
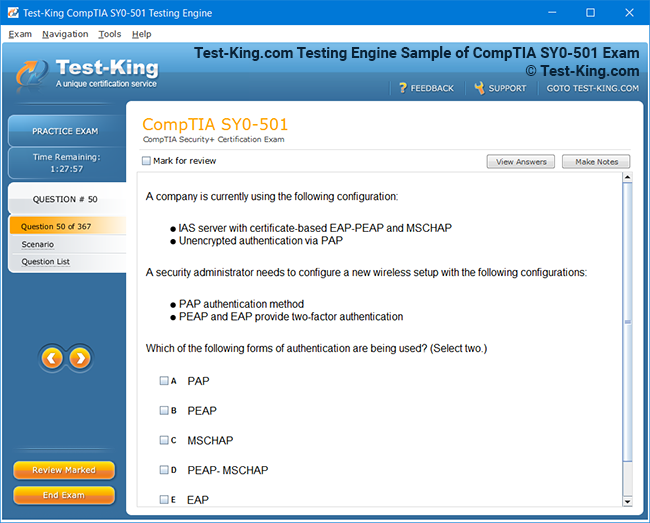
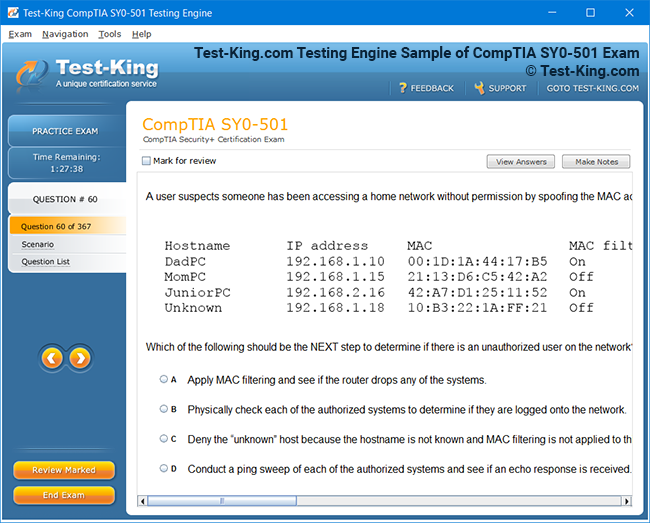
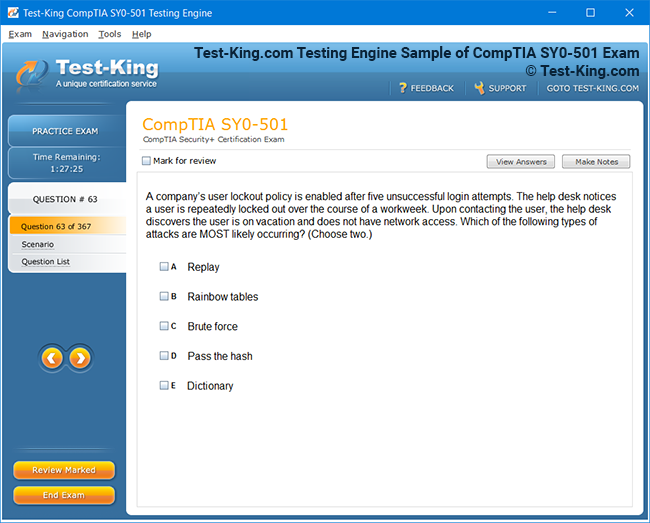
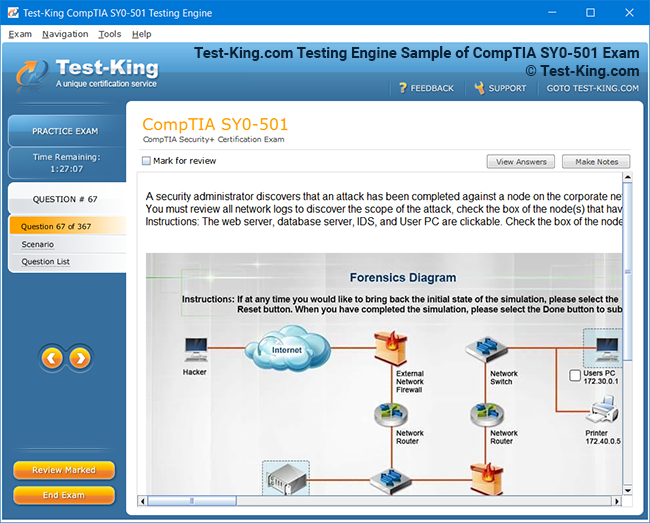
Product Screenshots
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Top NVIDIA Exams
NCA-GENL : The Road to Becoming an NVIDIA Certified Associate in Generative AI and LLMs
The pursuit of becoming an NVIDIA Certified Associate in Generative AI and LLMs is more than a technical achievement; it is a journey into the heart of a transformative discipline that is reshaping industries, redefining human-computer interaction, and rewriting the very foundations of computational intelligence. This certification, formally known as the NCA-GENL, is designed as an entry-level yet rigorous credential that measures a candidate’s aptitude in generative artificial intelligence and large language models, with a direct emphasis on the ecosystem built and supported by NVIDIA.
Understanding the Path to Certification
Generative AI has transcended its academic beginnings and is now ubiquitous in commercial systems ranging from conversational assistants to intelligent recommendation engines. Large language models, with their capacity to analyze, interpret, and generate human-like language, stand at the epicenter of this revolution. The examination that leads to the certification validates not just superficial familiarity with these topics but a candidate’s holistic grasp of the mathematical principles, programming practices, and optimization techniques that underpin their functionality.
The NCA-GENL examination is structured with careful intentionality. The entire test is scheduled within a one-hour time limit, with fifty questions carefully distributed across multiple dimensions of knowledge. It is priced at a level accessible to early-career practitioners and academic learners, with the current fee standing at one hundred thirty-five dollars. The test is conducted in English, with the assumption that candidates come with basic exposure to machine learning and an introductory familiarity with generative AI concepts. Although the assessment itself is brief, the preparation for it demands weeks if not months of dedicated study, immersion in hands-on exercises, and a cultivated familiarity with NVIDIA’s unique suite of products and solutions.
The distribution of knowledge areas in the exam offers a glimpse into its intellectual architecture. A smaller fraction, approximately one-tenth of the content, concentrates on the fundamentals of deep learning. This portion investigates support vector machines, exploratory data analysis, and the role of activation and loss functions in stabilizing learning algorithms. Another tenth is devoted to the architecture of transformers, demanding a clear comprehension of encoding, decoding, and attention mechanisms, which have emerged as the scaffolding for modern language models. The larger portion of the evaluation, nearly forty percent, emphasizes natural language processing and large language models. Within this portion, candidates are expected to demonstrate proficiency with text normalization methods like stemming and lemmatization, the theoretical and practical differences between WordNet and word2vec embeddings, the utilization of Python-based libraries such as spaCy, the functioning of NLP evaluation frameworks like GLUE, and standards of interoperability represented by ONNX. The remaining portion is heavily concentrated on the NVIDIA ecosystem itself. This includes applied knowledge of TensorRT, Triton Inference Server, RAPIDS for data pipelines, DGX systems, NeMo toolkit, and the broader NGC catalog.
Beyond these explicit areas, there are subtle expectations hidden in the syllabus. For example, questions concerning advanced optimization strategies for GPUs, CPUs, and memory management often appear. Likewise, nuanced exploration of NVIDIA platforms such as Jetson and NEO surfaces alongside theoretical inquiries into seminal research papers like “Attention Is All You Need” or the foundational Word2Vec. The candidate must also be prepared to engage with questions on quantization of models and the operational intricacies of deploying transformers at scale. These elements demonstrate that while the certification is tagged as entry-level, it is not shallow in its demands. It evaluates an individual’s ability to integrate fundamental understanding with applied skill.
To prepare for such a broad and multi-layered examination, aspirants must adopt a disciplined approach. At the beginning, one must grasp the overarching format and objectives of the test. Reading through NVIDIA’s official description of the examination provides clarity on what to expect. Once this clarity is established, the next step is to fortify one’s foundation. Machine learning and deep learning fundamentals must be revisited, including the building blocks of neural networks, gradient descent algorithms, and the subtleties of activation functions. Textual resources such as introductory textbooks on deep learning, in addition to modern digital courses available on platforms like Udemy and Lightning AI, provide robust starting points.
In parallel with theoretical studies, one must venture into the landscape of NVIDIA products, for this certification is inextricably tied to NVIDIA’s innovations. Candidates are expected to be comfortable with NeMo, which provides an open-source framework for conversational AI; TensorRT, which enhances the speed and efficiency of deep learning inference; cuOPT, which optimizes large-scale computational systems with GPU acceleration; DGX systems, which deliver powerful infrastructure for AI workloads; and NVIDIA Cloud, which opens access to flexible AI computing resources. Understanding these products goes beyond memorizing their names and requires practice in employing them within small projects or sandbox environments.
Programming proficiency forms another cornerstone of preparation. Although user-friendly tools exist, real mastery requires coding ability, particularly in Python. Knowledge of TensorFlow, PyTorch, and Keras should not remain theoretical. Implementing simple models, training them on small datasets, and debugging errors are essential exercises. These activities cultivate a familiarity with the rhythm of programming that is indispensable when handling larger and more complex generative AI projects. They also teach the aspirant how to translate abstract knowledge into concrete systems.
The preparation journey must also include sustained practice through projects. Building generative AI models that can synthesize text, generate images, or manipulate datasets enriches understanding in ways that static reading cannot. For example, working on a project that applies fine-tuning techniques to a pre-trained transformer not only reinforces theoretical ideas but also illuminates the challenges of data preprocessing, feature engineering, and experimental design. Similarly, engaging with retrieval-augmented generation techniques and deploying them in controlled environments allows the learner to comprehend the constraints and possibilities of modern AI systems. These projects serve as living laboratories where knowledge becomes skill.
After a cycle of theoretical learning, practical exploration, and programming exercises, the learner must evaluate their readiness. Practice tests play a pivotal role here. They simulate the structure and rhythm of the actual exam, familiarizing the candidate with the pace required to answer fifty questions within an hour. Scoring consistently above eighty percent in such practice assessments is a reliable indicator of preparedness. More importantly, analyzing mistakes within these tests reveals areas of weakness that can be targeted for review. Each error becomes an opportunity for growth, a chance to identify gaps in comprehension and correct them before facing the actual evaluation.
The difficulty of the certification cannot be ignored. For newcomers, the NCA-GENL may feel formidable, given its breadth of coverage and its expectation of applied skill. Concepts such as transformers, quantization, or RAPIDS pipelines may appear arcane at first. Yet with persistent study, structured practice, and deliberate immersion, the difficulty transforms from an obstacle into a catalyst for deeper learning. For individuals with prior exposure to machine learning, the test presents a challenging but manageable hurdle that validates their knowledge while sharpening their focus on NVIDIA’s unique contributions.
At its essence, pursuing the NVIDIA Certified Associate in Generative AI and LLMs is not simply about passing an exam. It is about aligning oneself with the future of artificial intelligence. This certification serves as a milestone that validates the learner’s ability to navigate the intricacies of modern AI, apply techniques in real-world contexts, and participate in the growing dialogue around how generative AI is shaping industries, research, and culture. It situates the professional at the intersection of theoretical mastery and practical capability, opening pathways for career advancement and intellectual enrichment.
Exploring the Curriculum in Depth
The NVIDIA Certified Associate in Generative AI and LLMs is not merely an entry credential but an intellectual passage that evaluates a candidate’s readiness to comprehend, design, and apply the core concepts of artificial intelligence in real practice. To understand the architecture of this examination, it is essential to explore the detailed content and syllabus that define its contours. The exam is meticulously structured, balancing foundational knowledge with more sophisticated and NVIDIA-specific capabilities. Its framework ensures that those who achieve certification are not only acquainted with theoretical principles but can also demonstrate competence in integrating those principles with technological platforms.
The examination covers a broad landscape of knowledge. While it is a single test with fifty questions to be attempted within sixty minutes, its internal divisions reveal how the syllabus is layered to balance simplicity with depth. A modest portion of the questions focuses on the rudiments of deep learning. In this section, aspirants are expected to display their understanding of support vector machines, exploratory data analysis, activation functions, and the nuanced interplay of loss functions in model optimization. This may sound elementary to some, but it establishes a foundation that is indispensable for comprehending the later parts of the exam where advanced methodologies are assessed.
Another important portion of the syllabus directs attention to transformer architectures, a framework that has revolutionized the world of natural language processing. The examination does not require candidates to replicate exhaustive mathematical derivations but expects clarity in the principles of encoding, decoding, and attention mechanisms. These are the cornerstones of large language models, and any practitioner in generative AI must recognize how these mechanisms orchestrate the transformation of raw linguistic input into coherent, context-aware output. The emphasis on transformers within the test underscores the dominance of these architectures in modern AI landscapes.
The most significant fraction of the exam is heavily weighted toward natural language processing and the direct workings of large language models. Here, candidates are expected to display mastery over a spectrum of techniques that range from the seemingly straightforward to the profoundly intricate. For instance, text normalization techniques like stemming and lemmatization, though elementary, test the candidate’s capacity to prepare raw data for computational analysis. Simultaneously, knowledge of embeddings such as Word2Vec and WordNet introduces deeper inquiries into how meaning and context are mathematically represented within a model. In addition, the use of libraries like spaCy is assessed, ensuring that candidates are not only theoretically adept but also practically capable of utilizing modern programming tools. Evaluation frameworks like GLUE are also addressed, revealing the test’s emphasis on the ability to measure performance using industry-standard benchmarks. Beyond these, standards of interoperability, exemplified by ONNX, are included to measure how well candidates can situate their work within broader systems that require compatibility and scalability.
Complementing this extensive coverage of language models is the exam’s concentration on the NVIDIA ecosystem itself. This portion requires a solid grasp of multiple tools, platforms, and technologies developed by NVIDIA to accelerate and optimize artificial intelligence. Candidates must be prepared to answer questions that delve into TensorRT, an engine designed to boost inference performance; Triton Inference Server, which simplifies the deployment of trained models at scale; RAPIDS data pipelines, which integrate GPU acceleration into data science workflows; DGX systems, which provide high-performance computing environments; NeMo, an open-source framework designed for building conversational AI models; and the NGC catalog, a repository that makes pre-trained models and resources accessible to developers. The test is explicit in requiring familiarity with these tools, and aspirants must move beyond surface-level knowledge to demonstrate an appreciation of how these systems function and why they are valuable in generative AI practices.
Advanced topics are woven throughout the syllabus, presenting subtle yet demanding challenges. CuDF data frames, GPU-accelerated machine learning with XGBoost, and graph analysis using cuGraph often appear in questions that test both memory and comprehension. The inclusion of these subjects ensures that the certification validates not only the candidate’s ability to work with traditional models but also their understanding of the high-performance computing environment that NVIDIA has cultivated. Seminal research papers, such as “Attention Is All You Need” or the groundbreaking contributions of Word2Vec, are another dimension of the test. While candidates are not required to reproduce the entire research, they must be able to identify the principles and innovations introduced by these works and explain their impact on the development of modern architectures.
Another theme that permeates the syllabus is optimization and deployment. Candidates must be able to articulate not just how models are built, but how they are integrated into real-world systems where efficiency and scalability are paramount. Questions may probe into memory optimization strategies, GPU and CPU allocation, or the intricacies of deploying a model in environments with constrained resources. By emphasizing these skills, the exam ensures that certified individuals are not merely theoreticians but are capable of pragmatic deployment in applied contexts.
What makes the exam both demanding and enriching is that it blends foundational knowledge with advanced practice, ensuring that the learner does not rely solely on rote memorization. For example, while one part of the exam may ask about the mechanics of gradient descent or the role of an activation function, another may demand insight into why certain optimization methods outperform others on GPU-accelerated systems. This duality reinforces the need for candidates to understand both the abstract underpinnings of algorithms and the applied intricacies of execution.
The exam does not shy away from testing nuanced subjects such as model quantization, which is particularly challenging. Quantization involves reducing the precision of models while maintaining their accuracy, a crucial step for deploying models in environments where computational resources are limited. This area often proves difficult for candidates because it requires balancing mathematical understanding with practical application. Similarly, the transformer model, already dominant in the landscape, appears throughout the test in different guises, from basic questions about attention to more advanced inquiries into encoder-decoder architectures and scaling techniques.
To truly appreciate the syllabus, one must recognize that it is deliberately designed to map onto real-world applications. Each portion of the exam, whether it is a deep learning basic, a transformer mechanism, or a question about NVIDIA infrastructure, reflects actual challenges that professionals face in their work. When a question asks about stemming and lemmatization, it indirectly tests how well a candidate can prepare textual data for an NLP pipeline. When a question probes TensorRT, it reflects the expectation that a professional can improve the performance of a deployed model. The exam, therefore, is not abstract but deeply rooted in the realities of working with generative AI.
For those preparing, the syllabus also indicates where to focus their energies. Spending time on natural language processing and large language models is indispensable, as nearly half of the test derives from these topics. Equally, neglecting NVIDIA-specific knowledge would be a grave error, as the certification is fundamentally tied to their ecosystem. Balancing preparation across fundamentals, advanced topics, and applied tools is the art of succeeding in this exam. It is also important to note that the test indirectly evaluates problem-solving skills, critical thinking, and the ability to synthesize diverse areas of knowledge into coherent answers.
The syllabus further reflects the philosophy of NVIDIA: to create not just tools but an integrated ecosystem that supports researchers, developers, and professionals in building next-generation applications. By aligning the examination with both general principles of AI and the specific products and frameworks of NVIDIA, the certification ensures that those who pass are aligned with industry expectations. It represents a fusion of academic rigor and technological applicability, a blend that defines the future of artificial intelligence.
Strategies for Mastery and Success
Embarking on the preparation journey for the NVIDIA Certified Associate in Generative AI and LLMs requires more than casual study. It is a structured endeavor that demands foresight, consistent practice, and deliberate immersion into both theoretical principles and applied methodologies. The exam, with its carefully balanced content, tests a candidate’s resilience in navigating diverse areas such as machine learning fundamentals, transformer architectures, natural language processing, and the multifaceted NVIDIA ecosystem. To be adequately prepared, an aspirant must adopt an approach that goes far beyond rote memorization and instead cultivates enduring comprehension and applicable skills.
The very first task is to become familiar with the exam’s format. The test is time-bound, allowing only sixty minutes to respond to fifty carefully constructed questions. Each question is designed not merely to probe shallow familiarity but to test whether the candidate can integrate concepts in a practical manner. The cost of the exam is set at one hundred thirty-five dollars, positioning it as accessible yet demanding enough to carry weight in the professional world. It is conducted in English, with the assumption that the participant already has introductory knowledge of generative AI and large language models. Recognizing these foundational details is essential, for they set the tone of preparation and highlight the importance of efficiency, accuracy, and clarity of thought under pressure.
Once the structural aspects are internalized, the next step involves fortifying the basics. Foundational knowledge in deep learning, machine learning, and core artificial intelligence principles forms the bedrock of preparation. Revisiting these topics might feel redundant to those with experience, but it is precisely this groundwork that anchors advanced study. Neural networks, activation functions, gradient descent methods, and exploratory data analysis all play roles within the exam’s framework. Without clarity in these basics, one will struggle to grasp the more sophisticated elements such as transformers, quantization, or RAPIDS pipelines. Books, digital courses, and interactive platforms offer a multitude of resources for this stage. Courses on deep learning fundamentals and generative AI basics provide a coherent entry point, while e-books like Generative AI in Practice and Introduction to Conversational AI expand the horizon of understanding with concrete examples and theoretical richness.
Parallel to reinforcing theory is the necessity of engaging with NVIDIA’s own ecosystem. The exam is crafted not only to test universal AI knowledge but also to measure competence in NVIDIA tools that dominate real-world applications. Understanding NeMo, the open-source toolkit for conversational AI, becomes indispensable. Candidates must also explore TensorRT, which accelerates inference in deep learning models, and cuOPT, designed for solving complex optimization tasks. Familiarity with DGX systems, celebrated for their high-performance computing capabilities, is vital, as is comprehension of NVIDIA Cloud solutions, which provide flexible computational environments for artificial intelligence. Gaining practical exposure to these platforms cannot be substituted by theoretical reading alone. Tutorials, lab simulations, and hands-on exercises allow aspirants to internalize their functions, ensuring that exam questions probing these tools can be met with confidence.
Programming skill is another indispensable component of preparation. The exam expects proficiency in Python, the lingua franca of artificial intelligence development. Candidates who restrict themselves to graphical interfaces or automated tools will find themselves at a disadvantage. Hands-on coding with frameworks like TensorFlow, PyTorch, and Keras is necessary to comprehend how algorithms are structured, trained, and evaluated. Beyond model construction, one must also cultivate dexterity in debugging, optimizing scripts, and handling data preprocessing. These skills ensure that when a question arises concerning the implementation of large language models or data pipelines, the candidate has more than superficial understanding to rely upon. Real projects, even if modest in scale, such as training a model to classify text or fine-tuning a transformer for sentiment analysis, provide invaluable practice that binds theory to application.
Building upon this, preparation must extend into practical projects that challenge the learner to synthesize multiple concepts simultaneously. For instance, creating a generative model that can produce coherent text or generate synthetic images requires combining preprocessing techniques, understanding embedding mechanics, and applying neural network fundamentals. Similarly, experimenting with retrieval-augmented generation methods deepens the understanding of how large language models can be enhanced with external data. These projects reveal the subtleties of data handling, the limitations of current architectures, and the necessity of optimization, preparing the candidate for questions that demand applied reasoning. Engaging with datasets of varying complexity, from simple textual corpora to multimodal inputs, builds resilience and cultivates problem-solving instincts that the exam seeks to validate.
Equally important is a strategic approach to practice testing. Practice exams simulate the time constraints and question structures of the actual test, providing a crucial mirror of readiness. Achieving high scores consistently, particularly beyond eighty percent, signals a solid grasp of the material. Yet the true value of practice lies in the review process. Every error should be dissected to uncover gaps in understanding. If a mistake arises from a question about embedding techniques, it signals the need to revisit Word2Vec or explore the differences between semantic and syntactic representations. If confusion occurs with RAPIDS pipelines, additional hands-on experimentation may be required. Over time, this iterative approach transforms weaknesses into strengths and refines the mental models that candidates will rely upon in the high-pressure environment of the actual exam.
An often-overlooked dimension of preparation is the psychological readiness needed for success. The exam is moderately challenging, not just because of its content but because of the intensity of answering fifty diverse questions in a compressed time frame. Cultivating time management skills during practice is essential. Candidates must train themselves to balance speed with accuracy, ensuring that they do not linger excessively on a single question while still avoiding careless mistakes. Mental stamina is equally critical. Sustaining focus throughout the entire duration requires resilience, which can be built through disciplined study routines and simulated exam conditions. Stress management techniques, such as controlled breathing and structured revision schedules, further contribute to maintaining composure under pressure.
Another aspect of preparation lies in understanding the broader context of the syllabus. Questions about research papers like “Attention Is All You Need” or early innovations like Word2Vec are not designed to test rote memorization but to measure whether the candidate can situate modern technologies within the lineage of artificial intelligence research. This requires reading seminal works with discernment, identifying their contributions, and appreciating how they underpin current practices. Similarly, questions about quantization or deployment strategies test a candidate’s ability to think beyond training models to integrating them into environments where efficiency, scalability, and adaptability matter. Recognizing this broader perspective transforms preparation from a narrow exercise into an expansive intellectual pursuit.
In the later stages of preparation, synthesis becomes the central focus. Candidates must practice drawing connections between diverse topics, for example, how transformers integrate with natural language processing pipelines, or how RAPIDS data pipelines can enhance the performance of large-scale machine learning tasks. This interconnected thinking mirrors real-world applications, where solving a problem rarely relies on a single isolated technique but instead requires combining multiple approaches. Simulated projects, interdisciplinary study, and collaborative learning can foster this capacity for integration.
Ultimately, preparing for the NVIDIA Certified Associate in Generative AI and LLMs is an immersion into both the foundations and the frontiers of artificial intelligence. It requires revisiting basic concepts, mastering modern tools, acquiring coding fluency, engaging in hands-on experimentation, practicing strategically, and cultivating psychological resilience. It is a demanding yet rewarding journey that transforms the aspirant into a practitioner capable of navigating the intricacies of generative AI and large language models with competence and confidence.
Exam Challenges and Expectations
The NVIDIA Certified Associate in Generative AI and LLMs represents a significant milestone for anyone aspiring to validate their understanding of large language models and the broader domain of generative artificial intelligence. Although it is officially classified as an entry-level credential, it carries a level of complexity that requires more than superficial preparation. The test is designed not only to assess knowledge but to measure the ability to apply that knowledge within practical contexts that reflect the fast-evolving landscape of artificial intelligence. Its difficulty arises from several interwoven factors: the breadth of the syllabus, the technical nature of NVIDIA’s ecosystem, the integration of theoretical underpinnings with applied skills, and the limited time frame within which candidates must respond accurately.
The exam format itself introduces its own layer of difficulty. Candidates are allotted sixty minutes to address fifty carefully constructed questions. This compresses both recall and reasoning into a short period, demanding efficiency, clarity, and focus. Unlike some examinations that rely solely on memorized definitions, this assessment integrates problem-solving scenarios that require genuine comprehension. Questions may involve understanding how gradient descent functions in optimizing a model, or why specific activation functions are chosen for certain architectures. Others may probe the inner workings of transformer-based models, such as the significance of attention mechanisms or encoder-decoder structures. The pace required to navigate these without succumbing to time pressure amplifies the perception of challenge, especially for those unaccustomed to such rigorous formats.
One of the most formidable aspects of the test is the weight assigned to natural language processing and large language models. Nearly half of the questions revolve around text-based systems, requiring proficiency in text normalization, embeddings, semantic interpretation, and the use of advanced libraries. This means a candidate must be prepared to handle inquiries about stemming versus lemmatization, or the deeper theoretical foundations of embeddings like Word2Vec. They must also be familiar with spaCy, GLUE benchmarks, and interoperability standards like ONNX. What makes this domain difficult is its dual demand for both theoretical understanding and practical application. A candidate might understand how embeddings function in theory, but unless they have actually worked with them in practice, their answers may lack the precision the exam requires.
Another dimension that contributes to the difficulty is the emphasis on NVIDIA-specific platforms and technologies. For many aspirants, this is where the challenge intensifies, as the exam expects familiarity with tools that are not universally taught in generic machine learning courses. TensorRT, Triton Inference Server, RAPIDS pipelines, DGX systems, NeMo, and the NGC catalog are not merely add-ons but integral parts of the syllabus. A candidate must know how TensorRT accelerates inference or why Triton is crucial for deploying large models at scale. Questions may delve into the subtleties of optimizing workloads on GPU clusters or integrating RAPIDS data pipelines for end-to-end machine learning tasks. Those who overlook these tools in their preparation often find themselves bewildered by the specificity of the questions. Mastery of this ecosystem requires hands-on exposure, and without that, even otherwise strong candidates may falter.
The presence of advanced topics further enhances the perception of difficulty. Subjects like GPU-accelerated XGBoost, cuDF data frames, and cuGraph challenge candidates to merge knowledge of algorithms with high-performance computing. These are not theoretical constructs but practical tools used in industry, and the exam expects recognition of their value and operation. Added to this are references to seminal research works such as “Attention Is All You Need” and Word2Vec, which serve as intellectual anchors for modern architectures. Understanding the historical and technical significance of these works requires more than a casual read; it demands an ability to distill their core contributions and explain their relevance in the current context of large language models.
Optimization and deployment practices add another layer of intricacy. The test may include scenarios where candidates must decide the best strategies for model quantization, memory allocation, or inference acceleration in production environments. This focus on applied skills reveals the exam’s intent: to certify professionals who can bridge the gap between building a model and making it operational in real-world systems. The difficulty here is not in memorizing terms but in comprehending why certain approaches outperform others depending on context. This nuance elevates the exam beyond being a theoretical exercise into one that tests professional competence.
The psychological aspect of the test should not be underestimated. For many candidates, the knowledge that they must navigate a wide syllabus within an unforgiving time frame can create considerable anxiety. This mental pressure can lead to mistakes that would not occur under relaxed conditions. The exam therefore not only tests technical proficiency but also the ability to maintain composure and clarity of thought under duress. Candidates who practice managing stress and simulating exam conditions tend to fare better, while those who neglect this element often struggle even if they have studied the material extensively.
Another reason the exam is considered moderately challenging is the way it integrates different areas of knowledge. It is not uncommon for a question to weave together deep learning fundamentals with NVIDIA-specific implementation. For example, a candidate might need to recall the mechanics of backpropagation while also identifying how RAPIDS accelerates this process within GPU-driven pipelines. Similarly, understanding the theoretical operation of transformers must be paired with knowledge of how NeMo supports their deployment in conversational AI systems. This integration of theory and application tests whether candidates can think holistically rather than in isolated categories, a skill that is essential for real-world problem-solving but difficult to achieve without consistent and deliberate preparation.
What complicates matters further is the fact that the exam has been crafted to reflect the realities of contemporary artificial intelligence development. This means that superficial learners who depend solely on textbooks or slide decks will find themselves at a disadvantage. Instead, the test rewards those who immerse themselves in projects, experiments, and practical applications. The difficulty level therefore rises for individuals who have not engaged directly with generative models, fine-tuned large language systems, or experimented with GPU acceleration. To succeed, one must blend theoretical literacy with experiential wisdom, an endeavor that requires significant time and commitment.
The perception of difficulty also varies based on the candidate’s background. Those who come from a pure software development background may struggle with the mathematical and theoretical rigor of deep learning principles. Conversely, those who are academically strong in algorithms may find the practical use of NVIDIA platforms daunting if they lack exposure. This makes the exam an equalizer, demanding competence across domains rather than allowing expertise in one area to carry the candidate through. Such multidimensional difficulty ensures that the certification holds genuine value, as it reflects balanced proficiency rather than narrow specialization.
Time pressure compounds these challenges. With only a little more than a minute allocated per question, there is little room for lengthy deliberation. Candidates must develop the ability to identify key points quickly, apply relevant knowledge, and eliminate distractors without hesitation. This level of efficiency is often developed only through repeated practice under simulated conditions. Without this preparation, even well-prepared individuals may find themselves running out of time, leaving questions unanswered.
In evaluating the overall difficulty, it becomes evident that the exam is not designed to be insurmountable. With structured preparation, hands-on practice, and disciplined study habits, candidates can pass with confidence. However, its moderate challenge is intentional, as it ensures that the credential represents real skill and not merely attendance at a course. The questions are written to expose weaknesses, test adaptability, and reward genuine mastery. For aspirants, recognizing this truth is crucial: the difficulty is a measure of quality, and overcoming it not only leads to certification but also prepares one to handle real-world challenges in artificial intelligence and large language models with greater competence and assurance.
Frequently Asked Considerations, Practical Illustrations, and Closing Reflections
When exploring the journey of preparing for the NVIDIA Certified Associate in Generative AI and LLMs, many aspiring professionals naturally arrive at a point where they seek clarity about practical matters. These questions often go beyond the syllabus itself and reflect genuine curiosity about readiness, value, preparation, and how the credential integrates into their broader career path. Instead of addressing these questions as abrupt fragments, it is more useful to shape them into flowing explanations that give both guidance and reassurance while weaving in examples, context, and the subtleties of this growing field.
One of the most common inquiries revolves around whether a candidate with only a foundational background in artificial intelligence can realistically succeed in this exam. The answer lies in the structure of the certification itself. It is designed at the associate level, meaning it does not demand years of professional mastery but instead expects a blend of theoretical knowledge and demonstrable practical skills. Candidates with limited exposure often assume they must become experts in every NVIDIA product or advanced research paper before even considering the test. In truth, what is required is focused learning, thoughtful study planning, and a willingness to engage with hands-on exercises. For instance, someone new to NVIDIA solutions might begin by experimenting with NeMo for conversational models or working through RAPIDS tutorials for accelerated data analysis. These practical steps transform abstract concepts into experiential knowledge, allowing even beginners to gradually build the competence required to clear the exam.
Another question that arises concerns the long-term value of the certification. Some professionals wonder if the NVIDIA Certified Associate in Generative AI and LLMs will hold weight in an industry where new advancements appear almost daily. The significance of the credential lies precisely in its alignment with NVIDIA’s ecosystem, which dominates large parts of the artificial intelligence hardware and software infrastructure worldwide. Since GPUs form the backbone of model training and inference, and since NVIDIA continues to spearhead innovations in AI acceleration, the certification does not merely validate theoretical understanding but marks candidates as conversant with industry-standard tools. Employers increasingly look for individuals who can transition seamlessly from academic concepts into real-world deployments, and this credential signals that capacity. Its long-term value is therefore less about static recognition and more about serving as a foundation from which to pursue higher certifications, specialized projects, or advanced research roles.
The time investment needed for preparation is another area of curiosity. While some individuals can pass with only a few weeks of dedicated study, most candidates find that two to three months of consistent preparation yield the best results. This timeline allows for gradual mastery of theoretical subjects such as transformer architectures and optimization strategies, while also providing space to explore NVIDIA’s unique platforms like TensorRT and Triton Inference Server. Candidates who try to compress all of this learning into a short span may find themselves overwhelmed, not because the material is impossible but because their minds do not have adequate time to absorb, synthesize, and apply the concepts. A measured approach, where study sessions are paired with applied projects, proves far more effective. For example, dedicating a week to revisiting the seminal paper “Attention Is All You Need” while simultaneously implementing a small-scale transformer model creates a synergy between reading and doing. Over time, this synergy develops confidence that theoretical knowledge can be turned into practical problem-solving.
Another consideration many candidates raise is the role of practice tests. They often ask whether mock exams truly reflect the structure and difficulty of the official test. Practice assessments play an indispensable role, not merely in measuring knowledge but in conditioning the mind to the exam’s rhythm. They expose blind spots, highlight recurring themes, and train candidates to manage the sixty-minute timeframe effectively. A candidate who consistently scores above eighty percent in practice sessions is usually ready to attempt the real exam with composure. However, it is not just about the score but the process of reviewing mistakes, understanding why certain options were incorrect, and retraining one’s thought process. These iterative cycles of self-evaluation transform uncertainty into readiness.
An area where curiosity often deepens is the specific emphasis on large language models within the syllabus. Many professionals wonder why such a large proportion of the test is devoted to them compared with more general machine learning concepts. The answer is tied to the trajectory of artificial intelligence itself. Large language models are not only the most widely applied generative systems today but also the driving force behind many contemporary applications, from conversational assistants to complex content generation engines. By centering a significant portion of the exam on LLMs, NVIDIA ensures that certified individuals possess the expertise demanded by the most relevant and impactful domains of modern AI. In this sense, candidates should not view the emphasis as restrictive but as preparation for the realities of professional practice, where proficiency with transformers, embeddings, and fine-tuning methods carries immense value.
Some candidates also wonder about the practical relevance of mastering NVIDIA-specific tools as opposed to sticking with general-purpose frameworks like TensorFlow or PyTorch. This is where the unique positioning of the certification becomes clear. While general frameworks provide the backbone of model development, NVIDIA’s ecosystem addresses the crucial challenges of performance, scalability, and deployment. For instance, TensorRT optimizes inference speeds to levels that are essential for enterprise-grade systems, while Triton Inference Server orchestrates models at scale with flexibility across GPUs and CPUs. Understanding these tools is therefore not an academic exercise but a way to bridge theory with the high-performance demands of industry. When candidates engage with them, they are not only preparing for exam questions but equipping themselves to contribute meaningfully to real-world projects.
There is also frequent curiosity about the difficulty of specific subjects within the syllabus. Many report that topics like model quantization or transformer internals pose greater challenges than basic machine learning concepts. This perception is accurate, as these areas demand nuanced comprehension and often involve counterintuitive principles. For example, quantization requires one to appreciate how reducing numerical precision can conserve memory and accelerate computation without drastically sacrificing model accuracy. This balance is delicate and cannot be understood through rote memorization alone; it requires both experimentation and critical reflection. Similarly, attention mechanisms in transformers challenge learners to grasp how context is preserved across long sequences, an idea that diverges sharply from earlier recurrent network paradigms. Such areas contribute significantly to the exam’s overall difficulty and necessitate deeper immersion.
Beyond these academic and practical concerns, candidates frequently express curiosity about how the certification impacts career growth. While no credential can guarantee opportunities, the NVIDIA Certified Associate in Generative AI and LLMs often acts as a catalyst. It signals not just a grasp of theory but also adaptability to cutting-edge technologies that employers actively integrate. Professionals who achieve the credential often find themselves entrusted with more complex projects, considered for advancement, or given access to collaborative opportunities involving high-performance AI systems. The credential also provides a stepping stone toward advanced certifications or specialized roles in AI research, model deployment, or enterprise-level innovation. It becomes part of a portfolio that demonstrates continuous learning and professional ambition.
The financial cost of the exam is another frequent point of inquiry. At a price of one hundred thirty-five dollars, it may appear modest compared with some other certifications, yet its value lies in the credibility it offers. Considering the ubiquity of NVIDIA hardware and the rapid adoption of generative AI applications, the return on investment becomes evident for those who leverage the credential to expand their responsibilities or secure roles that emphasize AI expertise. The cost should not be viewed as a hurdle but as an investment in professional validation that can open doors to higher earnings and new projects.
It is also worth addressing the issue of language. Since the exam is conducted in English, candidates for whom English is not the first language sometimes worry about comprehension. While technical terminology remains universal across contexts, the phrasing of questions may require careful reading. For such candidates, practicing with English-based resources, participating in discussion groups, and engaging with technical literature helps mitigate linguistic obstacles. This ensures that language proficiency does not impede the demonstration of technical knowledge.
Finally, it is important to reflect on what success in this exam truly signifies. Passing the NVIDIA Certified Associate in Generative AI and LLMs is not simply about receiving a certificate; it is about confirming that one can engage with artificial intelligence at a professional level, navigate NVIDIA’s ecosystem, and apply concepts to real-world challenges. The knowledge gained during preparation often proves more valuable than the credential itself, as it empowers individuals to approach projects with a structured, informed, and adaptable mindset.
Conclusion
The path to becoming an NVIDIA Certified Associate in Generative AI and LLMs is marked by curiosity, challenge, and growth. It is not an effortless endeavor, nor is it intended to be. Instead, it represents a balanced test of foundational knowledge, applied skills, and the ability to think critically under time constraints. Addressing the common concerns of candidates—from preparation strategies and subject difficulty to long-term value—reveals that the certification serves as both a milestone and a springboard. It validates competence in generative artificial intelligence while preparing candidates to engage confidently with NVIDIA technologies and real-world implementations. For professionals seeking to thrive in the rapidly expanding domain of AI, achieving this credential offers both recognition and readiness, ensuring they are equipped to meet the demands of an industry defined by constant evolution and boundless opportunity.

