
Certification: VCS InfoScale
Certification Full Name: Veritas Certified Specialist InfoScale
Certification Provider: Veritas
Exam Code: VCS-260
Exam Name: Administration of Veritas InfoScale Availability 7.3 for UNIX/Linux
Product Screenshots
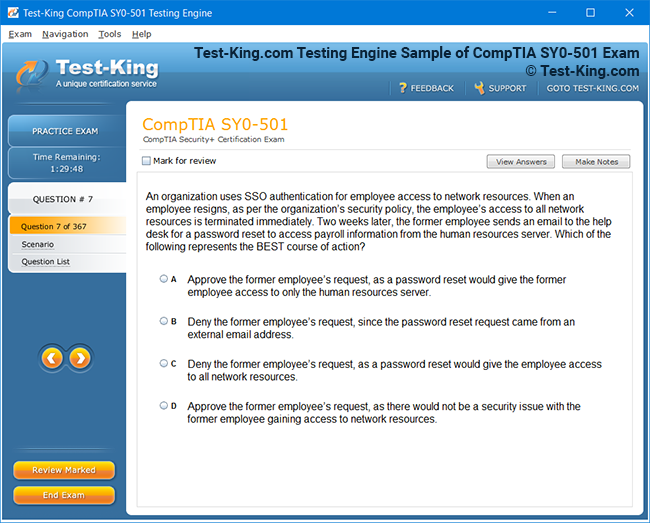
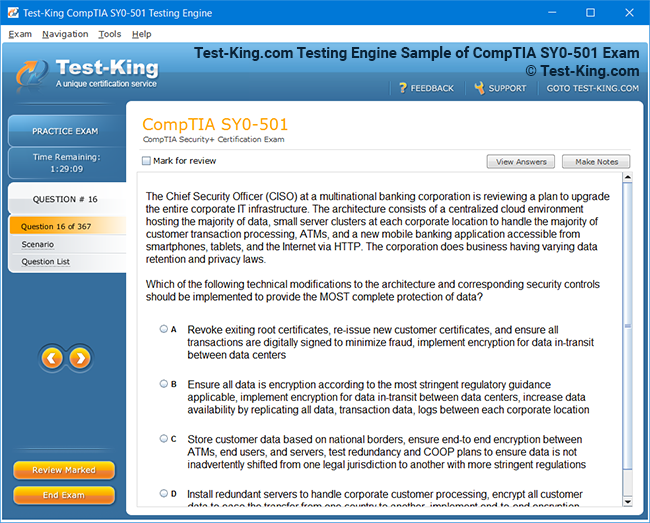
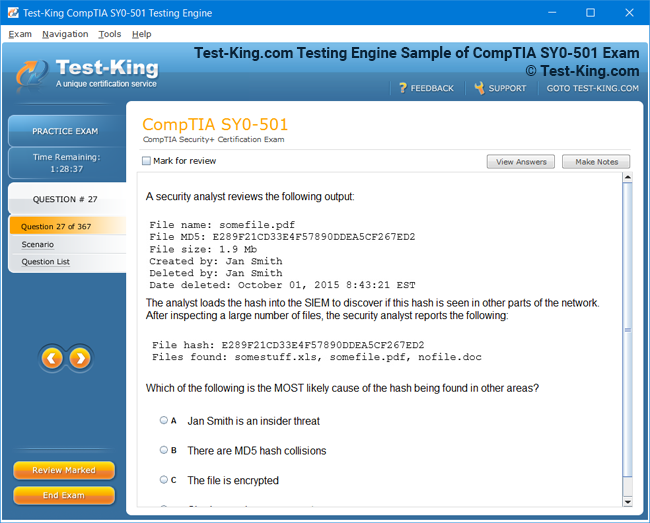
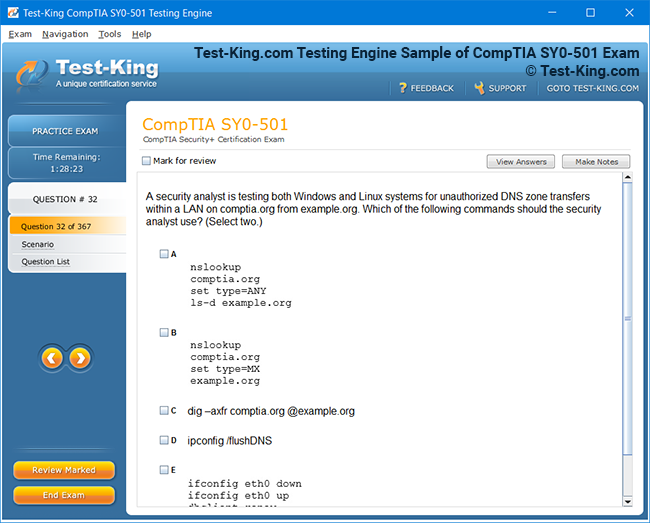
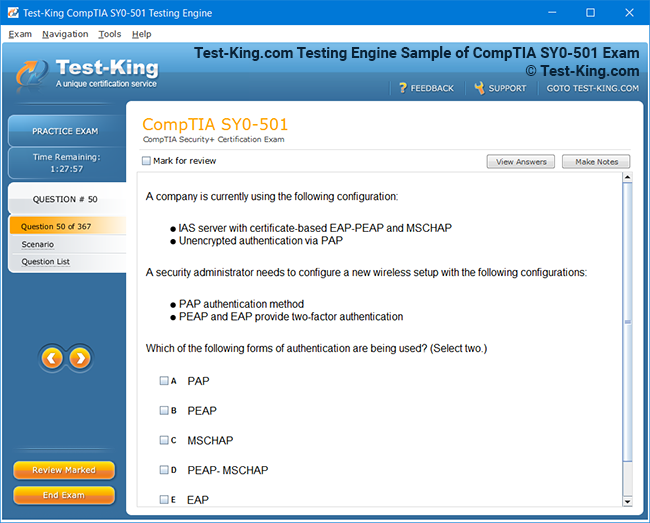
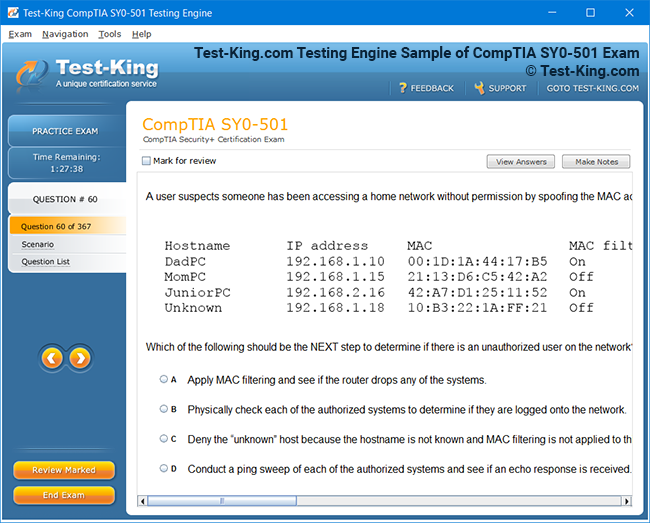
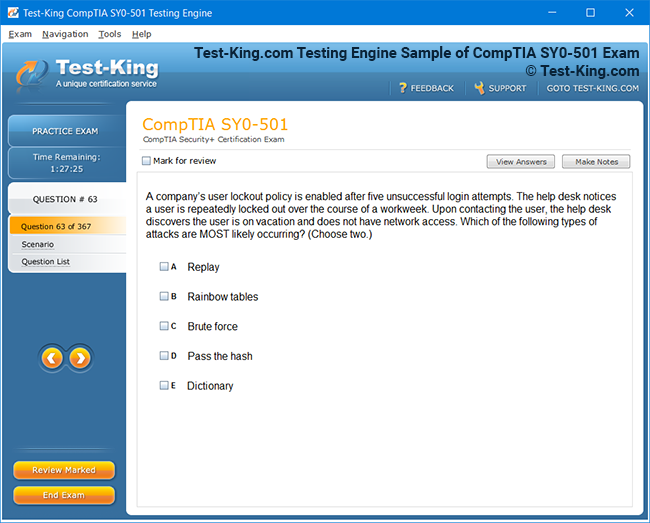
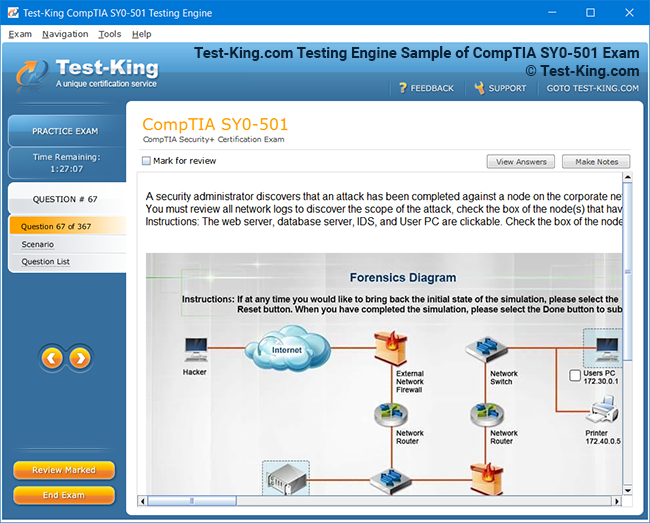
VCS InfoScale Storage Administration Certification Insights and Architectural Foundations
Veritas InfoScale Storage Administration represents a sophisticated realm of storage virtualization designed for UNIX and Linux environments. Candidates aiming to navigate this domain must comprehend the intricate symbiosis between storage hardware and software abstractions that collectively optimize resource utilization, ensure data resiliency, and facilitate seamless scalability. The administration of Veritas InfoScale Storage encompasses several critical areas, each demanding a combination of theoretical knowledge and practical acumen.
Understanding the Core of Veritas InfoScale Storage Administration
The exam for Veritas Certified Specialist in InfoScale Storage seeks to validate an individual's ability to administer, configure, and manage storage solutions while demonstrating proficiency in UNIX/Linux environments. Mastery of these concepts begins with understanding storage virtualization, which allows physical storage resources to be abstracted into logical units. Storage virtualization provides organizations with agility, enabling them to reallocate storage dynamically, consolidate disparate storage systems, and implement robust replication strategies. The benefits of virtualization extend beyond flexibility; they encompass enhanced fault tolerance, simplified management, and optimized performance through intelligent data placement strategies.
Within the realm of Veritas InfoScale Storage, several components coalesce to form a cohesive infrastructure. The foundational element is Storage Foundation, which delivers a comprehensive suite for managing storage volumes, file systems, and clustering environments. Paired with the Cluster File System, Storage Foundation enables concurrent access to shared data, ensuring high availability across nodes. Volume Manager, an integral element, provides advanced volume creation and management capabilities, allowing administrators to design concatenated, striped, mirrored, RAID-5, and layered volumes, each suited to specific performance and redundancy requirements. Understanding these volumes and their interplay with file systems is critical, as it determines how data is organized, accessed, and safeguarded.
Dynamic Multi-Pathing, often abbreviated as DMP, introduces an additional layer of resilience by facilitating multiple pathways between servers and storage devices. This mechanism mitigates the risk of a single path failure and optimizes throughput, particularly in high-demand environments such as VMware infrastructures. Complementing this is the Veritas InfoScale Operations Manager, a graphical interface that simplifies monitoring, reporting, and proactive management of storage landscapes. Through Operations Manager, administrators can gain visibility into performance metrics, detect anomalies, and orchestrate corrective actions without delving into complex command-line operations.
Beyond basic components, advanced storage capabilities further elevate the value of InfoScale Storage. Storage Foundation for databases, Veritas File Replicator, and Veritas Volume Replicator provide mechanisms for data replication and disaster recovery, ensuring continuity even in the face of catastrophic failures. These tools facilitate synchronous and asynchronous replication strategies, enabling administrators to tailor solutions to the organization’s recovery point and recovery time objectives. Flexible Storage Sharing represents another sophisticated feature, allowing multiple systems to access shared storage resources without compromising data integrity or performance. Understanding these architectural concepts is vital, as they underpin the advanced administration tasks that the exam evaluates.
Candidates preparing for this exam must also recognize the distinction between physical and virtual storage objects. Physical objects encompass disks, arrays, and storage devices, while virtual objects include volumes, file systems, and snapshots. The ability to navigate between these layers, understanding their dependencies and operational intricacies, is a hallmark of competent InfoScale Storage administration. Administering these objects involves not only creation and configuration but also ongoing monitoring, optimization, and troubleshooting to ensure uninterrupted service delivery.
Installation, Licensing, and Configuration Essentials
A critical aspect of Veritas InfoScale Storage administration involves the installation and configuration of software components across UNIX and Linux platforms. This process begins with the Common Product Installer, which provides a guided interface for deploying Storage Foundation, Volume Manager, and associated tools. During installation, candidates must be familiar with licensing procedures, ensuring that the software is authorized for the intended environment and that compliance requirements are met. Licensing is not merely a legal obligation but also a prerequisite for enabling full functionality of storage management features.
Once installed, configuration tasks extend to creating local and clustered disk groups. Disk groups represent logical aggregations of physical disks, forming the foundation upon which volumes and file systems are built. In a clustered environment, multiple nodes share these disk groups, providing redundancy and high availability. Administrators must understand the implications of disk group placement, balancing performance requirements with fault tolerance considerations. Configuring concatenated volumes involves combining multiple physical disks into a single logical volume, whereas striped volumes distribute data across disks to enhance performance. Mirrored and RAID-5 volumes introduce redundancy, safeguarding data against disk failures, while layered volumes allow complex configurations that combine different volume types for specialized workloads.
File system management is another critical facet of InfoScale Storage administration. Administrators must be capable of creating and managing both local and clustered file systems. Clustered file systems enable simultaneous access from multiple nodes, a necessity for high-availability applications. Configuring file systems involves specifying parameters such as block size, journaling options, and allocation policies, all of which impact performance, reliability, and storage efficiency. In addition, volume configuration extends to adding mirrors and logs, which serve to enhance fault tolerance and facilitate recovery in case of unexpected failures.
The command-line interface remains a cornerstone of administrative tasks. While graphical tools provide convenience, understanding CLI commands allows administrators to perform intricate operations, automate repetitive tasks, and troubleshoot issues with precision. Veritas InfoScale Operations Manager complements the CLI by offering a centralized console for monitoring and managing storage environments. Through Operations Manager, administrators can visualize disk usage, monitor performance metrics, and configure alerts to proactively address potential issues.
Advanced Storage Architecture and Object Management
An intricate understanding of advanced storage architecture is indispensable for effective administration. Flexible Storage Sharing allows multiple systems to utilize shared storage without risking data corruption, thereby supporting scalable and resilient infrastructures. Replication solutions, including Veritas File Replicator and Volume Replicator, ensure that data remains available even during hardware failures, disasters, or maintenance operations. These replication mechanisms involve complex processes such as data synchronization, conflict resolution, and consistency checks, all of which require careful configuration and ongoing monitoring.
Managing physical and virtual storage objects is an ongoing responsibility. Physical objects, such as disks and storage arrays, must be monitored for health, utilization, and performance. Virtual objects, including volumes, snapshots, and file systems, require configuration, maintenance, and periodic validation to ensure they meet performance expectations and adhere to organizational policies. The interplay between physical and virtual objects defines the storage environment’s efficiency and resilience, making object management a crucial skill for exam candidates.
Snapshots and storage checkpoints serve as essential tools for data protection and operational flexibility. Snapshots provide point-in-time copies of volumes, enabling administrators to restore data quickly in case of corruption or accidental deletion. Checkpoints extend this functionality by capturing the state of file systems and volumes, supporting rapid recovery and testing scenarios. Configuring checkpoint visibility, auto-mounting, and retention policies ensures that these mechanisms integrate seamlessly into operational workflows without consuming unnecessary resources.
Storage tiering and SmartIO represent additional advanced concepts that elevate the performance and efficiency of InfoScale Storage environments. Storage tiering automatically relocates frequently accessed data to high-performance storage while moving less active data to economical, lower-performance tiers. SmartIO optimizes input/output operations, reducing latency and improving throughput, particularly for database workloads and high-demand applications. Understanding these features, their configuration, and their operational benefits is integral for effective administration and exam preparedness.
Dynamic Multi-Pathing and Performance Optimization
Dynamic Multi-Pathing provides redundancy and load balancing for storage connections, ensuring continuous access even in the event of path failures. Configuring DMP involves defining path groups, monitoring path health, and optimizing path selection policies to maximize throughput. Administrators must be adept at identifying potential bottlenecks, analyzing performance metrics, and implementing corrective measures to maintain high availability and optimal performance.
Monitoring tools and reporting mechanisms are critical for maintaining the health of the storage environment. Veritas InfoScale Operations Manager offers comprehensive reporting capabilities, including performance trends, utilization reports, and event logs. By leveraging these insights, administrators can make informed decisions, anticipate potential issues, and implement preventative measures. File system features such as data compression and deduplication further enhance storage efficiency by reducing redundant data and optimizing storage consumption. Recognizing which file systems benefit most from these capabilities allows administrators to maximize storage value while maintaining performance.
Administrative Tasks and Troubleshooting
Effective administration encompasses routine maintenance, troubleshooting, and proactive management. Basic troubleshooting involves identifying the root cause of storage failures, performing recovery procedures, and validating that corrective actions restore full functionality. Administrators must be capable of resolving issues related to disk failures, volume inconsistencies, file system corruption, and connectivity problems. Utilizing both CLI commands and Operations Manager tools, administrators can perform diagnostic tests, analyze logs, and execute corrective actions with precision.
Online administrative tasks, including volume resizing, mirror addition, and log management, enable administrators to make changes without disrupting ongoing operations. Kernel components orchestrate the underlying storage architecture, managing data flow, access permissions, and redundancy mechanisms. A deep understanding of these components ensures that administrators can anticipate system behavior, optimize performance, and maintain stability in complex, multi-node environments.
Site Awareness, a feature designed for geographically dispersed storage clusters, enhances resilience by enabling clusters to operate efficiently across multiple locations. Configuring this feature involves defining site policies, managing replication, and ensuring that failover mechanisms function as intended. Administrators must integrate Site Awareness with other advanced features such as replication, tiering, and SmartIO to maintain continuity and performance across distributed environments.
Administrative Operations and File System Management
Administering a robust storage environment requires more than the mere installation of Veritas InfoScale Storage components. It demands a meticulous understanding of the operational intricacies inherent in UNIX and Linux platforms. File system management serves as the cornerstone of effective administration. Administrators must perform regular operations to create, modify, and maintain file systems, ensuring that data remains accessible, consistent, and resilient. Local file systems allow isolated access within a single node, whereas clustered file systems facilitate simultaneous access across multiple nodes, preserving high availability and preventing data inconsistencies. Creating a file system involves choosing appropriate parameters, such as block size, journaling modes, and allocation strategies, each of which influences performance, reliability, and storage efficiency.
Managing file systems also entails ongoing monitoring and optimization. Administrators must identify potential bottlenecks, analyze I/O patterns, and adjust configurations to enhance throughput and reduce latency. Thin provisioning introduces an additional layer of sophistication, allowing storage administrators to allocate logical volumes that exceed the physical storage capacity. This approach maximizes storage utilization and defers the need for additional hardware procurement. Thin reclamation, the process of reclaiming unused space within thin-provisioned volumes, ensures that storage remains available and efficiently utilized, preventing wastage and improving overall system performance.
Volume management is intrinsically linked to file system administration. Veritas Volume Manager enables the creation of concatenated, striped, mirrored, RAID-5, and layered volumes, each serving distinct use cases. Concatenated volumes combine multiple physical disks into a singular logical volume, emphasizing simplicity and capacity. Striped volumes distribute data across multiple disks, enhancing performance for read and write operations. Mirrored volumes provide redundancy, ensuring that data remains available even if one disk fails. RAID-5 volumes employ parity-based redundancy, balancing fault tolerance with storage efficiency. Layered volumes allow complex configurations, combining different volume types to meet specialized workload requirements. Properly configuring volumes involves adding mirrors, creating logs, and monitoring volume health to prevent data loss and maintain system integrity.
Monitoring Tools and Performance Analysis
Monitoring is an indispensable aspect of storage administration. Veritas InfoScale Operations Manager offers a comprehensive interface for observing the health, utilization, and performance of storage environments. Through this platform, administrators can track disk usage, volume performance, and file system activity, enabling proactive management. Identifying abnormal patterns or potential failures before they escalate ensures that systems remain resilient and performance remains optimal. Operations Manager also provides reporting capabilities, which allow administrators to document performance metrics, analyze trends, and prepare capacity planning strategies.
Performance analysis extends beyond monitoring metrics. Administrators must understand how kernel components interact with storage objects to orchestrate efficient data flow. The kernel manages I/O requests, enforces access controls, and coordinates redundancy mechanisms. Knowledge of these internal operations allows administrators to anticipate system behavior, optimize performance, and troubleshoot issues effectively. Performance tuning may involve adjusting DMP path priorities, optimizing read/write operations, and fine-tuning file system parameters to align with workload characteristics.
Dynamic Multi-Pathing plays a pivotal role in enhancing performance and redundancy. By providing multiple pathways between servers and storage devices, DMP ensures that a failure in one path does not disrupt operations. Administrators configure path groups, monitor path health, and adjust path selection policies to optimize throughput. In virtualized environments, particularly those leveraging VMware, DMP facilitates seamless data access and minimizes latency. Understanding the interplay between DMP, volume configurations, and file systems is essential for maintaining a high-performance, resilient storage infrastructure.
Snapshots and Checkpoints for Data Protection
Snapshots and storage checkpoints are fundamental mechanisms for safeguarding data and ensuring operational flexibility. Snapshots capture a point-in-time image of a volume or file system, enabling administrators to restore data rapidly in case of corruption, accidental deletion, or system failure. These snapshots consume minimal storage resources while providing a reliable recovery mechanism. Administrators must manage snapshot visibility, retention, and auto-mounting policies to ensure that snapshots remain accessible without interfering with normal operations.
Checkpoints extend the functionality of snapshots by preserving the state of file systems and volumes at specific intervals. Checkpoints facilitate rapid recovery, testing, and system validation. Proper management involves configuring automated creation schedules, retention periods, and visibility settings. By leveraging snapshots and checkpoints, administrators can perform maintenance, upgrades, and testing without jeopardizing data integrity. These mechanisms are particularly useful in clustered environments, where multiple nodes access shared storage, and any disruption can impact multiple applications simultaneously.
Replication and Disaster Recovery
Replication mechanisms such as Veritas File Replicator and Veritas Volume Replicator ensure that data remains accessible in the event of hardware failures, disasters, or planned maintenance. File Replicator provides asynchronous and synchronous replication for files, while Volume Replicator extends these capabilities to entire volumes, ensuring consistency and continuity across nodes. Administrators must configure replication policies, monitor replication status, and validate data integrity regularly. Replication also involves managing bandwidth, scheduling replication cycles, and handling conflict resolution to prevent data divergence.
Disaster recovery planning is intimately tied to replication. Administrators must anticipate potential failures, define recovery point objectives, and implement recovery time objectives. By integrating replication, snapshots, and checkpoints, administrators create a robust strategy that minimizes downtime and data loss. Site Awareness enhances these capabilities by allowing geographically dispersed clusters to maintain high availability. Configuring Site Awareness involves defining site policies, managing replication between sites, and ensuring that failover mechanisms operate as intended.
Storage Tiering and SmartIO Optimization
Storage tiering is a sophisticated approach to optimizing resource utilization by dynamically moving data between high-performance and cost-effective storage tiers. Frequently accessed data resides on high-speed devices such as SSDs, while infrequently accessed data is relocated to economical storage media. This automatic reallocation ensures that critical workloads experience minimal latency while reducing overall storage costs. Administrators must configure tiering policies, monitor data movement, and analyze access patterns to maximize the benefits of tiering.
SmartIO enhances performance by optimizing input/output operations across volumes and file systems. This technology analyzes workload characteristics, adjusts caching strategies, and improves throughput, particularly for database and high-demand applications. Configuring SmartIO requires understanding workload patterns, selecting appropriate caching policies, and monitoring the impact on overall performance. By integrating SmartIO with tiering, administrators achieve a balanced environment where performance, resilience, and efficiency coexist harmoniously.
Troubleshooting and Recovery
Effective troubleshooting requires both analytical acumen and practical experience. Administrators must identify the root causes of storage failures, perform corrective actions, and validate system integrity. Common issues include disk failures, volume inconsistencies, file system corruption, and path failures in DMP configurations. Utilizing CLI commands and Operations Manager tools, administrators can execute diagnostic procedures, examine logs, and implement remedial actions systematically.
Recovery procedures often involve restoring from snapshots or checkpoints, repairing corrupted volumes, and re-establishing replication synchronization. Online administrative capabilities allow adjustments to volumes, mirrors, and logs without interrupting ongoing operations. Kernel components orchestrate storage operations in real-time, managing I/O requests, coordinating redundancy, and ensuring consistent performance. A deep understanding of these internal mechanisms enables administrators to predict system behavior, optimize performance, and prevent recurring issues.
Administrators must also be adept at managing storage for high-availability applications. Configuring clustered file systems, coordinating DMP paths, and monitoring replication ensures that mission-critical services remain uninterrupted. Regular performance reviews, health checks, and proactive adjustments contribute to maintaining a stable, resilient, and optimized environment. By combining monitoring, troubleshooting, and advanced configuration, administrators can provide a seamless storage experience, safeguarding data integrity while maximizing system efficiency.
Operational Visibility and Reporting
Maintaining operational visibility is critical for informed decision-making and proactive management. Veritas InfoScale Operations Manager provides a unified interface for monitoring performance, analyzing trends, and generating reports. Administrators can track disk usage, volume health, replication status, and I/O performance, gaining insights into the operational dynamics of the storage environment. Reporting capabilities support capacity planning, trend analysis, and audit compliance, enabling administrators to anticipate future requirements and justify resource allocations.
Understanding the interplay between physical and virtual storage objects enhances operational visibility. Physical objects include disks, arrays, and controllers, while virtual objects encompass volumes, snapshots, and file systems. Administrators must monitor both layers to ensure data integrity, performance optimization, and resilience. By leveraging operational visibility, administrators can implement preventative measures, optimize workloads, and maintain high availability across diverse environments.
Advanced Volume and File System Configuration
Managing complex storage environments necessitates an in-depth understanding of advanced volume and file system configurations. Veritas InfoScale Storage provides administrators with the ability to tailor storage infrastructures according to workload demands and organizational requirements. Creating layered volumes allows for the combination of different volume types to optimize both performance and redundancy. Concatenated volumes are particularly useful for aggregating multiple disks into a singular logical unit, while striped volumes enhance data throughput by distributing data across disks. Mirrored volumes maintain redundancy by replicating data across disks, ensuring availability even in the event of hardware failure. RAID-5 volumes introduce parity-based redundancy, balancing fault tolerance with efficient use of storage space.
In clustered environments, administrators must be adept at managing both local and clustered file systems. Clustered file systems facilitate concurrent access by multiple nodes, enabling high-availability applications to operate seamlessly. Configuring these systems requires attention to parameters such as block size, allocation policies, and journaling techniques, each of which directly affects performance and reliability. Volume configuration extends beyond creation; administrators must also manage mirrors, add logs for recovery, and optimize layouts to reduce latency. This level of control allows organizations to fine-tune storage according to both transactional and analytical workload patterns, ensuring consistent performance across a variety of use cases.
Snapshots and storage checkpoints play an essential role in advanced configuration by providing mechanisms for rapid recovery and operational testing. Snapshots capture point-in-time images of volumes, enabling administrators to restore data quickly if corruption or accidental deletion occurs. Checkpoints preserve the state of file systems and volumes at specific intervals, supporting operational validation, backup testing, and disaster recovery exercises. Administrators must configure checkpoint retention, visibility, and auto-mounting policies to integrate these mechanisms efficiently into day-to-day operations, minimizing resource consumption while maximizing availability.
Security and Access Management
Securing storage environments is a critical responsibility for administrators. Veritas InfoScale Storage provides mechanisms for controlling access to both physical and virtual storage objects. Administrators can assign permissions to individual users or groups, ensuring that only authorized personnel can modify volumes, manage file systems, or configure replication tasks. Maintaining a robust security posture requires understanding how storage components interact with operating system security frameworks, including UNIX and Linux permission models.
Encryption and secure data replication are additional layers of protection. Encrypting volumes ensures that data remains unreadable to unauthorized users, while secure replication protocols safeguard data during transfer between systems or sites. Administrators must balance security with performance, as encryption and replication can introduce latency if not properly configured. Auditing and monitoring access to storage resources further enhances security, allowing administrators to detect anomalies, track usage patterns, and respond proactively to potential threats.
Integrating security with operational workflows involves a careful orchestration of policies, replication schedules, and snapshot management. Site Awareness adds another dimension to security by ensuring that geographically distributed clusters maintain data integrity and continuity. Administrators must configure site-specific policies, replication strategies, and failover mechanisms to prevent data loss and maintain compliance with organizational and regulatory requirements.
Performance Tuning and Optimization
Performance tuning is a continuous responsibility in advanced storage administration. Administrators must analyze I/O patterns, monitor throughput, and optimize the interaction between volumes, file systems, and physical storage devices. Dynamic Multi-Pathing provides redundancy and load balancing, ensuring uninterrupted access and enhanced performance. Configuring DMP involves defining path groups, monitoring path health, and adjusting path selection policies to maximize efficiency. In virtualized environments, DMP contributes to seamless access, reducing latency and improving overall system responsiveness.
Storage tiering further optimizes performance by automatically relocating frequently accessed data to high-speed storage devices while moving less active data to economical tiers. This dynamic allocation ensures that critical workloads experience minimal latency while reducing overall storage costs. SmartIO enhances input/output operations by analyzing workload patterns and adjusting caching strategies accordingly. Administrators configure SmartIO policies to balance performance and resource utilization, particularly for database workloads and high-demand applications.
Advanced monitoring and reporting complement performance tuning by providing administrators with actionable insights. Veritas InfoScale Operations Manager allows observation of trends, detection of anomalies, and measurement of resource utilization. By analyzing these metrics, administrators can identify bottlenecks, anticipate capacity requirements, and implement corrective actions before performance degradation occurs. Fine-tuning involves adjusting file system parameters, volume layouts, DMP policies, and caching mechanisms, all orchestrated to maintain optimal throughput and responsiveness.
Replication Strategies and Disaster Recovery
Replication strategies are central to maintaining continuity and resilience in storage environments. File Replicator and Volume Replicator offer asynchronous and synchronous replication options, allowing administrators to safeguard data across multiple locations. File Replicator handles replication at the file level, while Volume Replicator ensures consistency for entire volumes. Administrators configure replication schedules, monitor synchronization status, and validate data integrity regularly to ensure that replicated copies remain accurate and accessible.
Disaster recovery planning involves integrating replication with snapshots, checkpoints, and Site Awareness. Administrators define recovery point objectives and recovery time objectives, ensuring that data remains available even during hardware failures or catastrophic events. Configuring failover mechanisms, managing replication bandwidth, and resolving conflicts are all part of ensuring that recovery strategies operate as intended. In geographically dispersed clusters, Site Awareness provides additional resilience by enabling automated failover, minimizing downtime, and preserving transactional consistency.
Effective disaster recovery requires administrators to simulate failover scenarios, verify the integrity of replicated data, and test recovery procedures. This proactive approach ensures that both planned maintenance and unexpected disruptions can be managed without compromising data availability or operational continuity. By combining replication, snapshots, tiering, and monitoring, administrators create a storage environment that is resilient, efficient, and highly responsive to changing demands.
Automation and Operational Efficiency
Automation is a key factor in managing complex storage environments. Veritas InfoScale Storage allows administrators to automate routine tasks such as volume creation, snapshot management, replication scheduling, and monitoring. By leveraging scripting capabilities and CLI commands, repetitive operations can be executed consistently and accurately, reducing the risk of human error. Automation also supports proactive maintenance by triggering alerts, initiating corrective actions, and optimizing resource allocation without manual intervention.
Operational efficiency extends to monitoring performance, managing storage utilization, and optimizing throughput. Administrators use reporting tools to track disk usage, analyze I/O patterns, and anticipate capacity needs. Proactive adjustments, such as reallocating resources, tuning file system parameters, and adjusting caching policies, contribute to maintaining performance and reliability. Integrating automation with monitoring and reporting enables administrators to maintain a dynamic, responsive storage infrastructure that adapts to workload fluctuations and organizational requirements.
Managing High Availability and Clustered Environments
High availability is a critical consideration in storage administration. Clustered file systems, DMP, replication, and Site Awareness collectively ensure that storage services remain operational under adverse conditions. Administrators configure clustered environments to enable simultaneous access by multiple nodes while maintaining data integrity. Failover mechanisms, redundancy strategies, and load balancing policies are all integral to sustaining continuous operations.
Monitoring clustered environments involves tracking node health, disk utilization, volume performance, and replication status. Administrators analyze these metrics to detect potential failures, balance workloads, and optimize resource allocation. By understanding how physical and virtual storage objects interact within clustered configurations, administrators can anticipate system behavior, prevent downtime, and maintain consistent service delivery.
Troubleshooting Complex Storage Scenarios
Troubleshooting in advanced environments requires a combination of diagnostic skills, operational knowledge, and analytical reasoning. Administrators encounter a variety of challenges, including disk failures, volume inconsistencies, path disruptions in DMP configurations, and file system corruption. Resolving these issues necessitates a methodical approach, leveraging both CLI commands and monitoring tools to identify root causes and implement corrective actions.
Recovery strategies involve restoring from snapshots or checkpoints, repairing corrupted volumes, reestablishing replication synchronization, and validating system integrity. Online administrative capabilities allow changes to volumes, mirrors, and logs without interrupting ongoing operations. Kernel components orchestrate storage operations, manage I/O requests, coordinate redundancy mechanisms, and maintain performance consistency. A comprehensive understanding of these internal operations enables administrators to predict system behavior, optimize performance, and prevent recurring issues.
Maintaining high availability and resilience also involves proactive measures such as adjusting DMP policies, tuning file system parameters, monitoring replication, and managing storage tiering. Administrators must anticipate potential disruptions, implement preventative measures, and ensure that all storage layers function cohesively. The ability to troubleshoot, optimize, and orchestrate storage operations underpins the skill set required for successful administration and certification in Veritas InfoScale Storage.
Operational Visibility and Strategic Insights
Operational visibility is crucial for informed decision-making and long-term strategic planning. Administrators utilize Veritas InfoScale Operations Manager to monitor trends, detect anomalies, and analyze resource utilization. Reporting capabilities support capacity planning, workload optimization, and audit compliance, providing actionable insights that guide infrastructure management. Understanding the interrelation between physical and virtual storage objects enhances visibility, ensuring that both layers are monitored, analyzed, and optimized effectively.
By integrating advanced configuration, performance tuning, replication, disaster recovery, and automation, administrators cultivate a storage environment that is resilient, efficient, and adaptive. Operational insights guide strategic decisions, enabling organizations to balance performance, cost, and resilience while maintaining high availability and data integrity. Proficiency in these areas is essential for managing complex UNIX and Linux storage environments and achieving excellence in Veritas InfoScale Storage administration.
Real-World Storage Management Scenarios
Veritas InfoScale Storage administration is not limited to theoretical understanding; practical experience and scenario-based knowledge are essential for effective management. Administrators frequently encounter complex operational situations requiring rapid decision-making and strategic foresight. A common scenario involves managing storage growth in dynamic environments where workloads fluctuate unpredictably. Thin provisioning enables administrators to allocate logical storage beyond the physical capacity of available disks, providing flexibility and delaying capital expenditure. However, effective management requires continual monitoring to ensure that physical resources can accommodate actual usage and that thin reclamation is performed to recover unused space, maintaining optimal utilization.
Clustered environments present another practical challenge. Multiple nodes accessing the same disk groups demand careful orchestration to prevent data inconsistencies. Administrators must ensure that clustered file systems are correctly configured to handle concurrent access, balancing performance with reliability. In such environments, Volume Manager plays a pivotal role, facilitating the creation of concatenated, striped, mirrored, and layered volumes that meet the specific requirements of transactional or analytical workloads. Mirrored volumes and RAID-5 configurations provide resilience against hardware failure, while layered volumes enable complex configurations that optimize both performance and redundancy.
Snapshots and checkpoints are indispensable tools for managing live systems without service interruptions. Snapshots create point-in-time images of volumes, allowing administrators to perform maintenance or testing without risking data loss. Checkpoints provide additional granularity, preserving the state of file systems and volumes at scheduled intervals. Configuring retention, visibility, and auto-mounting policies ensures that these mechanisms integrate seamlessly into operational workflows. In production environments, snapshots are often combined with replication strategies to safeguard critical data across nodes or geographic locations, enhancing both availability and disaster preparedness.
Handling Failures and Recovery
Storage failures can occur unexpectedly, necessitating immediate response to prevent downtime or data loss. Administrators must be adept at diagnosing issues such as disk failures, volume corruption, or path disruptions in Dynamic Multi-Pathing configurations. DMP ensures that multiple pathways exist between servers and storage devices, providing redundancy and minimizing the impact of a single path failure. Understanding how to configure path groups, monitor path health, and adjust path selection policies is crucial for maintaining continuous access. In virtualized environments, proper DMP configuration is particularly important to sustain performance and minimize latency.
Recovery operations may involve restoring data from snapshots or checkpoints, reestablishing replication synchronization, or repairing corrupted volumes. Online administrative capabilities allow these actions to be performed without interrupting ongoing operations, a critical requirement in high-availability environments. Kernel components manage the underlying storage architecture, orchestrating data flow, enforcing redundancy, and ensuring that I/O requests are processed efficiently. A comprehensive understanding of these internal mechanisms enables administrators to troubleshoot effectively, anticipate potential issues, and implement long-term solutions.
Replication strategies are also essential for recovery. File Replicator enables asynchronous and synchronous replication at the file level, while Volume Replicator ensures that entire volumes remain consistent across nodes. Administrators configure replication schedules, monitor synchronization, and validate data integrity, ensuring that replicated copies are reliable and accessible. Combining replication with snapshots, checkpoints, and Site Awareness creates a layered approach to disaster recovery, minimizing downtime and preserving transactional consistency even in geographically dispersed clusters.
Performance Monitoring and Optimization
Maintaining optimal performance in complex storage environments requires continuous monitoring and tuning. Veritas InfoScale Operations Manager provides a centralized interface for tracking disk usage, I/O performance, volume health, and file system activity. By analyzing performance metrics, administrators can identify bottlenecks, adjust configurations, and optimize resource allocation. Performance tuning often involves fine-tuning file system parameters, adjusting caching strategies with SmartIO, and reallocating workloads across storage tiers. SmartIO improves input/output efficiency by analyzing workload characteristics and dynamically optimizing caching behavior, particularly for high-demand applications and databases.
Storage tiering further enhances performance and efficiency. Frequently accessed data is relocated to high-speed storage devices, while infrequently used data resides on economical media. This dynamic allocation balances performance with cost-effectiveness, ensuring that critical workloads experience minimal latency without consuming excessive high-performance storage. Administrators must monitor access patterns, adjust tiering policies, and ensure that tiered data remains available and consistent across volumes and file systems. By integrating tiering with replication, snapshots, and SmartIO, storage environments can maintain resilience, performance, and efficiency simultaneously.
Advanced Troubleshooting Techniques
Troubleshooting complex storage scenarios requires analytical acumen and hands-on experience. Administrators frequently face issues such as volume inconsistencies, file system corruption, path failures, and replication conflicts. Diagnosing these problems involves systematic investigation using both CLI commands and Operations Manager tools. Logs, performance metrics, and system alerts provide critical insights into the root cause of failures, enabling administrators to implement corrective measures effectively.
In clustered or multi-node environments, troubleshooting is further complicated by concurrent access to shared storage. Administrators must understand how clustered file systems coordinate data access, detect conflicts, and maintain integrity. Resolving issues in such environments often involves restoring from snapshots or checkpoints, repairing volumes, adjusting DMP configurations, and validating replication synchronization. The ability to perform these actions without disrupting active workloads is essential, as high-availability services cannot tolerate extended downtime.
Proactive troubleshooting is equally important. Administrators analyze trends, monitor disk health, and assess I/O patterns to anticipate potential failures before they impact operations. Regular performance reviews, snapshot validation, and replication monitoring reduce the likelihood of unexpected disruptions. By combining proactive measures with responsive troubleshooting, administrators maintain a resilient and efficient storage environment that supports both business continuity and operational excellence.
Security and Access Control in Operational Environments
In real-world scenarios, securing storage environments is paramount. Administrators control access to physical and virtual objects through permissions and roles, ensuring that only authorized personnel can modify volumes, manage file systems, or configure replication tasks. UNIX and Linux permission models interact with InfoScale Storage security mechanisms, requiring administrators to understand the interplay between operating system-level security and storage-level controls.
Encryption enhances data protection by making volumes unreadable to unauthorized users, while secure replication protocols protect data during transfer between systems or geographic locations. Administrators must carefully balance security and performance, as encryption and replication can introduce additional latency if improperly configured. Monitoring access patterns, auditing changes, and responding to anomalies are critical aspects of maintaining a secure storage environment.
Site Awareness extends security and operational resilience to geographically distributed environments. By defining site-specific policies and failover configurations, administrators ensure that clusters maintain data integrity and continuity even during regional disruptions. Security considerations are integrated with operational workflows, replication strategies, and snapshot management to provide a cohesive approach to protecting critical data.
Practical Tips for High Availability and Scalability
Ensuring high availability requires a multifaceted approach that integrates clustered file systems, replication, Dynamic Multi-Pathing, and Site Awareness. Administrators must configure redundancy, failover mechanisms, and load-balancing policies to minimize downtime and maintain consistent access to critical applications. Monitoring clustered nodes, managing disk groups, and balancing workloads across volumes and file systems contribute to maintaining operational stability.
Scalability is achieved through careful planning of disk groups, volumes, and storage tiers. Administrators anticipate growth in data and workload demands, allocating resources proactively to prevent performance degradation. Thin provisioning, storage tiering, and dynamic volume management enable environments to scale seamlessly while optimizing resource utilization. Integrating automation and monitoring further enhances scalability by allowing routine tasks to be executed consistently and efficiently, reducing the risk of human error while maintaining performance and availability.
Integrating Automation and Operational Efficiency
Automation is a cornerstone of managing complex storage infrastructures. By automating tasks such as volume creation, snapshot management, replication scheduling, and performance monitoring, administrators reduce operational overhead and enhance consistency. Scripting and CLI commands allow repetitive operations to be executed with precision, while Operations Manager provides visual insights into system performance and alerts for proactive maintenance.
Operational efficiency is further improved by analyzing trends and performance data to optimize storage configurations. Adjusting caching policies, tuning file system parameters, reallocating volumes, and managing storage tiers are all part of ensuring that storage environments remain responsive and resilient. By integrating automation with monitoring and reporting, administrators can maintain a dynamic infrastructure that adapts to evolving workloads, minimizes downtime, and maximizes resource utilization.
Dynamic Monitoring and Resource Allocation
Efficient storage administration demands continuous observation of system performance and judicious allocation of resources. Veritas InfoScale Storage equips administrators with tools to monitor disk usage, volume health, I/O throughput, and file system activity. Real-time performance monitoring is essential for maintaining operational equilibrium, as workloads frequently fluctuate due to variable application demands and user activity. Administrators must interpret trends and patterns in usage to anticipate bottlenecks, optimize capacity, and allocate resources dynamically.
In complex UNIX and Linux environments, dynamic allocation of storage resources ensures that critical workloads experience minimal latency while non-critical processes operate on secondary storage tiers. Storage tiering plays a pivotal role in balancing performance with cost-efficiency. Frequently accessed data resides on high-speed storage devices, while less frequently used information is migrated to economical storage tiers. Administrators must configure tiering policies that align with organizational priorities and monitor the movement of data to maintain consistency and responsiveness. SmartIO complements this process by optimizing input/output operations through intelligent caching mechanisms. By analyzing workload characteristics and dynamically adjusting caching strategies, administrators enhance throughput for database operations and high-demand applications, ensuring seamless access to critical data.
Advanced Volume Management and Optimization
Volume management is central to maintaining performance and resilience in InfoScale Storage environments. Administrators create, configure, and optimize concatenated, striped, mirrored, RAID-5, and layered volumes to meet diverse operational requirements. Concatenated volumes combine multiple physical disks into a single logical volume, offering simplicity and expanded capacity. Striped volumes distribute data across multiple disks to enhance read and write performance, which is crucial for high-throughput workloads. Mirrored volumes replicate data across multiple disks to provide redundancy, while RAID-5 configurations introduce parity-based fault tolerance, balancing storage efficiency with data protection. Layered volumes allow administrators to combine different volume types, enabling tailored solutions for specific workload profiles.
Volume optimization is not limited to initial configuration. Administrators must continuously monitor volume health, performance metrics, and usage patterns. Adjustments such as adding mirrors, redistributing data across stripes, or resizing volumes are often required to maintain efficiency and reliability. Advanced scenarios may involve integrating volumes with snapshots, checkpoints, and replication mechanisms to ensure data integrity while supporting real-time operational demands.
Snapshots, Checkpoints, and Replication Integration
Snapshots and checkpoints are indispensable for managing live environments without interrupting service. Snapshots capture point-in-time images of volumes, enabling administrators to perform maintenance, testing, or recovery operations without risking data loss. Checkpoints provide additional granularity, preserving the state of file systems and volumes at specific intervals. Administrators configure retention policies, auto-mounting, and visibility parameters to ensure that snapshots and checkpoints integrate seamlessly with operational workflows, maintaining availability and minimizing resource consumption.
Replication strategies complement these mechanisms by extending data protection across nodes or geographic locations. File Replicator enables asynchronous and synchronous replication at the file level, while Volume Replicator ensures the consistency of entire volumes. Administrators configure replication schedules, monitor synchronization, and validate data integrity, creating a layered approach to disaster recovery. Combining replication with snapshots and checkpoints ensures that organizations can recover rapidly from failures while maintaining operational continuity. Site Awareness adds an additional dimension, allowing geographically dispersed clusters to maintain high availability and preserve data integrity even in the event of regional disruptions.
Real-Time Troubleshooting and Diagnostics
Troubleshooting in real-time environments requires rapid diagnosis and precise corrective action. Administrators encounter issues such as disk failures, volume corruption, file system inconsistencies, and path failures within Dynamic Multi-Pathing configurations. DMP provides multiple paths between servers and storage devices, reducing the impact of individual path failures and enhancing performance. Configuring DMP involves defining path groups, monitoring path health, and adjusting path selection policies to optimize throughput and minimize latency. In virtualized environments, DMP configuration is critical for maintaining seamless access to storage resources, ensuring that applications continue to function without disruption.
Recovery operations are frequently executed without service interruption. Administrators may restore from snapshots or checkpoints, repair corrupted volumes, or reestablish replication synchronization while maintaining active workloads. Kernel components orchestrate storage operations in real-time, managing I/O requests, enforcing redundancy, and ensuring consistent performance across multiple nodes. Understanding the behavior of these kernel components allows administrators to troubleshoot effectively, implement corrective actions, and anticipate potential failures before they escalate.
Proactive troubleshooting strategies involve analyzing historical performance data, monitoring trends, and validating the integrity of snapshots, volumes, and replication processes. By identifying potential bottlenecks and resource contention points, administrators can implement preventative measures to maintain resilience and efficiency. This approach reduces unplanned downtime, minimizes operational risk, and ensures that storage environments remain responsive to fluctuating demands.
Security Considerations During Performance Management
Operational security is an essential aspect of real-time performance tuning. Administrators must ensure that only authorized personnel can access and modify storage objects, volumes, and file systems. Permissions, roles, and access control mechanisms are configured in alignment with UNIX and Linux security models. Secure replication protocols and encryption mechanisms safeguard data during transfer or while at rest, ensuring confidentiality and integrity without compromising performance.
Balancing security and performance is critical, as encryption and replication can introduce latency if not properly optimized. Administrators must monitor resource utilization, adjust replication schedules, and optimize caching strategies to maintain both security and responsiveness. Site Awareness further strengthens operational security by enabling geographically dispersed clusters to maintain continuity and integrity even under adverse conditions. Security policies are integrated with operational workflows, replication schedules, and snapshot management to provide a cohesive approach to safeguarding critical data in real-time environments.
Optimizing Clustered Environments for High Availability
Clustered environments provide resilience and high availability, but they require careful orchestration. Administrators manage disk groups, file systems, volumes, and replication mechanisms across multiple nodes, ensuring that concurrent access does not compromise data integrity. High-availability strategies include configuring failover mechanisms, balancing workloads, and monitoring node health. Dynamic Multi-Pathing contributes to reliability by providing redundant pathways for data access, reducing the risk of downtime due to hardware failures.
Performance tuning in clustered environments involves monitoring I/O patterns, analyzing node utilization, and optimizing the distribution of workloads across storage resources. Administrators adjust volume layouts, configure mirrors, and fine-tune file system parameters to maintain responsiveness while ensuring redundancy. Integration with storage tiering, SmartIO, and replication further enhances performance, providing a seamless experience for end-users and minimizing latency for mission-critical applications.
Automation and Operational Efficiency in Real-Time Scenarios
Automation enhances operational efficiency by enabling administrators to schedule routine tasks, manage replication, and perform maintenance operations without manual intervention. Veritas InfoScale Storage provides scripting capabilities and CLI commands to automate repetitive actions, reducing the potential for human error and ensuring consistency across operations. Routine tasks such as volume creation, snapshot management, and replication synchronization can be executed automatically, allowing administrators to focus on strategic performance optimization.
Operational efficiency is further enhanced by integrating real-time monitoring with automated decision-making. Administrators can leverage alerts, performance metrics, and trend analysis to trigger automated adjustments, such as reallocating volumes, adjusting caching policies, or redistributing workloads across storage tiers. By combining monitoring, automation, and proactive performance tuning, administrators maintain a dynamic, resilient, and high-performing storage infrastructure that adapts to fluctuating workloads.
Disaster Recovery and High-Impact Operational Scenarios
In high-impact operational scenarios, administrators must ensure that storage environments remain resilient and recoverable. Integrating snapshots, checkpoints, replication, and Site Awareness enables organizations to respond swiftly to failures, minimizing downtime and preserving transactional consistency. Administrators plan recovery point objectives and recovery time objectives, configure failover mechanisms, and validate the integrity of replicated data.
Simulating disaster scenarios and performing recovery drills are essential for maintaining readiness. These exercises allow administrators to identify potential weaknesses, refine recovery processes, and validate operational procedures. By combining proactive measures with real-time operational strategies, administrators ensure that storage infrastructures can withstand unexpected failures while maintaining performance, availability, and data integrity.
Strategic Insights for Long-Term Performance
Long-term performance management involves understanding the interaction between physical storage, virtual volumes, file systems, and operational workloads. Administrators analyze historical performance trends, monitor capacity utilization, and optimize resource allocation to support evolving organizational needs. Storage tiering, SmartIO, and replication strategies are continually adjusted to align with business priorities and workload requirements.
Operational insights guide decisions related to scaling storage resources, upgrading hardware, or implementing new technologies. By combining real-time monitoring with historical analysis, administrators anticipate future demands, prevent performance degradation, and maintain a resilient, high-performing storage environment. Integrating automation, proactive monitoring, and strategic performance tuning ensures that InfoScale Storage remains responsive, efficient, and aligned with organizational goals over the long term.
Preparing for Certification with Real-World Scenarios
Successfully navigating the Veritas InfoScale Storage Administration certification requires more than theoretical knowledge; it demands practical experience and a deep understanding of operational nuances. Administrators are often confronted with scenarios that mirror real-world challenges, including fluctuating workloads, dynamic resource allocation, and high-availability requirements. Understanding how to manage storage environments under these conditions is critical for both certification and professional practice. Thin provisioning enables the allocation of logical storage beyond available physical capacity, allowing organizations to maximize efficiency while delaying the acquisition of additional hardware. Administrators must monitor usage patterns continuously and perform thin reclamation to recover unused storage space, ensuring optimal resource utilization.
Clustered environments add complexity to storage administration. Multiple nodes accessing shared storage resources necessitate careful orchestration to avoid data inconsistencies. Administrators must configure clustered file systems, manage disk groups, and maintain redundancy through mirrored or RAID-5 volumes. Volume Manager facilitates the creation and optimization of concatenated, striped, mirrored, and layered volumes, each designed to meet specific workload characteristics. Layered volumes, in particular, allow sophisticated configurations that optimize both performance and resilience, combining different volume types to address varying operational demands.
Snapshots and checkpoints play a vital role in maintaining operational continuity. Snapshots capture point-in-time images of volumes, allowing administrators to perform maintenance, testing, or recovery tasks without risking data loss. Checkpoints preserve the state of file systems and volumes at designated intervals, supporting rapid recovery and operational validation. Configuring retention, visibility, and auto-mounting ensures these tools integrate seamlessly into workflows, providing flexibility while conserving resources. Combining snapshots with replication strategies further enhances data protection and availability across nodes and geographic locations.
Performance Optimization and Advanced Monitoring
Real-time performance monitoring is essential for administrators preparing for certification and managing high-performance storage environments. Veritas InfoScale Operations Manager provides a comprehensive interface for monitoring I/O performance, disk usage, volume health, and file system activity. Administrators interpret trends and metrics to identify bottlenecks, optimize capacity allocation, and maintain responsiveness. Performance tuning often involves adjusting file system parameters, reconfiguring volume layouts, and fine-tuning caching strategies using SmartIO. This technology optimizes input/output operations by analyzing workload characteristics and dynamically adapting caching behavior, particularly for high-demand applications and database workloads.
Storage tiering is a crucial strategy for optimizing performance while balancing cost. Frequently accessed data is relocated to high-speed storage devices, while infrequently used information is migrated to economical tiers. Administrators must configure tiering policies that align with organizational priorities, monitor data movement, and ensure consistency across volumes and file systems. Integrating SmartIO with tiering further enhances efficiency, allowing the storage environment to respond dynamically to changing workloads without sacrificing performance or availability.
Advanced monitoring also supports proactive management. Administrators can leverage alerts, historical trends, and capacity reports to anticipate potential issues before they impact operations. By analyzing I/O patterns, disk utilization, and volume performance, administrators can implement preventive measures such as redistributing workloads, adding mirrors, or adjusting caching policies. Proactive management not only improves system resilience but also develops the analytical acumen necessary for certification success.
Troubleshooting and Recovery Strategies
Effective troubleshooting is a hallmark of proficient storage administration. Administrators encounter challenges such as disk failures, volume corruption, file system inconsistencies, and path disruptions in Dynamic Multi-Pathing configurations. DMP provides multiple pathways between servers and storage devices, ensuring redundancy and minimizing the impact of a single path failure. Configuring path groups, monitoring path health, and adjusting path selection policies are essential for sustaining continuous access and high performance. In virtualized environments, DMP ensures seamless connectivity and reduces latency, critical for mission-critical workloads.
Recovery operations often involve restoring from snapshots or checkpoints, repairing corrupted volumes, or reestablishing replication synchronization. Online administrative capabilities allow these operations to be performed without interrupting active workloads. Understanding kernel-level orchestration of storage operations, I/O management, and redundancy enforcement equips administrators to diagnose and resolve complex issues efficiently. Proactive troubleshooting also involves analyzing trends, validating snapshots and checkpoints, and monitoring replication health, ensuring that potential problems are mitigated before they impact operations.
Replication strategies are central to maintaining resilience and continuity. File Replicator manages replication at the file level, while Volume Replicator ensures consistency across entire volumes. Administrators configure replication schedules, monitor synchronization status, and validate data integrity, creating a robust disaster recovery framework. Site Awareness extends these capabilities to geographically dispersed clusters, enabling automated failover, preserving transactional consistency, and safeguarding data integrity during regional disruptions.
Security and Operational Resilience
Operational security is intertwined with performance and availability. Administrators control access to storage objects, volumes, and file systems through UNIX and Linux permission models, assigning roles and privileges to ensure that only authorized personnel can perform modifications. Encryption provides protection for data at rest, while secure replication protocols safeguard data in transit. Balancing security measures with performance considerations is essential, as encryption and replication can introduce latency if not optimized.
Administrators integrate security protocols with operational workflows, including replication, snapshots, and automated maintenance tasks. This cohesive approach ensures that critical data remains protected without compromising responsiveness. Site Awareness further enhances resilience by ensuring that geographically distributed clusters maintain integrity and continuity even in the event of infrastructure failures. Maintaining security, performance, and availability simultaneously develops the operational expertise required for certification and real-world administration.
Automation and High-Impact Operational Scenarios
Automation is a cornerstone of efficient storage management. Repetitive tasks such as volume creation, snapshot scheduling, replication synchronization, and monitoring alerts can be automated using scripting and CLI commands. This reduces operational overhead, minimizes human error, and ensures consistent execution of critical tasks. Integrating automation with real-time monitoring allows administrators to respond proactively to changes in workloads, redistribute resources dynamically, and maintain optimal performance across the storage environment.
High-impact operational scenarios, such as sudden workload spikes or hardware failures, demand swift and precise responses. Administrators rely on a combination of snapshots, checkpoints, replication, and DMP to ensure continuity. Proactive monitoring and automation enable rapid mitigation of issues, minimizing downtime and preserving data integrity. Practicing these scenarios not only reinforces operational skills but also prepares administrators for complex problem-solving questions encountered during certification.
Exam-Oriented Strategies and Best Practices
Success in Veritas InfoScale Storage Administration certification requires strategic preparation. Candidates should combine theoretical study with practical, hands-on experience. Understanding the interdependencies between volumes, file systems, replication, tiering, and SmartIO is crucial for answering scenario-based questions. Administrators should practice performing volume configuration, creating snapshots, implementing replication, and tuning performance in lab environments to simulate real-world conditions.
Analyzing sample questions and practice exams helps familiarize candidates with the exam format, question types, and complexity levels. Administrators should approach each question with methodical reasoning, applying their operational knowledge to determine the most effective solution. Reviewing operational workflows, disaster recovery strategies, and performance optimization techniques enhances both exam readiness and practical competence.
Time management during the exam is equally important. Candidates should prioritize questions based on familiarity and complexity, ensuring that high-confidence questions are answered first while reserving time for complex scenario-based problems. Maintaining a balance between speed and accuracy ensures optimal performance under timed conditions. Developing a structured study plan that incorporates hands-on practice, theory review, and practice exams maximizes the likelihood of achieving certification success.
Strategic Insights for Long-Term Administration
Long-term administration of InfoScale Storage requires continuous assessment and adaptation. Administrators must monitor evolving workloads, analyze historical performance data, and optimize storage resources to meet changing organizational demands. Storage tiering, SmartIO optimization, replication strategies, and automated workflows should be continuously reviewed and adjusted to maintain performance, efficiency, and resilience.
Administrators must also anticipate future capacity requirements, plan hardware upgrades, and integrate emerging technologies to ensure that storage environments remain responsive and cost-effective. Strategic insights derived from operational metrics guide decisions regarding scaling, performance tuning, and security enhancements. By fostering a proactive and analytical approach, administrators maintain high availability, operational efficiency, and resilience over time.
Conclusion
Mastering Veritas InfoScale Storage Administration involves a delicate balance of theoretical understanding, practical experience, and strategic foresight. Administrators must excel in configuring volumes, managing file systems, optimizing performance, implementing replication, and securing storage environments. Proficiency in snapshots, checkpoints, Dynamic Multi-Pathing, SmartIO, and storage tiering is essential for maintaining high availability and operational resilience.
Certification preparation benefits from a combination of hands-on practice, scenario-based learning, and examination strategies, reinforcing operational acumen and problem-solving skills. By integrating real-world experience with exam-oriented insights, administrators cultivate the expertise required to manage complex UNIX and Linux storage infrastructures effectively. The culmination of knowledge, practical skills, and strategic planning ensures that both certification objectives and professional operational goals are achieved, enabling administrators to deliver resilient, efficient, and high-performing storage solutions in demanding enterprise environments.
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Veritas Certifications
- VCP Storage Management and High Availability for UNIX - Veritas Certified Professional Storage Management and High Availability for UNIX
- VCS - Veritas Certified Specialist
- VCS Backup Exec - Veritas Certified Specialist Backup Exec
- VCS Enterprise Vault - Veritas Certified Specialist Enterprise Vault
- VCS InfoScale - Veritas Certified Specialist InfoScale
- VCS NetBackup - Veritas Certified Specialist NetBackup
- VCS Storage Foundation - Veritas Certified Specialist Storage Foundation
