
Certification: IBM Certified Data Engineer - Big Data
Certification Full Name: IBM Certified Data Engineer - Big Data
Certification Provider: IBM
Exam Code: C2090-101
Exam Name: IBM Big Data Engineer
Product Screenshots
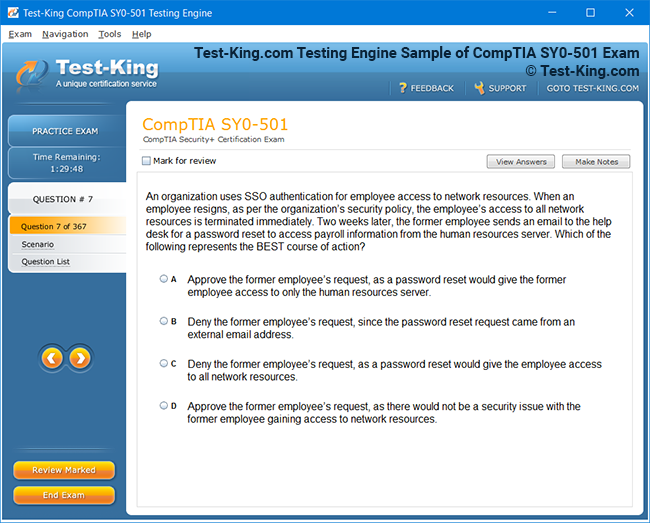
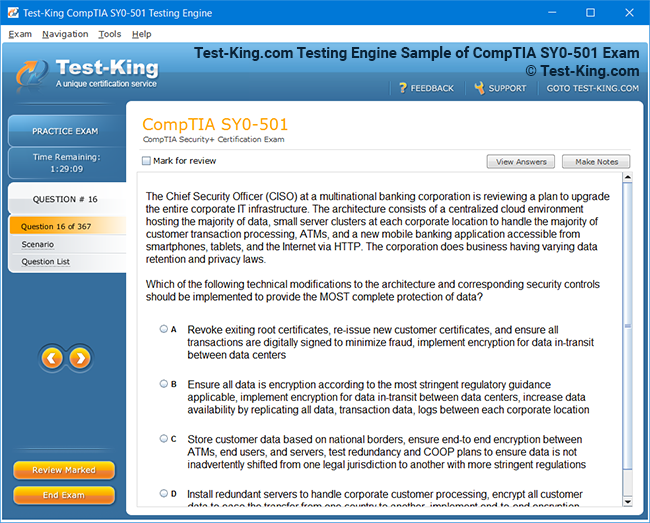
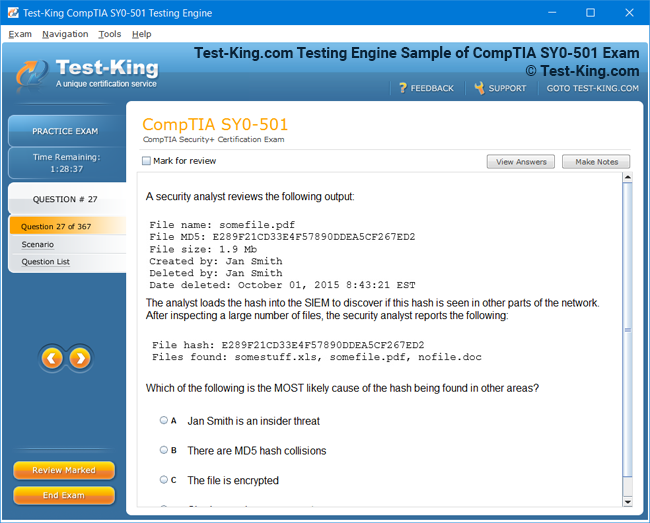
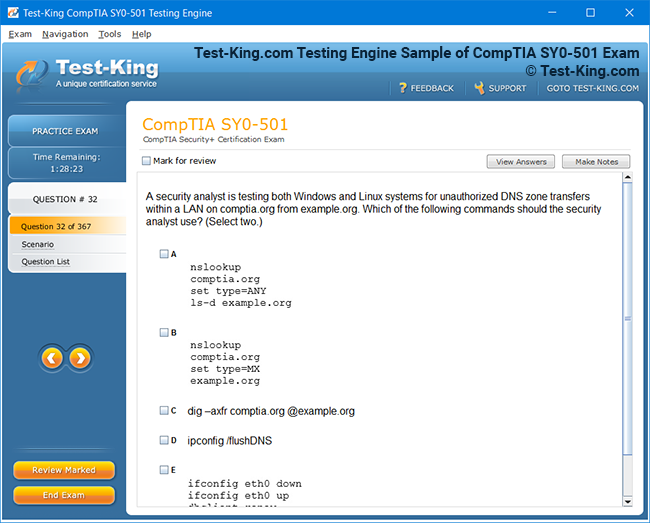
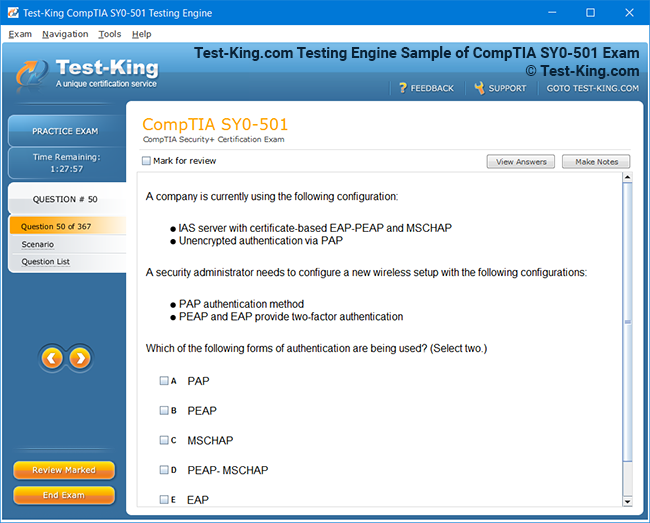
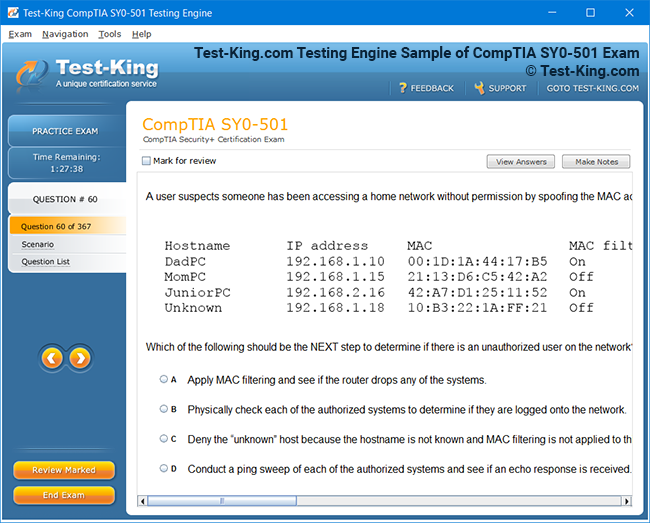
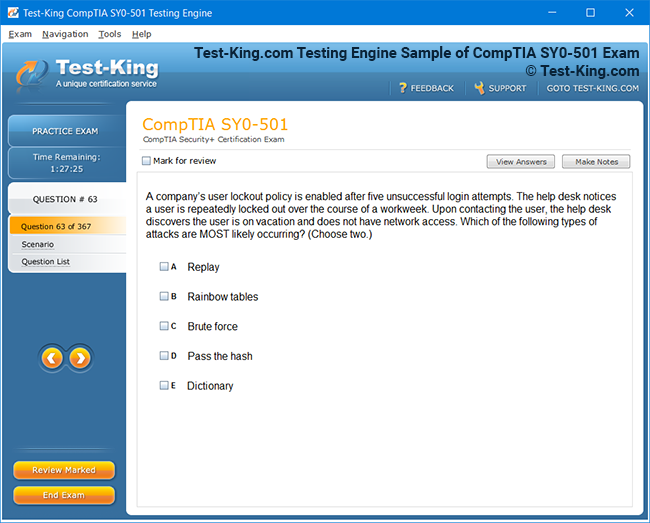
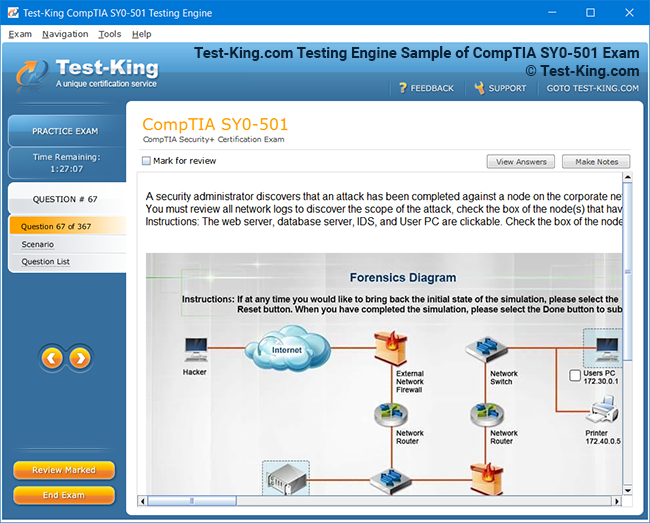
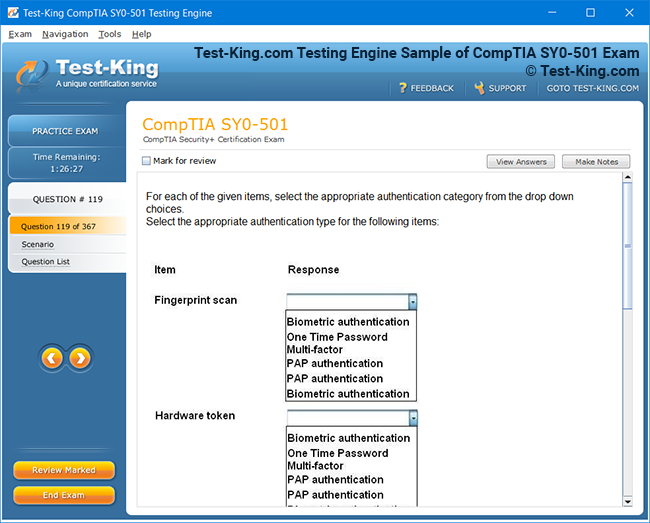
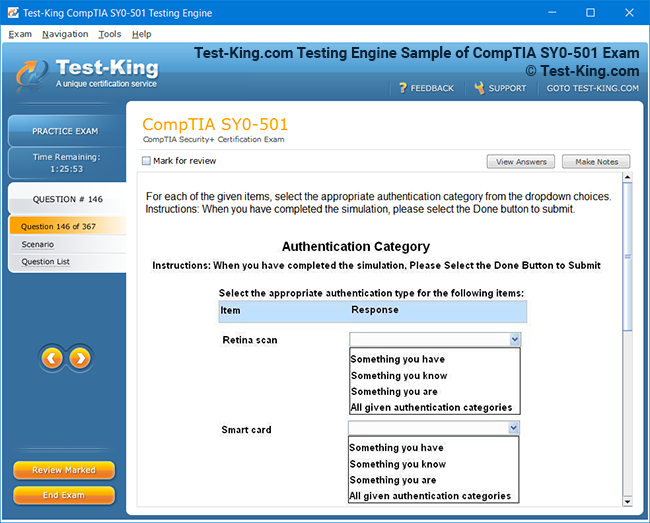
Accelerated Learning and Certification in IBM Certified Data Engineer Big Data
In the rapidly evolving landscape of data engineering, professionals are expected to possess a robust understanding of both foundational and auxiliary software tools. A concentrated focus on primary systems such as BigInsights, BigSQL, Hadoop, and Cloudant provides a solid footing for managing and analyzing vast datasets. BigInsights, a comprehensive platform for big data analytics, enables the orchestration of complex data workloads and the execution of scalable queries. It allows engineers to perform data mining, analytical processing, and reporting, establishing a versatile environment for enterprise-grade insights. Complementing this, BigSQL integrates seamlessly to facilitate structured querying within distributed frameworks, allowing practitioners to execute complex SQL queries over massive datasets with efficiency and reliability. Hadoop, an open-source ecosystem, forms the backbone of many large-scale data infrastructures, providing distributed storage and processing capabilities. Its architecture ensures redundancy, fault tolerance, and parallel processing, which are indispensable for high-volume, high-velocity data operations. Cloudant, a NoSQL database, introduces flexibility by accommodating unstructured and semi-structured data, making it ideal for applications where data schema evolves rapidly or where diverse data types converge.
Mastering Core and Peripheral Software Tools
Alongside these core systems, peripheral tools augment the data engineering process, addressing integration, governance, security, and operational monitoring. Information Server plays a pivotal role in metadata management, enabling the tracking of data lineage and ensuring transparency across data workflows. Integration capabilities, including balanced optimization for Hadoop and JAQL pushdown, enhance system performance by streamlining query execution and minimizing resource consumption. Data governance frameworks ensure data quality, consistency, and compliance with regulatory requirements, safeguarding enterprises against potential anomalies or breaches. Security features embedded within BigInsights provide multi-layered protection, encompassing authentication, authorization, and encryption, while supplementary tools like Guardium monitor and detect unauthorized activities across datasets. DataClick, both for BigInsights and anticipated for Cloudant, facilitates the extraction of operational data into analytical environments, enabling timely decision-making through sophisticated analytics. Additionally, BigMatch offers solutions aimed at creating a unified view of disparate datasets, thereby enhancing accuracy and comprehensiveness in enterprise reporting.
Analytics tools such as SPSS and BigSheets empower engineers to derive meaningful insights from structured and semi-structured datasets. In-memory analytics accelerates computations by storing datasets directly in memory, circumventing latency associated with disk-based operations. Meanwhile, database solutions like Netezza and DB2 BLU enhance query performance through columnar storage, data compression, and parallel processing, which collectively improve throughput and reduce execution times. Graph databases provide specialized structures for representing and analyzing relationships within data, facilitating complex network analyses and enabling advanced machine learning applications, including System ML, which allows scalable machine learning model deployment directly within the big data ecosystem. Streams and streaming data concepts introduce near-real-time processing capabilities, essential for scenarios that require immediate analytics or rapid anomaly detection. Altogether, these tools and methodologies equip data engineers to handle high-volume, high-variety, and high-velocity data environments with agility and precision.
Examination Preparation and Competency Domains
As part of an accelerated training regimen, candidates undertake a rigorous examination designed to validate their proficiency in big data engineering. The assessment comprises multiple-choice questions covering domains such as data loading, security, architecture and integration, performance and scalability, and data preparation, transformation, and export. Mastery of data loading techniques entails understanding the mechanisms for ingesting, cleansing, and distributing data efficiently across distributed environments. This involves balancing system throughput, minimizing latency, and ensuring data fidelity throughout the pipeline. Data security competency encompasses authentication protocols, user access control, monitoring, and the safeguarding of personally identifiable information. Engineers must be adept at implementing secure data transfer, enforcing role-based access, and applying continuous monitoring to detect and respond to anomalies. Architectural and integration skills focus on designing systems that seamlessly incorporate multiple tools and platforms, considering physical and logical architectures, cluster management, network topology, and critical interfaces. Engineers must also understand how to scale distributed systems, optimize performance, and ensure high availability under varying workloads.
Performance and scalability assessment evaluates the ability to tune databases, optimize queries, and manage workloads across a heterogeneous ecosystem. Candidates learn how to exploit parallelism, caching strategies, and indexing techniques to achieve desired throughput while minimizing resource consumption. Equally vital is the domain of data preparation, transformation, and export, which encompasses converting raw data into analyzable formats, integrating heterogeneous datasets, performing aggregations, and preparing exports for downstream analytical tools. Knowledge in these areas ensures that the engineer can bridge the gap between raw data and actionable insights, ultimately supporting business intelligence and operational analytics initiatives.
Recommended Prerequisites for Effective Learning
Prior to engaging in an intensive data engineering curriculum, learners are advised to acquire foundational knowledge spanning multiple facets of the data environment. Understanding the architecture of the data layer, potential points of risk, and areas prone to latency or bottlenecks provides a strategic perspective for addressing performance and reliability challenges. Translating functional requirements into actionable technical specifications allows for coherent system design, while familiarity with logical and physical architecture enables engineers to map solutions efficiently onto infrastructure. Cluster management skills, along with network configuration expertise, underpin the operational reliability of distributed systems. Data modeling knowledge, including entity relationships, normalization, and schema evolution strategies, supports scalable database designs capable of accommodating growth and change.
Non-functional requirements such as high availability, fault tolerance, disaster recovery, and data replication must be anticipated to maintain service continuity. Engineers must also evaluate performance metrics, including query efficiency, workload distribution, and resource utilization, to ensure that systems operate within acceptable thresholds. Best practices in data movement, manipulation, and storage are critical, particularly when handling cloud-based datasets, where considerations around latency, consistency, and cost efficiency come into play. Data ingestion strategies, storage choices, querying methodologies, and governance protocols all converge to form a holistic approach to managing enterprise-scale information systems. Additionally, implementing security measures, including LDAP authentication, user role management, and continuous monitoring, ensures that sensitive information remains protected against internal and external threats.
Learning Environment and Support
An accelerated training environment provides learners with an immersive experience designed to maximize knowledge retention and practical application. Participants engage in extended instructor-led sessions, typically exceeding twelve hours per day, which fosters deep understanding of core and auxiliary tools. Around-the-clock lab access allows for hands-on experimentation, reinforcing theoretical concepts through applied practice. Digital courseware complements live instruction, providing reference material and exercises that support independent exploration of complex topics. Residential learners benefit from accommodation and continuous access to meals and beverages, creating a distraction-free setting conducive to focused study. Practice tests and on-site examination opportunities simulate the conditions of formal assessment, helping candidates gauge their readiness and refine their approach.
The combination of intensive instruction, uninterrupted lab access, and structured assessments accelerates the learning curve, enabling participants to absorb intricate concepts in a condensed timeframe. Learners benefit from exposure to multiple learning modalities, including visual demonstrations, auditory explanations, and tactile engagement with systems. This multimodal approach caters to diverse cognitive styles, enhancing comprehension and retention. The curriculum also integrates real-world scenarios, ensuring that knowledge is directly applicable to enterprise-grade projects. Participants learn not only to operate software but also to make informed architectural decisions, optimize performance, and implement security measures in complex, distributed data environments.
Advantages of Accelerated Big Data Training
The advantages of undertaking concentrated training in big data engineering extend beyond mere certification. Rapid exposure to a comprehensive toolset allows engineers to gain proficiency in both foundational and emerging technologies, equipping them for immediate application in professional environments. The immersive schedule accelerates competency acquisition, reducing the time typically required to develop equivalent expertise through conventional learning approaches. A holistic, all-inclusive format, encompassing course materials, examinations, and logistical support, alleviates ancillary burdens, allowing learners to focus entirely on skill acquisition.
Training within a highly recognized institution further enhances professional credibility, as recognition in the industry signals adherence to high standards and proven educational methodologies. Learners are immersed in an ecosystem of peers and instructors who are experienced in enterprise-level big data solutions, facilitating knowledge exchange and collaborative problem-solving. Continuous practice and assessment cycles reinforce understanding, helping participants internalize best practices for data ingestion, storage, querying, and governance. Exposure to both structured and unstructured data environments, combined with instruction in advanced analytical tools and machine learning techniques, ensures that engineers are prepared to navigate the intricacies of modern data ecosystems with confidence and agility.
Enhancing Efficiency Through Core and Complementary Tools
In contemporary data engineering, mastery of both principal and complementary software environments is essential for handling complex, high-volume datasets with agility. BigInsights forms the cornerstone for orchestrating large-scale analytical operations, allowing data engineers to manage multifaceted workloads, execute distributed queries, and derive actionable insights from heterogeneous data sources. Its architecture is designed to support batch processing, real-time analytics, and integration with other enterprise systems, providing a robust platform for scalable data management. BigSQL complements these capabilities by offering a sophisticated querying environment within distributed systems. Its capacity to process structured queries across large, partitioned datasets ensures efficiency, minimizes computational overhead, and reduces latency in data retrieval operations. Hadoop, a ubiquitous open-source framework, provides the underlying infrastructure for distributed storage and parallel computation. Its design enables redundancy, fault tolerance, and horizontal scaling, which are indispensable for enterprise-grade applications. Cloudant introduces the flexibility of a NoSQL paradigm, allowing for storage and retrieval of unstructured or semi-structured data, which is increasingly prevalent in modern analytical scenarios.
Supplementary tools enhance the efficacy of the data engineering workflow, addressing integration, security, and governance challenges. Information Server facilitates metadata management and data lineage tracking, offering transparency and auditability across complex workflows. Integration mechanisms, including balanced optimization for Hadoop and JAQL pushdown, optimize query execution and resource utilization, ensuring seamless interoperability between components. Data governance frameworks safeguard data integrity, enforce compliance, and maintain consistency, reducing operational risk. Security features within BigInsights, augmented by monitoring solutions such as Guardium, protect sensitive data through layered authentication, role-based access control, and real-time surveillance. DataClick facilitates the transfer of operational data into analytical environments, enabling timely insights, while BigMatch strives to consolidate multiple data sources into a coherent, unified view. These complementary tools collectively enhance the accuracy, reliability, and utility of big data ecosystems.
Advanced analytics capabilities such as in-memory computations, SPSS, and BigSheets enable faster processing and visualization of data. In-memory analytics accelerates performance by storing active datasets in volatile memory, circumventing the latency associated with disk-based operations. Netezza and DB2 BLU employ columnar storage, indexing, and parallel processing to optimize query execution and throughput, further enhancing system performance. Graph databases allow engineers to explore relationships and dependencies within datasets, facilitating advanced network analytics and sophisticated pattern recognition. System ML and other machine learning frameworks empower predictive modeling and automated decision-making directly within the big data infrastructure. Streams and streaming concepts support near-real-time data ingestion and processing, allowing enterprises to respond swiftly to evolving operational conditions. Collectively, these tools equip engineers to handle datasets of enormous scale, high velocity, and complex variety with precision and efficiency.
Examination Preparation and Domain Expertise
The accelerated learning pathway emphasizes both practical proficiency and theoretical understanding, culminating in a structured examination that assesses competence across critical domains. Data loading is a primary focus, encompassing techniques for ingesting, cleaning, and distributing vast datasets efficiently within distributed environments. This requires an understanding of system throughput, resource allocation, and error mitigation strategies. Data security constitutes another essential area, with emphasis on implementing authentication protocols, managing user permissions, monitoring access, and safeguarding personally identifiable information. Candidates are expected to understand best practices for data protection, including continuous auditing and proactive threat detection.
Architecture and integration skills are evaluated in terms of designing coherent, scalable systems that interconnect diverse tools while maintaining reliability and performance. Engineers must navigate the complexities of logical and physical architectures, cluster management, and network topology to ensure robust system operation. Performance and scalability competencies are tested through scenarios requiring query optimization, resource allocation, and workload management. Practitioners must demonstrate proficiency in leveraging parallelism, caching, indexing, and partitioning to maximize efficiency and throughput. Data preparation, transformation, and export are equally critical, as engineers convert raw data into structured, analyzable formats, integrate heterogeneous sources, and prepare exports for downstream analytical tools. Mastery in these domains ensures that engineers can transform complex data into actionable insights, supporting strategic decision-making and operational efficiency.
Foundational Knowledge for Effective Data Engineering
Preparation for accelerated training demands familiarity with multiple aspects of the data ecosystem. Understanding the architecture and potential risk areas within the data layer provides a strategic foundation for anticipating performance bottlenecks and reliability concerns. Translating functional requirements into technical specifications enables coherent system design, while competence in mapping logical architectures onto physical infrastructure ensures operational feasibility. Cluster management and network configuration are critical for maintaining distributed system stability, while expertise in data modeling supports scalable schema design and evolution.
Non-functional requirements, including high availability, fault tolerance, disaster recovery, and data replication, are integral to robust system design. Performance monitoring, encompassing query efficiency, workload balancing, and resource utilization, ensures that data environments operate within acceptable thresholds. Data movement, storage, and manipulation strategies are crucial for managing both on-premise and cloud-based datasets, where latency, cost, and consistency considerations intersect. Engineers must also address governance and security protocols, implementing LDAP authentication, role-based access, and continuous monitoring to protect sensitive information. Comprehensive knowledge in these areas enables practitioners to design, deploy, and maintain resilient, high-performance big data ecosystems capable of supporting enterprise-scale operations.
Immersive Learning Environment and Hands-On Practice
An accelerated curriculum provides an intensive, immersive experience, optimizing knowledge retention and skill acquisition. Participants engage in extended instructor-led sessions, typically exceeding twelve hours per day, complemented by round-the-clock lab access that allows for hands-on experimentation. Digital courseware supplements live instruction, offering exercises, case studies, and reference material to reinforce comprehension. Residential learners benefit from uninterrupted access to meals and accommodation, providing a focused environment conducive to intensive study. On-site practice tests and exam simulations mirror real assessment conditions, helping candidates refine their understanding and approach.
This immersive environment enables participants to absorb complex concepts efficiently, engaging multiple learning modalities including visual, auditory, and kinesthetic approaches. By integrating theoretical instruction with practical application, learners gain proficiency in system configuration, data ingestion, query optimization, security implementation, and analytical modeling. Real-world scenarios embedded within the curriculum allow engineers to apply knowledge directly to enterprise challenges, bridging the gap between academic instruction and professional practice. The intensive schedule accelerates skill acquisition, ensuring that learners achieve both breadth and depth of understanding in a condensed timeframe.
Benefits of Accelerated Big Data Learning
Undertaking concentrated training in big data engineering confers multiple advantages beyond formal certification. Rapid immersion in comprehensive toolsets allows engineers to gain practical proficiency in both foundational and emerging technologies, facilitating immediate application in professional environments. Extended learning hours promote deep comprehension, reducing the time typically required to develop equivalent expertise through traditional methods. An all-inclusive format, covering course materials, examinations, accommodation, and logistical support, allows learners to concentrate exclusively on skill acquisition.
Recognition of the training institution in the broader professional landscape further enhances credibility, signaling adherence to rigorous educational standards. Participants benefit from exposure to seasoned instructors and peer cohorts, fostering collaborative learning and knowledge exchange. Continuous assessment cycles, including practice exams and real-world problem solving, reinforce best practices in data ingestion, storage, querying, governance, and security. Exposure to both structured and unstructured datasets, coupled with advanced analytical frameworks and machine learning tools, prepares engineers to navigate complex, multi-dimensional data environments with agility and confidence. The immersive approach ensures that learners are not only capable of operating software tools but also adept at making strategic architectural decisions, optimizing performance, and implementing enterprise-scale data solutions.
Comprehensive Approach to Core and Auxiliary Tools
In the contemporary realm of data engineering, a thorough understanding of both foundational and supplementary software environments is paramount to orchestrating complex data ecosystems. The proficiency in BigInsights provides engineers with the ability to execute scalable analytics over voluminous and heterogeneous datasets. It facilitates distributed processing, supports both batch and real-time computation, and allows for integration with other enterprise applications, ensuring that data-driven decisions can be derived with precision and rapidity. BigSQL enhances these capabilities by offering a sophisticated structured query environment that operates seamlessly across partitioned datasets, optimizing retrieval times and reducing computational strain. Hadoop remains a fundamental framework, enabling distributed storage and parallelized computation across clusters, offering resilience through redundancy and fault tolerance. Cloudant, with its schema-flexible NoSQL design, allows for the management of unstructured and semi-structured data, making it indispensable for modern applications where data types and structures frequently evolve.
Alongside these core tools, ancillary systems amplify the effectiveness of big data operations. Information Server provides robust metadata management and lineage tracking, allowing data engineers to maintain transparency and compliance throughout complex workflows. Integration functionalities, such as balanced optimization for Hadoop and JAQL pushdown capabilities, facilitate efficient query execution, enhancing overall system throughput. Governance frameworks ensure data integrity, standardization, and regulatory compliance, reducing operational risks. Security features, complemented by monitoring solutions such as Guardium, protect sensitive data through access control, authentication, and proactive anomaly detection. DataClick enables the movement of operational datasets into analytical environments, permitting timely insights, while BigMatch strives to consolidate disparate datasets into a unified view, promoting accuracy in reporting. Complementary analytics tools like SPSS and BigSheets provide advanced computational and visualization capabilities, allowing engineers to interrogate data, identify trends, and communicate findings effectively. In-memory analytics accelerates computation by retaining datasets in volatile memory, thereby minimizing the latency associated with traditional disk-based operations.
Netezza and DB2 BLU enhance data processing by employing columnar storage and parallel execution strategies, enabling high-performance querying even under substantial workloads. Graph databases facilitate relationship-based analysis, essential for exploring intricate networks and dependencies, while machine learning frameworks, including System ML, allow predictive modeling directly within the big data infrastructure. Streaming data concepts and technologies support near-real-time ingestion and processing, allowing enterprises to react swiftly to emerging trends or anomalies. Streams provide continuous data flow handling capabilities, enabling applications to process events with minimal delay. Collectively, these tools equip engineers with the technical acumen to manage, analyze, and optimize extensive data environments that exhibit high volume, variety, and velocity.
Examination Readiness and Domain Competence
Participants in an accelerated data engineering curriculum are prepared to undertake a rigorous assessment designed to evaluate proficiency across key operational and theoretical domains. Data loading encompasses the methods and strategies for efficiently ingesting, transforming, and distributing data across distributed systems. Engineers must understand error mitigation, resource allocation, and throughput optimization to ensure reliable and accurate data delivery. Security domains examine the implementation of authentication protocols, role-based access control, monitoring procedures, and compliance with data protection regulations, including considerations for personally identifiable information.
Architecture and integration knowledge is assessed through the ability to design cohesive systems that combine multiple tools, platforms, and data sources while maintaining scalability, reliability, and efficiency. Candidates must demonstrate an understanding of cluster management, network topology, and system interdependencies to ensure optimal operation under varying workloads. Performance and scalability competencies are tested through optimization of queries, resource distribution, workload balancing, and parallel execution, requiring familiarity with caching, indexing, and partitioning strategies. Data preparation, transformation, and export involve converting raw data into structured, analyzable formats, integrating heterogeneous sources, performing aggregations, and preparing data for downstream analytics. Mastery in these domains enables engineers to transform raw information into actionable insights that support enterprise intelligence initiatives.
Prerequisites for Successful Learning
Before engaging in an accelerated learning trajectory, candidates are encouraged to cultivate knowledge across multiple aspects of the data environment. Understanding the architecture and potential risk areas within the data layer provides a strategic advantage for anticipating bottlenecks and mitigating operational disruptions. Translating functional requirements into precise technical specifications ensures coherent system design, while mapping logical architectures onto physical infrastructure enables the practical deployment of solutions. Competence in cluster management, network configuration, and critical interface management ensures that distributed systems operate with resilience and efficiency. Data modeling expertise, including schema evolution, normalization, and entity-relationship management, supports the construction of scalable, adaptable databases capable of meeting future demands.
Consideration of non-functional requirements such as high availability, fault tolerance, disaster recovery, and replication is critical to maintaining uninterrupted operations. Performance evaluation, encompassing query efficiency, workload distribution, and resource utilization, ensures that systems perform optimally under variable loads. Strategies for data ingestion, storage, querying, governance, and manipulation are essential for managing enterprise-scale datasets across on-premise and cloud infrastructures. Security measures, including LDAP authentication, role-based access control, and continuous monitoring, protect sensitive information and ensure compliance with organizational and regulatory standards. These prerequisites establish a foundation for effective participation in immersive, accelerated training and provide the technical background necessary to navigate complex, multi-layered data environments.
Immersive Training Environment and Experiential Learning
An accelerated learning environment offers immersive, hands-on experiences that optimize knowledge acquisition and practical skill development. Participants engage in extended instructor-led sessions, often surpassing twelve hours per day, and have access to laboratories for continual experimentation with real-world data scenarios. Digital courseware supplements these sessions, providing reference material, exercises, and case studies to reinforce comprehension. Residential arrangements allow learners uninterrupted access to resources, meals, and accommodation, creating a conducive environment for focused study and skill development. Practice assessments and on-site examinations simulate actual testing conditions, enabling participants to evaluate their progress and refine their understanding.
The integration of multiple learning modalities—visual, auditory, and kinesthetic—enhances comprehension and retention, accommodating diverse cognitive styles. The curriculum emphasizes real-world application, ensuring that participants not only master technical operations but also develop critical thinking and decision-making skills necessary for enterprise-level projects. Extended engagement with core and complementary tools enables learners to implement optimized workflows, integrate complex systems, and address challenges in performance tuning, security, and data governance. Experiential learning in a controlled yet dynamic environment ensures that participants acquire both theoretical knowledge and practical competence, fostering confidence and proficiency in big data engineering.
Advantages of Intensive Data Engineering Training
Concentrated training in big data engineering provides numerous benefits beyond mere certification. Rapid exposure to a comprehensive suite of tools and technologies equips engineers with practical expertise for immediate application in professional contexts. Extended instructional periods promote deeper understanding and faster skill acquisition compared to traditional methods. An all-inclusive training model, encompassing course materials, examinations, accommodation, and logistical support, allows participants to focus entirely on learning without extraneous distractions.
Recognition of the training institution enhances professional credibility, signaling adherence to high educational standards and proven instructional methodologies. Learners engage with experienced instructors and peers, facilitating knowledge exchange, collaborative problem-solving, and exposure to diverse perspectives. Continuous assessment and application cycles reinforce best practices in data ingestion, storage, querying, governance, and security. Familiarity with both structured and unstructured datasets, along with advanced analytical techniques and machine learning frameworks, prepares engineers to handle sophisticated, multi-dimensional data environments with agility and confidence. Immersive training ensures that participants are capable not only of operating software but also of making informed architectural decisions, optimizing system performance, and implementing enterprise-scale solutions.
Integrated Tools and Analytical Workflows
In the ever-expanding universe of data engineering, proficiency in both foundational platforms and auxiliary software is essential for orchestrating complex analytical workflows. BigInsights provides a versatile environment for processing and interpreting massive volumes of heterogeneous data, supporting both batch and real-time operations. Its architecture is designed to accommodate large-scale distributed computations, enabling engineers to execute intricate queries, perform comprehensive data mining, and derive actionable insights with precision. BigSQL extends this functionality by allowing structured queries to be performed efficiently across distributed datasets, enhancing data accessibility while reducing computational latency. Hadoop, as a cornerstone framework, provides a reliable infrastructure for distributed storage and parallelized computation, offering resilience through redundancy and fault tolerance. Cloudant’s schema-flexible NoSQL architecture allows storage of unstructured and semi-structured data, essential for modern applications where data formats continuously evolve.
Ancillary tools bolster the capabilities of these core platforms by addressing integration, governance, and operational efficiency. Information Server enables meticulous metadata management and lineage tracking, ensuring transparency across complex workflows. Balanced optimization for Hadoop and JAQL pushdown capabilities improve query efficiency and resource utilization. Data governance ensures consistency, quality, and compliance, mitigating operational risks and reinforcing organizational standards. Security frameworks, supplemented by monitoring mechanisms such as Guardium, protect sensitive information through authentication, access control, and real-time surveillance. DataClick facilitates extraction of operational data into analytical frameworks, enabling timely decision-making, while BigMatch consolidates disparate datasets into a coherent, unified perspective for reporting and analysis. Analytic tools such as SPSS and BigSheets allow engineers to explore data intricacies, perform predictive modeling, and visualize insights effectively. In-memory analytics accelerates computations by retaining data in volatile memory, minimizing latency associated with traditional disk operations.
Databases like Netezza and DB2 BLU optimize storage and retrieval through columnar architectures, indexing, and parallel execution, allowing high-performance querying under substantial workloads. Graph databases enable relationship-focused analyses, essential for uncovering connections within complex networks. Machine learning frameworks, including System ML, facilitate predictive modeling directly within big data environments, while streaming concepts provide near-real-time processing capabilities for continuous ingestion and analysis. Streams handle constant data flows efficiently, allowing enterprises to respond promptly to emerging trends or anomalies. Collectively, these tools equip engineers with the capability to manage large-scale data ecosystems characterized by volume, variety, and velocity with accuracy and agility.
Competency Domains and Examination Focus
The accelerated learning pathway culminates in an examination designed to evaluate mastery across operational and theoretical domains. Data loading is a critical component, involving ingestion, cleansing, transformation, and distribution of large datasets. Engineers must optimize throughput, ensure data fidelity, and address errors or inconsistencies during processing. Data security is emphasized, covering authentication protocols, user permissions, monitoring, and protection of personally identifiable information. Candidates are expected to implement secure data transfer mechanisms, role-based access, and continuous surveillance to mitigate potential threats.
Architecture and integration skills are assessed by examining the ability to design robust, scalable systems that interconnect diverse tools while maintaining performance and reliability. Understanding logical and physical architectures, cluster management, and network configurations is essential for seamless integration. Performance and scalability competencies require mastery of query optimization, workload balancing, resource allocation, and parallel processing strategies. Data preparation, transformation, and export involve converting raw information into analyzable formats, integrating heterogeneous datasets, and preparing data for downstream analytics. Proficiency in these domains ensures that engineers can transform complex data into actionable insights, driving informed business decisions and operational intelligence.
Prerequisite Knowledge for Accelerated Learning
Effective engagement in accelerated data engineering curricula demands foundational knowledge across several aspects of the data ecosystem. Understanding the architecture of the data layer, potential risk points, and areas prone to latency or bottlenecks provides a strategic advantage in system design. Translating functional requirements into technical specifications allows engineers to create coherent solutions, while mapping logical architectures onto physical infrastructure ensures practical feasibility. Cluster management, network configuration, and interface knowledge are essential for maintaining system stability. Data modeling expertise, including schema evolution, normalization, and entity-relationship design, supports scalable database solutions capable of adapting to changing requirements.
Non-functional requirements such as high availability, fault tolerance, disaster recovery, and replication must be considered to maintain uninterrupted operations. Performance metrics, including query efficiency, workload distribution, and resource utilization, help engineers monitor and optimize system performance. Data movement, storage, querying, and governance strategies are essential for managing enterprise-scale datasets across on-premise and cloud infrastructures. Security protocols, including LDAP authentication, role-based access, and continuous monitoring, safeguard sensitive information and ensure regulatory compliance. Mastery of these prerequisite domains provides the foundation for immersive learning experiences, ensuring participants are equipped to manage complex big data ecosystems efficiently and effectively.
Immersive Training and Practical Application
Accelerated training programs provide an immersive environment designed to maximize knowledge retention and skill acquisition. Learners engage in extended instructor-led sessions, often exceeding twelve hours daily, coupled with laboratory access for hands-on experimentation. Digital courseware supplements live instruction, providing exercises, case studies, and reference materials to reinforce theoretical understanding. Residential training arrangements offer uninterrupted access to accommodations, meals, and resources, creating an optimal environment for focused study. Practice assessments and exam simulations emulate formal testing conditions, allowing participants to evaluate their progress and refine approaches.
A multimodal learning approach integrates visual, auditory, and kinesthetic strategies, accommodating diverse cognitive styles and enhancing comprehension. Real-world case studies and scenario-based exercises allow learners to apply technical knowledge to enterprise-grade challenges, bridging the gap between theoretical understanding and practical application. Extended exposure to core and auxiliary tools enables participants to develop optimized workflows, integrate complex systems, implement security measures, and manage governance protocols effectively. Experiential learning ensures that engineers acquire both theoretical proficiency and practical competency, fostering confidence and readiness for professional application.
Advantages of Intensive Data Engineering Training
Engaging in concentrated big data training provides numerous advantages, extending beyond certification attainment. Rapid immersion in core and supplementary tools equips engineers with practical expertise applicable immediately in professional environments. Extended instructional periods promote accelerated skill acquisition and deeper understanding compared to conventional learning methods. An all-inclusive training model, encompassing course materials, examinations, accommodation, and logistical support, allows learners to concentrate fully on learning without distraction.
Institutional recognition enhances professional credibility, signaling adherence to rigorous educational standards. Learners interact with experienced instructors and peers, fostering collaborative problem-solving, knowledge sharing, and exposure to diverse analytical perspectives. Continuous assessment and application cycles reinforce best practices in data ingestion, storage, querying, governance, and security. Exposure to structured and unstructured datasets, advanced analytics, machine learning frameworks, and streaming technologies prepares engineers to navigate multi-dimensional, high-velocity data environments with agility and confidence. Immersive training ensures that participants not only operate software proficiently but also make informed architectural decisions, optimize performance, and implement enterprise-scale data solutions with efficacy.
Comprehensive Strategies for Core and Complementary Tools
The contemporary landscape of data engineering requires an in-depth understanding of both foundational platforms and auxiliary technologies to manage and analyze large-scale datasets effectively. BigInsights offers a versatile environment for orchestrating distributed computations and deriving actionable insights from heterogeneous data sources. Its architecture supports both batch processing and near-real-time analytics, enabling engineers to execute complex queries, perform predictive modeling, and integrate results into enterprise decision-making systems. BigSQL enhances the querying capabilities within these distributed environments, facilitating efficient processing of structured data and optimizing resource allocation for faster retrievals. Hadoop remains a central framework, providing fault-tolerant distributed storage and parallelized computation, which is essential for managing voluminous and high-velocity datasets. Cloudant, with its flexible NoSQL architecture, allows the storage and retrieval of unstructured and semi-structured data, supporting applications where data schemas evolve dynamically or where data diversity is high.
Complementary tools augment the effectiveness of these core platforms by providing specialized functionalities for integration, governance, and operational efficiency. Information Server serves as a metadata management and lineage tracking system, enabling engineers to maintain visibility across complex workflows and ensure compliance with regulatory requirements. Integration capabilities such as balanced optimization for Hadoop and JAQL pushdown improve system throughput and minimize resource consumption. Data governance frameworks guarantee data integrity, enforce standardization, and mitigate operational risks. Security features, augmented by monitoring solutions like Guardium, ensure that sensitive information remains protected through multi-layered authentication, role-based access control, and continuous surveillance. DataClick enables the extraction of operational data into analytical systems, allowing engineers to perform timely analytics, while BigMatch consolidates disparate datasets into a unified view, enhancing the accuracy of reporting and decision-making.
Advanced analytics capabilities including SPSS and BigSheets facilitate the exploration, modeling, and visualization of datasets. In-memory analytics accelerates processing by storing data in volatile memory, reducing latency associated with traditional storage systems. Netezza and DB2 BLU optimize performance through columnar storage, indexing, and parallelized execution strategies, enabling rapid querying even under substantial workloads. Graph databases allow engineers to analyze complex relationships and dependencies within data, providing the foundation for advanced network analysis and predictive modeling. Machine learning frameworks, such as System ML, enable the development and deployment of predictive models directly within the big data environment, while streaming concepts and Streams allow near-real-time data ingestion and analysis for prompt operational decision-making. Together, these tools equip engineers to manage and optimize data ecosystems characterized by high volume, velocity, and variety, ensuring robust, scalable, and insightful analytics.
Examination Preparation and Skill Development
Accelerated learning programs culminate in examinations that evaluate both theoretical understanding and practical competency. Data loading forms a critical area of assessment, requiring engineers to ingest, cleanse, transform, and distribute datasets efficiently within distributed systems. Proficiency in this domain includes understanding throughput optimization, error handling, and the maintenance of data fidelity. Data security knowledge covers authentication protocols, access control, monitoring, and protection of personally identifiable information. Engineers must be able to implement secure transfer mechanisms, role-based permissions, and continuous monitoring to safeguard sensitive data.
Architecture and integration skills are tested by evaluating the ability to design coherent, scalable systems that interconnect multiple tools while maintaining performance and reliability. Understanding cluster management, logical and physical architecture, and network configuration is essential to ensure seamless interoperability. Performance and scalability competencies involve optimizing queries, balancing workloads, and effectively utilizing system resources. Engineers are expected to employ parallelism, caching strategies, indexing, and partitioning to maximize efficiency and throughput. Data preparation, transformation, and export are examined through the ability to convert raw data into analyzable formats, integrate heterogeneous datasets, perform aggregations, and prepare exports for downstream analytical tools. Mastery in these domains ensures that engineers can transform raw information into actionable insights, supporting enterprise intelligence initiatives and operational optimization.
Prerequisites for Effective Learning
Successful participation in accelerated data engineering curricula requires a solid foundation across multiple facets of the data environment. Understanding the architecture of the data layer, potential risks, and areas prone to latency or bottlenecks provides a strategic advantage. Translating functional requirements into technical specifications enables coherent system design, while mapping logical solutions onto physical infrastructure ensures feasibility and reliability. Knowledge of cluster management, network configurations, and critical interface management supports the stability and efficiency of distributed systems. Data modeling expertise, including schema evolution, normalization, and entity-relationship design, provides the foundation for scalable, adaptable database structures capable of handling large-scale enterprise demands.
Non-functional requirements, including high availability, fault tolerance, disaster recovery, and replication strategies, are essential for maintaining continuous operation. Performance monitoring, encompassing query efficiency, workload distribution, and resource utilization, ensures optimal system functioning. Data movement, storage, querying, governance, and manipulation strategies are necessary for managing datasets across on-premise and cloud-based infrastructures. Security implementation, including LDAP authentication, role-based access, and continuous monitoring, safeguards sensitive information and ensures compliance with organizational and regulatory standards. These prerequisites provide learners with the foundational knowledge required to fully benefit from immersive, accelerated learning experiences, enabling them to navigate complex big data environments confidently.
Experiential Learning and Immersive Environment
Accelerated learning environments provide immersive experiences designed to maximize knowledge retention and practical skill development. Participants engage in extended instructor-led sessions, frequently surpassing twelve hours per day, supported by laboratory access for hands-on experimentation. Digital courseware supplements live instruction, offering exercises, case studies, and reference material to reinforce theoretical comprehension. Residential learning arrangements allow uninterrupted access to accommodations, meals, and study resources, creating an environment optimized for focused skill acquisition. Practice assessments and simulated exams mirror real-world testing conditions, allowing participants to gauge readiness and refine strategies for examination success.
The learning model integrates multiple cognitive approaches, combining visual, auditory, and kinesthetic modalities to cater to diverse learning styles. Scenario-based exercises and real-world applications provide opportunities for engineers to implement technical knowledge in enterprise-grade situations, bridging the gap between theory and practice. Extended engagement with core and complementary tools allows participants to design optimized workflows, integrate complex systems, implement security protocols, and maintain governance standards effectively. This experiential approach ensures participants develop both theoretical understanding and practical competence, fostering readiness for professional application in diverse data engineering environments.
Advantages of Intensive Big Data Training
Participating in concentrated big data training provides a host of advantages beyond formal certification. Rapid immersion in foundational and supplementary tools enables engineers to acquire practical expertise for immediate professional application. Extended instructional periods facilitate accelerated skill acquisition and deeper comprehension relative to conventional learning approaches. All-inclusive training models, encompassing course materials, examinations, accommodations, and logistical support, allow learners to concentrate fully on learning objectives without extraneous distractions.
Recognition of the training institution enhances professional credibility, reflecting adherence to rigorous educational standards and instructional methodologies. Participants interact with experienced instructors and peers, fostering collaborative problem-solving, knowledge exchange, and exposure to diverse analytical perspectives. Continuous assessment cycles and practical exercises reinforce best practices in data ingestion, storage, querying, governance, and security. Familiarity with both structured and unstructured datasets, advanced analytics, machine learning frameworks, and streaming technologies equips engineers to navigate multi-dimensional, high-velocity data environments with agility and confidence. Immersive training ensures that participants are capable not only of proficiently operating software tools but also of making informed architectural decisions, optimizing system performance, and implementing enterprise-scale data solutions effectively.
Operational Excellence in Core and Supplementary Tools
In the evolving domain of data engineering, proficiency with foundational platforms and auxiliary technologies is indispensable for designing, managing, and optimizing high-volume data ecosystems. BigInsights provides a dynamic environment for orchestrating distributed analytics, enabling engineers to execute intricate queries, perform advanced data mining, and integrate results into enterprise decision-making workflows. Its architecture supports both batch and near-real-time analytics, ensuring that operational intelligence is accessible across a spectrum of use cases. BigSQL extends these capabilities by facilitating structured queries over distributed datasets, reducing latency, and optimizing system resource utilization. Hadoop remains a central framework, offering distributed storage and parallel computation to handle voluminous and high-velocity datasets reliably. Cloudant, with its schema-flexible NoSQL architecture, accommodates unstructured and semi-structured data, supporting applications where data types continuously evolve and diverse datasets converge.
Complementary tools enhance efficiency by providing specialized functions for integration, governance, and operational monitoring. Information Server supports meticulous metadata management and lineage tracking, offering transparency across complex data workflows. Balanced optimization for Hadoop and JAQL pushdown improve query execution, ensuring efficient utilization of resources. Data governance ensures quality, consistency, and compliance, mitigating risks and maintaining organizational standards. Security frameworks, complemented by monitoring solutions like Guardium, protect sensitive information through authentication, role-based access, and continuous surveillance. DataClick allows operational datasets to be integrated into analytical environments, facilitating timely insights, while BigMatch consolidates disparate datasets into a unified perspective for accurate reporting. Analytical tools such as SPSS and BigSheets empower engineers to explore data, identify trends, and generate visual insights. In-memory analytics reduces latency by retaining active datasets in volatile memory, while Netezza and DB2 BLU optimize performance through columnar storage, indexing, and parallelized execution. Graph databases enable analysis of intricate relationships, providing insights for network analysis and predictive modeling, while System ML allows the deployment of machine learning models within the big data environment. Streaming concepts and Streams facilitate near-real-time ingestion and processing, allowing rapid response to operational and analytical requirements.
Examination Preparation and Skill Mastery
Accelerated learning programs prepare candidates for examinations that evaluate both practical competence and theoretical understanding. Data loading involves ingestion, cleansing, transformation, and distribution of datasets across distributed environments. Engineers are required to optimize throughput, address errors, and ensure fidelity of data during processing. Data security is emphasized, encompassing authentication, access control, monitoring, and protection of personally identifiable information. Engineers implement secure transfer protocols, role-based permissions, and continuous monitoring to safeguard sensitive datasets.
Architecture and integration skills are assessed through the ability to design coherent, scalable systems interconnecting multiple tools while maintaining performance and reliability. Understanding cluster management, logical and physical architectures, and network configurations is essential for system integration. Performance and scalability competencies involve query optimization, workload balancing, and efficient resource allocation. Engineers leverage parallelism, indexing, caching, and partitioning strategies to maximize system throughput. Data preparation, transformation, and export require converting raw datasets into analyzable formats, integrating heterogeneous sources, performing aggregations, and preparing data for downstream analytics. Proficiency in these domains ensures that engineers can translate complex datasets into actionable insights that support enterprise intelligence and operational optimization.
Prerequisites for Effective Learning
Effective engagement in accelerated data engineering curricula demands foundational knowledge across multiple aspects of the data ecosystem. Understanding the architecture and potential risk points in the data layer enables engineers to anticipate bottlenecks and mitigate operational challenges. Translating functional requirements into technical specifications allows for coherent solution design, while mapping logical architectures onto physical infrastructure ensures feasibility and reliability. Competence in cluster management, network configuration, and interface management underpins stable system operations. Data modeling expertise, including schema evolution, normalization, and entity-relationship design, supports the development of scalable and adaptable database structures.
Non-functional requirements such as high availability, fault tolerance, disaster recovery, and replication strategies are critical for uninterrupted operations. Performance monitoring, including query efficiency, workload distribution, and resource utilization, ensures optimal system functionality. Data ingestion, storage, querying, governance, and manipulation strategies are necessary to manage enterprise-scale datasets across on-premise and cloud infrastructures. Security protocols, including LDAP authentication, role-based access, and continuous monitoring, protect sensitive data and ensure compliance with organizational and regulatory standards. These prerequisites provide the foundation for immersive learning experiences and ensure engineers are equipped to navigate complex big data ecosystems efficiently.
Immersive Learning Environment and Experiential Practice
Accelerated learning programs provide immersive experiences to maximize knowledge acquisition and practical skill development. Participants engage in extended instructor-led sessions, often exceeding twelve hours daily, supported by laboratory access for hands-on experimentation. Digital courseware supplements instruction, offering exercises, case studies, and reference material to reinforce comprehension. Residential arrangements provide uninterrupted access to accommodations, meals, and study resources, fostering a focused environment for intensive learning. Practice assessments and simulated exams replicate formal testing conditions, enabling learners to evaluate their preparedness and refine strategies for examination success.
Multiple cognitive modalities, including visual, auditory, and kinesthetic approaches, enhance comprehension and retention. Scenario-based exercises and real-world applications allow engineers to implement technical knowledge in enterprise-grade situations, bridging the gap between theoretical understanding and practical application. Extended exposure to core and auxiliary tools equips participants to optimize workflows, integrate complex systems, enforce security protocols, and maintain governance standards effectively. Experiential learning ensures engineers develop both theoretical proficiency and practical competence, enabling them to apply skills confidently in professional environments.
Advanced Performance, Integration, and Governance Strategies
Engineers are expected to master advanced strategies for system performance, integration, and governance. Optimization of query execution, workload balancing, and resource allocation are fundamental to maximizing throughput. Engineers employ parallelism, caching strategies, indexing, and data partitioning to enhance system performance. Integrating multiple tools and platforms requires careful consideration of logical and physical architecture, ensuring seamless interoperability and minimal latency.
Data governance remains a critical component of operational success. Engineers establish protocols to maintain data quality, ensure consistency across diverse sources, and comply with regulatory requirements. Metadata management and lineage tracking provide visibility into data transformations, facilitating auditability and transparency. Security frameworks, combined with continuous monitoring and anomaly detection, protect sensitive data and enforce compliance standards. Stream processing and near-real-time analytics allow organizations to act quickly on emerging trends or operational anomalies, ensuring that decision-making remains timely and accurate.
Machine learning integration within big data ecosystems provides predictive capabilities, enabling proactive strategies across operational and analytical domains. Graph databases facilitate relationship and network analysis, supporting sophisticated pattern recognition and predictive modeling. In-memory analytics reduces latency and enhances the performance of real-time computations. Collectively, these strategies ensure that data ecosystems remain efficient, secure, and capable of delivering actionable insights across a range of enterprise use cases.
Advantages of Immersive Big Data Training
Concentrated big data training delivers significant advantages beyond certification. Rapid immersion in core and complementary tools equips engineers with practical expertise for immediate application in professional contexts. Extended instructional periods accelerate learning, fostering deep comprehension compared to traditional methods. An all-inclusive approach, encompassing course materials, examinations, accommodations, and logistical support, allows participants to concentrate exclusively on skill acquisition.
Recognition of the training institution enhances professional credibility and signals adherence to rigorous educational standards. Interaction with experienced instructors and peers fosters knowledge sharing, collaborative problem-solving, and exposure to diverse analytical perspectives. Continuous assessments and practical exercises reinforce best practices in data ingestion, storage, querying, governance, and security. Exposure to structured and unstructured datasets, advanced analytics, machine learning frameworks, and streaming technologies equips engineers to navigate complex, multi-dimensional data environments with confidence. Immersive training ensures that participants can operate software proficiently, make informed architectural decisions, optimize system performance, and implement enterprise-scale data solutions effectively.
Conclusion
The mastery of big data ecosystems requires not only familiarity with foundational platforms like BigInsights, BigSQL, Hadoop, and Cloudant, but also proficiency in auxiliary tools that enhance integration, governance, security, and analytics. Accelerated learning programs provide immersive experiences that combine theoretical instruction with hands-on practice, equipping engineers with the skills necessary to design, optimize, and secure complex data environments. Advanced strategies in performance tuning, workflow integration, governance, and machine learning enable organizations to derive actionable insights from massive, heterogeneous datasets. By embedding these capabilities within operational and analytical frameworks, engineers can ensure that big data solutions remain efficient, resilient, and capable of supporting enterprise intelligence in dynamic and high-velocity contexts. Comprehensive training and practical experience foster confidence, expertise, and readiness to navigate the intricate challenges of modern data ecosystems, positioning engineers as effective architects and operators of advanced big data solutions.
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Top IBM Exams
- C1000-156 - QRadar SIEM V7.5 Administration
- C1000-171 - IBM App Connect Enterprise V12.0 Developer
- S2000-025 - IBM AIX v7.3 Administrator Specialty
- C2090-320 - DB2 11 Fundamentals for z/OS
- C1000-138 - IBM API Connect v10.0.3 Solution Implementation
- C1000-200 - IBM MQ v9.4 Administrator - Professional
IBM Certifications
- IBM Certified Administrator - Cloud Pak for Integration V2021.2
- IBM Certified Administrator - IBM Cloud Pak for Business Automation v21.0.3
- IBM Certified Administrator - IBM Cognos Analytics Administrator V11
- IBM Certified Administrator - Security QRadar SIEM V7.5
- IBM Certified Administrator - Spectrum Protect V8.1.9
- IBM Certified Advocate - Cloud v1
- IBM Certified Advocate - Cloud v2
- IBM Certified Application Developer - Curam SPM V7.X
- IBM Certified Associate Administrator - IBM QRadar SIEM V7.3.2
- IBM Certified Associate Analyst - IBM QRadar SIEM V7.3.2
- IBM Certified Associate Business Process Analyst - Curam V6.0.5
- IBM Certified BPM System Administration - Business Process Manager Advanced V8.5
- IBM Certified Data Engineer - Big Data
- IBM Certified Database Administrator - DB2 11 DBA for z/OS
- IBM Certified Database Associate - DB2 11 Fundamentals for z/OS
- IBM Certified Deployment Professional - FileNet P8 V5.5.3
- IBM Certified Deployment Professional - Maximo Asset Management v7.6 Functional Analyst
- IBM Certified Deployment Professional - Maximo Manage v8.0
- IBM Certified Deployment Professional - Security Access Manager V9.0
- IBM Certified Developer - Business Automation Workflow V20.0.0.2 using Workflow Center
- IBM Certified Mobile Application Developer - Mobile Foundation V8.0
- IBM Certified SOC Analyst - IBM QRadar SIEM V7.3.2
- IBM Certified Solution Advisor - Spectrum Storage V7
- IBM Certified Solution Architect - Cloud Pak for Integration v2021.4
- IBM Certified Solution Designer - Datacap V9.0
- IBM Certified Solution Developer - App Connect Enterprise V11
- IBM Certified Solution Developer - InfoSphere DataStage v11.3
- IBM Certified Solution Developer - Integration Bus v10.0
- IBM Certified Specialist - AI Enterprise Workflow V1
- IBM Certified Specialist - SPSS Modeler Professional v3
- IBM Certified System Administrator - MQ V9.0
- IBM Certified System Administrator - WebSphere Application Server Network Deployment V8.5.5 and Liberty Profile
- IBM Certified System Administrator - WebSphere Application Server Network Deployment V9.0
- IBM Certified Technical Advocate - Cloud v3
- IBM Cloud Pak for Data System V1.x Administrator Specialty
- IBM Enterprise Content Management - Software Technical Mastery
- IBM Mastery - IBM Mastery Test
- IBM Technical Mastery - IBM Watson Customer Engagement: Watson Supply Chain
