurations, or applying staged processing can alleviate bottlenecks. This illustrates the necessity of integrating parallelism knowledge with transformation logic for efficient job design.
Memory management is closely tied to performance tuning in parallel jobs. Candidates may encounter scenarios where large input datasets or complex transformations result in memory exhaustion. Corrective strategies include adjusting stage buffer sizes, reducing intermediate data storage, or splitting jobs to distribute memory demands. The examination evaluates the candidate’s ability to diagnose memory-related bottlenecks and implement solutions that maintain throughput and reliability.
Monitoring and logging provide critical insights into performance issues. Candidates may be asked to interpret job execution logs, identify stages with prolonged processing times, or detect patterns indicative of skew, contention, or memory constraints. The examinee must then recommend tuning strategies, such as optimizing stage configurations, modifying partitioning methods, or adjusting parallel execution parameters. This demonstrates applied analytical skills essential for managing enterprise-scale ETL workflows effectively.
Data provenance and traceability are also relevant to performance evaluation. Scenarios may involve tracking the flow of records through parallel jobs to identify performance bottlenecks or validate transformations. Candidates must utilize log data, stage metrics, and monitoring tools to trace execution paths, identify inefficiencies, and propose tuning measures. This reinforces the importance of maintaining both operational visibility and performance awareness in complex data integration environments.
Candidate evaluation extends to practical orchestration of parallel jobs with dependencies. A scenario might describe a sequence of jobs where upstream performance directly impacts downstream execution. The examinee must design solutions that preserve parallelism advantages, handle variable data loads, and ensure timely completion. Techniques could include adjusting stage options, introducing intermediate storage, or revising job dependencies to optimize overall sequence performance.
Load balancing is a key concept frequently assessed in the examination. Candidates may encounter situations where uneven node utilization causes certain partitions to lag while others complete quickly. Corrective actions include refining partitioning keys, adjusting parallelism degrees, and redistributing stages across nodes. Understanding the relationship between node allocation, data partitioning, and execution efficiency is critical for achieving optimal parallel performance.
Candidates are also expected to manage high-volume data movement efficiently. Scenarios may present jobs transferring millions of records between heterogeneous systems. Solutions involve selecting appropriate stages, configuring buffers, applying partitioned processing, and minimizing inter-node communication. The IBM C2090-424 examination evaluates the candidate’s ability to design robust, scalable jobs that perform consistently under demanding operational conditions.
Finally, candidate proficiency is measured by the ability to integrate all tuning strategies into holistic job designs. A scenario may combine complex transformations, multiple lookups, aggregations, parallelism, skew, and environmental variability. The examinee must synthesize knowledge of stage configuration, link behavior, partitioning, node allocation, buffer management, and sequence orchestration to produce efficient, reliable, and scalable solutions. This comprehensive understanding of advanced parallelism and performance tuning is at the core of the IBM C2090-424 certification’s evaluative framework.
Real-World Scenarios and DataStage Administration Insights
InfoSphere DataStage v11.3 is not only a powerful data integration platform but also a sophisticated environment requiring careful administrative oversight to ensure operational reliability and efficiency. Within the IBM C2090-424 certification examination, candidates are assessed on their ability to manage, monitor, and optimize DataStage projects in real-world scenarios. The examination evaluates knowledge of job orchestration, user management, project governance, and integration with broader enterprise data systems. Understanding the interplay between technical configurations, administrative controls, and business requirements is essential for successfully navigating the exam and applying DataStage capabilities effectively in practical environments.
DataStage projects serve as the central organizational units where jobs, sequences, shared containers, and parameters are maintained. Candidates are expected to comprehend how project-level settings influence job execution, metadata management, and overall data flow consistency. A scenario in the examination might describe a project migrated from development to production that exhibits intermittent failures or inconsistencies. The candidate must recognize that misaligned environment variables, parameter sets, or project configurations are potential sources of the problem. Corrective actions may include verifying project-level settings, reconciling parameter values, and ensuring that environment-specific references are consistent across all jobs and sequences.
User and role management is a recurring theme within the IBM C2090-424 evaluation. DataStage provides granular control over user privileges, enabling administrators to define roles that govern job design, execution, monitoring, and system access. A typical scenario may involve a user who is unable to execute certain jobs despite holding design permissions. The candidate must infer that role inheritance, privilege restrictions, or project-specific access controls may be responsible for the issue. Understanding the nuances of role-based access control, including the implications of operational versus design privileges, is critical to maintaining secure and well-governed projects.
Job deployment and version management are key administrative responsibilities evaluated by the examination. A candidate may encounter a scenario in which multiple versions of a job exist across development, testing, and production environments, resulting in inconsistent outputs or failures. The examinee must apply knowledge of DataStage version control, project export and import procedures, and environment synchronization to ensure that the correct job version is deployed. Awareness of version dependencies, parameter propagation, and environmental adjustments is crucial to maintain operational integrity during project migration or updates.
Monitoring job execution is a fundamental administrative activity assessed in the examination. Candidates may be asked to interpret execution logs, identify performance bottlenecks, and determine the root causes of errors or delays. For instance, a scenario might describe a job that completes successfully but exhibits unusually high resource consumption. The candidate must analyze runtime metrics, consider stage configurations, parallelism settings, and buffer allocations, and propose tuning or design adjustments to optimize performance. This demonstrates the ability to integrate operational monitoring with practical problem-solving.
Error handling at the administrative level is another vital aspect. Candidates must understand how to implement robust mechanisms to capture, report, and mitigate job failures. A scenario might describe a sequence that halts unexpectedly due to an unhandled exception in a downstream job. The examinee is expected to configure error handling stages, such as exception handlers or notifications, to ensure continuity and visibility. Mastery of these administrative strategies ensures that DataStage projects maintain resilience and can recover gracefully from unexpected events, aligning operational practices with enterprise reliability standards.
DataStage administration also encompasses environmental configuration management. Jobs often rely on environment variables, system-specific paths, and connection definitions to function correctly. A scenario in the exam may describe a job that runs flawlessly in the development environment but fails in production. The candidate must identify that discrepancies in environment variables, database connection details, or server-specific configurations are likely causes and take corrective action. Understanding the interaction between jobs, sequences, and their operating environments is essential for ensuring seamless execution across diverse infrastructures.
Backup and recovery strategies are integral to DataStage administration. Candidates may be asked to devise plans for preserving project integrity, safeguarding metadata, and recovering from accidental job deletions or environment failures. A scenario might describe a corrupted project or a missing shared container, requiring the candidate to recommend restoration procedures using exported project backups. Knowledge of proper scheduling, backup consistency, and restoration steps demonstrates the examinee’s capability to maintain operational continuity in complex enterprise environments.
Integrating DataStage with databases and external systems is a recurring theme in administrative scenarios. Jobs may involve multiple source systems, including relational databases, mainframes, cloud-based storage, or flat files. Candidates are expected to configure connections, validate data accessibility, and troubleshoot connectivity issues. An examination narrative might present a job failing due to an unresponsive database or incorrect schema mapping. The candidate must determine the appropriate administrative actions, such as verifying credentials, testing connectivity, or adjusting stage properties to ensure accurate and timely data transfer.
Performance monitoring is closely linked to administrative insight. Candidates may encounter scenarios where job throughput fluctuates or resource utilization is uneven. Understanding system-level metrics, such as CPU usage, memory allocation, and node activity, allows the examinee to propose administrative or configuration adjustments to improve performance. For instance, reallocating processing nodes, adjusting parallelism degrees, or modifying stage buffer sizes may resolve observed inefficiencies. Such scenarios test the ability to align administrative oversight with technical tuning, ensuring high-performance data integration.
Metadata management is another critical area evaluated within the IBM C2090-424 examination. Candidates are expected to understand how project metadata influences job execution, lineage tracking, and data consistency. A scenario might describe inconsistencies in column definitions between jobs using shared containers or reference tables. The examinee must apply administrative knowledge to reconcile these discrepancies, maintain synchronization, and ensure that downstream processes operate reliably. Mastery of metadata governance enables certified professionals to maintain accuracy, consistency, and auditability across projects.
DataStage administrative responsibilities extend to job scheduling and operational automation. Candidates may be asked to configure job schedules, sequence triggers, and notifications to optimize workflow execution. For example, a scenario might describe a sequence of dependent jobs requiring coordinated execution based on upstream completion or external event triggers. The candidate must configure appropriate scheduling parameters, handle potential conflicts, and ensure that jobs execute reliably and in the correct order. This illustrates the integration of administrative insight with practical operational strategy.
Security considerations in DataStage administration encompass user authentication, project access controls, and data protection policies. A scenario might describe unauthorized access attempts or restricted user activity. The examinee must evaluate role configurations, project-level permissions, and operational audit settings to ensure that access aligns with organizational policies. Understanding the interplay between technical configurations and enterprise governance is essential for protecting sensitive data and maintaining compliance with regulatory standards.
Real-world administrative scenarios also address resource optimization. Candidates may encounter jobs that consume excessive memory, CPU, or I/O bandwidth, impacting other processes. The examinee must analyze resource utilization, identify stages causing contention, and propose adjustments such as optimizing stage options, redistributing workload, or reconfiguring node allocations. These scenarios demonstrate the candidate’s ability to harmonize operational efficiency with technical performance within the enterprise environment.
DataStage administration requires proactive monitoring of job dependencies and sequence integrity. A scenario may describe cascading failures in sequences caused by upstream job errors or misconfigured triggers. The candidate must evaluate the sequence logic, implement conditional execution rules, and ensure proper exception handling. Mastery of these administrative techniques ensures that complex workflows execute reliably and predictably, reducing operational risk and minimizing downtime.
Audit and compliance management is increasingly relevant within DataStage administration. Candidates may be tested on scenarios involving traceability of data transformations, historical job execution records, and validation of metadata changes. For example, a scenario may describe the need to verify the lineage of specific data fields through multiple jobs and sequences. The examinee must utilize administrative tools to extract lineage information, correlate transformations, and confirm compliance with enterprise governance policies. Such capabilities reflect the professional’s ability to manage both technical and regulatory dimensions of data integration.
Advanced scenarios may involve multi-environment management, where projects operate across development, testing, and production landscapes. Candidates must ensure that jobs, parameters, and environment variables are correctly synchronized across environments. A scenario might describe inconsistent behavior due to misaligned configuration files or unpropagated parameter changes. The examinee must apply administrative knowledge to validate configurations, adjust references, and harmonize project settings, ensuring consistent operation across all environments.
High-volume job management is another focus area. Candidates may be presented with situations where large data volumes cause prolonged job execution or failures. The examinee must evaluate stage-level settings, parallelism configurations, and node resource allocations to improve throughput. For example, optimizing partitioning methods, tuning buffer sizes, or restructuring sequences may alleviate performance bottlenecks. Such scenarios test the candidate’s ability to maintain operational performance under demanding workloads.
Job recovery and restart mechanisms are crucial for maintaining resilience. A scenario might describe a long-running job that fails mid-execution due to network interruption or resource contention. The candidate must determine how to implement restart options, checkpointing, and selective recovery strategies to minimize data loss and resume processing efficiently. Understanding these mechanisms ensures that operations remain robust and reliable in real-world environments.
Integration with enterprise monitoring and alerting systems is also relevant. Candidates may encounter scenarios requiring configuration of notifications for job failures, completion, or performance anomalies. The examinee must ensure that alerts provide actionable information, align with organizational workflows, and facilitate timely corrective action. Such capabilities demonstrate the professional’s ability to maintain operational awareness and respond proactively to issues.
Data consistency and reconciliation are frequently tested within administrative contexts. A scenario may involve verifying that multiple jobs processing overlapping datasets produce consistent outputs. The candidate must analyze job logic, parameter settings, and stage configurations to ensure that results are accurate and aligned with business expectations. This emphasizes the intersection of administrative insight and technical verification in maintaining data quality.
The examination may also include scenarios involving disaster recovery planning. Candidates must understand strategies for project replication, metadata backup, and environment restoration. A scenario might describe the need to restore a critical project after server failure. The examinee must identify appropriate backup files, validate integrity, and execute restoration procedures to resume operations with minimal disruption. Such scenarios test practical skills in maintaining operational continuity and resilience.
Candidates are also expected to demonstrate knowledge of operational optimization. This includes identifying redundant stages, consolidating sequences, and eliminating unnecessary data movement. A scenario may describe a job with excessive intermediate processing steps, causing resource strain. The examinee must analyze the workflow, identify optimization opportunities, and propose changes that reduce complexity and improve performance without compromising functionality.
Multi-system integration scenarios are common in the examination. Candidates may be asked to manage jobs interacting with diverse data sources, including relational databases, flat files, cloud storage, and web services. The examinee must configure connectivity,validate data flows, and troubleshoot errors to ensure accurate and reliable integration. For example, a scenario might describe mismatched schemas between source and target systems, requiring stage adjustments, mapping corrections, and validation procedures.
Exam Preparation Strategies and Practice Insights
Preparing for the IBM C2090-424 certification requires a combination of theoretical knowledge, practical experience, and strategic study planning. InfoSphere DataStage v11.3 is a sophisticated platform, and the examination evaluates a candidate’s mastery of job design, parallel execution, performance tuning, administration, and real-world problem-solving skills. Effective preparation encompasses understanding core concepts, practicing scenario-based questions, and developing confidence in troubleshooting and optimizing complex data integration workflows. The examination emphasizes applied expertise, so candidates must bridge the gap between conceptual understanding and operational execution.
Understanding the architecture of DataStage is foundational for exam readiness. Candidates should familiarize themselves with the layered components, including the metadata repository, parallel execution engine, client interfaces, and project management features. A scenario-based question may describe a job failing due to incorrect environment variables or stage misconfiguration. The examinee must reason through the interaction of architectural components, interpret log messages, and propose corrective actions. Emphasizing architecture comprehension allows candidates to anticipate issues, design resilient workflows, and optimize job performance during the examination.
Practical hands-on experience is critical for reinforcing theoretical knowledge. Candidates are encouraged to construct jobs using various stages, links, and sequences, experimenting with partitioning strategies, transformer derivations, lookups, and aggregations. A scenario might involve a job integrating data from multiple sources and applying complex transformations. By practicing, candidates develop an intuitive understanding of data flow, stage optimization, and parallel execution nuances. Familiarity with job behavior under different loads and configurations enables them to analyze and troubleshoot problems efficiently during the exam.
Parallelism and performance tuning form a significant portion of exam preparation. Candidates should explore partitioning techniques such as hash, range, and round-robin, understanding how these affect workload distribution and prevent data skew. A scenario may present a job with uneven processing times across nodes. The examinee must determine optimal partitioning, adjust buffer sizes, and fine-tune stage configurations to achieve balanced performance. Mastering these concepts ensures candidates can answer questions that require both theoretical knowledge and practical insight into high-volume ETL operations.
Error handling, recovery, and job sequencing are equally important. The examination often includes scenarios where sequences fail due to upstream job errors or unhandled exceptions. Candidates should practice implementing job activity stages, decision stages, and exception handling strategies. For example, a scenario might require configuring a sequence to continue processing valid data despite a failure in one of the jobs. Developing familiarity with these techniques allows examinees to anticipate potential workflow interruptions and design sequences that are resilient and maintain data integrity.
Administration skills are essential for ensuring project consistency, security, and operational efficiency. Candidates should practice managing users, roles, privileges, and environment variables. A scenario might describe a user unable to access certain jobs or stages. The examinee must determine if the issue is due to project-level permissions, role inheritance, or environment misconfiguration. Understanding administrative tasks such as project export/import, version management, and backup restoration helps candidates answer practical questions on ensuring consistency across development, testing, and production environments.
Data lineage, metadata management, and integration with external systems are recurring themes in the exam. Candidates should explore how DataStage tracks data from source to target, including transformations and aggregations. A scenario could involve identifying the impact of a schema change on multiple dependent jobs. The examinee must understand lineage propagation, metadata consistency, and sequence dependencies to maintain data integrity. Practicing these concepts ensures candidates can handle questions involving complex job dependencies, multiple environments, and heterogeneous data sources.
Using scenario-based practice questions enhances problem-solving skills. Candidates may encounter narratives where job failures occur due to subtle misconfigurations or inefficient stage design. For instance, a job processing millions of records may fail intermittently. The examinee must analyze stage settings, partitioning, buffer allocation, and error handling to identify the root cause. Practicing such scenarios helps candidates develop analytical thinking, reinforces their understanding of the platform, and prepares them for the practical challenges presented in the examination.
Time management and strategic study planning are crucial for comprehensive preparation. Candidates should allocate time to review core concepts, practice hands-on exercises, and solve scenario-based questions under simulated exam conditions. Reviewing documentation, official guides, and previous practice questions allows candidates to identify knowledge gaps and focus on areas that require reinforcement. Effective preparation balances conceptual understanding with applied skills, ensuring candidates can approach any scenario with confidence and accuracy.
Candidates should also focus on performance monitoring and tuning exercises. Understanding how to interpret runtime metrics, logs, and system utilization enables them to diagnose bottlenecks and optimize job execution. A scenario may describe a job exhibiting uneven node utilization or excessive memory consumption. The examinee must determine adjustments to partitioning, buffer sizes, or stage configurations. Regularly practicing these exercises hones both analytical and practical skills, ensuring candidates can respond accurately to performance-related scenarios during the examination.
Parameterization and modularization are vital strategies to ensure flexibility and maintainability in job design. Candidates should practice defining parameters for file paths, database connections, thresholds, and other dynamic values. A scenario might require a job to run across multiple environments without manual modifications. Proper parameter usage allows the examinee to answer questions on reusable and adaptable job designs efficiently. Modular design using shared containers and reusable components further ensures consistency and reduces redundancy, enhancing exam preparedness.
Understanding common pitfalls and challenges in real-world data integration projects is also beneficial. Candidates may be presented with scenarios where jobs behave inconsistently due to misaligned environment variables, data skew, or unoptimized stage configurations. Practicing troubleshooting steps, such as reviewing logs, validating data flows, and applying tuning adjustments, prepares candidates to approach these questions methodically. Exposure to real-world-like problems ensures that examinees develop resilience and problem-solving capabilities required by the IBM C2090-424 exam.
Integration with enterprise data systems is another area of focus. Candidates should understand how DataStage connects with relational databases, cloud storage, mainframes, and flat files. A scenario might describe data transformation failures due to mismatched data types or connectivity issues. The examinee must identify appropriate stage configurations, validate connections, and ensure consistent data mapping. Familiarity with integration challenges ensures candidates can respond to complex scenarios involving heterogeneous systems accurately.
Mock examinations and timed practice sessions provide essential rehearsal for exam conditions. Candidates should simulate the examination environment, answer scenario-based questions under time constraints, and review their responses critically. Such practice develops time management skills, reinforces knowledge retention, and identifies areas requiring additional focus. Exposure to multiple types of questions ensures candidates can adapt to unexpected scenarios and approach each problem strategically.
Collaboration and discussion forums can enhance exam preparation. Candidates may benefit from sharing experiences, discussing challenging scenarios, and reviewing alternative approaches to complex job designs. These interactions provide insights into practical solutions, deepen understanding of platform capabilities, and expose candidates to nuanced problem-solving techniques. Engaging with a professional community also builds confidence in approaching scenario-based questions with clarity and precision.
Regular review of official IBM documentation and best practices is critical. Candidates should examine job design guidelines, parallelism strategies, error handling techniques, and administrative controls. A scenario may describe a complex transformation workflow requiring adherence to best practices to maintain performance and accuracy. The examinee must apply these principles effectively, demonstrating both conceptual understanding and practical application. Continuous review ensures candidates remain up-to-date with platform features and understand the rationale behind recommended approaches.
Focusing on job orchestration and workflow optimization is essential. Candidates should practice designing sequences that manage dependencies, handle exceptions, and ensure efficient execution. A scenario might involve a multi-job sequence where downstream processes depend on upstream completion. The examinee must configure triggers, conditional execution, and error handling to maintain workflow integrity. Understanding orchestration principles ensures candidates can design robust sequences capable of handling real-world operational demands.
Troubleshooting and debugging skills are frequently assessed. Candidates may encounter jobs with intermittent failures, unexpected outputs, or performance bottlenecks. The examinee must analyze logs, stage configurations, partitioning, and data flows to identify the root cause. Regular practice with debugging scenarios enhances analytical reasoning, reinforces knowledge of platform intricacies, and builds confidence in problem resolution under examination conditions.
Understanding data quality considerations is another essential aspect. Candidates should practice implementing validation, cleansing, and reconciliation operations within jobs. A scenario may describe inconsistent or incomplete data being loaded into a target system. The examinee must apply error handling, validation stages, and transformation logic to ensure data integrity. Familiarity with these practices ensures candidates can design jobs that meet enterprise standards for accuracy and completeness.
Finally, candidates must integrate all learned strategies into comprehensive preparation. This involves combining architectural understanding, parallelism, performance tuning, administration, error handling, and real-world scenario analysis. Practicing diverse question types, reviewing logs, simulating job failures, and applying corrective measures equips candidates to handle the full spectrum of examination challenges with confidence.
Preparing systematically using these strategies not only reinforces knowledge but also builds the practical skills necessary for success in the IBM C2090-424 examination. Candidates who immerse themselves in hands-on practice, scenario-based problem solving, and administrative oversight gain a competitive advantage, enabling them to approach each question analytically and respond with precision. A holistic approach to preparation ensures mastery of InfoSphere DataStage v11.3 capabilities, enhancing both exam performance and professional competency in real-world data integration environments.
Conclusion
Achieving the IBM C2090-424 certification requires a balance of theoretical knowledge, practical experience, and strategic preparation. Candidates must understand the architecture, stages, links, parallelism, performance tuning, administration, and real-world problem-solving aspects of InfoSphere DataStage v11.3. Scenario-based practice, hands-on exercises, and familiarity with administrative tasks equip candidates to approach the examination with confidence and accuracy. By integrating these preparation strategies, individuals not only succeed in obtaining certification but also acquire the skills necessary to design, optimize, and manage complex enterprise data integration workflows efficiently and reliably. Comprehensive mastery of these areas ensures long-term professional growth and the ability to contribute effectively to data-driven organizational objectives.

