
Certification: IBM Enterprise Content Management - Software Technical Mastery
Certification Full Name: IBM Enterprise Content Management - Software Technical Mastery
Certification Provider: IBM
Exam Code: P2070-072
Product Screenshots
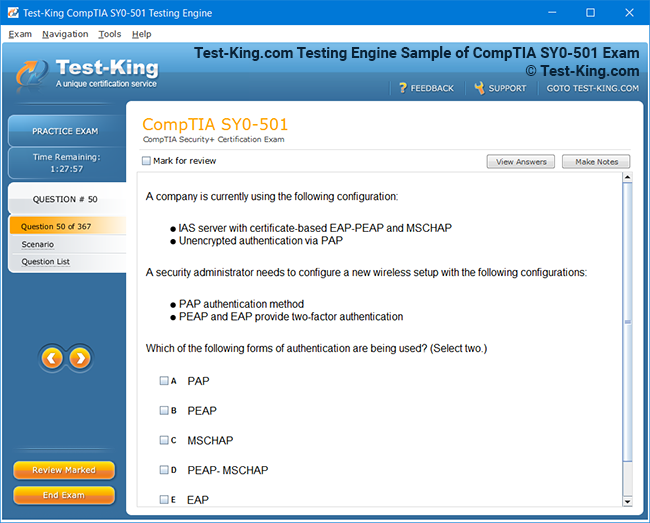
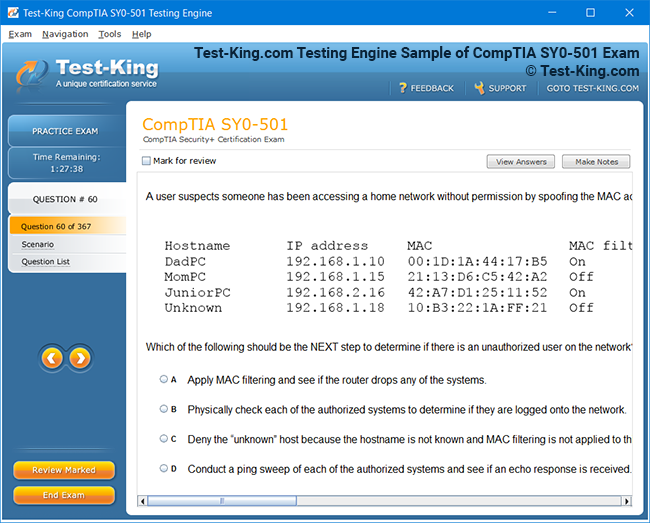
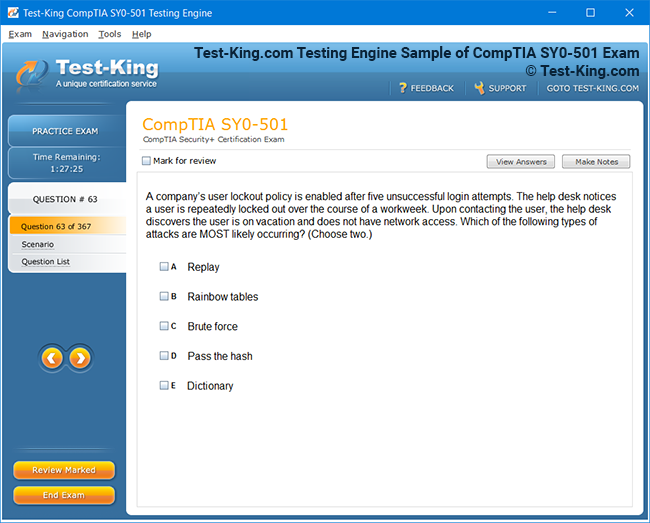
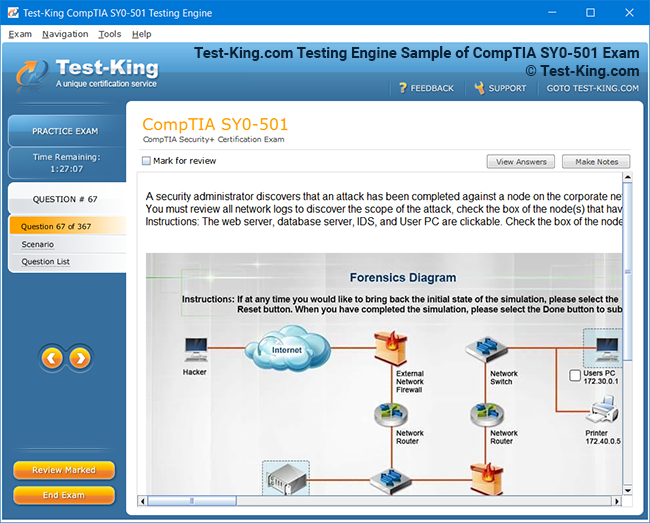
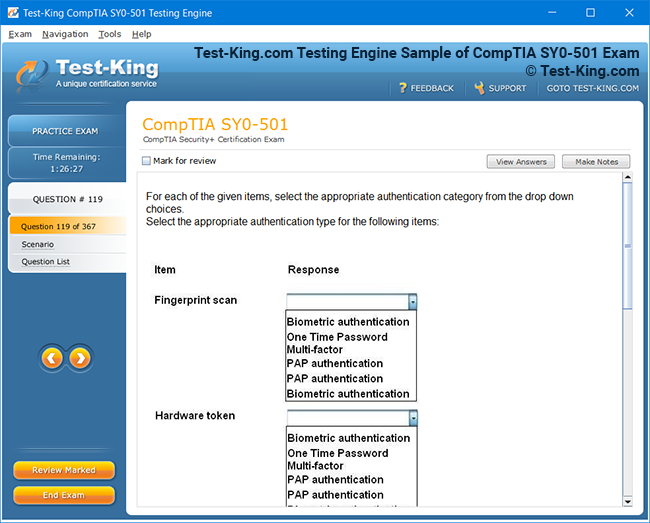
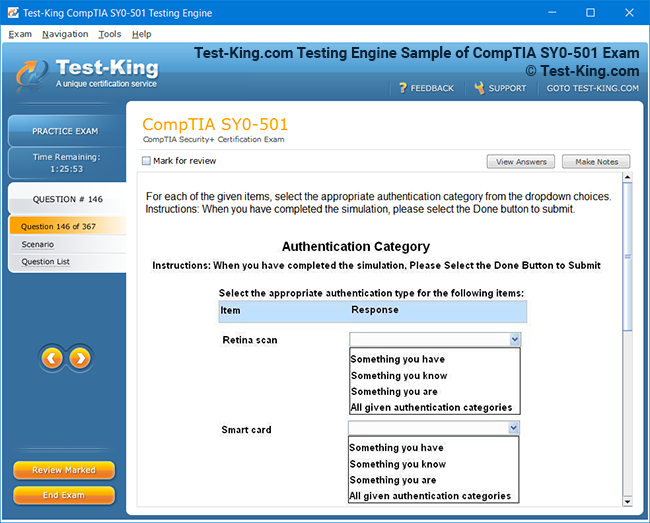
Comprehensive Guide to Certification of IBM Enterprise Content Management: Achieving Software Technical Mastery
In the contemporary digital milieu, enterprises grapple with an ever-expanding deluge of information that requires meticulous organization, retrieval, and security. IBM Enterprise Content Management stands as a paragon in the landscape of content management solutions, offering a cohesive framework that integrates document management, records management, imaging, and workflow automation. At its core, this system enables organizations to capture, store, manage, and deliver content seamlessly across departments and operational silos. Mastery in this domain does not merely signify proficiency in software operations but embodies the capability to architect and optimize content strategies that amplify efficiency, reduce operational redundancy, and ensure compliance with regulatory mandates.
Understanding IBM Enterprise Content Management and Its Importance
The certification in Software Technical Mastery provides professionals with a profound understanding of IBM ECM’s capabilities. Unlike superficial training, this credential fosters an intimate comprehension of intricate software functionalities, encompassing repository management, metadata schemas, version control, and advanced search capabilities. Individuals who attain this recognition are not only versed in system navigation but are capable of diagnosing complex enterprise challenges, configuring solutions that align with business objectives, and leveraging ECM to streamline knowledge flows.
Organizations that implement IBM ECM with technical mastery witness tangible benefits. Operational bottlenecks caused by unstructured data are mitigated, while audit readiness and records retention practices are enhanced. The software's integration with existing enterprise systems, such as ERP and CRM platforms, permits data harmonization across multiple channels, thereby fostering an ecosystem where information is not only accessible but actionable. Professionals who understand these integrations at a granular level can contribute strategically, aligning technology deployment with corporate governance, compliance requirements, and operational objectives.
Core Competencies Developed Through IBM ECM Mastery
Gaining technical mastery in IBM Enterprise Content Management cultivates a multifaceted skill set that spans from foundational operational knowledge to advanced strategic application. A central competency involves comprehensive document lifecycle management, including the capture, indexing, storage, retrieval, and eventual disposition of content. Candidates develop a keen understanding of how to structure repositories to accommodate voluminous data, ensuring that retrieval times remain minimal and system performance is optimized even under heavy transactional loads.
Another salient skill is workflow orchestration. Professionals learn to design, implement, and refine automated workflows that reduce human error, enforce compliance, and expedite operational processes. This involves understanding conditional routing, escalation protocols, and exception handling, allowing content to traverse organizational layers efficiently while preserving audit trails. The ability to tailor these workflows to specific organizational requirements reflects a sophisticated grasp of both technical intricacies and business needs.
Moreover, proficiency in IBM ECM encompasses advanced metadata modeling and taxonomy creation. By crafting precise metadata schemas, professionals enhance content discoverability and enable predictive analytics, ensuring that decision-makers can access relevant information expeditiously. The certification also emphasizes security and permissions management, instructing individuals on how to safeguard sensitive information, enforce access controls, and implement encryption protocols to protect intellectual property.
An often-overlooked skill developed through this mastery is system optimization. Professionals learn to monitor performance metrics, troubleshoot bottlenecks, and perform configuration tuning to maintain high system responsiveness. This competency is critical for large enterprises where even minor inefficiencies can translate into significant operational costs. Additionally, mastery includes understanding integration possibilities with emerging technologies, such as AI-driven content analysis, cloud-based storage solutions, and mobile access frameworks, positioning certified professionals at the forefront of technological evolution in content management.
Examining the Certification Objectives
The IBM Enterprise Content Management Software Technical Mastery certification is meticulously designed to validate a candidate’s comprehensive proficiency. Its objectives extend beyond the rote memorization of features to a practical demonstration of system understanding and problem-solving acumen. Among the primary goals is ensuring that professionals can configure and maintain repositories, develop complex workflows, manage document security, and apply advanced search functionalities to facilitate rapid information retrieval.
Furthermore, the certification underscores the importance of compliance and governance. Candidates are assessed on their ability to implement retention schedules, enforce audit controls, and align ECM deployment with statutory and organizational requirements. This aspect of the certification reflects the reality that enterprises operate within a labyrinthine framework of regulations and internal policies, where mismanagement of content can result in legal repercussions and reputational damage.
Another objective pertains to the integration of IBM ECM with broader enterprise systems. Candidates must demonstrate competence in connecting ECM to databases, ERP, CRM, and collaboration platforms, ensuring seamless data flow and interoperability. This focus reinforces the notion that technical mastery extends beyond software mechanics, encompassing strategic thinking about enterprise architecture and digital transformation initiatives.
The examination also tests analytical capabilities, requiring candidates to interpret system logs, troubleshoot errors, and optimize performance. Professionals who excel in these areas are capable of preempting potential failures, identifying inefficiencies, and implementing corrective measures that enhance operational reliability. This proactive approach to system management embodies the distinction between functional knowledge and technical mastery.
Career Impact and Opportunities
Obtaining mastery in IBM Enterprise Content Management opens avenues for numerous career trajectories. Certified professionals are sought after for roles that demand not only software proficiency but also the ability to translate technological capabilities into organizational advantage. Positions such as ECM Consultant, Technical Specialist, Content Architect, and Solutions Designer become accessible to those who demonstrate both operational expertise and strategic insight.
The recognition conferred by this certification serves as a differentiator in a competitive employment landscape. Organizations value individuals who can immediately contribute to system optimization, governance compliance, and workflow automation. In addition, certified professionals often assume leadership roles in project implementation, guiding teams through complex deployment processes, integrating ECM with legacy systems, and training end-users to maximize adoption and efficacy.
Beyond immediate employment benefits, IBM ECM mastery enhances professional credibility and positions individuals for upward mobility. The skill set acquired is transferable across industries, including finance, healthcare, government, and manufacturing, where content management challenges are both complex and mission-critical. By understanding the intricacies of document control, compliance, and integration, certified professionals contribute not only to operational efficiency but also to strategic decision-making processes.
Practical Applications and Real-World Implementation
IBM ECM is not an abstract system; its practical utility manifests in everyday enterprise operations. For example, in the healthcare sector, the ability to manage patient records securely while ensuring rapid retrieval can directly influence patient outcomes. Similarly, financial institutions rely on ECM for regulatory compliance, audit readiness, and risk mitigation, where delayed or mismanaged information can result in substantial penalties.
In manufacturing environments, ECM streamlines document-intensive processes such as quality control, supply chain management, and contract administration. Mastery in this software allows professionals to design content repositories that mirror operational workflows, implement automated approvals, and facilitate interdepartmental collaboration. The result is a reduction in manual labor, increased accuracy, and improved operational throughput.
Moreover, ECM mastery enables enterprises to harness unstructured data. Through metadata modeling, advanced search, and intelligent categorization, organizations convert disparate content into actionable insights. Professionals skilled in IBM ECM can employ analytical tools to identify trends, forecast operational needs, and support evidence-based decision-making. This capability is increasingly vital as businesses navigate complex, data-driven landscapes where timely access to information confers a competitive edge.
Exploring the Architecture and Functionalities of IBM ECM
In the contemporary enterprise landscape, managing information efficiently is a challenge of escalating complexity. IBM Enterprise Content Management offers a sophisticated ecosystem designed to capture, organize, and deliver content across multifarious organizational touchpoints. Its architecture is predicated on the seamless integration of document management, records retention, imaging solutions, and workflow orchestration, forming a resilient backbone that supports operational excellence. By attaining technical mastery in this environment, professionals acquire not only operational dexterity but also the capacity to architect content strategies that elevate organizational performance.
At its core, IBM ECM encompasses repositories capable of housing both structured and unstructured data. These repositories facilitate rapid retrieval through the employment of advanced indexing methodologies and metadata tagging. The ability to structure these repositories with meticulous precision ensures that information is accessible, searchable, and contextually relevant. Professionals adept in this domain are able to calibrate the architecture to accommodate voluminous data streams while maintaining system responsiveness, an attribute crucial in high-demand environments such as finance, healthcare, and manufacturing.
The software’s functional breadth extends to robust workflow automation, enabling content to traverse predefined paths with minimal human intervention. Mastery in designing these workflows requires an intimate understanding of conditional routing, exception handling, and escalation procedures. By configuring these workflows strategically, enterprises mitigate operational latency, reduce errors, and enforce compliance consistently across departments. In addition, IBM ECM provides tools to monitor workflow efficacy, allowing continuous optimization and adaptation to evolving business processes.
Capturing and Managing Content Efficiently
One of the pivotal aspects of technical mastery lies in the capability to capture content efficiently. IBM ECM offers multiple ingestion methods, including digital scanning, electronic document transfer, and direct system integration. By mastering these processes, professionals can ensure that content enters the repository in a structured, retrievable, and compliant manner. Attention to metadata is paramount; crafting precise metadata schemas not only enhances discoverability but also facilitates downstream analytics, enabling organizations to extract actionable insights from otherwise opaque data reservoirs.
Content management extends beyond mere storage. Version control is an integral component of IBM ECM, allowing professionals to maintain historical records of documents, track changes, and revert to prior iterations when necessary. This functionality is crucial for collaborative environments where multiple stakeholders engage with the same documents. Mastery involves configuring version control parameters that balance data integrity with operational efficiency, ensuring that system performance remains optimal even under intensive usage scenarios.
Moreover, content management includes adherence to retention policies and regulatory compliance. Professionals trained in technical mastery understand how to implement retention schedules that align with organizational policies and statutory requirements. Automated disposition, audit trails, and access control mechanisms fortify content governance, mitigating risks associated with information loss, unauthorized access, or regulatory infractions. These capabilities highlight the symbiotic relationship between operational proficiency and strategic oversight in the realm of enterprise content management.
Optimizing Workflows and Automation
Workflow optimization is a hallmark of mastery in IBM ECM. Professionals learn to analyze organizational processes, identify bottlenecks, and implement automated pathways that accelerate document handling while reducing human error. Workflow configuration in IBM ECM allows for nuanced conditional logic, where documents may follow divergent paths based on attributes such as department, content type, or priority. Escalation mechanisms ensure that overdue tasks are flagged and addressed promptly, maintaining continuity in operations.
The implementation of automated notifications, reminders, and task assignments exemplifies how ECM can harmonize communication across teams. Mastery entails understanding the interplay between workflow triggers, document status updates, and system notifications, enabling administrators to maintain operational coherence even in complex, multi-departmental environments. Professionals capable of orchestrating these workflows contribute to both tactical efficiency and strategic agility, facilitating rapid adaptation to dynamic business conditions.
Additionally, the integration of analytics within workflows allows organizations to monitor process efficiency and identify opportunities for continuous improvement. By examining system logs, performance metrics, and throughput data, professionals can implement iterative enhancements, ensuring that workflows remain aligned with evolving organizational priorities. This analytical aptitude distinguishes technically proficient individuals from those with superficial operational knowledge, underscoring the depth of understanding required for mastery.
Ensuring Security and Compliance
Security and compliance are paramount in any enterprise content management endeavor. IBM ECM offers a comprehensive security framework encompassing authentication, authorization, encryption, and audit capabilities. Professionals pursuing technical mastery acquire the ability to configure access controls at granular levels, ensuring that sensitive content is visible only to authorized personnel. By implementing role-based permissions, organizations can balance operational accessibility with stringent confidentiality requirements.
Compliance management is closely intertwined with security. Regulatory frameworks such as HIPAA, GDPR, and Sarbanes-Oxley necessitate meticulous content governance. Technical mastery equips professionals to design systems that automatically enforce retention schedules, generate audit reports, and maintain immutable records for regulatory inspections. This capability not only mitigates legal risks but also reinforces organizational accountability and trustworthiness. The combination of security, compliance, and operational agility positions IBM ECM as an indispensable asset for enterprises navigating complex legal and operational landscapes.
Integration and Interoperability with Enterprise Systems
A critical dimension of mastery involves integrating IBM ECM with other enterprise platforms. Organizations often rely on ERP, CRM, and collaborative tools that generate and consume vast quantities of data. IBM ECM facilitates seamless interoperability, enabling content to flow unobstructed between systems. Professionals with technical mastery are adept at configuring these integrations, ensuring that data remains consistent, accurate, and synchronized across all platforms.
Integration extends to cloud environments and mobile frameworks, supporting flexible, distributed workforces. Mastery in IBM ECM encompasses understanding API connectivity, data mapping, and system orchestration, allowing organizations to leverage the full potential of digital transformation initiatives. The ability to harmonize ECM with disparate systems transforms content management from a siloed operational function into a strategic enabler of enterprise-wide efficiency, visibility, and agility.
Enhancing Decision-Making through Content Intelligence
IBM ECM provides tools that enable organizations to convert static content into actionable intelligence. Advanced search capabilities, coupled with metadata-driven insights, allow professionals to uncover trends, patterns, and anomalies within enterprise data. Mastery in this domain involves configuring content analytics, developing reporting dashboards, and extracting insights that inform operational and strategic decisions.
By leveraging ECM for content intelligence, organizations can anticipate operational challenges, optimize resource allocation, and improve customer engagement. Professionals skilled in these capabilities bridge the gap between information management and strategic foresight, transforming raw data into a catalyst for informed decision-making. This function is particularly valuable in sectors such as finance and healthcare, where timely access to accurate information can profoundly impact outcomes.
Career Advantages and Industry Recognition
Achieving technical mastery in IBM ECM significantly elevates career prospects. Certified professionals are recognized as experts capable of architecting and managing complex content management ecosystems. They are often entrusted with leading implementation projects, training personnel, and advising executive leadership on technology strategies. The breadth of knowledge acquired enables them to operate across industries, including finance, government, healthcare, and manufacturing, where content management challenges are both ubiquitous and critical.
Mastery in IBM ECM not only confers operational authority but also enhances professional credibility. Organizations value individuals who can reduce inefficiencies, enforce compliance, and drive digital transformation initiatives. Consequently, certified professionals enjoy access to senior technical roles, consulting opportunities, and strategic advisory positions. Their ability to translate technological potential into tangible organizational benefits renders them indispensable assets within any enterprise ecosystem.
Enhancing Enterprise Efficiency through IBM ECM
The contemporary enterprise environment is characterized by voluminous data inflows and intricate operational processes, necessitating sophisticated mechanisms for content management. IBM Enterprise Content Management provides a robust platform designed to capture, organize, and disseminate information with precision and agility. Attaining mastery in this environment equips professionals with the capacity to architect intricate repositories, optimize workflows, and implement security measures that safeguard organizational knowledge. This technical acumen transcends mere software navigation, empowering individuals to align content strategies with overarching business objectives.
The architecture of IBM ECM is meticulously crafted to accommodate diverse content types, encompassing structured documents, unstructured data, multimedia files, and transactional records. Mastery involves understanding how these varied content forms interact within a unified repository, ensuring seamless accessibility, consistent version control, and rapid retrieval. The configuration of indexing methodologies, metadata schemas, and search parameters is central to optimizing system performance, particularly in enterprises with high-volume content ecosystems. Professionals skilled in this domain can orchestrate repositories to balance storage efficiency with operational agility, mitigating latency and enhancing overall productivity.
Workflow orchestration constitutes another critical competency. IBM ECM enables the automation of complex processes, facilitating the movement of content through predetermined routes with minimal manual intervention. Mastery in workflow design entails configuring conditional logic, exception handling, and escalation mechanisms, thereby ensuring that operational bottlenecks are minimized. By monitoring workflow efficacy and implementing iterative refinements, professionals enhance process reliability, enforce compliance, and foster a culture of operational excellence.
Content Capture and Lifecycle Management
Effective content management begins with precise capture mechanisms. IBM ECM provides multiple ingestion pathways, including scanning, electronic document transfer, and direct system integration, ensuring that information enters the repository in a structured and retrievable form. Mastery involves not only the technical implementation of these methods but also the strategic consideration of metadata, classification schemes, and indexing to optimize discoverability and analytical potential.
Lifecycle management extends beyond capture, encompassing version control, retention policies, and content disposition. Professionals adept in IBM ECM configure repositories to maintain historical records, track modifications, and implement automated retention schedules. These capabilities are vital in collaborative environments, regulatory contexts, and industries with stringent compliance obligations. By mastering lifecycle management, professionals ensure that content remains secure, accessible, and auditable, transforming data into a strategic asset rather than a procedural burden.
In addition to operational control, lifecycle management enables predictive analysis and proactive decision-making. Metadata tagging and advanced indexing facilitate the extraction of actionable insights, allowing organizations to anticipate trends, monitor performance, and respond to emerging challenges. Professionals who leverage these capabilities convert information into intelligence, supporting strategic initiatives and fostering enterprise resilience.
Security, Compliance, and Risk Mitigation
Security and compliance are central to IBM ECM mastery. The platform offers a comprehensive framework encompassing authentication, role-based access control, encryption, audit trails, and regulatory compliance enforcement. Professionals trained in technical mastery can implement granular permissions, safeguarding sensitive content while ensuring operational accessibility.
Compliance management extends to adherence with statutory requirements and industry standards, including data protection regulations and corporate governance mandates. Mastery involves configuring automated retention schedules, ensuring immutable audit trails, and implementing reporting mechanisms that facilitate regulatory inspections. By combining security, compliance, and operational oversight, professionals mitigate risks associated with data breaches, legal infractions, and reputational damage.
A nuanced aspect of security mastery involves threat anticipation and proactive system monitoring. Professionals analyze access logs, transaction histories, and workflow patterns to identify anomalies, unauthorized activity, or inefficiencies. By implementing corrective measures and reinforcing security protocols, they fortify organizational resilience against internal and external threats, demonstrating a depth of expertise that transcends routine administrative functions.
Advanced Workflow Automation
The orchestration of workflows within IBM ECM embodies both operational efficiency and strategic foresight. Professionals master the configuration of complex processes, integrating conditional routing, parallel processing, and escalation triggers to ensure content moves swiftly and accurately across organizational layers. These workflows reduce human error, accelerate decision-making, and maintain compliance with regulatory standards.
Advanced workflow mastery also involves integrating notifications, task assignments, and progress tracking. Professionals ensure that all stakeholders are informed, deadlines are adhered to, and exceptions are addressed promptly. By monitoring workflow performance metrics, analyzing throughput data, and iteratively refining processes, they create a dynamic system capable of adapting to organizational evolution and external market pressures.
Automation in content management extends to intelligent classification, automated indexing, and metadata tagging. These capabilities enable repositories to self-organize, enhancing search efficiency, facilitating analytics, and improving operational responsiveness. Mastery in these domains allows professionals to reduce manual intervention, optimize resource allocation, and ensure that information remains both accessible and actionable.
Integration with Enterprise Systems
IBM ECM’s true potential is realized when integrated with broader enterprise ecosystems. Organizations frequently rely on ERP, CRM, collaboration platforms, and cloud-based services, creating complex information flows. Professionals with technical mastery are adept at configuring seamless integrations, ensuring consistent data synchronization, accurate content migration, and uninterrupted accessibility.
Integration extends to mobile frameworks, supporting distributed workforces and remote access requirements. Mastery includes understanding API connectivity, data mapping, and interoperability standards, enabling content to flow fluidly across systems while maintaining security and compliance. This capability transforms ECM from a siloed operational tool into a strategic enabler, supporting digital transformation, process optimization, and knowledge-driven decision-making.
Furthermore, integration facilitates advanced analytics and reporting. By harmonizing content across systems, professionals enable organizations to generate real-time insights, track operational performance, and evaluate process efficiency. These insights inform strategic initiatives, resource allocation, and risk mitigation strategies, reinforcing the value of ECM mastery beyond conventional operational benefits.
Content Intelligence and Analytics
IBM ECM provides sophisticated tools to transform content into actionable intelligence. Advanced search functionalities, coupled with metadata-driven analytics, allow organizations to uncover patterns, identify trends, and anticipate operational needs. Mastery in this domain involves configuring analytics modules, generating comprehensive reports, and integrating insights into strategic planning processes.
By leveraging content intelligence, organizations can optimize workflows, enhance customer engagement, and improve decision-making quality. Professionals skilled in these capabilities bridge the gap between operational content management and strategic foresight, ensuring that enterprise knowledge is leveraged effectively to drive competitive advantage. This intelligence-centric approach is particularly valuable in industries where timely access to accurate information underpins operational and financial outcomes.
Troubleshooting and System Optimization
Technical mastery also encompasses advanced troubleshooting and system optimization. Professionals are trained to identify and resolve performance bottlenecks, system errors, and content inconsistencies. By analyzing transaction logs, workflow metrics, and repository structures, they diagnose issues with precision and implement corrective actions that minimize downtime and maintain operational continuity.
System optimization involves tuning repository configurations, refining indexing strategies, and adjusting workflow parameters to maximize efficiency. Professionals also evaluate integration points, ensuring that content flows seamlessly across interconnected systems. This proactive approach ensures that ECM deployments remain robust, scalable, and aligned with evolving organizational demands, highlighting the depth of expertise required for technical mastery.
Strategic Applications and Industry Impact
Mastery in IBM ECM translates into tangible benefits across multiple industries. In healthcare, ECM enables secure management of patient records, regulatory compliance, and rapid retrieval for clinical decision-making. In finance, it supports audit readiness, regulatory adherence, and risk mitigation. Manufacturing and logistics enterprises utilize ECM for quality control documentation, contract management, and supply chain visibility.
Professionals adept in ECM not only optimize operational processes but also contribute to strategic initiatives. Their expertise allows organizations to harness content intelligence, improve governance, and align technological capabilities with corporate objectives. The combination of operational acumen, strategic insight, and technological proficiency underscores the transformative potential of technical mastery within contemporary enterprises.
Leveraging IBM ECM for Organizational Excellence
In contemporary enterprises, information is both an asset and a challenge, requiring sophisticated methods to capture, organize, and deliver content with precision and efficiency. IBM Enterprise Content Management provides a robust framework that enables organizations to manage diverse types of content seamlessly, including structured documents, unstructured data, multimedia files, and transactional records. Achieving technical mastery in this domain equips professionals with the expertise to configure repositories, optimize workflows, ensure compliance, and facilitate strategic decision-making.
The architecture of IBM ECM is meticulously designed to balance performance, scalability, and security. Repositories form the core of the system, allowing content to be stored, indexed, and retrieved with remarkable speed and accuracy. Professionals with deep technical understanding can design hierarchical storage structures, implement advanced metadata schemes, and refine indexing strategies to ensure that content remains accessible and searchable even in large-scale deployments. By configuring repositories thoughtfully, organizations minimize latency, prevent redundancy, and maintain operational fluidity across diverse departments.
Workflow automation represents another critical dimension of mastery. IBM ECM enables the design of intricate workflows that guide content through predefined routes, incorporating conditional logic, escalation triggers, and exception handling. This functionality not only expedites processes but also reduces the likelihood of human error. Professionals skilled in workflow orchestration can map complex organizational processes into automated sequences, ensuring content reaches the appropriate stakeholders promptly while maintaining a comprehensive audit trail for compliance and governance purposes.
Capturing and Structuring Content for Maximum Efficiency
Effective content management begins with precise capture and structuring. IBM ECM supports a variety of ingestion methods, including scanning, electronic transfers, and direct system integrations, each ensuring that information enters repositories in a structured, retrievable format. Mastery involves not only technical competence but also the strategic application of metadata and classification schemes to optimize discoverability and enable analytics.
Content lifecycle management extends beyond initial capture to encompass version control, retention, and eventual disposition. Professionals adept in IBM ECM configure repositories to maintain detailed historical records, monitor revisions, and enforce automated retention schedules. These practices are crucial in environments requiring collaboration among multiple stakeholders or adherence to regulatory mandates. By mastering content lifecycle management, professionals transform data into a strategic resource that supports operational efficiency, mitigates compliance risks, and enhances decision-making capabilities.
Strategic metadata utilization is another hallmark of technical proficiency. By implementing nuanced metadata structures, professionals enhance search functionality, enable predictive analytics, and facilitate intelligent content categorization. These strategies allow organizations to leverage their content as an analytical tool, identifying patterns, trends, and operational insights that inform both tactical and strategic initiatives.
Ensuring Security, Compliance, and Governance
Security and compliance are inseparable elements of enterprise content management. IBM ECM provides an extensive suite of security features, including authentication, role-based access control, encryption, and audit logging. Professionals achieving technical mastery are capable of implementing intricate access hierarchies, ensuring sensitive information is protected while remaining accessible to authorized personnel.
Compliance encompasses adherence to regulatory requirements, corporate governance standards, and internal policies. Mastery involves configuring automated retention schedules, immutable audit trails, and comprehensive reporting mechanisms. By enforcing these protocols, professionals mitigate legal and operational risks, maintain accountability, and strengthen organizational trust. A sophisticated understanding of compliance management also entails proactive monitoring for anomalies, identifying potential security threats, and implementing preventative measures to maintain system integrity.
The integration of security and compliance within operational workflows enhances organizational resilience. By embedding controls into automated processes, professionals ensure that content handling, approval mechanisms, and retrieval practices are consistent, auditable, and aligned with industry regulations. This holistic approach underscores the strategic value of technical mastery, where operational efficiency and regulatory adherence are intertwined.
Workflow Optimization and Process Intelligence
IBM ECM enables organizations to transform routine operational processes through intelligent workflow automation. Professionals with advanced expertise configure workflows that incorporate conditional branching, parallel processing, escalation paths, and automated notifications. By doing so, content navigates complex organizational structures efficiently, reducing bottlenecks and ensuring that critical information reaches stakeholders in a timely manner.
Workflow monitoring and continuous optimization are integral to technical mastery. Professionals analyze performance metrics, identify inefficiencies, and refine processes iteratively. The integration of analytics into workflows allows organizations to assess throughput, track completion times, and evaluate compliance adherence. This analytical approach ensures that workflows are not static but evolve to meet organizational needs and external demands, reinforcing operational agility and strategic responsiveness.
Automated content classification, metadata tagging, and indexing further enhance workflow efficiency. By reducing manual intervention, professionals enable the system to self-organize, streamline search and retrieval, and facilitate downstream analytics. Mastery in these areas demonstrates the ability to orchestrate a system that operates with minimal human dependency while delivering maximal operational impact.
Integration with Enterprise Ecosystems
IBM ECM attains its full potential when integrated with other enterprise systems. Modern organizations operate within interconnected ecosystems comprising ERP, CRM, collaboration platforms, and cloud services. Technical mastery involves ensuring seamless interoperability, accurate data synchronization, and consistent accessibility across these systems.
Integration extends to mobile and remote environments, supporting distributed teams and dynamic workflows. Professionals proficient in IBM ECM understand API connectivity, data mapping, and integration protocols, enabling content to flow unobstructed while maintaining security and compliance. This capability transforms content management from a static repository into a dynamic strategic asset, underpinning digital transformation initiatives, enhancing operational efficiency, and enabling knowledge-driven decision-making.
Integration also supports advanced analytics, enabling organizations to consolidate insights across multiple systems. By harmonizing content from diverse sources, professionals facilitate real-time reporting, performance monitoring, and predictive analysis. These insights inform resource allocation, strategic planning, and operational adjustments, highlighting the strategic significance of technical mastery beyond mere operational competency.
Harnessing Content Intelligence and Analytics
IBM ECM provides tools to convert stored content into actionable intelligence. Advanced search capabilities, combined with metadata-driven analytics, allow organizations to detect patterns, identify trends, and anticipate operational needs. Mastery in this domain involves configuring analytics modules, developing insightful reports, and integrating findings into organizational strategy.
Content intelligence enables predictive decision-making, enhances process efficiency, and supports customer engagement initiatives. Professionals skilled in these capabilities bridge the gap between operational management and strategic foresight, ensuring that organizational knowledge is utilized effectively to create competitive advantages. The ability to leverage content as an analytical instrument distinguishes technically proficient professionals from those with superficial operational understanding.
Intelligent content analytics also supports compliance monitoring, risk assessment, and workflow optimization. By analyzing repository usage, access patterns, and metadata trends, professionals can identify potential inefficiencies or regulatory deviations, implementing corrective measures proactively. This capability underscores the transformative potential of ECM mastery in fostering resilient, data-driven enterprises.
Troubleshooting and Performance Optimization
Achieving technical mastery entails advanced problem-solving and system optimization skills. Professionals are trained to diagnose performance bottlenecks, resolve errors, and maintain repository integrity. By analyzing transaction logs, workflow metrics, and repository configurations, they identify inefficiencies and implement corrective actions that ensure continuous operational continuity.
Performance optimization extends to repository tuning, indexing refinement, and workflow enhancement. Professionals evaluate integration points, optimize search efficiency, and streamline content retrieval mechanisms. This proactive approach ensures that ECM systems remain robust, scalable, and responsive, even in the face of growing data volumes and increasingly complex enterprise processes.
Additionally, troubleshooting requires a comprehensive understanding of interdependencies within the ECM ecosystem. Professionals consider the interplay between content capture, repository management, workflow orchestration, integration, and analytics when diagnosing issues. This holistic perspective is indicative of true mastery, where technical expertise is applied strategically to maintain system reliability, enhance efficiency, and support organizational objectives.
Strategic Applications Across Industries
IBM ECM’s technical mastery translates into tangible operational and strategic benefits across diverse sectors. In healthcare, ECM enables secure management of patient records, regulatory compliance, and rapid access for clinical decisions. Financial institutions utilize ECM for audit readiness, compliance adherence, and risk mitigation, while manufacturing and logistics enterprises rely on ECM to manage quality control documentation, supply chain data, and contractual information.
Professionals proficient in ECM not only optimize operational workflows but also contribute to strategic initiatives. By leveraging content intelligence, ensuring compliance, and facilitating integration across systems, they enable organizations to make informed decisions, improve governance, and drive innovation. The ability to harness ECM as a strategic enabler underscores its transformative potential and the value of attaining technical mastery.
Advancing Operational Efficiency through IBM ECM
The modern enterprise environment is inundated with complex data flows and diverse content types that demand sophisticated management solutions. IBM Enterprise Content Management provides a comprehensive platform designed to capture, store, organize, and disseminate content with accuracy and efficiency. Technical mastery in this domain equips professionals to design repositories, automate workflows, enforce compliance, and harness content as a strategic asset, enabling organizations to optimize operational performance and maintain a competitive edge.
The architecture of IBM ECM is engineered to balance scalability, speed, and security, allowing it to accommodate both structured and unstructured data with equal efficacy. Repositories form the backbone of the system, facilitating rapid retrieval, precise indexing, and version control. Professionals with deep technical understanding can design hierarchical storage frameworks, implement metadata schemas, and optimize search algorithms to ensure seamless access to critical information. By configuring these repositories effectively, organizations reduce latency, prevent redundancy, and enhance operational continuity across diverse departments.
Workflow automation is a pivotal component of ECM, allowing content to traverse complex organizational structures with minimal human intervention. Mastery in workflow orchestration involves configuring conditional routing, parallel processing, escalation triggers, and exception handling. This ensures that information reaches the appropriate stakeholders efficiently while maintaining comprehensive audit trails. By continuously monitoring workflow efficacy and implementing iterative improvements, professionals enhance operational reliability, reduce bottlenecks, and facilitate adherence to regulatory mandates.
Content Capture and Lifecycle Management
Effective content management begins with precise capture mechanisms and intelligent structuring. IBM ECM supports multiple ingestion pathways, including scanning, electronic document transfer, and direct system integration, ensuring that information is captured accurately and stored in a retrievable format. Mastery involves strategic utilization of metadata, classification systems, and indexing methods to optimize discoverability and enable advanced analytics.
Lifecycle management extends beyond initial capture to encompass version control, retention, archiving, and eventual disposition. Professionals adept in IBM ECM configure repositories to maintain detailed historical records, monitor revisions, and implement automated retention schedules that align with organizational policies and compliance requirements. This ensures that content remains secure, auditable, and operationally useful throughout its lifecycle. By mastering these capabilities, professionals transform static content into a dynamic organizational asset that supports decision-making, reduces redundancy, and mitigates risk.
Metadata modeling is a critical aspect of lifecycle management. By implementing complex metadata structures, professionals enhance search functionality, facilitate intelligent content categorization, and enable predictive analytics. This approach allows organizations to harness content as an analytical tool, identify emerging patterns, optimize resource allocation, and anticipate operational challenges. Mastery in metadata strategy distinguishes individuals who can leverage content for strategic insight from those who operate at a purely functional level.
Security, Compliance, and Governance
Security and compliance are integral to effective content management. IBM ECM provides a robust framework for authentication, authorization, encryption, and audit logging. Professionals with technical mastery configure role-based access controls, ensuring that sensitive content remains protected while remaining accessible to authorized users. By enforcing these security measures, organizations reduce the risk of data breaches, maintain operational integrity, and strengthen stakeholder trust.
Compliance extends beyond security to include adherence to regulatory frameworks, internal governance policies, and industry standards. Mastery involves implementing automated retention schedules, immutable audit trails, and reporting mechanisms that facilitate inspections and audits. By embedding compliance into operational workflows, professionals ensure that content handling practices are consistent, auditable, and aligned with regulatory mandates. Proactive monitoring and anomaly detection further strengthen compliance, allowing organizations to anticipate risks and respond with agility.
Governance practices within IBM ECM also include content classification, policy enforcement, and access oversight. Professionals adept in these areas create structured processes that balance operational efficiency with regulatory adherence, ensuring that content management supports strategic organizational objectives while mitigating legal and operational risks.
Workflow Optimization and Process Intelligence
IBM ECM empowers organizations to transform operational workflows through intelligent automation. Professionals with advanced expertise design workflows incorporating conditional logic, parallel processing, escalation mechanisms, and automated notifications. This ensures that content moves efficiently through organizational hierarchies, reducing bottlenecks, minimizing errors, and maintaining process continuity.
Continuous workflow optimization is a hallmark of technical mastery. By analyzing performance metrics, throughput data, and compliance adherence, professionals identify inefficiencies and implement iterative improvements. Integration of analytics within workflows allows organizations to monitor progress, forecast operational needs, and optimize resource allocation. These insights facilitate adaptive workflows that respond dynamically to evolving organizational demands and external pressures, reinforcing operational resilience and strategic agility.
Advanced automation includes intelligent content categorization, metadata tagging, and indexing, reducing manual intervention and enhancing system self-organization. Professionals with mastery configure these features to optimize search efficiency, streamline retrieval, and support downstream analytics, creating a content management ecosystem that operates autonomously while maximizing operational impact.
Integration and Interoperability with Enterprise Systems
IBM ECM achieves its full potential when integrated with broader enterprise ecosystems. Modern organizations rely on interconnected systems, including ERP, CRM, collaborative platforms, and cloud services. Professionals with technical mastery ensure seamless interoperability, accurate data synchronization, and consistent content accessibility across these platforms.
Integration extends to mobile and remote environments, supporting distributed teams and dynamic workflows. Mastery includes expertise in API connectivity, data mapping, and system orchestration, enabling content to flow unobstructed while maintaining security and compliance. This transforms ECM from a static repository into a strategic organizational asset, facilitating digital transformation, enhancing operational efficiency, and enabling informed, knowledge-driven decision-making.
Integrated ECM also supports advanced analytics by consolidating content from multiple systems. By harmonizing diverse data streams, professionals enable real-time reporting, operational monitoring, and predictive analysis. These insights inform strategic initiatives, resource allocation, and risk management, demonstrating the profound impact of technical mastery beyond conventional content management functions.
Content Intelligence and Analytics
IBM ECM offers powerful tools to convert stored content into actionable intelligence. Advanced search capabilities, coupled with metadata-driven analytics, allow organizations to identify trends, detect anomalies, and anticipate operational requirements. Mastery involves configuring analytics modules, generating comprehensive reports, and integrating insights into strategic decision-making processes.
Content intelligence facilitates predictive planning, enhances operational efficiency, and improves customer engagement. Professionals skilled in these capabilities bridge the divide between routine content management and strategic foresight, ensuring that organizational knowledge is leveraged effectively to create competitive advantages. By analyzing repository usage, access patterns, and workflow efficiency, professionals can proactively identify areas for improvement and implement corrective measures, reinforcing organizational resilience and performance.
Troubleshooting and System Optimization
Technical mastery also encompasses advanced troubleshooting and system optimization. Professionals are trained to diagnose performance bottlenecks, resolve operational errors, and maintain repository integrity. By evaluating transaction logs, workflow metrics, and repository configurations, they identify inefficiencies and implement corrective actions that ensure uninterrupted operations.
Optimization extends to repository tuning, indexing refinement, workflow enhancement, and integration evaluation. Professionals proactively refine system parameters to maximize search efficiency, streamline content retrieval, and maintain performance under heavy workloads. This approach ensures that ECM deployments remain robust, scalable, and aligned with evolving organizational demands, demonstrating the strategic value of technical expertise.
Holistic troubleshooting considers interdependencies across the ECM ecosystem. Professionals evaluate content capture, workflow orchestration, repository management, integration, and analytics collectively when addressing issues. This comprehensive perspective is indicative of true mastery, reflecting the ability to maintain system reliability, enhance operational efficiency, and support long-term organizational objectives.
Strategic Applications Across Industries
IBM ECM’s technical mastery produces tangible benefits across diverse industries. In healthcare, ECM ensures secure patient record management, regulatory compliance, and rapid access for clinical decision-making. Financial institutions rely on ECM for audit readiness, regulatory adherence, and risk mitigation. Manufacturing, logistics, and supply chain enterprises utilize ECM to manage quality control documentation, contracts, and operational records efficiently.
Professionals with mastery optimize workflows, implement compliance measures, and integrate content systems with broader enterprise architectures. They enable organizations to leverage content intelligence for strategic planning, operational refinement, and informed decision-making. The transformative potential of IBM ECM underscores the significance of technical mastery in driving operational excellence, governance, and innovation within contemporary enterprises.
Elevating Organizational Performance through IBM ECM
In the contemporary business ecosystem, enterprises confront an ever-expanding influx of information, necessitating sophisticated content management frameworks. IBM Enterprise Content Management offers a comprehensive solution to capture, store, organize, and deliver information seamlessly across organizational structures. Achieving technical mastery in this domain equips professionals with the expertise to architect repositories, automate workflows, ensure regulatory compliance, and leverage content intelligence to inform strategic decisions. Mastery transcends operational proficiency, positioning individuals as pivotal contributors to organizational efficiency, innovation, and competitiveness.
The architecture of IBM ECM is meticulously engineered to accommodate both structured and unstructured content. Repositories serve as the operational backbone, facilitating precise indexing, version control, and rapid retrieval. Professionals adept in the system design hierarchical storage schemas, metadata configurations, and indexing algorithms to optimize search efficiency and maintain operational fluidity. By calibrating repositories thoughtfully, organizations reduce redundancy, prevent latency, and sustain seamless information flows across departments, enhancing decision-making agility and operational cohesion.
Workflow orchestration is integral to content management efficiency. IBM ECM allows the creation of sophisticated automated workflows incorporating conditional logic, escalation mechanisms, parallel processing, and exception handling. Mastery involves not only the technical design but also strategic alignment of workflows with organizational objectives. Professionals ensure that information reaches stakeholders promptly, while audit trails and reporting mechanisms maintain transparency, accountability, and regulatory adherence.
Content Capture and Structured Management
Effective content management begins with precise capture mechanisms and strategic organization. IBM ECM supports diverse ingestion methodologies, including scanning, electronic document transfer, and direct integration with enterprise systems. Professionals mastering these processes ensure content enters repositories accurately, consistently, and in a form optimized for retrieval and analysis. Metadata strategies and classification schemas play a pivotal role in enhancing discoverability, enabling content intelligence, and facilitating predictive analytics.
Lifecycle management encompasses capture, storage, versioning, retention, archiving, and disposition. Mastery in this domain equips professionals to configure repositories that maintain historical records, monitor revisions, and implement automated retention schedules aligned with regulatory mandates. By overseeing the entire lifecycle, individuals ensure content remains secure, auditable, and operationally relevant throughout its existence. Advanced metadata utilization further enhances the ability to categorize content intelligently, support analytics, and extract actionable insights from organizational information assets.
Organizations benefit from professionals capable of leveraging content to anticipate trends, optimize resource allocation, and enhance decision-making. Metadata-driven insights enable predictive planning, operational optimization, and early identification of potential inefficiencies or risks. Mastery in these competencies transforms content from a passive operational requirement into a strategic asset that drives performance and fosters innovation.
Security, Compliance, and Risk Management
Security and compliance are foundational pillars of effective enterprise content management. IBM ECM provides robust capabilities encompassing authentication, authorization, encryption, and audit logging. Professionals with technical mastery implement granular role-based access controls, safeguarding sensitive content while maintaining accessibility for authorized stakeholders. Effective security frameworks mitigate operational risks, preserve organizational integrity, and strengthen trust across internal and external constituencies.
Compliance management integrates regulatory adherence, governance protocols, and industry standards. Mastery involves the deployment of automated retention schedules, immutable audit trails, and reporting mechanisms capable of satisfying regulatory inspections. Embedding compliance within operational workflows ensures that all content handling practices are consistent, auditable, and aligned with legal and corporate requirements. Proactive monitoring, anomaly detection, and timely remediation constitute an advanced layer of compliance management, reinforcing organizational resilience and operational reliability.
Governance strategies within IBM ECM extend to classification policies, content lifecycle oversight, and policy enforcement. Professionals skilled in these areas create structured processes that balance operational efficiency with regulatory compliance, ensuring that content management supports organizational objectives while minimizing legal and operational risk. The strategic integration of security, compliance, and governance enhances both efficiency and trust, reinforcing the value of technical mastery in contemporary enterprises.
Workflow Automation and Operational Intelligence
IBM ECM empowers organizations to optimize workflows through automation, enabling content to traverse complex structures efficiently. Mastery involves designing workflows incorporating conditional branching, parallel processing, escalation pathways, and automated notifications. These automated sequences ensure information reaches the correct stakeholders in a timely manner, reducing bottlenecks, minimizing errors, and enhancing operational transparency.
Workflow monitoring and iterative optimization are essential elements of technical proficiency. By analyzing performance metrics, throughput data, and compliance adherence, professionals identify inefficiencies and implement refinements to improve operational performance. Integrated analytics within workflows allow organizations to forecast operational needs, optimize resource allocation, and respond dynamically to internal and external pressures. Advanced automation further enhances workflow efficiency, including intelligent classification, metadata tagging, and automated indexing, allowing content management systems to self-organize and function with minimal human intervention.
The integration of workflow intelligence with operational reporting enables organizations to visualize process efficiency, identify areas for improvement, and implement proactive strategies. Professionals capable of harnessing these insights position organizations for sustained growth, resilience, and strategic adaptability.
Integration with Enterprise Ecosystems
IBM ECM reaches its full potential when integrated with other enterprise platforms. Organizations typically operate in interconnected ecosystems consisting of ERP, CRM, collaboration tools, and cloud-based services. Technical mastery involves ensuring seamless interoperability, accurate data synchronization, and uninterrupted content accessibility across these platforms.
Integration also extends to mobile and distributed environments, supporting remote workforces and dynamic operational requirements. Professionals leverage API connectivity, data mapping, and system orchestration to enable content flow without compromising security or compliance. This integration transforms ECM from a repository-centric system into a strategic enabler, enhancing operational efficiency, supporting digital transformation initiatives, and empowering knowledge-driven decision-making.
Unified ECM ecosystems facilitate advanced analytics by consolidating data streams from multiple sources. Professionals skilled in integration develop real-time reporting frameworks, monitor operational performance, and support predictive analytics. These capabilities inform strategic planning, resource optimization, and risk management, illustrating the transformative impact of technical mastery on organizational performance and resilience.
Content Intelligence and Predictive Analytics
IBM ECM equips organizations with tools to convert content into actionable intelligence. Advanced search capabilities combined with metadata-driven analytics allow the identification of patterns, detection of anomalies, and anticipation of operational needs. Mastery involves configuring analytics modules, generating comprehensive reports, and integrating insights into organizational strategy.
Content intelligence supports predictive decision-making, enhances operational efficiency, and improves customer engagement. Professionals skilled in these competencies bridge operational management with strategic foresight, ensuring that organizational knowledge is fully leveraged to drive competitive advantage. By monitoring repository usage, workflow patterns, and metadata trends, organizations can proactively address inefficiencies, optimize processes, and implement improvements that sustain long-term operational excellence.
Intelligent analytics also strengthen compliance monitoring, risk assessment, and workflow optimization. Professionals analyze data patterns to detect deviations, mitigate risks, and refine operational procedures. The ability to translate content into actionable intelligence exemplifies the strategic depth conferred by technical mastery, where information functions as both an operational tool and a catalyst for organizational advancement.
Troubleshooting and System Optimization
Technical mastery encompasses advanced problem-solving and system optimization capabilities. Professionals identify and resolve performance bottlenecks, correct operational errors, and maintain repository integrity. By analyzing transaction logs, workflow metrics, and repository configurations, they implement corrective measures that ensure continuity and reliability of operations.
Optimization extends to fine-tuning repository structures, refining indexing algorithms, enhancing workflow sequences, and evaluating integration points. These measures maintain high system performance, even under extensive data loads or complex operational requirements. Professionals adopt a holistic approach to troubleshooting, considering interdependencies across content capture, workflow orchestration, repository management, integration, and analytics. This comprehensive perspective ensures that ECM deployments are resilient, efficient, and capable of supporting evolving organizational objectives.
Strategic Applications and Industry Impact
IBM ECM technical mastery produces measurable benefits across a wide spectrum of industries. In healthcare, ECM enables secure patient record management, compliance with stringent regulations, and rapid access to critical information for clinical decisions. Financial institutions leverage ECM to maintain audit readiness, adhere to regulatory mandates, and mitigate operational risks. Manufacturing and logistics enterprises utilize ECM to manage contracts, quality control documentation, and supply chain information with precision and efficiency.
Professionals adept in IBM ECM not only optimize operational workflows but also contribute to organizational strategy. By leveraging content intelligence, integrating systems, and ensuring compliance, they facilitate informed decision-making, enhance governance, and drive innovation. This strategic application underscores the transformative potential of technical mastery, establishing ECM as both an operational and strategic pillar within modern enterprises.
Conclusion
Mastery in IBM Enterprise Content Management transcends basic software proficiency, encompassing operational excellence, strategic foresight, and advanced analytical capability. Professionals who achieve technical mastery are equipped to architect repositories, automate workflows, ensure compliance, optimize performance, and integrate ECM seamlessly with enterprise ecosystems. By transforming content into actionable intelligence, these individuals enable organizations to anticipate challenges, streamline operations, and make informed strategic decisions. Across industries ranging from healthcare to finance and manufacturing, the impact of technical mastery manifests in enhanced efficiency, regulatory adherence, and sustainable competitive advantage. As enterprises continue to grapple with the increasing complexity and volume of information, expertise in IBM ECM remains a vital asset, positioning certified professionals at the forefront of innovation, governance, and operational excellence.
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Top IBM Exams
IBM Certifications
- IBM Certified Administrator - Cloud Pak for Integration V2021.2
- IBM Certified Administrator - IBM Cloud Pak for Business Automation v21.0.3
- IBM Certified Administrator - IBM Cognos Analytics Administrator V11
- IBM Certified Administrator - Security QRadar SIEM V7.5
- IBM Certified Administrator - Spectrum Protect V8.1.9
- IBM Certified Advocate - Cloud v1
- IBM Certified Advocate - Cloud v2
- IBM Certified Application Developer - Curam SPM V7.X
- IBM Certified Associate Administrator - IBM QRadar SIEM V7.3.2
- IBM Certified Associate Analyst - IBM QRadar SIEM V7.3.2
- IBM Certified Associate Business Process Analyst - Curam V6.0.5
- IBM Certified BPM System Administration - Business Process Manager Advanced V8.5
- IBM Certified Data Engineer - Big Data
- IBM Certified Database Administrator - DB2 11 DBA for z/OS
- IBM Certified Database Associate - DB2 11 Fundamentals for z/OS
- IBM Certified Deployment Professional - FileNet P8 V5.5.3
- IBM Certified Deployment Professional - Maximo Asset Management v7.6 Functional Analyst
- IBM Certified Deployment Professional - Maximo Manage v8.0
- IBM Certified Deployment Professional - Security Access Manager V9.0
- IBM Certified Developer - Business Automation Workflow V20.0.0.2 using Workflow Center
- IBM Certified Mobile Application Developer - Mobile Foundation V8.0
- IBM Certified SOC Analyst - IBM QRadar SIEM V7.3.2
- IBM Certified Solution Advisor - Spectrum Storage V7
- IBM Certified Solution Architect - Cloud Pak for Integration v2021.4
- IBM Certified Solution Designer - Datacap V9.0
- IBM Certified Solution Developer - App Connect Enterprise V11
- IBM Certified Solution Developer - InfoSphere DataStage v11.3
- IBM Certified Solution Developer - Integration Bus v10.0
- IBM Certified Specialist - AI Enterprise Workflow V1
- IBM Certified Specialist - SPSS Modeler Professional v3
- IBM Certified System Administrator - MQ V9.0
- IBM Certified System Administrator - WebSphere Application Server Network Deployment V8.5.5 and Liberty Profile
- IBM Certified System Administrator - WebSphere Application Server Network Deployment V9.0
- IBM Certified Technical Advocate - Cloud v3
- IBM Cloud Pak for Data System V1.x Administrator Specialty
- IBM Enterprise Content Management - Software Technical Mastery
- IBM Mastery - IBM Mastery Test
- IBM Technical Mastery - IBM Watson Customer Engagement: Watson Supply Chain
