
Exam Code: C2090-101
Exam Name: IBM Big Data Engineer
Certification Provider: IBM
Corresponding Certification: IBM Certified Data Engineer - Big Data
Product Screenshots
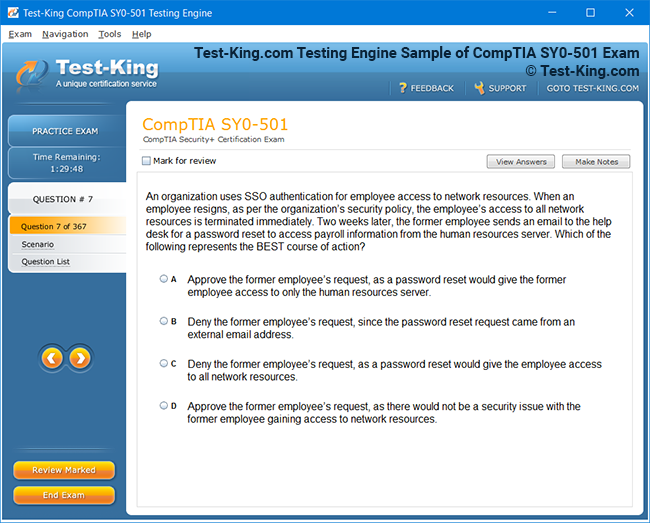
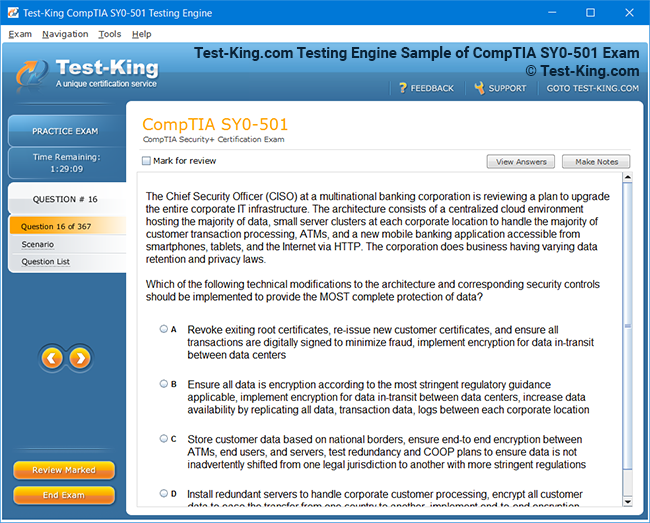
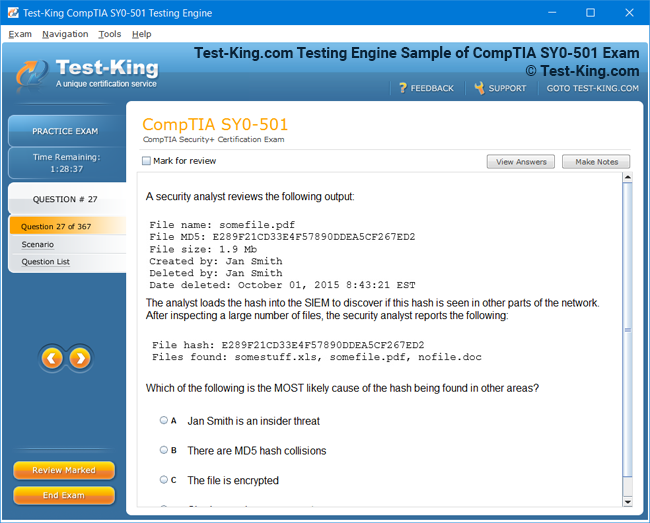
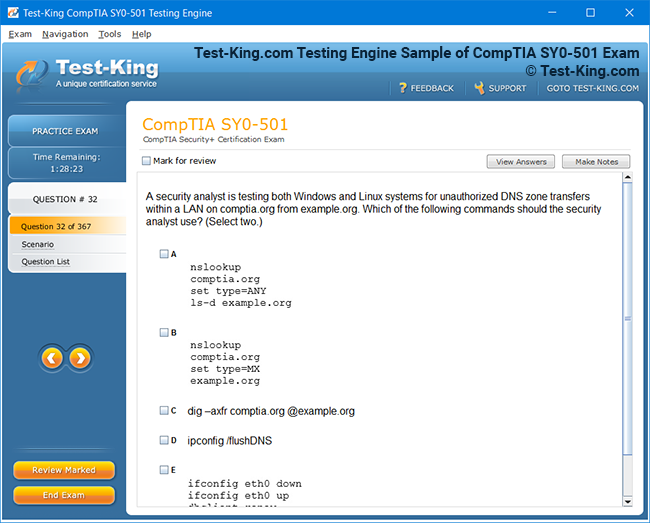
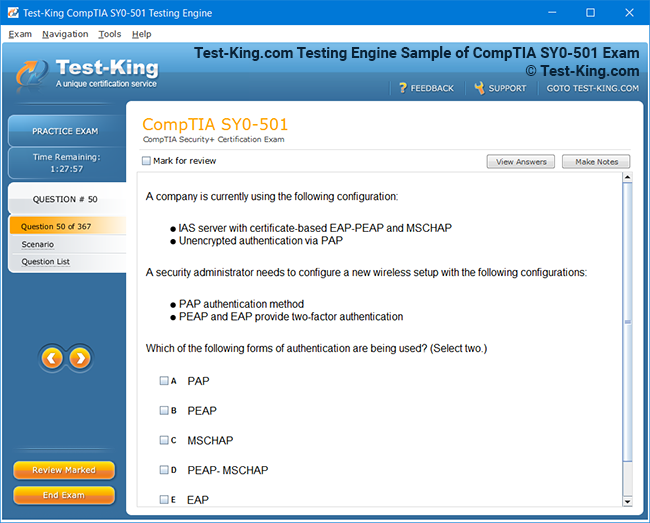
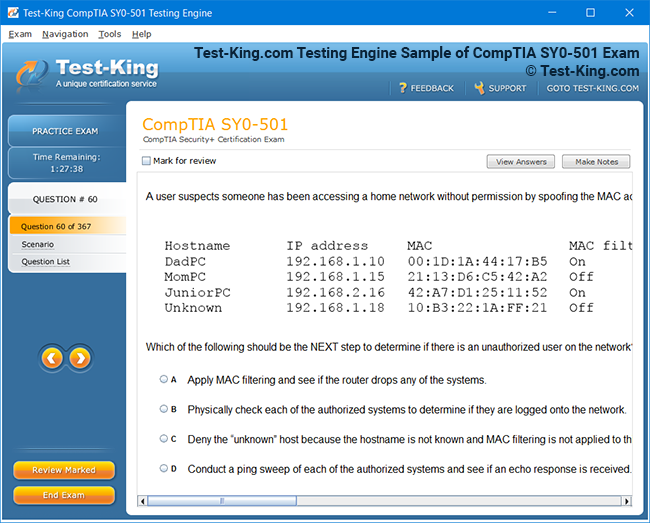
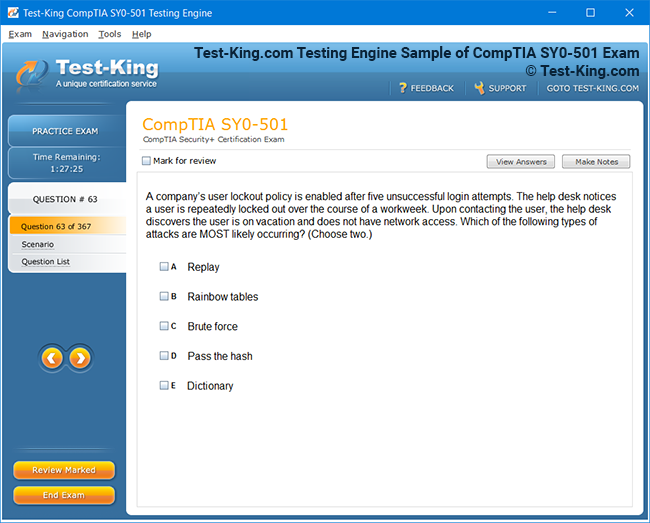
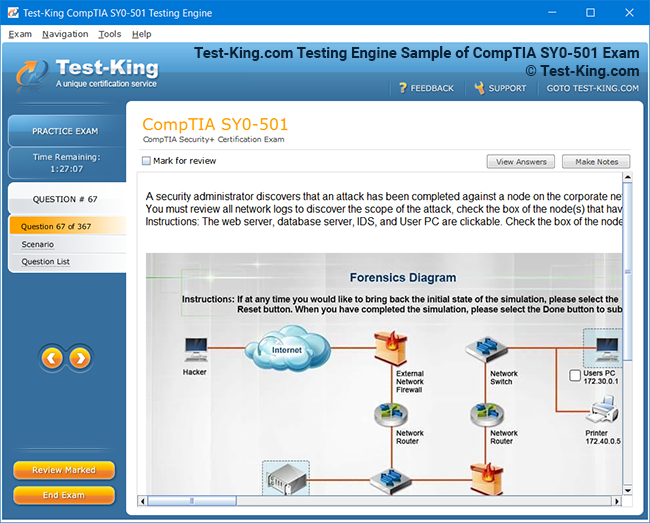
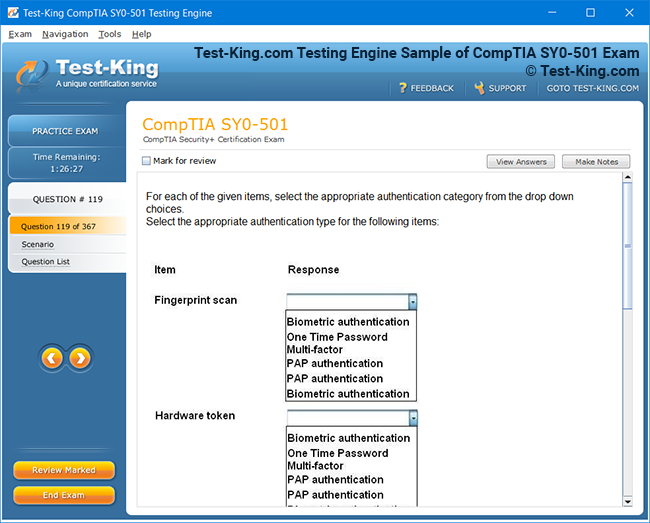
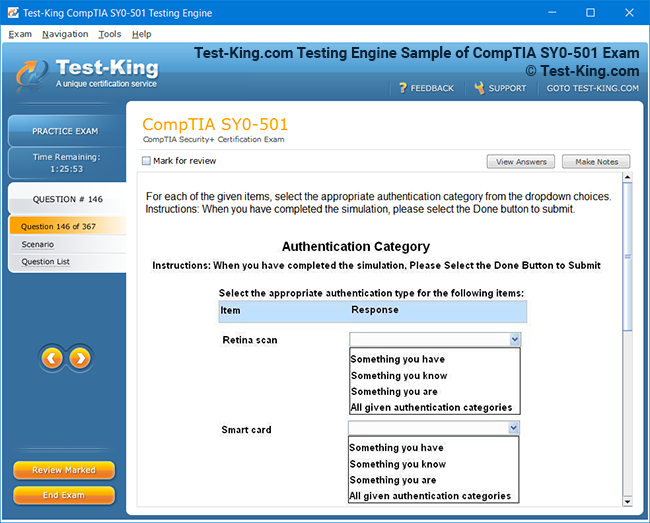
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Top IBM Exams
Comprehensive Guide to the IBM Big Data Engineer C2090-101 Exam
The IBM Big Data Engineer C2090-101 exam represents a crucial benchmark in the professional world of data engineering, analytics, and cognitive technology. This certification validates one’s ability to manage, design, and implement complex data-driven infrastructures using IBM’s advanced Big Data ecosystem. As enterprises navigate the ever-growing data deluge, the importance of a credential that confirms expertise in processing, analyzing, and orchestrating massive datasets has grown exponentially. The exam is not merely a test of technical competence; it is a demonstration of a candidate’s comprehensive understanding of data pipelines, distributed computing paradigms, and the architectural intricacies of large-scale information systems.
The C2090-101 certification is recognized globally for its rigor and alignment with real-world industrial demands. IBM, as a pioneer in enterprise technology, designed this certification to measure skills that bridge theoretical data management principles with applied engineering proficiency. Professionals who pursue this certification are often data engineers, data architects, or analytics specialists seeking to validate their command over IBM’s Big Data platforms and allied technologies such as Hadoop, Spark, Kafka, and various NoSQL systems. The certification acts as both a credential of competence and a catalyst for career elevation within data-driven industries.
Understanding the Foundation and Significance of the IBM Big Data Engineer Certification
The central ethos behind this examination revolves around the capability to architect, integrate, and optimize Big Data solutions that are robust, secure, and scalable. The IBM Big Data Engineer exam is not confined to theoretical comprehension but emphasizes practical implementation across data ingestion, storage, transformation, and visualization layers. As such, it demands a broad yet profound understanding of distributed systems, parallel processing, data governance, and analytics integration.
The Purpose and Structure of the IBM Big Data Engineer Examination
The IBM Big Data Engineer C2090-101 exam assesses candidates through a structured format that mirrors real-world project environments. Each element of the examination evaluates different facets of data engineering — from data modeling to performance optimization. Candidates must demonstrate their proficiency in designing and maintaining data ecosystems that can sustain high-velocity, high-volume information flows without compromising integrity or reliability.
The exam encompasses key conceptual pillars including Hadoop architecture, Spark-based processing, data ingestion using tools like Flume and Sqoop, and the orchestration of data pipelines through IBM’s enterprise-level frameworks. Furthermore, it evaluates understanding of database systems, both relational and non-relational, with an emphasis on integration between structured and unstructured data. While many certification programs focus narrowly on technology-specific tasks, IBM’s exam extends its purview to a holistic understanding of end-to-end data ecosystems.
Typically, candidates preparing for the C2090-101 certification encounter questions that reflect real-world problem-solving rather than memorization of terminologies. For instance, instead of merely asking what Hadoop’s NameNode does, the exam may present a scenario where a cluster encounters latency, and the candidate must identify the probable cause based on data flow comprehension. Such a format ensures that only those who possess genuine operational and architectural insight succeed.
To excel in this exam, aspirants must internalize not just IBM’s product-specific tools but also universal Big Data paradigms such as distributed computation, fault tolerance, and resource management. The test validates an individual’s capability to work seamlessly across hybrid data environments — combining cloud-native storage, on-premise clusters, and real-time processing engines into one cohesive infrastructure.
Conceptual Depth: Core Domains and Competency Areas
The IBM Big Data Engineer exam covers multiple domains, each representing a distinct area of expertise within the data engineering spectrum. The first major domain encompasses data ingestion and integration. Candidates are expected to understand how to assimilate disparate data sources, ranging from transactional systems and IoT devices to social media feeds and enterprise data warehouses. Knowledge of streaming data frameworks, message queues, and batch processing pipelines is indispensable.
The second domain centers on data storage and management. This involves understanding the nuances between HDFS, NoSQL databases, and IBM’s proprietary data stores. Engineers must be able to determine optimal storage strategies based on access patterns, scalability requirements, and consistency models. This domain also introduces the candidate to concepts such as data replication, indexing, partitioning, and lifecycle management — each vital for maintaining system performance in large-scale deployments.
Another crucial domain pertains to data processing and transformation. Here, Spark plays a pivotal role, as it has become the backbone of modern data processing due to its in-memory computing capability. Understanding Spark’s architecture, including RDDs, DataFrames, and the Catalyst optimizer, is essential. Candidates must be adept at applying transformations, joins, aggregations, and streaming computations while maintaining efficiency across clusters.
The examination also tests competence in data analysis and visualization. Although the IBM Big Data Engineer is primarily an engineering role rather than a business intelligence position, the ability to interpret data meaningfully is fundamental. IBM’s certification expects candidates to understand how analytical results can be integrated into dashboards, reports, and cognitive applications. This includes using IBM Cognos, Watson Studio, and other analytical platforms for real-world decision support.
A further dimension involves data governance and security. In the current digital landscape, safeguarding information assets is a central concern. The IBM certification ensures that engineers comprehend access control models, encryption mechanisms, auditing, and compliance frameworks. Knowledge of secure cluster configuration and privacy-preserving analytics is often a differentiating factor among candidates.
Finally, the exam validates practical deployment and troubleshooting abilities. Candidates should be familiar with performance tuning, workload balancing, and error recovery strategies. These skills distinguish proficient data engineers from merely competent ones, as real-world data systems frequently encounter bottlenecks, hardware failures, and configuration anomalies that require nuanced and rapid resolution.
The Professional Relevance and Industry Impact
Earning the IBM Big Data Engineer certification places professionals in a distinct echelon within the data domain. Organizations across industries — finance, healthcare, logistics, manufacturing, and government — depend on data-driven insights for strategic decisions. With enterprises handling petabytes of information daily, the need for engineers capable of orchestrating complex data ecosystems is acute. The C2090-101 certification signals to employers that the holder can not only operate Big Data frameworks but also align them with business objectives and compliance mandates.
IBM’s certification programs have historically emphasized practical industry alignment, ensuring that certified engineers are immediately productive in enterprise roles. The Big Data Engineer credential follows this tradition by grounding its competencies in applied scenarios. Certified professionals are typically expected to manage data workflows that combine traditional RDBMS systems with cloud-native architectures such as IBM Cloud Pak for Data or hybrid clusters leveraging Kubernetes.
Moreover, this certification underlines an individual’s adaptability in a rapidly evolving field. Big Data technologies evolve swiftly, and new paradigms like data mesh, lakehouse architecture, and real-time analytics pipelines are reshaping traditional data management. The IBM Big Data Engineer exam ensures that candidates can contextualize these innovations within IBM’s technological ecosystem. Thus, certification holders become versatile practitioners capable of bridging emerging technologies with established enterprise infrastructures.
From an organizational standpoint, employing certified engineers enhances the reliability and scalability of data operations. Enterprises gain from reduced downtime, improved data quality, and streamlined analytics pipelines, all of which contribute directly to cost efficiency and innovation velocity. Consequently, IBM-certified professionals often occupy pivotal roles in data modernization projects, cloud migrations, and AI integration initiatives.
The Knowledge Framework Behind Preparation
Preparation for the IBM Big Data Engineer exam requires a systematic approach that intertwines theoretical understanding with hands-on experimentation. Aspirants must immerse themselves in the IBM documentation ecosystem, whitepapers, and platform guides that detail the internal workings of products such as InfoSphere BigInsights, IBM Streams, and DataStage. Understanding IBM’s perspective on data integration, cleansing, and governance provides the foundational mindset required to approach the exam with confidence.
A disciplined study strategy typically begins with mastering Hadoop’s core components — the NameNode, DataNode, ResourceManager, and YARN architecture. Comprehension of how data blocks are distributed, replicated, and processed forms the bedrock upon which further knowledge is built. Subsequently, learners progress to Spark, exploring its interactive shell, cluster managers, and fault tolerance mechanisms. They must also become comfortable configuring and tuning Spark jobs to optimize execution across multi-node environments.
Another critical area of focus is data ingestion. Candidates are encouraged to practice importing data from various sources using utilities like Sqoop for relational data and Flume for streaming or log data. Understanding message-based ingestion using Kafka adds an additional layer of competence, as real-world pipelines frequently involve event-driven architectures.
IBM’s examination also values familiarity with analytical modeling and data lifecycle management. Understanding ETL processes, data cleansing methodologies, and metadata management ensures that engineers can design resilient systems from ingestion to insight. Exposure to IBM’s Watson platform, including its AI-driven analytics capabilities, also enhances one’s comprehension of how Big Data supports advanced decision-making.
Additionally, candidates must practice troubleshooting in simulated cluster environments. Since the exam’s practical orientation demands diagnostic acuity, learners should familiarize themselves with monitoring tools, log interpretation, and performance metrics. Efficient cluster management and task scheduling knowledge often make the difference between a borderline and an outstanding performance.
The Broader Learning Mindset and Evolutionary Relevance
Beyond technical competence, success in the IBM Big Data Engineer exam depends on cultivating a cognitive perspective that values continuous learning, analytical reasoning, and conceptual integration. Big Data engineering is not a static discipline; it is an ever-evolving synthesis of data science, systems architecture, and computational strategy. Those who aspire to achieve mastery must approach the certification not merely as an endpoint but as an initiation into a more profound engagement with data ecosystems.
The global economy’s reliance on data-centric models has made data engineers the architects of digital transformation. By undertaking this certification, professionals align themselves with IBM’s long-standing tradition of innovation, scientific precision, and enterprise reliability. The C2090-101 credential embodies the convergence of theory and application, mathematics and infrastructure, algorithm and architecture.
In today’s landscape, where machine learning and artificial intelligence dominate discourse, the role of the data engineer as the enabler of intelligent systems becomes even more pivotal. Without reliable data pipelines and well-engineered architectures, even the most sophisticated models collapse under inconsistency or inefficiency. The IBM Big Data Engineer certification prepares individuals to ensure that the informational backbone of AI-driven enterprises remains robust and adaptive.
Through the disciplined pursuit of this certification, professionals refine not only their technical dexterity but also their analytical temperance, strategic foresight, and systemic literacy. This amalgamation of qualities transforms them into not just engineers but custodians of organizational intelligence. The IBM C2090-101 exam stands, therefore, not as a mere assessment but as a rite of passage into the sophisticated world of enterprise-scale data engineering.
Defining the Scope and Objectives of the IBM Big Data Engineer Certification
The IBM Big Data Engineer C2090-101 exam is meticulously designed to evaluate a candidate’s proficiency in orchestrating complex data ecosystems while demonstrating a nuanced understanding of both traditional and contemporary Big Data paradigms. The primary objective of this certification is to validate an individual’s capability to architect, implement, and maintain scalable data pipelines that accommodate vast volumes of structured, semi-structured, and unstructured information. Beyond technical execution, the certification emphasizes strategic alignment of data engineering initiatives with enterprise goals, ensuring that practitioners can contribute to intelligent decision-making frameworks within their organizations.
The examination measures competence across a spectrum of domains that are essential for real-world Big Data engineering. Candidates are expected to exhibit proficiency in distributed storage management, cluster computing, data ingestion methodologies, transformation and processing techniques, and analytical integration. Mastery of IBM-specific platforms, alongside foundational knowledge of open-source ecosystems such as Hadoop, Spark, and Kafka, is critical to demonstrating a holistic understanding of modern data architectures. The examination is constructed not merely as a knowledge assessment but as a simulation of the challenges faced by enterprise data engineers in high-stakes environments.
IBM envisages the C2090-101 exam as a bridge between academic comprehension and practical application. Candidates must exhibit the capacity to design robust, fault-tolerant systems capable of maintaining performance under fluctuating workloads. In addition, the certification underscores the importance of data governance, security, and compliance, reinforcing the ethical and operational responsibilities incumbent upon engineers in contemporary enterprises. By attaining this credential, professionals affirm their aptitude to function as pivotal contributors to data-driven strategies that shape organizational direction.
Architectural Competence in Distributed Systems
A significant domain within the IBM Big Data Engineer exam is architectural competence in distributed systems. Candidates must possess a deep understanding of how large-scale clusters operate, including the orchestration of data nodes, resource allocation, and task scheduling. The Hadoop Distributed File System (HDFS) forms the backbone of many IBM Big Data solutions, and proficiency in its internal mechanisms, such as block replication, failover management, and NameNode functionality, is essential. Understanding how data is segmented, stored, and retrieved across multiple nodes is fundamental to maintaining system resilience and optimizing performance.
Complementing HDFS is the examination of cluster computing frameworks, notably Apache Spark. Candidates are required to demonstrate mastery over Spark’s architecture, including the Resilient Distributed Dataset (RDD) abstraction, DataFrames, and the Catalyst optimizer. Emphasis is placed on the ability to implement parallelized computations effectively, manage memory efficiently, and ensure fault tolerance during large-scale processing tasks. Familiarity with job scheduling, DAG construction, and partitioning strategies further underlines the candidate’s ability to optimize complex workflows.
IBM’s platforms often integrate with other components such as Kafka for event streaming, enabling the construction of real-time data pipelines. Candidates are expected to comprehend message queuing, topic partitioning, and consumer-producer models, ensuring seamless ingestion and transformation of streaming data. The integration of batch and stream processing paradigms demonstrates an engineer’s capacity to accommodate diverse operational requirements while maintaining system integrity.
Data Ingestion and Integration Methodologies
Effective data ingestion is a foundational pillar of the IBM Big Data Engineer exam. Candidates must be conversant with various strategies for assimilating data from heterogeneous sources, including relational databases, cloud storage, IoT devices, web APIs, and legacy enterprise systems. The examination emphasizes the practical implementation of ingestion tools such as Sqoop for structured relational data, Flume for log aggregation, and Kafka for real-time messaging. Understanding the mechanics of these tools, including configuration parameters, fault tolerance strategies, and integration with downstream processing engines, is essential for constructing reliable data pipelines.
Integration extends beyond simple data movement to encompass transformation, cleansing, and harmonization. Candidates must demonstrate proficiency in ETL workflows, ensuring that ingested data adheres to quality standards and is suitable for analytical consumption. This involves knowledge of schema evolution, type coercion, and handling of missing or inconsistent values. IBM’s focus on enterprise applicability necessitates that engineers can design processes that seamlessly incorporate heterogeneous data into cohesive datasets for processing and analysis.
Storage Management and Optimization
The examination evaluates a candidate’s understanding of storage management within distributed environments. Engineers must be capable of selecting appropriate storage solutions based on access patterns, latency requirements, and scalability considerations. HDFS remains central to storage strategy, with candidates expected to understand block size optimization, replication factors, and storage tiering. Additionally, NoSQL databases such as Cassandra or IBM Cloudant are assessed for their applicability in managing semi-structured data, offering high availability and partition tolerance.
Storage optimization extends to indexing, partitioning, and lifecycle management, ensuring that systems maintain performance as data volumes expand. Candidates are required to understand compression techniques, data deduplication, and caching strategies to maximize throughput while minimizing resource consumption. This domain emphasizes the engineer’s ability to balance performance, cost, and reliability across diverse storage infrastructures.
Data Transformation and Processing Competencies
Processing and transforming data are critical aspects of the IBM Big Data Engineer C2090-101 exam. Candidates must demonstrate the ability to implement complex transformations using Spark, including joins, aggregations, and window functions. Understanding lazy evaluation, job execution plans, and optimization strategies ensures efficient resource utilization. Real-time processing capabilities, facilitated by Spark Streaming or IBM Streams, are examined to ensure that engineers can maintain low-latency pipelines for time-sensitive analytics.
Data transformation also encompasses enrichment, filtering, and validation processes. Candidates should be able to apply business logic and analytical calculations within distributed environments while ensuring data integrity. Integration of data processing with storage solutions, message queues, and analytical platforms is a recurrent theme, reflecting the interconnected nature of enterprise data systems.
Analytics Integration and Visualization
The examination places emphasis on the capacity to integrate engineering workflows with analytical and visualization tools. Engineers must be able to prepare datasets suitable for machine learning, predictive modeling, and business intelligence applications. Proficiency in IBM Cognos, Watson Studio, and other analytical suites is evaluated, emphasizing the seamless translation of raw data into actionable insights. This domain underscores the necessity for engineers to understand both the technical intricacies of data preparation and the strategic implications of analytical outputs.
Visualization, while not the primary focus, forms a component of the examination to ensure that engineers can communicate data findings effectively. Candidates are expected to be familiar with dashboard creation, reporting pipelines, and the visualization of streaming data, facilitating informed decision-making within organizations.
Security, Governance, and Compliance
Data governance and security are integral to the IBM Big Data Engineer exam. Candidates must comprehend access control mechanisms, encryption strategies, and compliance frameworks relevant to enterprise data management. Understanding authentication, authorization, and audit trails ensures that systems adhere to regulatory requirements and protect sensitive information. Knowledge of secure cluster configuration, privacy-preserving analytics, and data masking is essential for engineers tasked with safeguarding organizational data assets.
Compliance extends to both internal governance policies and external regulatory standards. IBM emphasizes the necessity for engineers to design workflows that ensure data lineage, traceability, and accountability. This capability is particularly critical in industries such as finance, healthcare, and government, where regulatory adherence is mandatory. The certification examines the candidate’s ability to implement and maintain robust governance structures within complex, distributed environments.
Performance Optimization and Troubleshooting
The IBM Big Data Engineer examination assesses practical capabilities in performance tuning and troubleshooting. Candidates must demonstrate proficiency in identifying bottlenecks, optimizing resource allocation, and balancing workloads across clusters. Understanding task scheduling, memory management, and I/O optimization is critical for maintaining high system performance. Engineers are also expected to diagnose failures, interpret logs, and implement recovery strategies in real-time operational contexts.
Practical competence extends to monitoring and instrumentation, allowing engineers to proactively detect anomalies and maintain system health. Familiarity with monitoring tools, metrics analysis, and alerting mechanisms is integral to ensuring continuous availability and efficiency. The exam tests not only technical knowledge but also the candidate’s ability to apply this knowledge to solve complex, emergent challenges within enterprise-grade Big Data infrastructures.
Real-World Applicability and Strategic Importance
The C2090-101 certification reinforces the engineer’s role in enabling organizational intelligence through reliable, scalable, and secure data systems. By demonstrating mastery over ingestion, storage, processing, analytics integration, security, and optimization, candidates affirm their readiness to manage the intricate data ecosystems upon which modern enterprises depend.
IBM’s examination framework mirrors the operational realities of data-intensive organizations, ensuring that certified engineers can contribute to strategic initiatives such as predictive analytics, AI integration, and digital transformation projects. Mastery of these competencies ensures that professionals are not only technically adept but also capable of aligning their engineering efforts with broader organizational objectives.
Approaching the Examination with a Structured Mindset
Preparation for the IBM Big Data Engineer C2090-101 exam requires an approach that blends intellectual discipline with immersive practical experience. The examination evaluates not only theoretical understanding but also applied proficiency in orchestrating complex data ecosystems. Aspirants must cultivate a mindset that prioritizes both analytical reasoning and hands-on experimentation, recognizing that the ability to navigate real-world scenarios is a distinguishing factor in achieving success.
The first step in preparation involves a comprehensive mapping of the exam’s domains, aligning study efforts with each competency area. Distributed systems, data ingestion, storage management, processing, analytics integration, security, and performance optimization constitute the core pillars. Candidates must assess their strengths and weaknesses across these areas, designing a study trajectory that ensures balanced mastery. This strategic alignment prevents fragmented learning and cultivates a cohesive understanding of the interconnected nature of enterprise data engineering.
Immersive Understanding of Distributed Systems
Candidates should dedicate significant effort to understanding the architectural principles underlying distributed computing environments. Hadoop and Spark form the backbone of IBM’s Big Data infrastructure, and familiarity with their internals is paramount. Comprehending the NameNode and DataNode functions within HDFS, the orchestration of YARN, and the mechanisms of fault tolerance equips candidates with the insight to design resilient data storage solutions. Spark’s in-memory computation, RDD abstractions, DataFrame operations, and Catalyst optimization require sustained study and repeated practice to internalize the nuances of performance tuning and parallelized computation.
Real-world applications often demand integration of batch and stream processing, making familiarity with Spark Streaming or IBM Streams indispensable. Candidates benefit from setting up controlled cluster environments to simulate task scheduling, resource allocation, and failure recovery. Such experiential learning allows them to translate theoretical principles into operational competency, reinforcing memory retention and procedural fluency.
Mastering Data Ingestion and Integration
Data ingestion remains a foundational competency in the C2090-101 exam. Engineers must acquire proficiency in assimilating data from a diverse array of sources, including relational databases, cloud storage, IoT sensors, and web APIs. Tools such as Sqoop, Flume, and Kafka are evaluated not simply for operational knowledge but for the capacity to orchestrate seamless, fault-tolerant pipelines. Understanding configuration parameters, error handling mechanisms, and integration patterns is critical for ensuring data quality and continuity across enterprise-scale workflows.
Integration extends into transformation and normalization processes. Candidates should practice designing ETL workflows that handle schema evolution, data cleansing, and validation, ensuring the ingestion pipeline supports downstream analytical operations. Applying business logic, enriching data streams, and harmonizing disparate datasets strengthens the engineer’s capability to maintain coherent, accurate information flows. Simulation of real-time ingestion scenarios, including event-driven architectures and high-velocity data streams, further hones operational acumen.
Storage Solutions and Optimization Techniques
Storage management is a nuanced domain requiring both theoretical knowledge and applied experimentation. Candidates must explore HDFS replication strategies, block size optimization, and data tiering, balancing redundancy and performance. NoSQL systems such as Cassandra and IBM Cloudant offer unique considerations for semi-structured data, emphasizing partitioning strategies, consistency models, and high availability configurations.
Optimization techniques extend to indexing, caching, and lifecycle management, all of which influence system responsiveness under heavy workloads. Practical exercises in compressing datasets, deduplicating redundant entries, and configuring storage policies reinforce understanding of both resource efficiency and performance metrics. Familiarity with hybrid architectures that integrate on-premise clusters with cloud storage solutions further equips candidates to manage complex enterprise data landscapes.
Processing and Transformation Proficiency
Proficiency in data transformation and processing is central to the examination. Candidates must navigate advanced Spark operations, including joins, aggregations, and window functions, while understanding the implications of lazy evaluation and execution planning. Real-time processing skills, facilitated by Spark Streaming or IBM Streams, enable engineers to construct low-latency pipelines critical for analytics in dynamic environments.
Transformation workflows often incorporate filtering, enrichment, and validation steps, ensuring data integrity and alignment with organizational requirements. Candidates should engage in repeated practice to develop an instinctive understanding of performance implications associated with various transformation strategies. Integrating these workflows with storage layers, ingestion pipelines, and analytical platforms ensures comprehensive operational competence.
Analytics Integration and Data Interpretation
Understanding the interface between engineered pipelines and analytical outputs is essential. Candidates must demonstrate the ability to prepare datasets for machine learning models, predictive analytics, and business intelligence tools. IBM platforms such as Watson Studio and Cognos provide practical applications, enabling engineers to validate their ability to translate raw data into actionable insights.
Visualization and reporting, although secondary to core engineering, form an important aspect of preparation. Candidates should practice constructing dashboards, visualizing streaming data, and generating reports that reflect the integrity and utility of processed information. This facet of preparation ensures that engineers are not merely custodians of data but facilitators of strategic insights, reinforcing the broader organizational impact of their work.
Security and Governance Considerations
Security and governance are non-negotiable components of the IBM Big Data Engineer examination. Candidates must understand authentication, authorization, encryption, and auditing mechanisms within distributed environments. Comprehending compliance requirements, data masking, and privacy-preserving analytics strategies ensures adherence to both corporate policies and regulatory standards.
Practical exercises in configuring secure clusters, managing access control lists, and implementing encryption protocols provide candidates with experiential knowledge essential for real-world application. By integrating security and governance principles into their preparation, aspirants cultivate a holistic understanding of enterprise data stewardship, aligning operational competence with ethical and regulatory obligations.
Performance Tuning and Operational Troubleshooting
Performance tuning and troubleshooting represent a critical domain in preparation. Candidates should study task scheduling, memory allocation, and I/O optimization to maximize cluster efficiency. Familiarity with monitoring tools, log analysis, and error diagnosis enables engineers to maintain system health and preempt operational disruptions.
Simulation of failure scenarios, including node outages, network latency, and resource contention, equips candidates with the problem-solving acuity required in professional environments. These exercises foster not only technical expertise but also analytical reasoning, as candidates must identify root causes and implement effective remediation strategies.
Structured Learning Resources and Methodologies
A disciplined approach to preparation involves the judicious selection of learning resources and study methodologies. IBM documentation, product manuals, and platform-specific whitepapers provide authoritative guidance on the technical intricacies of each domain. Supplementary materials, such as online tutorials, community forums, and interactive labs, enable practical experimentation and reinforcement of theoretical concepts.
Practice examinations and scenario-based assessments are invaluable for consolidating knowledge. Candidates should approach these exercises not merely as tests but as simulations of enterprise challenges, analyzing incorrect responses to identify conceptual gaps. Peer discussions, study groups, and mentorship can further enrich understanding, exposing candidates to diverse problem-solving approaches and fostering collaborative learning skills.
Cognitive Approaches to Exam Readiness
Beyond content mastery, cognitive strategies play a vital role in preparation. Time management, critical thinking, and pattern recognition are essential for navigating complex examination scenarios. Candidates benefit from iterative study cycles, alternating between theoretical review, practical exercises, and reflective analysis to reinforce comprehension.
Developing mental models of data pipelines, cluster architectures, and workflow orchestration enhances the ability to reason through novel problems presented in the exam. Visualization of processes, mapping interdependencies, and anticipating failure points strengthen both confidence and proficiency. This cognitive dimension complements technical skills, ensuring candidates are not only knowledgeable but also strategically agile in their application.
Integration of Practical Experience
The IBM Big Data Engineer examination rewards candidates who have engaged deeply with practical environments. Working on live projects, managing clusters, and implementing real-time pipelines provides experiential learning that transcends textbook understanding. Candidates who integrate hands-on experimentation into their preparation cultivate intuition for performance tuning, error diagnosis, and workflow optimization.
By simulating enterprise-scale data challenges, aspirants develop resilience and adaptability, qualities that are reflected in their examination performance. Such experiential learning also reinforces familiarity with IBM-specific tools and their integration within broader Big Data ecosystems, aligning preparation with the practical demands of certification.
Iterative Refinement and Knowledge Consolidation
Successful preparation requires iterative refinement of knowledge and continuous consolidation of skills. Candidates should regularly revisit foundational concepts, practice problem-solving exercises, and analyze complex scenarios to ensure enduring comprehension. Cross-domain integration, wherein ingestion, storage, processing, analytics, and governance principles are considered holistically, strengthens the ability to apply knowledge flexibly and accurately.
Reflection on practice exercises, coupled with targeted review of weak areas, enables focused improvement and reduces the likelihood of oversight during the examination. This cyclical approach to learning ensures that candidates achieve a depth and breadth of understanding commensurate with the rigorous standards of the IBM Big Data Engineer C2090-101 certification.
Operational Relevance of the IBM Big Data Engineer Certification
The IBM Big Data Engineer C2090-101 exam emphasizes the practical and operational relevance of data engineering within enterprise environments. Professionals certified in this domain are expected to translate theoretical principles into actionable strategies, enabling organizations to leverage vast and varied datasets effectively. The examination underscores the engineer’s ability to manage end-to-end data pipelines, optimize cluster performance, and integrate analytical frameworks, ensuring that data-driven decision-making is both accurate and timely.
Data engineering in real-world environments extends beyond the execution of predefined processes. Engineers are tasked with designing adaptive systems that can accommodate evolving business requirements, unpredictable data influx, and heterogeneous data sources. The IBM certification validates an individual’s capacity to implement scalable architectures, employing tools and methodologies that maintain operational continuity and performance integrity across diverse computing environments. This operational emphasis situates certified engineers at the confluence of technology, analytics, and strategic enterprise imperatives.
Advanced Data Ingestion and Streaming
In contemporary enterprises, data flows continuously from myriad sources, including transactional systems, IoT devices, social media, and third-party APIs. The IBM Big Data Engineer exam evaluates a candidate’s mastery of ingestion frameworks capable of assimilating this heterogeneous data. Tools such as Sqoop facilitate structured data migration from relational databases into distributed storage environments, whereas Flume enables the collection and transportation of high-volume log data. Kafka underpins real-time streaming pipelines, supporting event-driven architectures essential for instantaneous analytics.
Candidates are expected to understand the intricacies of topic partitioning, producer-consumer dynamics, and fault tolerance mechanisms within these streaming environments. In practice, data pipelines require fine-tuned orchestration, ensuring that batch and real-time processes coexist without contention. Engineers must also implement data validation, enrichment, and transformation steps in transit, preparing information for subsequent analytical operations. This combination of ingestion proficiency and transformation capability is crucial for maintaining the fidelity and utility of enterprise datasets.
Distributed Storage and Management Strategies
Efficient storage management is indispensable for sustaining performance across large-scale Big Data infrastructures. IBM engineers must navigate the complexities of HDFS, implementing block replication strategies, optimizing block sizes, and configuring storage tiers to balance latency, throughput, and reliability. NoSQL databases such as Cassandra, MongoDB, or IBM Cloudant are deployed for semi-structured and unstructured datasets, with engineers optimizing partitioning, consistency, and availability according to specific operational requirements.
Advanced storage strategies also involve lifecycle management, compression, and deduplication. Engineers must anticipate growth patterns, implement archival policies, and ensure that storage utilization aligns with performance objectives. Hybrid architectures integrating on-premise clusters with cloud resources, including IBM Cloud Pak for Data, demand proficiency in orchestrating storage across multiple environments while preserving data integrity and access efficiency.
Processing and Transformation in Distributed Environments
Data processing forms the backbone of analytical insight. The IBM Big Data Engineer exam assesses a candidate’s ability to implement complex transformations using distributed computing frameworks. Spark remains central to these operations, with its RDD and DataFrame abstractions facilitating parallelized computations. Mastery of joins, aggregations, window functions, and user-defined operations enables engineers to construct pipelines capable of processing high-volume datasets efficiently.
Real-time processing with Spark Streaming or IBM Streams allows organizations to react to events instantaneously, enabling operational intelligence in domains such as finance, telecommunications, and manufacturing. Candidates are expected to understand fault tolerance, checkpointing, and the orchestration of streaming micro-batches, ensuring that low-latency pipelines remain reliable under variable workloads. Transformation pipelines frequently incorporate enrichment, filtering, and validation steps, embedding business logic and ensuring consistency across distributed systems.
Analytical Integration and Cognitive Computing
A distinguishing feature of IBM’s Big Data ecosystem is the integration of data engineering with analytical and cognitive platforms. Certified engineers are expected to prepare datasets for predictive analytics, machine learning models, and AI-driven applications. IBM Watson Studio and Cognos provide environments for model development, testing, and deployment, with engineers ensuring that underlying pipelines deliver clean, structured, and timely data.
The capacity to translate raw datasets into actionable insights requires an understanding of statistical methods, feature engineering, and analytical modeling principles. Engineers must also facilitate visualization pipelines, generating dashboards and reports that communicate results effectively to stakeholders. This integration of engineering and analytics enables enterprises to harness data as a strategic asset, supporting decision-making across operational and managerial domains.
Security, Governance, and Compliance Frameworks
Enterprise data engineering is inseparable from security and governance considerations. IBM Big Data Engineer candidates are expected to implement access control mechanisms, encryption protocols, and auditing frameworks that safeguard sensitive information. Compliance with regulations such as GDPR, HIPAA, or internal corporate policies is fundamental, requiring engineers to maintain traceability, data lineage, and accountability across distributed systems.
Practical application involves configuring secure clusters, defining role-based access controls, and implementing data masking or anonymization techniques. Engineers must also monitor compliance continuously, integrating governance mechanisms within pipelines to prevent unauthorized access and ensure the reliability of operational data. This domain reinforces the ethical and strategic responsibilities incumbent upon certified engineers in managing enterprise information assets.
Performance Optimization and Resource Management
Maintaining optimal performance across distributed clusters is a core competency evaluated in the C2090-101 exam. Candidates must demonstrate an ability to analyze workloads, allocate resources judiciously, and implement tuning strategies for memory management, parallelization, and input-output operations. Engineers often encounter heterogeneous workloads with varying resource demands, requiring adaptive optimization strategies to ensure consistent performance.
Monitoring and instrumentation form a critical part of operational oversight. Candidates should become familiar with log analysis, metrics interpretation, and alerting mechanisms that enable proactive issue resolution. Performance optimization encompasses both preventive and corrective measures, including workload balancing, task scheduling refinement, and identification of bottlenecks in storage, network, or computational layers. These skills ensure that distributed pipelines maintain throughput, low latency, and high availability, even under peak operational stress.
Real-World Project Applications
IBM-certified Big Data Engineers routinely participate in projects that demand sophisticated orchestration of data infrastructure. In finance, pipelines may ingest high-frequency trading data, apply real-time transformations, and feed predictive models that inform algorithmic trading decisions. In healthcare, patient monitoring devices generate continuous streams requiring real-time anomaly detection and integration with electronic health records. In manufacturing, sensor networks produce telemetry data used to predict equipment failures and optimize maintenance schedules.
In each context, engineers must implement scalable, fault-tolerant systems that maintain data integrity and enable actionable insights. The certification ensures that candidates are proficient in translating these domain-specific requirements into robust technological solutions, integrating storage, processing, and analytics frameworks to serve organizational objectives effectively.
Advanced Toolsets and Ecosystem Integration
IBM’s Big Data ecosystem encompasses a variety of advanced tools that extend beyond fundamental Hadoop and Spark capabilities. Data orchestration platforms facilitate end-to-end workflow management, enabling automated execution, monitoring, and error handling. Stream processing engines support real-time analytics, while cognitive computing platforms integrate AI and machine learning into operational pipelines.
Candidates must understand the interdependencies among these tools, configuring systems to optimize throughput, reliability, and resource utilization. Practical familiarity with command-line operations, configuration tuning, cluster management, and orchestration strategies reinforces the ability to deploy and maintain sophisticated data environments in enterprise settings.
Troubleshooting and Operational Diagnostics
Effective engineers develop diagnostic acumen that allows rapid identification and resolution of system anomalies. IBM Big Data Engineer candidates are trained to interpret logs, detect performance degradation, and isolate root causes within distributed environments. Common issues include node failures, resource contention, network latency, and configuration inconsistencies. Engineers must design mitigation strategies that restore operational continuity while preserving data integrity.
Simulation of failure scenarios during preparation enhances problem-solving agility. Candidates refine procedural knowledge, improve response times, and develop an intuitive understanding of system behavior under stress. These competencies distinguish proficient engineers capable of sustaining high-performing data ecosystems from those who operate reactively, underscoring the practical value of certification in enterprise contexts.
Cognitive Strategies for Operational Excellence
Beyond technical mastery, cognitive strategies play a crucial role in the engineer’s ability to navigate complex data environments. Visualization of data flows, mapping interdependencies, and anticipating bottlenecks enable proactive decision-making. Iterative reasoning, scenario analysis, and pattern recognition equip engineers to adapt to emergent challenges, aligning operational activities with organizational priorities.
Certified engineers combine analytical acumen with strategic foresight, ensuring that data pipelines not only function efficiently but also support higher-level objectives such as predictive modeling, real-time decision-making, and enterprise-wide intelligence. This integration of cognitive and technical competencies forms the hallmark of IBM-certified Big Data engineering expertise.
Leveraging Authoritative Documentation and Technical Literature
A foundational element of preparation for the IBM Big Data Engineer C2090-101 exam involves comprehensive engagement with authoritative documentation and technical literature. IBM provides extensive manuals, whitepapers, and platform-specific guides that detail the architecture, configuration, and operational principles of its Big Data ecosystem. Candidates are encouraged to assimilate these materials to develop an intrinsic understanding of distributed storage mechanisms, cluster orchestration, Spark transformations, and real-time data processing pipelines.
Technical literature serves a dual purpose: it imparts both conceptual clarity and operational insight. By studying the intricacies of HDFS replication strategies, YARN resource scheduling, and Spark’s Catalyst optimizer, candidates cultivate the analytical framework necessary to approach complex examination scenarios. These resources also elucidate best practices for data ingestion, pipeline integration, and governance, providing a practical orientation that aligns closely with enterprise requirements. Persistent engagement with documentation fosters both retention and adaptability, enabling candidates to navigate emergent problems during the exam confidently.
Utilizing Practice Labs for Experiential Learning
Hands-on practice constitutes a critical dimension of exam preparation. IBM-certified candidates benefit from setting up controlled lab environments that simulate enterprise-grade clusters. These labs facilitate experiential learning, allowing aspirants to implement, test, and troubleshoot ingestion pipelines, transformation workflows, and storage configurations. Practical experimentation with tools such as Sqoop, Flume, Kafka, Spark, and NoSQL databases enables engineers to internalize procedural nuances and performance optimization techniques.
Lab exercises reinforce theoretical understanding by translating abstract concepts into operational competence. For example, configuring a multi-node Spark cluster to process streaming telemetry data allows candidates to explore task scheduling, memory management, and checkpointing in real-time. Similarly, constructing fault-tolerant HDFS structures teaches replication strategies, block management, and data recovery protocols. Such exercises enhance not only technical proficiency but also cognitive agility, equipping candidates to reason through complex, novel scenarios presented in the examination.
Mock Exams as Diagnostic and Refinement Tools
Mock examinations serve as both diagnostic instruments and mechanisms for knowledge consolidation. Candidates are encouraged to undertake multiple iterations of timed practice tests that replicate the structure and cognitive demands of the C2090-101 exam. These exercises reveal knowledge gaps, identify areas requiring reinforcement, and familiarize candidates with the logical sequencing of problem-solving required for distributed data engineering scenarios.
A strategic approach to mock exams involves not merely completing questions but conducting a detailed analysis of errors and alternative solutions. By dissecting incorrect responses, aspirants uncover misconceptions, refine conceptual frameworks, and develop strategies for efficient problem resolution. Repeated engagement with mock tests also cultivates time management skills, enhancing the ability to allocate appropriate durations to each domain and ensuring that all questions are addressed with deliberate attention and accuracy.
Integration of Study Groups and Collaborative Learning
Collaborative learning offers an additional dimension of preparation, leveraging peer insight and shared problem-solving experience. Study groups allow candidates to discuss complex concepts, exchange practical strategies, and simulate real-world project scenarios collaboratively. Interaction with peers exposes engineers to alternative perspectives, diverse methodologies, and nuanced operational tactics that may not emerge through solitary study.
Such collaborative engagements also facilitate critical discussion on distributed system behavior, performance tuning, and workflow orchestration. By articulating explanations and debating optimal solutions, candidates reinforce their comprehension, solidify memory retention, and enhance cognitive flexibility. Peer collaboration, particularly when structured around practical labs and scenario-based exercises, integrates theoretical understanding with applied proficiency, aligning preparation with the pragmatic orientation of the IBM Big Data Engineer certification.
Strategic Prioritization of Study Domains
Effective preparation demands a disciplined prioritization of study domains, allocating effort according to both personal competency and examination weighting. Candidates are encouraged to first consolidate foundational knowledge of distributed systems, storage architectures, and cluster management. Mastery of HDFS, YARN, and Spark transformations establishes the scaffolding upon which more advanced competencies—such as real-time processing, analytics integration, and security governance—can be developed.
Once foundational domains are secured, aspirants should focus on pipeline construction, performance optimization, and troubleshooting techniques. Simulated scenarios involving data ingestion failures, node outages, or resource contention cultivate resilience and practical reasoning. Subsequent emphasis on analytics integration, visualization, and cognitive computing ensures that candidates can translate engineered pipelines into actionable organizational insights, reflecting the holistic expectations of the C2090-101 examination.
Conceptual Mapping and Knowledge Frameworks
Creating conceptual maps and knowledge frameworks enhances cognitive organization and facilitates rapid retrieval of complex information during preparation. Candidates are advised to develop interconnected diagrams that trace data flows from ingestion to storage, transformation, processing, and analytical visualization. This mapping reinforces understanding of dependencies, fault propagation, and optimization strategies within distributed environments.
Frameworks also serve as cognitive scaffolds, allowing candidates to reason systematically through novel scenarios. By visualizing cluster hierarchies, task orchestration, and pipeline interconnections, engineers can anticipate operational challenges and devise strategic solutions. This approach strengthens both memory retention and analytical agility, enabling aspirants to navigate the intricate multi-domain questions characteristic of the IBM Big Data Engineer exam.
Targeted Engagement with Online Resources and Community Platforms
Digital platforms, online tutorials, and professional forums offer an expansive repository of practical insights, best practices, and experiential learning opportunities. Candidates may access tutorials demonstrating advanced Spark operations, Kafka stream configurations, or NoSQL optimization techniques. Forums and communities facilitate discussion of examination-like scenarios, enabling candidates to benchmark strategies, clarify doubts, and assimilate practical knowledge from experienced engineers.
Engagement with these resources complements formal documentation and lab exercises, providing contextual understanding of industry-standard approaches, emerging tools, and contemporary best practices. This integration ensures that candidates are conversant not only with IBM-specific tools but also with broader ecosystem trends, enhancing both examination readiness and professional adaptability.
Cognitive Reinforcement through Iterative Practice
Iterative practice reinforces cognitive assimilation of both theoretical principles and procedural skills. Candidates should cycle through documentation review, lab exercises, mock exams, and scenario analysis repeatedly, refining comprehension and procedural fluency with each iteration. This recursive approach consolidates learning, reduces cognitive fatigue during examination conditions, and cultivates confidence in the application of complex data engineering principles.
Iterative practice also promotes adaptive reasoning, enabling candidates to transfer knowledge across domains. For example, understanding fault tolerance in HDFS informs approaches to Spark streaming reliability, while ingestion challenges encountered in batch pipelines can enhance problem-solving for real-time processing scenarios. The synergy created through iterative engagement strengthens holistic competency, aligning preparation with the multifaceted nature of the IBM Big Data Engineer examination.
Time Management and Exam Simulation
Time management is a critical component of examination readiness. Candidates should practice completing scenario-based questions within prescribed time constraints, developing strategies to allocate attention proportionately across diverse domains. Exam simulation, conducted under timed conditions, fosters situational awareness, reduces anxiety, and habituates candidates to the cognitive demands of high-stakes assessment.
Simulated examinations also allow aspirants to practice strategic decision-making, such as identifying high-yield questions, prioritizing complex problem-solving, and efficiently navigating multi-step scenarios. Coupled with iterative review and error analysis, this methodology enhances both accuracy and procedural efficiency, equipping candidates to perform confidently under examination conditions.
Integrating Real-World Scenario Analysis
The IBM Big Data Engineer exam emphasizes practical, scenario-based problem-solving. Preparation benefits from engagement with real-world case studies, project simulations, and operational problem analysis. Candidates should examine workflows encompassing end-to-end data pipelines, integrating ingestion, storage, transformation, processing, analytics, governance, and performance optimization considerations.
Scenario analysis cultivates anticipatory reasoning, enabling candidates to identify potential bottlenecks, optimize resource allocation, and preempt operational failures. Engineers learn to map theoretical principles onto practical challenges, bridging the gap between conceptual understanding and operational execution. This methodology aligns closely with the examination’s emphasis on applied proficiency, ensuring that preparation mirrors real-world expectations.
Continuous Knowledge Refinement and Self-Assessment
Ongoing refinement of knowledge is essential for enduring examination readiness. Candidates should engage in self-assessment exercises, revisiting weak domains, updating practical labs, and reviewing conceptual frameworks regularly. Reflection on performance in mock exams, lab exercises, and scenario analyses informs targeted study interventions, reinforcing mastery and mitigating gaps.
This continuous cycle of assessment, practice, and refinement ensures comprehensive readiness, encompassing both technical expertise and cognitive agility. By iteratively strengthening knowledge and procedural fluency, candidates position themselves to navigate the IBM Big Data Engineer C2090-101 examination with confidence, precision, and operational insight.
Translating Certification into Career Advantage
Earning the IBM Big Data Engineer C2090-101 certification represents a significant milestone in a professional’s data engineering trajectory. The credential validates expertise in distributed computing, large-scale data processing, and enterprise-grade analytics integration, providing tangible proof of competence to potential employers. Professionals equipped with this certification are often positioned for roles involving the design, implementation, and maintenance of robust data pipelines, the optimization of storage and processing architectures, and the facilitation of advanced analytical operations within diverse industries.
Organizations increasingly rely on certified engineers to transform raw data into actionable intelligence, support predictive modeling, and enable real-time decision-making. The C2090-101 credential signals not only technical proficiency but also strategic understanding of enterprise data operations, making certified professionals attractive candidates for leadership positions in data-intensive projects. Roles may include senior data engineer, solutions architect, Big Data consultant, or analytics infrastructure lead, each leveraging the competencies validated through rigorous examination and practical application.
Industry Integration and Cross-Domain Relevance
The IBM Big Data Engineer certification equips professionals to operate seamlessly across multiple industrial domains. In finance, certified engineers orchestrate pipelines that ingest high-frequency transactional data, detect anomalies, and feed predictive risk models. In healthcare, they manage patient monitoring systems, integrating sensor streams with electronic health records to enable proactive interventions. In manufacturing, engineers leverage sensor telemetry and operational data to predict maintenance requirements, optimize production workflows, and enhance supply chain visibility.
Beyond domain-specific applications, the certification fosters versatility in hybrid technology ecosystems. Engineers become adept at integrating on-premise clusters with cloud infrastructures, managing distributed storage solutions, and ensuring interoperability between Hadoop, Spark, and IBM’s proprietary platforms. This cross-domain competence positions certified professionals as pivotal enablers of digital transformation initiatives, capable of adapting their skill set to evolving technological landscapes and organizational requirements.
Enabling Advanced Analytical and Cognitive Solutions
Certified IBM Big Data Engineers play a crucial role in the deployment of advanced analytics and cognitive solutions. Their expertise ensures that data pipelines deliver clean, structured, and timely information to AI and machine learning platforms. By preparing datasets for predictive analytics, natural language processing, and anomaly detection, engineers directly contribute to enhanced decision-making and strategic foresight.
Integration with platforms such as IBM Watson Studio allows certified professionals to facilitate model training, testing, and deployment, while ensuring that analytical insights are operationalized within enterprise applications. Engineers also design workflows that maintain data integrity, enforce governance policies, and optimize resource allocation, thereby enabling organizations to realize the full potential of AI-driven solutions.
Leadership and Strategic Influence in Data Operations
Beyond technical execution, IBM Big Data Engineer certification fosters leadership capabilities within data operations. Certified professionals often assume roles that influence strategic planning, project prioritization, and technology adoption. Their deep understanding of distributed systems, ingestion frameworks, and analytics integration allows them to guide teams, optimize workflows, and establish best practices across projects.
By demonstrating proficiency in troubleshooting, performance tuning, and governance compliance, certified engineers can mentor junior staff, define operational standards, and contribute to organizational policies for data management. Their influence extends beyond day-to-day engineering tasks to encompass broader operational and strategic objectives, reinforcing the value of certification as a conduit for professional growth and recognition.
Opportunities for Global Mobility and Recognition
The IBM Big Data Engineer credential carries international recognition, enhancing career mobility and expanding professional opportunities. Certified engineers are qualified to participate in multinational projects, contribute to global enterprise data initiatives, and align with industry standards that transcend regional boundaries. The certification serves as a marker of credibility and competence in competitive labor markets, enabling professionals to pursue roles in consultancy, project leadership, and strategic advisory capacities.
Global applicability also extends to emerging technological hubs and digital transformation initiatives, where enterprises seek engineers capable of designing scalable, secure, and high-performing data ecosystems. Certified professionals may engage in projects spanning cloud migrations, data modernization efforts, and AI integration, providing both career advancement and exposure to cutting-edge technological environments.
Continuous Learning and Career Advancement
IBM Big Data Engineer certification establishes a foundation for continuous learning and skill augmentation. The rapidly evolving Big Data landscape necessitates ongoing engagement with emerging tools, frameworks, and methodologies. Certified professionals are positioned to advance into specialized domains, such as real-time analytics, cloud-native data architecture, or AI-driven data engineering, leveraging foundational competencies validated through the C2090-101 examination.
The certification encourages adoption of lifelong learning practices, including exploration of advanced IBM platforms, experimentation with novel distributed computing paradigms, and participation in professional communities. By maintaining currency with industry trends and technological innovations, certified engineers enhance their employability, sustain professional relevance, and position themselves for senior technical or managerial roles within data-driven enterprises.
Entrepreneurial and Consulting Opportunities
In addition to organizational roles, the IBM Big Data Engineer credential opens avenues for entrepreneurial and consulting engagements. Certified professionals may establish consultancies, advise enterprises on data strategy, or design customized solutions for clients seeking to optimize Big Data infrastructures. The certification signals authoritative expertise, facilitating trust-building with clients and stakeholders, and providing a competitive advantage in consultancy markets.
Entrepreneurial ventures may encompass designing data pipelines for start-ups, implementing AI-driven operational solutions, or managing cloud-based analytics environments. Certified engineers can also contribute to knowledge dissemination, offering training, workshops, and mentorship programs, thereby shaping the next generation of data engineering professionals.
Professional Networks and Knowledge Ecosystems
Certification enhances access to professional networks and knowledge ecosystems. IBM-certified engineers can participate in forums, collaborative platforms, and industry events that foster exchange of insights, best practices, and emerging technological innovations. Engagement with these networks provides opportunities for skill enhancement, collaborative problem-solving, and awareness of global trends in Big Data engineering.
By interacting with peers and industry leaders, certified professionals gain exposure to diverse methodologies, project experiences, and cutting-edge applications. This engagement enriches professional expertise, fosters continuous improvement, and reinforces the strategic value of certification in maintaining both operational and career excellence.
Career Trajectories and Long-Term Impact
Professionals holding the IBM Big Data Engineer C2090-101 certification often experience accelerated career trajectories. Their validated competencies in distributed systems, data pipeline orchestration, analytics integration, and performance optimization enable them to assume senior engineering, architecture, and leadership roles. Over time, certification contributes to career stability, professional credibility, and the capacity to influence organizational data strategies.
Long-term impact includes the ability to lead enterprise-scale projects, drive innovation in data-driven decision-making, and integrate advanced analytical frameworks into organizational processes. The combination of technical expertise, strategic insight, and professional recognition ensures that certified engineers remain valuable assets within dynamic, data-centric industries.
Strategic Professional Development
Certified professionals are encouraged to adopt strategic professional development practices to maximize the benefits of IBM Big Data Engineer certification. This includes targeted skill expansion, engagement with advanced IBM platforms, and participation in specialized training initiatives. By aligning career objectives with emerging technological trends, professionals enhance their marketability, maintain operational competence, and position themselves for roles that blend technical mastery with strategic influence.
Continuous engagement with professional communities, industry literature, and project-based learning ensures that engineers remain at the forefront of technological advancement. Certification, therefore, serves as both an initial benchmark of capability and a springboard for sustained professional evolution, enabling long-term career resilience and growth.
Conclusion
The IBM Big Data Engineer C2090-101 certification embodies a comprehensive validation of technical expertise, operational proficiency, and strategic understanding in the domain of enterprise data engineering. It equips professionals to design, implement, and maintain robust, scalable data pipelines, integrate analytical and cognitive frameworks, and ensure governance and compliance across complex infrastructures. Certified engineers translate these competencies into career advancement, leadership opportunities, and global recognition, positioning themselves as indispensable contributors to data-driven enterprises.
Through continuous engagement with practical labs, scenario-based learning, and professional networks, certified professionals reinforce their skills and adapt to evolving technological landscapes. The credential not only affirms mastery of IBM Big Data technologies but also fosters cognitive agility, strategic foresight, and operational excellence. Consequently, the IBM Big Data Engineer certification serves as a pivotal enabler of professional growth, organizational impact, and enduring relevance in the fast-evolving world of Big Data engineering.

