
Exam Code: CCAAK
Exam Name: Confluent Certified Administrator for Apache Kafka
Certification Provider: Confluent
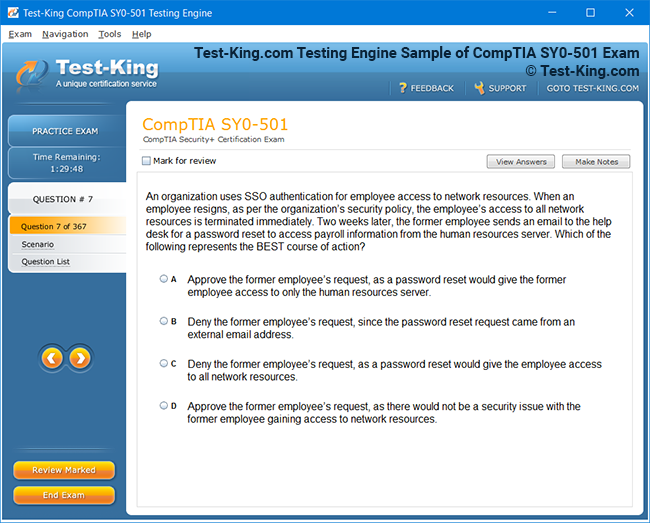
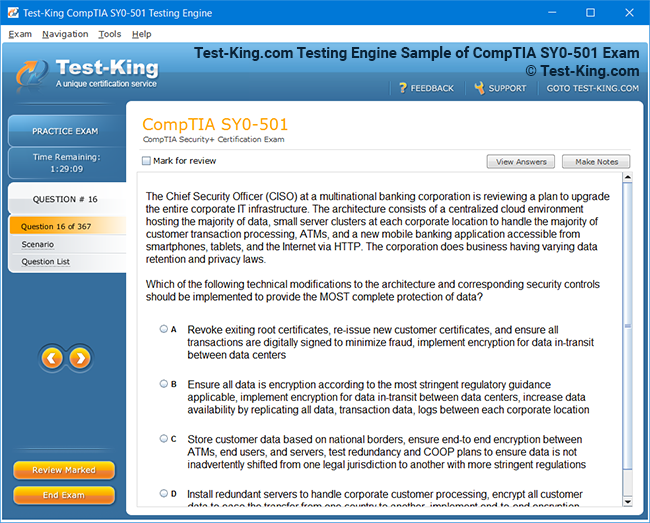
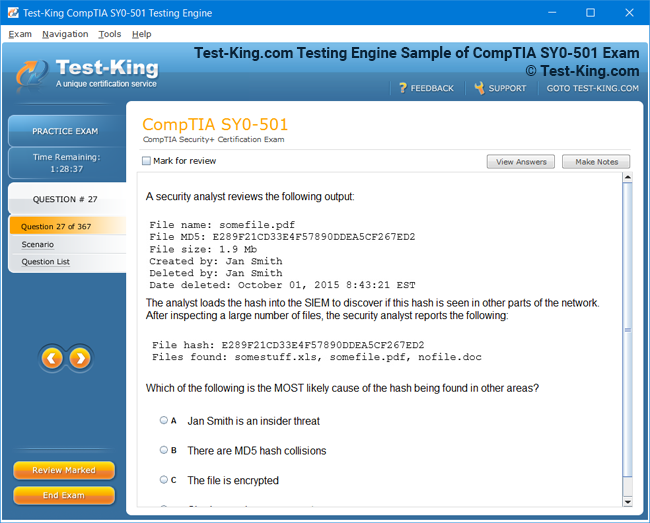
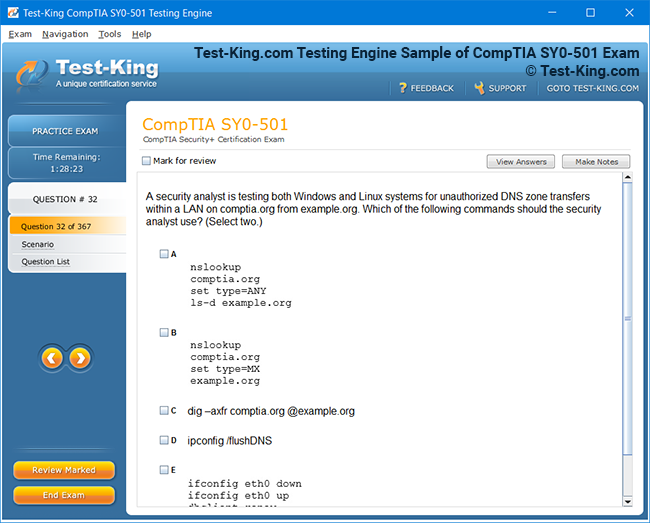
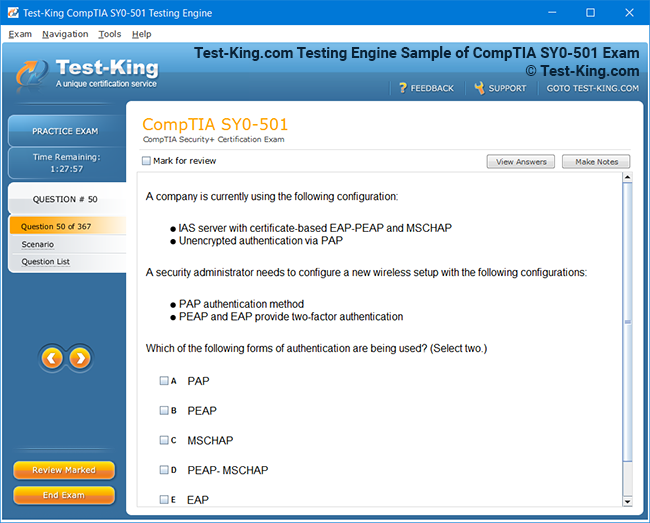
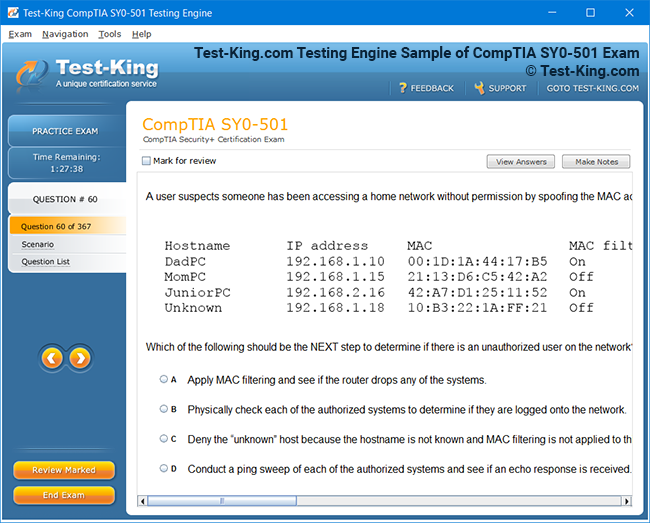
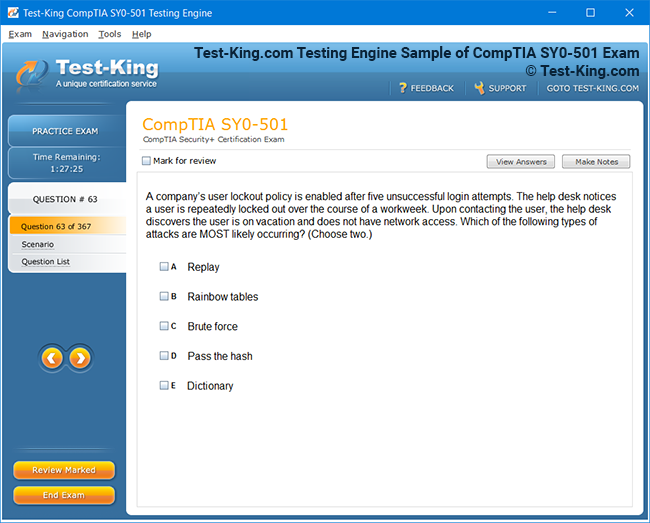
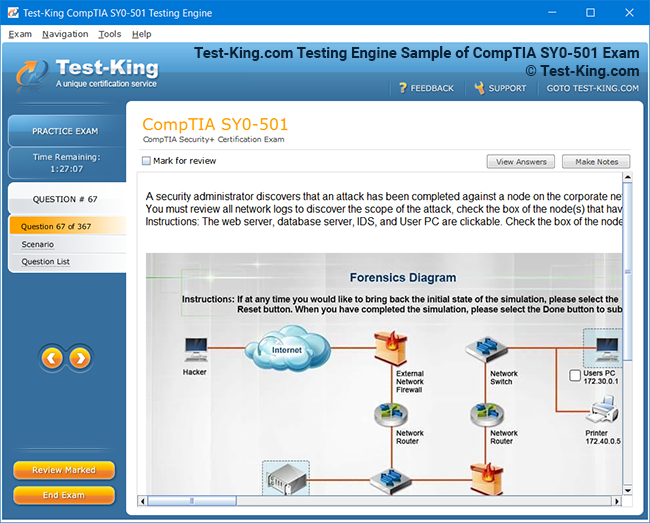
Product Screenshots
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Top Confluent Exams
How to Prepare for the Confluent Certified Developer for Apache Kafka (CCAAK) Exam
The Confluent Certified Developer for Apache Kafka, often abbreviated as CCAAK, represents one of the most recognized qualifications for professionals working with distributed data streaming systems. The examination is designed to assess mastery over the mechanics of Apache Kafka, its wider ecosystem, and the Confluent enhancements that expand its capabilities. For anyone seeking to validate technical proficiency and distinguish themselves in an increasingly competitive market, this certification becomes a compelling milestone. Yet beyond prestige, it is also a measure of the candidate’s ability to translate complex ideas into reliable implementations, and to demonstrate dexterity with concepts that range from the fundamentals of brokers to the intricate orchestration of stream processing.
The exam is composed of fifty-five multiple-choice questions and must be completed within ninety minutes. Each question probes knowledge across Kafka’s architecture, its operational behaviors, and the Confluent tools that integrate with it. Although the breadth is considerable, the assessment is carefully structured so that it reflects real-world usage scenarios rather than contrived theoretical exercises. The credential is valid for two years, after which renewal is necessary to ensure familiarity with evolving versions of the platform. Another essential detail is that the test does not require travel to an official center, since it can be taken directly from a personal computer with proper monitoring, making it accessible to candidates across regions. These practicalities matter, but the deeper concern for anyone embarking on the preparation journey is to know precisely where to focus attention and how to cultivate a resilient understanding of the required domains.
Understanding the Nature of the Certification
Preparation for the CCAAK examination is best understood as a process of layering knowledge. One begins with the absolute foundations, moves gradually through applied concepts, and ultimately arrives at an appreciation for the auxiliary components that Confluent introduces. For many, the journey may feel formidable, since Apache Kafka itself is not a trivial system. It thrives on distributed complexity, partitioning data streams, ensuring durability through replication, and demanding thoughtful configuration. The aspirant is not expected to be an encyclopedic authority on every command or configuration file, but there is a strong emphasis on conceptual mastery and the ability to discern correct patterns from misleading alternatives presented in the questions.
A recurring theme throughout preparation is the Kafka broker, the heartbeat of the cluster, where data flows incessantly through topics and partitions. An in-depth comprehension of how producers interact with brokers, how offsets maintain the consumer’s position in a stream, and how groups coordinate their reading responsibilities is not merely academic. These details form the backbone of many exam queries. They also underpin the real scenarios where an engineer might need to balance throughput against fault tolerance or guarantee message delivery semantics without inducing unnecessary latency. Such matters often sound deceptively simple but conceal profound intricacies when viewed through the prism of distributed computing.
Equally critical is the awareness of how Kafka Connect functions, for it is one of the pivotal tools that bridges external systems with the Kafka core. Understanding the role of workers and the distinctions between source and sink connectors becomes indispensable. A worker manages the lifecycle of connectors and tasks, while the connectors themselves embody the logic that ingests or exports data. A connector must transform and sometimes convert data formats, thereby emphasizing knowledge of converters. While it may sound peripheral, this component is a central part of the CCAAK assessment because it tests the candidate’s ability to envision how Kafka is integrated into larger ecosystems where databases, filesystems, or cloud services coexist.
Once the groundwork is established, the focus inevitably shifts toward Kafka Streams, which introduces a higher plane of abstraction. This library empowers developers to build stream-processing applications directly within Kafka, allowing real-time transformation, enrichment, and aggregation of data. For the exam, a candidate is expected to be comfortable with reading stream topologies, interpreting them in terms of directed acyclic graphs, and differentiating between stateless operations such as filters and stateful operations such as joins or aggregations. These tasks demand more than rote memorization; they require a lucid mental model of data continuously flowing through computational steps, punctuated by transformations and materialized states. If an individual has not yet encountered these operations, the learning curve can feel steep, but once mastered, the insight they provide into modern data architectures is profound.
No preparation would be complete without a discussion of Confluent’s unique components, since the certification derives its name from Confluent itself. Chief among these is the Schema Registry, which enforces consistency and compatibility of data structures across evolving pipelines. It typically works with Avro serialization, and thus the candidate should be conversant in how schemas are defined, versioned, and validated. The Confluent REST Proxy also makes an appearance, allowing interaction with Kafka through standard HTTP requests rather than relying exclusively on native clients. Its purpose is not only convenience but also interoperability, enabling systems with limited client support to participate in Kafka ecosystems. Another component, KSQL, resembles SQL in its syntax but operates over streaming data, permitting declarative queries to filter, join, and aggregate streams. Encountering KSQL for the first time may surprise learners with its familiarity, yet the challenge lies in appreciating the subtle distinctions between querying a static database and continuously querying an evolving stream. Reading a few canonical examples, often called recipes, proves invaluable in building this instinct.
Kafka setup itself can be a surprising domain of examination. Many assume that conceptual knowledge is sufficient, but in reality, the exam expects awareness of how a cluster is configured. Questions may involve heap sizing, selection of replication factors, or best practices for partition assignment. Such concerns reveal the practical side of Kafka, where performance and stability hinge on thoughtful choices. One may need to recall that too small a heap can lead to garbage collection storms, while excessive sizing introduces inefficiency. Thus, a nuanced understanding of these operational considerations can mean the difference between a correct and an incorrect answer in the exam.
Though not emphasized with equal weight, Kafka security and monitoring are still present. Even a cursory understanding of encryption, authentication, and authorization mechanisms is valuable. It helps to know how SSL, SASL, and ACLs contribute to a secure ecosystem. Monitoring, on the other hand, involves recognizing the indicators that reflect cluster health, such as lag in consumer groups or throughput rates across topics. While these topics may not dominate the exam blueprint, neglecting them entirely would be unwise. Even in real-world practice, they form the bedrock of a dependable Kafka deployment.
Beyond the content areas, preparation is also about discipline and strategy. Practice tests can provide immense benefit, not only by familiarizing the candidate with the style of questioning but also by identifying weak spots in knowledge. Taking such tests simulates the timing constraints and cultivates composure under exam pressure. When the first attempt at a practice assessment reveals gaps, it should be seen not as discouragement but as a roadmap for refinement. Many aspirants find that repeated exposure to mock questions sharpens their instincts and enables them to quickly eliminate distractors in the real exam.
Equally significant is the choice of study resources. The wealth of online courses, videos, and documentation can be overwhelming, but curating a balanced mix of theoretical reading and hands-on experimentation proves most fruitful. Kafka is inherently experiential; configuring a small cluster, producing and consuming messages, and experimenting with connectors engrains knowledge in a way that reading alone cannot. This kinesthetic style of learning reinforces memory through action and provides the mental images that help answer scenario-based questions later.
Time management plays a silent yet decisive role in preparation. Kafka encompasses a labyrinth of details, and without a structured schedule, it is easy to get lost in peripheral topics. Allocating time across fundamentals, connectors, streams, Confluent components, setup, and peripheral domains ensures balanced coverage. Some individuals spend disproportionate time on one domain they find interesting, neglecting others, only to find the neglected domains appear more frequently on the exam. A deliberate approach, informed by the official exam guide, prevents this imbalance and ensures readiness.
Another subtle yet potent element in preparation is community. While studying is often solitary, engaging with forums, discussion boards, and peer groups can reveal insights that solitary reading cannot. Explaining a Kafka concept to another person forces clarity of thought, often exposing gaps that were invisible when reading silently. Moreover, the shared experiences of those who have already attempted the certification can shed light on common pitfalls, frequently misunderstood concepts, and the types of scenarios that are recurrent in the questions. This communal aspect, though intangible, contributes significantly to confidence and preparedness.
As the exam date approaches, the focus shifts from expansion to consolidation. Rather than chasing entirely new domains, it is more productive to revisit notes, reattempt practice tests, and reinforce memory of core principles. Kafka is a domain where the fundamentals resurface repeatedly, in clusters of questions that test variations of the same concepts. Revisiting producers, consumers, partitions, offsets, and delivery semantics ensures that no matter how a question is phrased, the underlying knowledge remains solid. By the time the exam screen loads, the well-prepared candidate should feel a quiet familiarity with nearly every theme presented.
Deep Dive into Kafka Fundamentals and Integration
Preparing for the Confluent Certified Developer for Apache Kafka exam demands not only familiarity with Kafka's operational aspects but also a profound understanding of its theoretical underpinnings and integration with the Confluent ecosystem. The journey toward mastery begins with brokers, the linchpins of Kafka’s architecture. Brokers serve as intermediaries between producers and consumers, ensuring that messages are durably stored and efficiently routed across partitions. Each topic is divided into partitions, which enable parallel processing and scalability, and each partition maintains an offset that records the consumer’s position. Grasping the interplay between producers, which append messages to topics, and consumers, which retrieve these messages, is essential, as it directly influences delivery semantics. These semantics, whether at-most-once, at-least-once, or exactly-once, dictate the reliability and consistency of message processing, and understanding them is crucial for answering many of the exam questions.
Beyond the fundamentals, consumer groups introduce the concept of coordinated consumption. Multiple consumers in a group share the workload of reading from partitions, allowing for horizontal scalability while preserving the order of messages within a partition. This coordination relies on an intricate protocol that ensures no duplication or omission of data in typical operational scenarios. Knowledge of how partitions are assigned, how rebalancing occurs when consumers join or leave, and how lag is monitored can provide an aspirant with the edge needed for both theoretical and practical questions in the exam.
Kafka Connect represents the bridge between external data systems and Kafka, enabling seamless ingestion and export of information. Workers in Kafka Connect manage the lifecycle of connectors and tasks, overseeing fault tolerance and load distribution. Source connectors pull data into Kafka from databases, applications, or filesystems, while sink connectors push data from Kafka to downstream systems. Converters play a pivotal role in data translation, transforming records between internal Kafka formats and external representations. Understanding these concepts is critical because the exam often presents scenarios where the candidate must determine the most efficient and reliable integration approach.
Kafka Streams elevates data handling from the transportation of messages to active transformation and aggregation. This library enables the construction of real-time applications that process streams as they flow, performing operations that range from simple filtering to complex joins and aggregations. Stateless operations, such as mapping or filtering, do not maintain internal state and are comparatively straightforward. Stateful operations, in contrast, require storage of intermediate results and can involve windowing or aggregation, necessitating comprehension of how state stores work and how they interact with the stream topology. Candidates benefit from visualizing the topology as a directed graph, where nodes represent processing steps and edges represent the flow of data, as this conceptual model often clarifies the behavior of complex operations.
The Confluent ecosystem introduces additional tools that extend Kafka’s capabilities, which are integral to the exam. The Schema Registry maintains and enforces consistency of data formats, ensuring compatibility across evolving pipelines. Avro, the most common serialization format used with the registry, demands understanding of schemas, versioning, and compatibility rules. Misalignment in schema evolution can result in serialization errors, a scenario that the exam may subtly test through problem-based questions. The REST Proxy facilitates interactions with Kafka over HTTP, broadening access to environments where native Kafka clients are impractical. Understanding the mechanics of this proxy, its request-response patterns, and its limitations is useful not only for the exam but also for real-world deployments where inter-system communication is required. KSQL allows for declarative queries over streams, resembling SQL but designed for dynamic data. Knowledge of KSQL syntax, stream processing logic, and the distinction between persistent queries and transient ones can provide clarity for questions that simulate practical data manipulation tasks.
Kafka setup is another domain that often surprises candidates with its practical considerations. Heap sizing, partition replication, and cluster configuration can significantly affect performance and stability. An awareness of how JVM memory management impacts broker operation, how replication factor influences durability, and how partition count affects throughput is essential. These considerations require aspirants to balance theoretical knowledge with pragmatic operational reasoning, and the exam may challenge them to identify optimal configurations or predict the behavior of clusters under certain workloads.
Even though security and monitoring are not heavily weighted in the exam, a foundational understanding enhances preparedness. Kafka security involves authentication mechanisms such as SASL, encryption through SSL, and authorization via access control lists. These features ensure that sensitive data remains protected while maintaining accessibility for authorized users. Monitoring, on the other hand, entails observing consumer lag, message throughput, and broker health, allowing engineers to detect anomalies before they escalate into system failures. While candidates may not need to implement these measures in depth, recognizing their principles and implications can inform scenario-based questions.
Effective preparation also requires an intentional study methodology. Extensive reading of official documentation, combined with practical experimentation, cements understanding. Setting up local clusters, producing and consuming messages, and simulating failure scenarios reinforces knowledge through experiential learning. Practice exams serve a dual purpose: they accustom candidates to the format and timing of questions while highlighting areas that need reinforcement. Repeatedly attempting these assessments builds confidence, identifies recurring knowledge gaps, and sharpens problem-solving instincts.
Time management plays a subtle yet crucial role. Allocating study hours strategically ensures comprehensive coverage across fundamentals, streams, connectors, Confluent tools, setup, and peripheral topics. Overemphasis on a single domain can create vulnerabilities in the breadth required for success. A disciplined schedule, guided by the official exam outline, maximizes efficiency and maintains balance in preparation.
Engaging with the broader Kafka community can provide additional insights. Discussion forums, professional groups, and peer collaboration enable aspirants to encounter diverse perspectives, clarify misconceptions, and exchange practical advice. Articulating complex concepts to others reinforces understanding, often revealing subtle nuances that may otherwise go unnoticed. This communal engagement, though informal, becomes a valuable supplement to structured study.
Mastery of Kafka requires more than theoretical knowledge; it involves cultivating an intuition for how messages traverse clusters, how data transformations propagate, and how systems respond under load. Visualization and mental rehearsal of these processes are powerful tools. When confronted with questions that test reasoning rather than memorization, a candidate with this mental model can navigate ambiguities with confidence, discerning the correct approach amid plausible but incorrect alternatives.
The examination itself challenges both comprehension and application. Questions may present hypothetical system configurations, error scenarios, or performance constraints. Success depends on recognizing underlying principles rather than relying solely on memorized facts. The aspirant who has integrated practical experience with conceptual understanding is better equipped to evaluate trade-offs, select optimal solutions, and predict system behavior under varied conditions.
Kafka Streams, Kafka Connect, and Confluent components frequently intersect in practical scenarios. For instance, a stream processing application may consume data from a Kafka topic ingested via a source connector, apply transformations through Kafka Streams, and finally output the results to an external datastore through a sink connector. Candidates who can mentally trace such workflows, understand the responsibilities of each component, and anticipate the implications of configuration choices, demonstrate a depth of understanding that the exam often rewards.
Attention to detail is indispensable. Small distinctions in terminology, subtle differences in delivery semantics, or nuances in configuration parameters can distinguish a correct answer from an incorrect one. For example, understanding exactly how consumer group rebalancing affects offset management, or how schema evolution rules prevent compatibility violations, can make the difference in scenario-based questions. Memorization alone is insufficient; it is the synthesis of principles, experience, and analytic reasoning that produces mastery.
A final dimension involves continuous reflection on progress. Reviewing incorrect answers from practice exams, analyzing why certain decisions were wrong, and integrating corrective strategies into subsequent study sessions consolidates learning. This iterative process transforms weaknesses into strengths and ensures that knowledge becomes not only recallable but also applicable. Through repeated cycles of practice, reflection, and adjustment, aspirants develop the resilience and clarity required for success on the CCAAK exam.
Enhancing Knowledge of Kafka Architecture and Confluent Ecosystem
Achieving proficiency for the Confluent Certified Developer for Apache Kafka examination requires a thorough engagement with the intricate architecture of Kafka and the extended functionalities offered by the Confluent ecosystem. The Kafka cluster is fundamentally composed of brokers, each responsible for maintaining partitions of topics, ensuring data durability, and managing client interactions. Understanding how brokers coordinate, replicate data, and maintain consistency across a distributed system is central to grasping the operational integrity of Kafka. The flow of messages from producers to consumers traverses these brokers, guided by partitioning schemes and offset management, and candidates must visualize the choreography of these elements to handle scenario-based questions effectively. Delivery semantics, which delineate the guarantees of message transmission, form another essential layer of understanding. At-most-once, at-least-once, and exactly-once semantics each carry implications for data reliability and system design, and familiarity with these guarantees is indispensable for both the exam and practical implementations.
Consumer groups constitute a pivotal aspect of Kafka’s scalability and resilience. By distributing consumption across multiple consumers within a group, Kafka allows for parallel data processing while maintaining order within individual partitions. The process of partition assignment, rebalancing, and lag monitoring is complex yet foundational for anyone aiming to demonstrate a comprehensive understanding of Kafka’s mechanics. These dynamics are frequently explored in the examination through scenarios that require evaluative reasoning rather than straightforward recall, challenging candidates to predict system behavior under varying workloads and configurations.
Kafka Connect provides an essential bridge for integrating external data systems with Kafka’s robust streaming infrastructure. Workers in Kafka Connect oversee connectors and manage fault tolerance, ensuring that source and sink connectors reliably ingest or export data. Converters facilitate the translation between Kafka’s internal format and external data structures, which is crucial for maintaining data integrity across heterogeneous environments. The exam often tests candidates’ ability to discern optimal approaches for data integration, demanding both conceptual understanding and practical intuition. Recognizing how connectors operate, the challenges of schema evolution, and the mechanisms for error handling is key to navigating this domain.
Kafka Streams introduces a higher level of abstraction by enabling the creation of stream processing applications. These applications perform transformations, aggregations, and enrichments on data as it flows through Kafka topics. Candidates must be adept at interpreting stream topologies, which can be conceptualized as directed acyclic graphs representing the sequence of processing steps. Stateless operations, such as filtering and mapping, do not retain intermediate state, whereas stateful operations, such as joins and aggregations, require the maintenance of state stores and careful consideration of windowing strategies. Proficiency in Kafka Streams involves understanding how these operations interact with partitions, the implications for performance, and the strategies for ensuring fault tolerance. Scenario-based questions often challenge candidates to identify correct topologies or predict the outcomes of stream transformations, emphasizing the importance of an experiential grasp of streaming logic.
The Confluent ecosystem extends Kafka’s capabilities with components that ensure data consistency, accessibility, and usability. The Schema Registry is integral for managing schemas and maintaining compatibility across evolving pipelines. Avro serialization, commonly used with the registry, enforces strict adherence to defined data formats, requiring candidates to understand schema versioning, compatibility rules, and the consequences of schema violations. The REST Proxy provides HTTP-based access to Kafka, broadening the reach of Kafka clients and facilitating integration with environments where native clients are impractical. KSQL, designed for declarative queries over streaming data, allows for real-time filtering, aggregation, and transformation using a SQL-like syntax. Candidates must appreciate the distinctions between static queries in traditional databases and continuous queries in streaming contexts, as well as the nuances of persistent versus transient queries. Exam questions may simulate practical workflows, testing candidates’ ability to orchestrate these components effectively.
Kafka setup and configuration are often explored in unexpected ways within the examination. Heap sizing, replication factors, and cluster tuning can significantly affect performance and reliability. Awareness of how JVM memory impacts broker operation, how replication ensures durability, and how partition distribution influences throughput is essential. Candidates are expected to demonstrate a capacity for balancing theoretical understanding with practical reasoning, predicting system behavior under various configurations, and identifying potential bottlenecks or points of failure. These considerations reinforce the interconnectedness of Kafka’s architecture and operational best practices.
While security and monitoring may not dominate the examination blueprint, they remain important adjuncts to a candidate’s preparedness. Kafka security mechanisms, including authentication through SASL, encryption via SSL, and authorization through ACLs, protect sensitive data while ensuring legitimate access. Monitoring encompasses tracking consumer lag, message throughput, and broker health, enabling proactive intervention in the event of anomalies. Even a foundational grasp of these areas can enhance candidates’ comprehension of Kafka’s operational ecosystem and inform decisions in scenario-driven questions.
Preparation strategies extend beyond content mastery into disciplined study habits and experiential engagement. Engaging with practice exams familiarizes candidates with the style and structure of questions while highlighting knowledge gaps. Iterative exposure to practice questions encourages reflection and consolidation of understanding. Setting up test clusters, producing and consuming messages, and experimenting with connectors cultivates experiential knowledge, transforming abstract concepts into tangible skills. This hands-on approach is invaluable, as Kafka’s operational subtleties often resist purely theoretical study.
Effective time management ensures balanced coverage across all relevant domains. Allocating dedicated study intervals to core topics such as brokers, consumer groups, Kafka Connect, Kafka Streams, Confluent components, setup, and peripheral knowledge prevents overemphasis on familiar areas and neglect of less intuitive concepts. Structuring preparation according to the official examination outline ensures comprehensive readiness and mitigates the risk of encountering unexpected material during the test.
Community engagement provides an additional dimension of preparation. Interaction with forums, professional groups, and peers offers insights into nuanced topics and frequently misunderstood concepts. Articulating ideas to others consolidates understanding and fosters the ability to think critically about Kafka’s behavior and architecture. Observing and discussing real-world use cases enriches knowledge beyond what is found in formal study resources, cultivating intuition that is particularly beneficial when responding to scenario-based questions.
Visualization and mental modeling are powerful tools in mastering Kafka. Candidates benefit from constructing mental representations of message flows, stream topologies, and connector integrations, which allow them to anticipate outcomes and troubleshoot hypothetical scenarios. Understanding how data traverses brokers, partitions, and consumer groups, and how Kafka Streams processes stateful and stateless operations, builds a cognitive framework that enables rapid and accurate reasoning under exam conditions.
Advanced proficiency involves recognizing the interplay between Kafka Streams, Kafka Connect, and Confluent components. In practical applications, a data pipeline may ingest information through a source connector, process it using Kafka Streams transformations, and output results via a sink connector or KSQL query. Candidates who can mentally simulate these end-to-end flows, foresee potential failure points, and understand the configuration nuances of each component exhibit the level of comprehension that the examination is designed to measure.
Attention to detail is essential for success. Subtle distinctions in terminology, minor differences in configuration parameters, and nuanced behaviors of components can separate correct responses from incorrect ones. Candidates must internalize delivery semantics, schema compatibility rules, consumer group dynamics, and stream processing behavior to navigate complex questions effectively. Memorization alone is insufficient; mastery emerges from integrating practical experience with conceptual understanding, allowing candidates to apply principles flexibly in a variety of scenarios.
Reflection on practice performance consolidates knowledge and reinforces readiness. Reviewing incorrect answers, analyzing errors, and adapting strategies promotes iterative learning. This continuous refinement transforms weaknesses into strengths, ensuring that knowledge is both retained and applicable. Candidates who engage in this reflective practice develop resilience, confidence, and the analytical acuity necessary to excel in the examination environment.
Hands-on experimentation and mental rehearsal complement study materials. Setting up clusters, manipulating topics and partitions, creating connectors, and running stream applications cultivate a tacit understanding that is difficult to acquire through reading alone. Mental rehearsal of data flows and processing logic strengthens intuition, enabling candidates to anticipate outcomes and troubleshoot conceptual problems effectively. This combination of practical engagement and cognitive modeling forms the cornerstone of advanced preparation, bridging the gap between knowledge acquisition and applied competence.
Mastering Kafka Operations, Streams, and Confluent Integrations
The journey toward excelling in the Confluent Certified Developer for Apache Kafka examination necessitates a profound engagement with both Kafka’s internal operations and the extended ecosystem of Confluent tools that enhance its functionality. Kafka’s architecture revolves around brokers that orchestrate the flow of messages, maintain partitions, and ensure durability across distributed clusters. Each topic is subdivided into partitions, allowing parallelism and fault tolerance, while offsets track consumer progress within those partitions. Understanding the mechanics of message production and consumption, alongside delivery semantics that dictate whether messages are delivered at-most-once, at-least-once, or exactly-once, forms the foundation for interpreting complex scenarios within the exam. Candidates are expected to visualize the intricate choreography of brokers, producers, and consumers, as questions frequently test the ability to predict the behavior of systems under varying operational conditions.
Consumer groups add another dimension of sophistication to Kafka’s ecosystem. They allow multiple consumers to share the workload of reading partitions while preserving message order within each partition. The process of rebalancing when consumers join or leave, partition assignment strategies, and lag monitoring are essential topics. These dynamics are often presented in scenario-based questions where reasoning about system behavior under load is more important than rote memorization. Candidates benefit from mentally simulating the flow of messages and the interactions between brokers and consumers, as this kind of conceptual modeling strengthens the ability to answer nuanced queries.
Kafka Connect functions as a bridge between Kafka and external systems, enabling the ingestion and export of data. Workers orchestrate the execution of connectors, manage tasks, and provide fault tolerance. Source connectors facilitate the import of data into Kafka from databases, filesystems, or applications, whereas sink connectors export processed data to downstream systems. Converters are crucial in translating between Kafka’s internal serialization and the external formats required by connected systems. Understanding these components is essential for evaluating data integration workflows in practical contexts, as examination questions may challenge candidates to select the most effective configuration for specific scenarios.
Kafka Streams further elevates the ability to process data in real time. This library allows developers to build applications that perform transformations, aggregations, and enrichments on streaming data. Stateless operations, such as mapping or filtering, do not retain intermediate state, while stateful operations, including joins and aggregations, require maintaining state stores and using windowing strategies. Candidates should develop the capability to interpret stream topologies, envisioning them as directed graphs where each node represents a transformation and edges represent data flow. This mental modeling aids in understanding the implications of operations on throughput, latency, and fault tolerance, all of which are critical to correctly responding to scenario-driven questions.
The Confluent ecosystem introduces components that amplify Kafka’s capabilities, and mastery of these tools is pivotal. The Schema Registry enforces data consistency by managing schema definitions and ensuring backward or forward compatibility as schemas evolve. Avro is commonly used for serialization, and candidates must understand the consequences of schema evolution and incompatibility. The REST Proxy enables HTTP-based access to Kafka, facilitating integration with systems that cannot use native Kafka clients. KSQL provides a SQL-like interface for continuous queries over streams, allowing real-time aggregation, filtering, and joining of data. It is important to distinguish between persistent queries, which continuously update results, and transient queries, which execute once. Familiarity with common KSQL patterns and recipes enhances the ability to solve practical questions efficiently.
Kafka setup and operational considerations are often underestimated but remain essential for exam readiness. Heap sizing, partition replication, and cluster configuration affect system performance and reliability. Candidates must recognize how JVM memory allocation impacts brokers, how replication factors ensure durability, and how partition distribution influences throughput. These details often appear in questions that require predictive reasoning rather than mere recall. An understanding of operational best practices, such as balancing memory usage with throughput requirements or mitigating the risk of uneven partition distribution, strengthens the candidate’s ability to evaluate practical scenarios.
Security and monitoring, though not heavily emphasized in the exam, are essential adjuncts to preparation. Kafka employs authentication mechanisms like SASL, encryption through SSL, and authorization using ACLs to secure sensitive data while maintaining accessibility for authorized clients. Monitoring involves observing metrics such as consumer lag, broker throughput, and partition health, enabling preemptive intervention in the case of anomalies. Even foundational knowledge of these domains can inform answers to questions about best practices, failure scenarios, and system design considerations.
Effective preparation extends beyond knowledge acquisition to disciplined study methodology and hands-on experience. Practicing with mock exams exposes candidates to the question format and highlights areas requiring further attention. Iterative practice, reflection on incorrect answers, and targeted review reinforce understanding. Setting up local clusters, experimenting with topic creation, simulating data flow, and observing behavior under load cultivate experiential knowledge that complements theoretical study. This hands-on engagement is crucial because Kafka’s distributed systems contain subtleties that are difficult to grasp through reading alone.
Time management remains a vital strategy. Allocating study hours to core topics such as brokers, consumer groups, Kafka Connect, Kafka Streams, Confluent tools, configuration, and peripheral topics ensures balanced coverage. Overemphasis on familiar domains may result in neglect of less intuitive areas, which could appear unexpectedly in the exam. A structured approach informed by the official exam guide maximizes efficiency and mitigates the risk of encountering surprises.
Community engagement enhances preparation by offering insights that are often absent from official materials. Discussion forums, professional groups, and peer networks allow candidates to explore practical applications, clarify misunderstandings, and exchange problem-solving strategies. Articulating concepts to others reinforces understanding and sharpens analytical skills, preparing candidates to reason effectively when confronted with complex scenario-based questions. Real-world examples, shared through community interactions, provide context that enriches knowledge beyond formal documentation.
Visualization and cognitive modeling are essential for deep mastery. Mentally tracing message flows, simulating stream processing, and projecting the interaction between connectors, brokers, and consumers enables a candidate to anticipate system behavior and troubleshoot potential challenges. Understanding how Kafka Streams operations propagate through state stores, how Kafka Connect handles failures, and how schema compatibility impacts data integrity cultivates a cognitive framework that facilitates rapid and accurate reasoning during the examination.
Advanced readiness requires an appreciation of the integration between Kafka Streams, Kafka Connect, and Confluent components. A complete data pipeline may involve ingesting data through a source connector, processing it using Kafka Streams transformations, storing or querying results via KSQL, and exporting the output through a sink connector. Candidates capable of mentally simulating these workflows, predicting potential failure points, and reasoning about configuration implications demonstrate the depth of comprehension the exam evaluates. Scenario-based questions often mirror these real-world interactions, emphasizing applied understanding over memorization.
Attention to detail is crucial. Minor distinctions in terminology, subtle differences in configuration options, and nuanced behaviors of system components can determine whether a candidate selects the correct answer. Mastery involves understanding delivery semantics, schema evolution rules, consumer group coordination, and stream processing logic to navigate multi-layered scenarios. This integration of conceptual knowledge with practical intuition is central to achieving a high level of competence.
Reflection and iterative learning consolidate preparation. Reviewing mistakes from practice exams, analyzing why certain answers were incorrect, and adjusting strategies strengthens retention and application of knowledge. This continuous refinement transforms weaknesses into strengths and equips candidates to handle complex or unfamiliar questions confidently. Repeated cycles of practice, reflection, and adjustment cultivate resilience and analytical acuity, both of which are indispensable for success on the Confluent Certified Developer for Apache Kafka examination.
Hands-on experimentation complements cognitive modeling and study materials. Configuring clusters, manipulating topics and partitions, deploying connectors, and running stream processing applications provide experiential learning that embeds Kafka concepts into memory. Mental rehearsal of data flows and operational dynamics strengthens intuition, allowing candidates to anticipate outcomes and resolve hypothetical problems effectively. This combination of practical experience and conceptual clarity underpins advanced preparedness, enabling candidates to navigate both technical and scenario-based questions with confidence.
Comprehensive Insights into Kafka, Streams, and Confluent Ecosystem
Achieving mastery for the Confluent Certified Developer for Apache Kafka examination requires an exhaustive engagement with the complexities of Kafka’s architecture, its stream processing capabilities, and the extended functionality provided by Confluent’s ecosystem. At the core of Kafka is the broker, an indispensable component that coordinates data flow, manages partitions, and ensures that messages are durably stored across distributed clusters. Each topic is partitioned to allow parallelism, fault tolerance, and high throughput, while offsets track the precise position of consumers within each partition. Understanding how producers deliver messages to topics, how consumers retrieve them, and the implications of delivery semantics, whether at-most-once, at-least-once, or exactly-once, is vital for interpreting and responding to scenario-based questions in the examination.
Consumer groups are central to Kafka’s scalability, allowing multiple consumers to read from partitions collectively while maintaining the order of messages. The mechanics of partition assignment, rebalancing when consumers join or leave, and monitoring lag are critical topics. Candidates must mentally simulate the flow of data within consumer groups and anticipate the effects of cluster changes, as many questions probe practical reasoning rather than simple recall. This understanding is crucial for designing systems that are resilient, efficient, and capable of handling dynamic workloads.
Kafka Connect enables seamless integration between Kafka and external data systems. Workers orchestrate the execution of connectors, oversee fault tolerance, and manage task assignments. Source connectors ingest data from external systems into Kafka, while sink connectors export processed information to downstream applications or databases. Converters translate data between Kafka’s internal formats and the external structures required by connected systems. The exam often tests candidates’ ability to discern optimal strategies for data integration and error handling, emphasizing the necessity of a conceptual and practical understanding of these components.
Kafka Streams elevates processing capabilities by allowing real-time transformations, aggregations, and enrichments of streaming data. Stateless operations, such as mapping or filtering, do not retain intermediate state, whereas stateful operations, including joins and aggregations, rely on state stores and windowing techniques. A candidate must be capable of interpreting stream topologies, visualizing them as directed graphs in which nodes represent transformations and edges denote data flow. This cognitive modeling aids in understanding operational consequences on latency, throughput, and fault tolerance, all of which are tested in scenario-driven questions.
The Confluent ecosystem adds a further dimension of sophistication. The Schema Registry ensures data consistency across evolving pipelines, managing schema definitions and enforcing compatibility rules. Avro serialization, widely used in conjunction with the registry, requires candidates to understand schema versioning and the implications of schema evolution. The REST Proxy allows systems that cannot utilize native Kafka clients to interact with Kafka using HTTP requests, expanding accessibility. KSQL provides a SQL-like interface for continuous queries over streams, enabling real-time filtering, aggregation, and joining of data. Distinguishing between persistent and transient queries, and understanding the implications of query results for downstream systems, is essential for solving practical scenarios in the examination.
Kafka setup and operational considerations, while sometimes underestimated, remain essential. Heap sizing, partition replication, and cluster configuration have a profound effect on performance and stability. Candidates should be familiar with how JVM memory allocation impacts brokers, how replication ensures durability, and how partition distribution influences throughput and fault tolerance. Scenario-based questions frequently explore these topics, challenging candidates to reason about system behavior under various operational constraints. Recognizing the subtleties of these configurations strengthens the ability to evaluate and resolve real-world problems.
Security and monitoring are integral adjuncts to preparation, despite being lightly emphasized in the exam blueprint. Kafka provides authentication through SASL, encryption via SSL, and authorization using ACLs to secure data while ensuring legitimate access. Monitoring involves observing metrics such as consumer lag, broker throughput, and partition health to preempt potential failures. Even a fundamental understanding of these aspects informs reasoning in questions about operational best practices, anomaly detection, and system resilience.
Effective preparation encompasses disciplined study strategies and hands-on engagement. Practice exams familiarize candidates with question structure and highlight knowledge gaps, while iterative review of incorrect answers strengthens retention. Deploying local clusters, creating topics, experimenting with stream applications, and testing connectors provide experiential learning that complements theoretical study. This combination of reading, experimentation, and reflection builds a deep, intuitive understanding of Kafka and the Confluent ecosystem, enabling candidates to navigate complex and scenario-driven questions confidently.
Time management plays a pivotal role in preparation. Candidates should allocate study intervals strategically to cover core topics such as brokers, consumer groups, Kafka Connect, Kafka Streams, Confluent components, cluster configuration, and peripheral knowledge. Focusing disproportionately on one domain at the expense of others can leave gaps that are tested in the examination. A disciplined schedule, informed by the official exam outline, ensures balanced coverage and maximizes the efficiency of preparation efforts.
Engagement with the Kafka community provides invaluable support for advanced preparation. Discussion forums, professional groups, and peer interactions expose candidates to diverse perspectives, practical solutions, and recurring pitfalls. Articulating complex concepts to others consolidates understanding, encourages critical thinking, and builds the ability to reason under pressure. Real-world examples shared within these communities provide context that enhances comprehension beyond what can be gleaned from formal study resources alone.
Visualization and cognitive modeling are essential for mastering Kafka’s intricacies. Mentally tracing message flows through brokers, partitions, consumer groups, and connectors enables candidates to anticipate system behavior and troubleshoot potential issues. Understanding how Kafka Streams operations interact with state stores, how connectors handle data transformation and failures, and how schema evolution impacts compatibility develops an internal framework that supports rapid reasoning during the exam. Candidates who cultivate these mental models are better equipped to analyze scenarios, predict outcomes, and select optimal solutions efficiently.
Advanced proficiency entails integrating Kafka Streams, Kafka Connect, and Confluent components into coherent workflows. In practical applications, a data pipeline may ingest data through a source connector, process it using Kafka Streams transformations, perform real-time queries with KSQL, and export results through a sink connector. Candidates capable of mentally simulating these end-to-end workflows, anticipating potential failure points, and reasoning about configuration implications demonstrate the level of understanding the examination seeks. Scenario-based questions often mirror such workflows, emphasizing applied competence over rote memorization.
Attention to subtle distinctions is crucial for achieving mastery. Small differences in terminology, configuration options, or component behavior can determine the correctness of an answer. Mastery involves synthesizing knowledge of delivery semantics, consumer group dynamics, schema compatibility, and stream processing logic. Candidates must develop the ability to analyze multifaceted problems and apply principles flexibly to novel situations. This integration of conceptual understanding, practical intuition, and analytical reasoning forms the cornerstone of advanced preparation.
Iterative reflection consolidates expertise. Reviewing errors from practice exams, analyzing reasoning missteps, and implementing corrective strategies strengthens comprehension and ensures the retention of knowledge. This process transforms weaknesses into strengths and builds confidence in approaching unfamiliar or complex questions. Continuous cycles of practice, reflection, and refinement cultivate resilience, clarity, and the analytical acuity necessary for excellence in the examination environment.
Hands-on experimentation and mental rehearsal remain pivotal. Configuring clusters, manipulating topics, deploying connectors, and running stream processing applications embed Kafka concepts into practical experience. Mental rehearsal of message flows, stream topologies, and connector interactions fortifies intuition, enabling candidates to anticipate outcomes, troubleshoot hypothetical problems, and respond to examination scenarios with confidence. The synthesis of practical exposure and cognitive modeling ensures that knowledge is both recallable and applicable under exam conditions.
Conclusion
Preparation for the Confluent Certified Developer for Apache Kafka examination ultimately represents a fusion of theory, practice, and strategic reflection. By integrating knowledge of brokers, consumer groups, Kafka Streams, Kafka Connect, and Confluent tools with hands-on experience and mental visualization, candidates cultivate an ability to reason critically and solve complex problems. Time management, community engagement, and iterative reflection further enhance readiness, ensuring that aspirants are equipped to navigate the multifaceted challenges of the examination.
Achieving success in this certification demonstrates not only technical proficiency but also the capacity to translate complex distributed data concepts into practical, reliable solutions. Mastery of Kafka’s architecture, operational nuances, stream processing, and Confluent integrations reflects a comprehensive skill set that is recognized and valued in contemporary data-driven environments. The journey of preparation, though intensive, equips candidates with a rare combination of analytical insight, practical experience, and strategic understanding, positioning them to excel both in the examination and in professional applications of Apache Kafka.

