
Certification: VCP Storage Management and High Availability for UNIX
Certification Full Name: Veritas Certified Professional Storage Management and High Availability for UNIX
Certification Provider: Veritas
Exam Code: VCS-261
Exam Name: Administration of Veritas InfoScale Storage 7.3 for UNIX/Linux
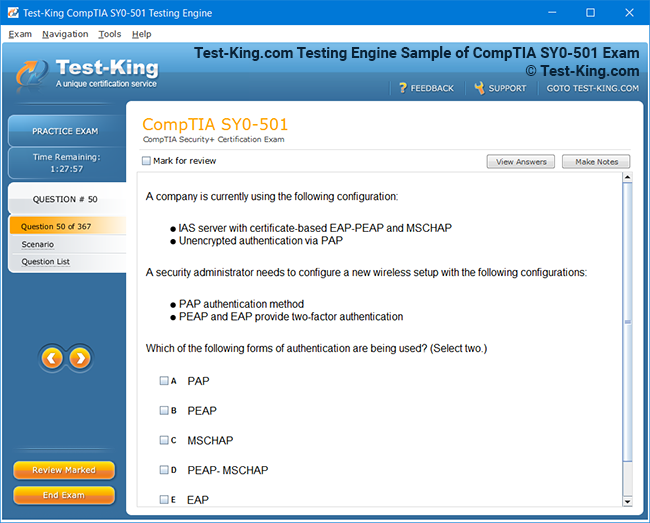
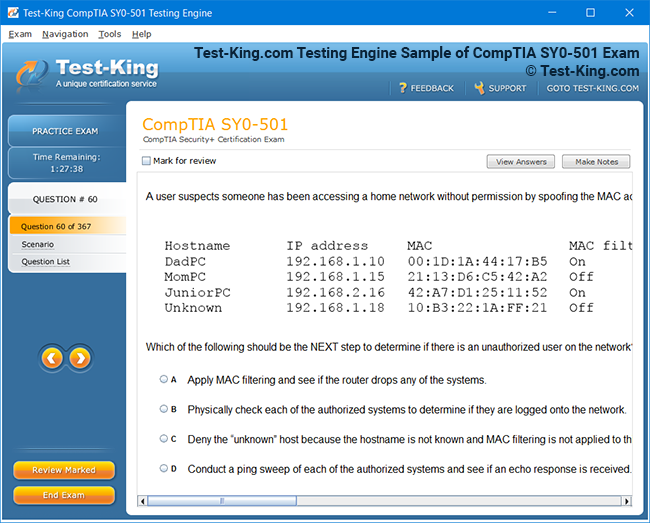
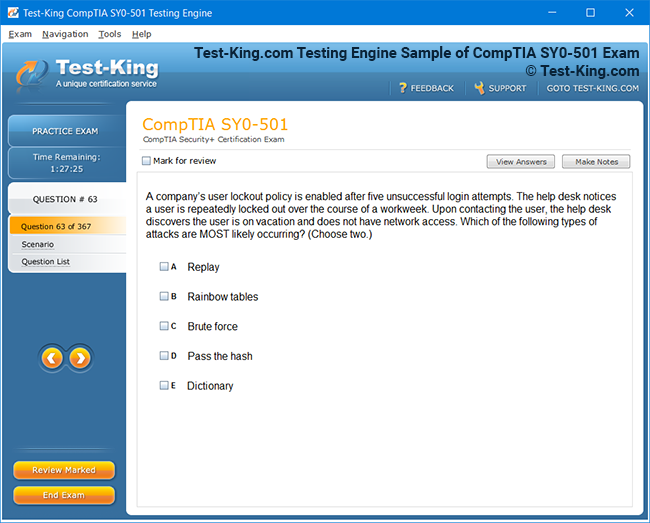
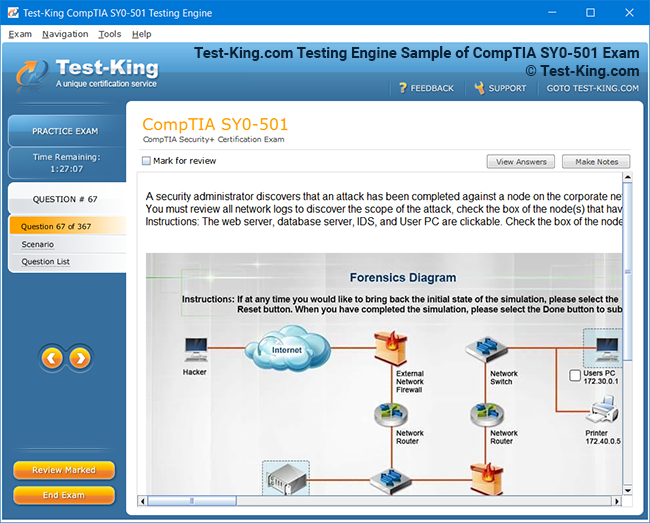
Product Screenshots
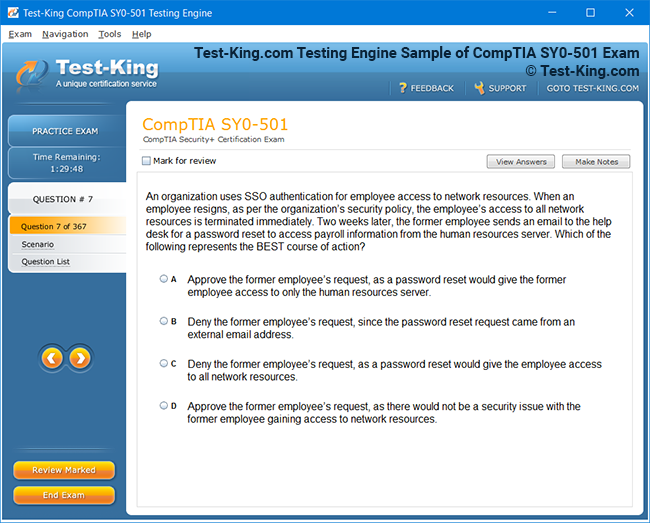
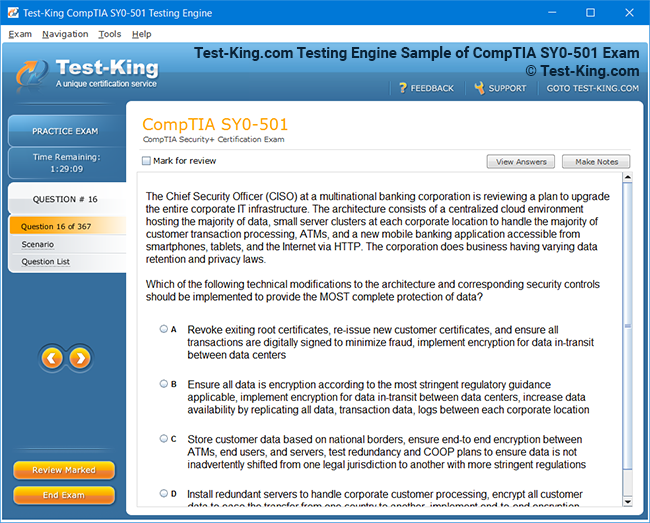
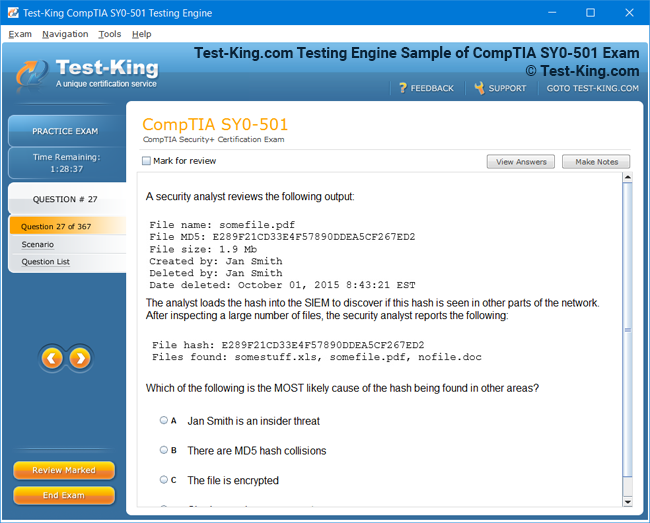
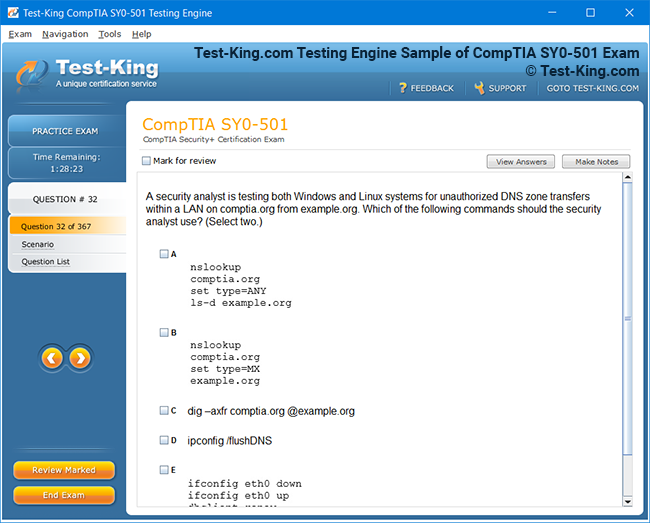
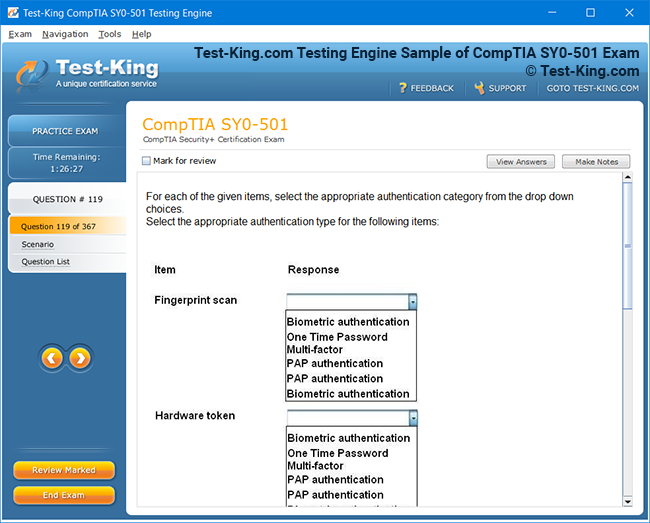
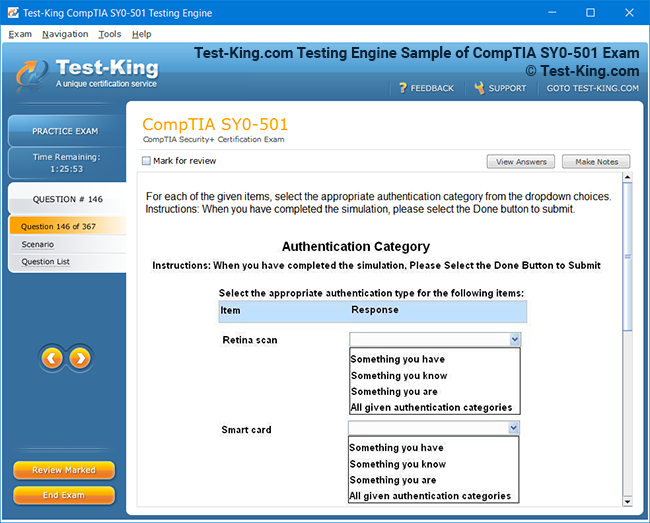
Mastering Veritas VCP: A Complete Guide to Storage Management and High Availability for UNIX
The Veritas Certified Professional credential for storage management and high availability in UNIX environments represents a pivotal milestone for IT professionals seeking to validate their expertise in robust system administration and resilient infrastructure design. This certification is recognized globally as an emblem of proficiency, demonstrating a deep understanding of complex storage architectures, volume management, fault-tolerant systems, and high-availability frameworks that underpin mission-critical UNIX environments. Professionals who pursue this designation are equipped with the ability to architect scalable storage solutions, optimize performance across heterogeneous systems, and ensure business continuity through meticulous planning and proactive maintenance.
Introduction to Veritas VCP and UNIX Storage Management
Storage management in UNIX systems is an intricate tapestry woven from multiple layers of abstraction, ranging from physical disks and hardware controllers to logical volumes, file systems, and clustered architectures. Understanding the interplay between these layers is essential for administrators who aspire to maintain seamless data availability while optimizing resource utilization. The Veritas VCP certification emphasizes not only technical know-how but also a strategic mindset that anticipates system bottlenecks, mitigates risks, and implements resilient configurations capable of withstanding both hardware and software anomalies.
UNIX storage systems are often characterized by their modularity and flexibility, allowing for sophisticated allocation schemes that balance performance, redundancy, and scalability. Physical storage, typically composed of hard disk drives, solid-state drives, or hybrid arrays, provides the foundational blocks upon which logical constructs are created. Logical volumes, managed through tools such as Veritas Volume Manager, offer administrators the ability to abstract storage devices into flexible units, facilitating resizing, migration, and replication without disrupting active workloads. High availability, in turn, ensures that these volumes remain accessible even when individual components fail, leveraging redundancy and failover mechanisms to prevent data loss and service interruptions.
The architecture of UNIX storage is underpinned by concepts such as file system hierarchies, allocation units, and data mirroring. Administrators must navigate the nuances of various file systems, each offering distinctive capabilities regarding journaling, caching, and access controls. Advanced techniques, including dynamic multipathing and striping, further augment performance by distributing workloads across multiple storage devices while maintaining fault tolerance. Veritas tools provide a rich suite of utilities that integrate these strategies seamlessly, enabling proactive monitoring, automated recovery, and meticulous management of storage resources.
A comprehensive understanding of high availability necessitates familiarity with clustering technologies and redundant configurations. Clusters connect multiple servers or nodes in a manner that allows workloads to continue running despite the failure of one or more components. This capability is critical in enterprise environments where downtime translates directly into financial loss and reputational damage. High availability also extends to data replication strategies, where synchronous and asynchronous mirroring ensures that multiple copies of critical data exist across geographically dispersed locations, providing resilience against localized failures or disasters.
Beyond the technical intricacies, pursuing the Veritas VCP credential fosters a mindset that blends analytical reasoning with operational foresight. Administrators learn to evaluate storage performance metrics, identify potential points of contention, and deploy preemptive solutions that maintain system stability. Tools for monitoring disk usage, latency, throughput, and error rates become indispensable allies in maintaining continuous operations. By integrating these practices into routine administration, professionals can preclude service degradation, optimize resource allocation, and extend the operational lifespan of UNIX storage infrastructures.
Career-wise, the Veritas VCP certification unlocks opportunities in roles that demand advanced storage and high-availability expertise, such as system architect, storage engineer, and enterprise infrastructure consultant. Employers value individuals who can design resilient architectures, perform seamless upgrades, and troubleshoot complex storage ecosystems with precision and efficiency. The certification also provides a competitive advantage in organizations that prioritize stringent uptime requirements, data integrity, and regulatory compliance.
Key concepts emphasized in the certification include fault tolerance, which ensures that systems continue to operate despite component failures; disaster recovery planning, which prepares environments for catastrophic events; and performance tuning, which maximizes throughput and minimizes latency. UNIX administrators gain proficiency in logical volume management, storage virtualization, snapshot creation, and replication techniques that collectively underpin high availability. Mastering these competencies equips professionals to anticipate challenges, deploy effective solutions, and maintain seamless operational continuity.
Another integral aspect of UNIX storage management lies in understanding the underlying hardware characteristics and their impact on performance and reliability. Disk types, controller interfaces, and storage networking protocols all influence throughput, latency, and scalability. Veritas training emphasizes the alignment of hardware capabilities with logical volume configurations, ensuring that system resources are leveraged optimally. Moreover, administrators learn to implement tiered storage strategies, allocating high-performance storage to critical workloads while relegating less sensitive data to more economical media.
The interrelationship between storage management and high availability cannot be overstated. Logical volumes, file systems, and data replication strategies must be orchestrated cohesively to prevent service disruptions. In practice, this requires meticulous planning of disk layouts, mirroring schemes, and failover sequences. Administrators must anticipate the failure modes of individual components and devise mechanisms for rapid recovery, balancing performance, redundancy, and cost considerations. Tools provided by Veritas, including volume management utilities and monitoring frameworks, facilitate this orchestration, providing real-time insights and automated recovery capabilities that are essential in complex UNIX environments.
In addition to technical mastery, the certification encourages a culture of vigilance and continuous improvement. Monitoring system health, analyzing performance trends, and performing regular maintenance are indispensable for sustaining high availability. Administrators must cultivate a habit of proactive intervention, identifying potential issues before they escalate into operational disruptions. Knowledge of historical failure patterns, coupled with experience in mitigation strategies, equips professionals to make informed decisions and implement best practices that safeguard data integrity and operational continuity.
UNIX environments present unique challenges and opportunities in storage management. The interplay of multiple operating systems, heterogeneous hardware, and networked storage necessitates a holistic understanding of infrastructure dynamics. The Veritas VCP certification provides structured guidance in navigating this complexity, offering insights into designing scalable architectures, implementing fault-tolerant solutions, and optimizing resource allocation. By mastering these principles, administrators can achieve operational excellence, ensuring that enterprise data remains secure, accessible, and performant under all conditions.
An essential component of high availability involves the orchestration of failover mechanisms. When a node or storage device becomes unavailable, workloads must transition seamlessly to alternate resources, maintaining service continuity without user-perceived downtime. Configurations such as mirrored volumes, redundant paths, and clustered servers facilitate this seamless transition. Veritas tools simplify the management of these configurations, offering automated failover, alerting mechanisms, and diagnostic utilities that empower administrators to respond quickly and effectively to unexpected events.
Training for the certification also emphasizes the development of analytical acumen. Administrators are encouraged to interpret storage performance metrics, correlate system events with potential issues, and devise remediation plans that balance immediate needs with long-term stability. This analytical approach complements the hands-on skills acquired through Veritas utilities, creating a comprehensive proficiency that spans both operational execution and strategic foresight.
Ultimately, mastering storage management and high availability in UNIX is not merely a technical pursuit; it is a commitment to operational excellence, resilience, and meticulous attention to detail. The Veritas VCP certification provides a structured pathway to achieving this mastery, equipping professionals with the knowledge, skills, and confidence required to maintain complex infrastructures, mitigate risks, and ensure uninterrupted access to critical data resources. Those who achieve this credential join an elite cohort of administrators capable of navigating the challenges of modern enterprise environments, delivering performance, reliability, and resilience that organizations depend upon.
Storage Management Fundamentals in UNIX Systems
Understanding storage management in UNIX environments requires an appreciation of the delicate balance between performance, reliability, and scalability. UNIX systems have evolved to accommodate increasingly complex workloads, making efficient allocation and management of storage resources a critical competency for administrators. The Veritas VCP credential emphasizes mastery over these dynamics, equipping professionals with the knowledge and tools necessary to construct resilient storage architectures that seamlessly integrate with high-availability frameworks. Storage management in UNIX is not merely a technical task but a strategic exercise in optimizing resources while safeguarding data integrity and accessibility.
At the foundation of UNIX storage lies the distinction between physical and logical components. Physical storage encompasses tangible media such as hard disk drives, solid-state drives, and hybrid arrays. These devices offer varying degrees of performance, endurance, and capacity, requiring administrators to select appropriate configurations based on workload requirements and organizational priorities. Logical storage, in contrast, abstracts these physical devices into manageable units, enabling administrators to manipulate storage volumes, file systems, and partitions without direct interference with the underlying hardware. Tools like Veritas Volume Manager provide an elegant interface to perform these abstractions, allowing dynamic resizing, migration, and replication of storage volumes in response to operational demands.
Disk allocation strategies in UNIX environments demand careful planning to optimize both performance and fault tolerance. RAID configurations, for instance, are commonly deployed to balance redundancy and speed. Levels such as RAID 0, RAID 1, RAID 5, and RAID 6 offer distinct trade-offs between data protection and throughput, with each configuration serving specific use cases. RAID 0 enhances performance through striping but provides no redundancy, whereas RAID 1 mirrors data to ensure availability in case of hardware failure. RAID 5 and RAID 6 combine striping and parity to protect data while maintaining efficient use of storage capacity. Administrators must possess not only a conceptual understanding of these configurations but also practical skills to implement them in complex UNIX infrastructures, ensuring continuous operation even under adverse conditions.
Beyond RAID, volume management techniques allow for more sophisticated control over storage resources. Logical volumes abstract physical disks into flexible units that can be resized, mirrored, or migrated without disrupting system availability. This abstraction is crucial in environments where workloads fluctuate or storage requirements change dynamically. By leveraging volume management tools, administrators can allocate storage more efficiently, create snapshots for data protection, and implement redundancy schemes that support high availability. The ability to orchestrate these volumes with precision distinguishes proficient UNIX administrators from their peers, reflecting the strategic mindset emphasized by the Veritas VCP credential.
File systems represent another critical dimension of storage management. UNIX supports multiple file systems, each optimized for particular operational characteristics such as performance, journaling, or scalability. Administrators must evaluate these options carefully, considering factors like access patterns, data integrity requirements, and long-term maintenance implications. Properly configured file systems facilitate efficient data retrieval, minimize latency, and contribute to overall system stability. The interaction between logical volumes and file systems is complex, requiring administrators to synchronize allocation strategies, caching mechanisms, and metadata management to achieve optimal performance and reliability.
Advanced UNIX storage management also incorporates techniques for monitoring and tuning system performance. Disk I/O, latency, and throughput are fundamental metrics that reflect the health and efficiency of storage subsystems. Administrators must analyze these metrics to identify bottlenecks, balance workloads, and implement optimization strategies that enhance responsiveness. Tools provided by Veritas enable detailed inspection of storage activity, offering insights into potential performance anomalies and enabling preemptive interventions. Proactive monitoring ensures that storage infrastructures operate smoothly under varying workloads, reducing the likelihood of unexpected downtime and enhancing overall service reliability.
Storage virtualization has emerged as a powerful mechanism for abstracting and consolidating physical resources. By creating virtual storage pools that span multiple devices, administrators can allocate capacity dynamically, optimize utilization, and simplify management. This approach not only enhances flexibility but also supports high availability by enabling seamless migration of data between physical devices without impacting active workloads. Veritas technologies facilitate virtualization by providing a cohesive interface to manage logical volumes, monitor performance, and implement redundancy schemes, allowing administrators to orchestrate complex storage environments with minimal disruption.
Data replication is integral to modern UNIX storage strategies, ensuring that multiple copies of critical data exist across diverse locations. Synchronous replication maintains real-time copies, providing immediate failover capabilities in the event of a primary system failure. Asynchronous replication, while introducing slight latency, enables cost-effective distribution of data across geographically distant sites. Both techniques are vital for maintaining high availability, disaster recovery readiness, and compliance with regulatory mandates. Veritas tools provide administrators with the capability to configure, monitor, and manage replication processes, ensuring that data remains consistent, accessible, and protected against various failure scenarios.
The orchestration of high availability and storage management relies heavily on clustering technologies. Clusters link multiple UNIX servers to operate as a cohesive system, providing failover capabilities that maintain service continuity even when individual nodes experience disruption. Storage volumes, logical partitions, and file systems are integrated into these clusters to ensure that workloads transition seamlessly in case of hardware or software failures. Administrators must understand not only the mechanics of clustering but also the intricate dependencies between storage components, application requirements, and network connectivity to implement robust high-availability solutions.
Disaster recovery planning complements high-availability strategies by preparing systems to withstand catastrophic events. A well-structured disaster recovery plan encompasses data backups, replication policies, and failover procedures that can be executed swiftly to restore operations. UNIX administrators must consider various failure scenarios, including hardware malfunction, software corruption, and environmental disasters, and design storage solutions that minimize downtime and data loss. Training for the Veritas VCP credential emphasizes the integration of disaster recovery into routine management, ensuring that administrators can respond effectively to unexpected events while maintaining business continuity.
Security considerations are also intertwined with storage management. Access control, encryption, and auditing mechanisms safeguard sensitive data against unauthorized access, tampering, and corruption. UNIX administrators must implement security policies at both the storage and file system levels, ensuring compliance with organizational standards and regulatory frameworks. Veritas solutions offer tools for monitoring access, encrypting volumes, and auditing changes, enabling administrators to maintain data integrity and confidentiality while simultaneously supporting high-performance operations.
Performance optimization is a recurring theme in UNIX storage management. Administrators must balance the competing demands of throughput, latency, and redundancy to ensure that systems perform efficiently under diverse workloads. Techniques such as disk striping, tiered storage allocation, and caching mechanisms contribute to achieving these objectives. Veritas utilities provide detailed insights into storage performance, enabling administrators to fine-tune configurations, predict bottlenecks, and implement proactive interventions that sustain optimal system operation. By mastering these techniques, professionals demonstrate the analytical acumen and practical skills valued by enterprise environments.
Storage maintenance and lifecycle management further enhance the reliability of UNIX systems. Regular monitoring, firmware updates, and disk health assessments prevent potential failures and extend the lifespan of storage devices. Administrators must anticipate obsolescence, plan for capacity expansion, and implement strategies for graceful replacement of aging components. The integration of maintenance routines with high-availability frameworks ensures that operational continuity is maintained even during upgrades or replacements, reflecting the meticulous planning emphasized in Veritas training.
Capacity planning is an essential aspect of storage management that influences both performance and cost-efficiency. Administrators must forecast storage consumption, assess workload trends, and allocate resources to meet evolving organizational demands. Techniques such as predictive analytics, trend monitoring, and utilization forecasting enable informed decision-making, ensuring that storage infrastructures remain scalable and responsive. Veritas solutions assist administrators in analyzing capacity trends, automating volume adjustments, and maintaining a balance between resource availability and operational requirements.
UNIX environments often involve heterogeneous storage architectures that integrate multiple device types, networked storage, and virtualization layers. Administrators must navigate these complexities to ensure cohesive operation and maintain high availability. Understanding the interplay between SANs, NAS devices, and local storage is critical for designing resilient storage topologies. Veritas training emphasizes strategies for unifying diverse storage elements, orchestrating data replication, and managing logical volumes in a manner that maximizes both performance and reliability.
The interplay between storage management and high availability necessitates a holistic perspective. Administrators must design systems that not only meet immediate performance needs but also anticipate failures, mitigate risks, and maintain service continuity. Redundant storage paths, mirrored volumes, and clustered configurations contribute to resilience, while performance monitoring and capacity planning support sustained efficiency. Veritas VCP training equips professionals with both the conceptual understanding and hands-on expertise to implement these strategies effectively, ensuring that UNIX infrastructures remain robust, scalable, and highly available.
High Availability Concepts and Implementation in UNIX Environments
High availability in UNIX environments constitutes a fundamental pillar of enterprise infrastructure, ensuring that mission-critical applications and data remain accessible even in the presence of hardware or software failures. Achieving this resilience requires a deep understanding of clustering, failover mechanisms, redundancy, and storage replication strategies, all of which are emphasized within the Veritas Certified Professional credential. High availability is not merely about preventing downtime; it is about orchestrating an intricate symphony of components and processes that maintain operational continuity under diverse and unpredictable conditions. Professionals trained in these concepts are capable of constructing systems that balance performance, reliability, and cost-effectiveness while mitigating the impact of failures on end users and business operations.
Clustering forms the backbone of high-availability architectures, connecting multiple UNIX servers into a cohesive unit capable of sustaining workloads even when individual nodes fail. These clusters operate through coordinated communication and shared resource management, ensuring that data and applications remain accessible despite disruptions. Administrators must understand the principles of quorum, node membership, and failover sequencing to configure clusters that are both resilient and efficient. The Veritas VCP certification emphasizes practical knowledge of clustering tools, enabling professionals to implement clusters that automatically detect failures, reassign resources, and maintain service continuity without requiring manual intervention.
Redundancy is another essential element of high availability, encompassing both hardware and software layers. Hardware redundancy involves duplicating critical components such as storage controllers, power supplies, network interfaces, and disks, ensuring that a single point of failure does not compromise system availability. Software redundancy includes mirrored volumes, replicated databases, and fault-tolerant applications that can continue operating in the event of a software anomaly. Effective implementation of redundancy requires careful planning to balance cost, complexity, and risk, ensuring that the system can recover gracefully from failures while maintaining optimal performance.
Failover mechanisms are integral to the operation of high-availability systems, allowing workloads to transition seamlessly from a failed component to a standby resource. Failover can be automated or manual, with automated failover providing immediate response to component failures and minimizing downtime. Administrators must configure failover policies to determine the priority of resources, detect failure conditions accurately, and execute transitions without introducing additional instability. Veritas tools facilitate the design and management of failover processes, offering monitoring, alerting, and recovery capabilities that enhance operational resilience.
Storage replication is central to high availability, ensuring that multiple copies of data exist across distinct devices or sites. Synchronous replication maintains real-time copies of data, guaranteeing that changes on the primary system are instantly reflected on the secondary system. This approach provides immediate failover capabilities and prevents data loss in the event of a primary system failure. Asynchronous replication, while introducing slight latency, allows for geographically dispersed copies that protect against regional disasters. Implementing these replication strategies requires administrators to evaluate network bandwidth, latency, and consistency models to maintain both performance and reliability across the infrastructure.
High availability also encompasses the design of disaster recovery strategies that complement failover and replication mechanisms. Disaster recovery planning involves defining recovery point objectives, recovery time objectives, and prioritization of critical services. Administrators must develop procedures to restore operations quickly following catastrophic events such as natural disasters, cyberattacks, or large-scale hardware failures. Veritas training emphasizes the integration of disaster recovery into the overall high-availability strategy, ensuring that administrators can respond effectively to severe disruptions while maintaining business continuity and data integrity.
Monitoring and proactive management are vital components of high-availability implementations. Administrators must continuously assess system health, performance metrics, and error logs to detect anomalies before they escalate into failures. Tools provided by Veritas allow for detailed inspection of storage activity, node performance, and network connectivity, enabling rapid identification and resolution of potential issues. Proactive monitoring not only prevents downtime but also provides insights that inform capacity planning, resource allocation, and optimization of high-availability configurations.
In UNIX environments, high availability often extends to networked storage systems, including SANs and NAS devices. Administrators must ensure that data paths are redundant, that multipathing is configured correctly, and that storage devices can tolerate component failures without interrupting service. Logical volume management, combined with clustered file systems, enhances resilience by enabling transparent failover of volumes and file systems across nodes. Veritas solutions offer comprehensive management of these configurations, allowing administrators to orchestrate complex storage topologies that meet stringent uptime requirements.
Load balancing is frequently integrated into high-availability designs to distribute workloads evenly across nodes or storage devices, preventing bottlenecks and maximizing resource utilization. By dynamically reallocating workloads in response to changing conditions, administrators can maintain optimal performance while minimizing the risk of overloading individual components. Load balancing strategies require careful monitoring, performance analysis, and coordination with failover mechanisms to ensure that redistribution occurs seamlessly and does not introduce additional instability into the system.
High availability in UNIX also involves managing dependencies between applications, services, and storage. Certain applications require access to specific storage volumes or network resources, and administrators must ensure that these dependencies are respected during failover events. Orchestrating the sequence of resource transitions, maintaining consistency between replicas, and preserving application state are critical tasks for professionals seeking to deliver uninterrupted service. Veritas tools provide the capabilities necessary to manage these dependencies effectively, offering automation, monitoring, and reporting features that simplify administration.
Administrators must also consider maintenance and upgrades within high-availability architectures. Performing software updates, hardware replacements, or configuration changes without impacting service requires meticulous planning, redundant resources, and failover orchestration. Techniques such as rolling upgrades, where components are updated sequentially while others remain operational, allow administrators to enhance system capabilities without introducing downtime. Veritas guidance emphasizes strategies for maintaining availability during maintenance activities, ensuring that infrastructure improvements do not compromise operational continuity.
Security is intertwined with high availability, as unauthorized access or tampering can compromise both data integrity and system uptime. Administrators must implement access controls, authentication mechanisms, and encryption policies to protect critical resources while supporting uninterrupted service. High-availability strategies must account for potential security incidents, incorporating failover and replication plans that mitigate the impact of breaches. Veritas solutions integrate monitoring, auditing, and access management, enabling administrators to maintain a secure and resilient environment.
Capacity planning and scalability are crucial considerations for high availability. As workloads grow and storage demands increase, administrators must ensure that infrastructure can expand without sacrificing performance or redundancy. Scalable designs incorporate modular storage arrays, additional cluster nodes, and dynamic volume allocation, allowing systems to accommodate evolving organizational requirements. Veritas training emphasizes the foresight and analytical skills needed to anticipate growth, evaluate performance trends, and implement scalable high-availability solutions that remain robust over time.
The orchestration of high availability requires a blend of technical expertise, strategic foresight, and operational discipline. Administrators must synthesize knowledge of storage management, clustering, failover, replication, and disaster recovery to construct resilient UNIX infrastructures capable of withstanding failures of varying magnitude. The Veritas VCP credential provides structured guidance in developing this expertise, combining hands-on experience with conceptual understanding to equip professionals with the skills needed to implement, manage, and optimize high-availability systems.
Performance optimization remains a continuous concern within high-availability frameworks. Monitoring throughput, latency, disk I/O, and network performance allows administrators to identify potential constraints and implement mitigations before they impact service. Techniques such as tiered storage allocation, caching, and load balancing contribute to maintaining responsiveness and reliability. Veritas solutions provide tools for detailed performance analysis, enabling proactive management and fine-tuning of high-availability configurations to meet stringent operational requirements.
Understanding failure modes and conducting root-cause analysis are critical to refining high-availability strategies. Administrators must examine past incidents, identify systemic vulnerabilities, and implement corrective measures that prevent recurrence. This analytical approach complements the practical skills of configuring clusters, replicating data, and orchestrating failover, resulting in resilient UNIX infrastructures capable of sustaining critical operations under adverse conditions. Training through the Veritas VCP program equips professionals with these analytical competencies, emphasizing both preventive measures and effective response to unforeseen disruptions.
High availability also requires attention to inter-node communication and network reliability. Cluster nodes must exchange state information, coordinate resource allocation, and maintain synchronization to ensure seamless failover. Network latency, packet loss, and configuration inconsistencies can disrupt these processes, making robust network design and monitoring essential. Veritas solutions provide insights into network health, path redundancy, and connectivity, enabling administrators to maintain resilient communication channels that underpin high-availability operations.
Ultimately, implementing high availability in UNIX environments is an exercise in foresight, precision, and orchestration. Professionals must integrate storage management, replication, clustering, monitoring, security, and scalability into a cohesive strategy that ensures uninterrupted service. The Veritas VCP credential equips administrators with the skills, knowledge, and practical experience required to navigate these complexities, providing the confidence and capability to design, deploy, and maintain high-availability infrastructures that meet enterprise demands and sustain mission-critical operations.
Advanced Veritas Storage Solutions for UNIX Systems
Advanced storage solutions in UNIX environments are essential for organizations that demand high performance, data integrity, and operational resilience. Veritas technologies provide a sophisticated framework for managing complex storage infrastructures, enabling administrators to implement features such as volume management, snapshots, replication, data migration, and performance tuning. Mastery of these solutions is a cornerstone of the Veritas Certified Professional credential, equipping professionals with the ability to design storage architectures that are both resilient and scalable while maintaining high availability across diverse workloads.
Veritas Volume Manager offers an extensive suite of functionalities that abstract physical storage into manageable logical units. This abstraction enables administrators to configure, resize, and migrate volumes dynamically without interrupting active workloads, providing unparalleled flexibility. Logical volumes created with Veritas allow for mirroring, striping, and concatenation, facilitating fault tolerance and performance optimization simultaneously. By decoupling storage management from hardware constraints, administrators gain the ability to deploy adaptive storage architectures capable of responding to fluctuating demands and evolving organizational requirements.
Snapshots and clones represent powerful tools for safeguarding data and streamlining operational processes. Snapshots capture point-in-time copies of volumes or file systems, enabling rapid recovery in the event of data corruption, accidental deletion, or system anomalies. Unlike traditional backups, snapshots can be created and reverted with minimal disruption, making them invaluable for high-availability environments where uptime is paramount. Clones extend this functionality by creating writable duplicates of data sets, which can be utilized for testing, reporting, or analytical purposes without impacting production environments. Administrators trained in Veritas solutions leverage these tools to maintain data integrity while supporting operational agility.
Data migration is another critical aspect of advanced storage management, allowing administrators to transfer volumes, file systems, or entire datasets across storage devices without affecting system availability. Migration may be prompted by hardware upgrades, performance optimization, or capacity balancing, and must be executed in a manner that preserves data consistency and accessibility. Veritas tools facilitate seamless data migration through dynamic volume adjustments, replication techniques, and automated failover mechanisms. This capability ensures that UNIX infrastructures remain adaptable, enabling administrators to optimize storage utilization while maintaining uninterrupted service.
Performance tuning in advanced storage environments requires a nuanced understanding of workload characteristics, I/O patterns, and resource allocation. Administrators must monitor metrics such as throughput, latency, disk utilization, and cache performance to identify bottlenecks and optimize configurations. Techniques such as striping, tiered storage, and intelligent caching contribute to enhancing responsiveness while ensuring that redundant copies maintain high availability. Veritas solutions provide comprehensive monitoring and analysis tools, enabling administrators to implement fine-grained performance optimizations that balance speed, reliability, and resilience.
Redundancy strategies in Veritas storage solutions extend beyond simple mirroring or RAID configurations. Administrators can deploy multi-pathing to ensure continuous access to storage devices even if individual network paths or controllers fail. Combined with volume replication and clustering, these strategies create an intricate network of resilient storage pathways that maintain uninterrupted data accessibility. Understanding the interplay between these mechanisms is critical for professionals seeking to deliver high availability in complex UNIX environments, as it allows for proactive failure mitigation and minimal disruption to business operations.
Integration with high-availability frameworks is a fundamental consideration when implementing advanced Veritas storage solutions. Logical volumes, snapshots, clones, and replication strategies must be orchestrated alongside clustering, failover, and load-balancing mechanisms to achieve seamless service continuity. Administrators must ensure that storage transitions during failover events are executed without data loss or service degradation, which requires careful configuration and synchronization of all storage components. Veritas tools provide the automation, monitoring, and alerting capabilities necessary to manage these intricate interdependencies efficiently.
Storage virtualization further enhances the capabilities of advanced UNIX storage environments. By consolidating physical devices into virtual storage pools, administrators can allocate resources dynamically, optimize utilization, and simplify management. Virtual volumes can span multiple devices, allowing workloads to migrate transparently in response to changing operational demands. This approach not only improves flexibility but also reinforces high availability by enabling seamless failover across virtualized storage arrays. Veritas technologies support sophisticated virtualization strategies, offering administrators granular control over logical volumes, replication, and performance tuning within these abstracted environments.
Advanced storage management also involves meticulous capacity planning and lifecycle management. Administrators must forecast growth trends, assess workload characteristics, and allocate resources in a manner that sustains performance and availability. Storage devices require ongoing maintenance, including health monitoring, firmware updates, and preemptive replacement of aging components to prevent failures. Veritas tools provide administrators with insights into disk health, utilization trends, and capacity metrics, facilitating informed decision-making and proactive interventions that extend the lifespan of storage infrastructures.
Security considerations are integral to advanced storage solutions, as administrators must protect sensitive data while maintaining high availability. Encryption, access control, and auditing mechanisms ensure that data remains confidential and tamper-resistant without impacting performance. Veritas solutions integrate these security features with storage management capabilities, enabling administrators to implement robust policies that safeguard critical data while supporting continuous operations. Security monitoring also complements high-availability strategies by detecting anomalies that could threaten both data integrity and system uptime.
Disaster recovery planning is closely linked to advanced storage strategies. Administrators must design storage architectures that support rapid recovery in the event of catastrophic failures, leveraging replication, snapshots, and clones to restore operations efficiently. The ability to replicate volumes across geographically dispersed sites enhances resilience against localized disasters, while automated failover mechanisms ensure uninterrupted access to replicated data. Veritas training emphasizes the integration of storage solutions with disaster recovery procedures, enabling administrators to create infrastructures that maintain operational continuity under the most adverse conditions.
Monitoring and analytics are indispensable for maintaining advanced storage solutions in optimal condition. Administrators must analyze detailed metrics related to I/O performance, latency, throughput, and error rates to detect potential issues before they affect system availability. Predictive analytics and trend monitoring allow for proactive adjustments, ensuring that storage resources are allocated efficiently and that high-availability configurations are maintained. Veritas tools provide comprehensive monitoring dashboards and reporting capabilities, empowering administrators to make data-driven decisions and optimize storage performance continuously.
Advanced storage strategies also involve optimizing data placement and access patterns. Tiered storage architectures allocate high-performance devices to critical workloads while relegating less sensitive data to lower-cost media, balancing performance and cost efficiency. Striping and concatenation techniques distribute workloads across multiple devices to enhance throughput, while replication and mirroring safeguard data against loss. Administrators must carefully orchestrate these strategies, considering the unique requirements of applications, workloads, and service-level agreements to ensure both performance and resilience.
The orchestration of storage and high availability extends to application-level considerations. Certain applications require low-latency access to specific volumes, consistent data replication, and seamless failover support. Administrators must configure storage solutions to meet these requirements, coordinating logical volumes, snapshots, replication schedules, and failover policies to deliver uninterrupted service. Veritas tools provide automation and monitoring capabilities that simplify this orchestration, allowing administrators to maintain consistency, performance, and availability across the entire infrastructure.
Performance tuning in advanced Veritas environments also involves intelligent caching strategies. By leveraging cache memory to store frequently accessed data, administrators can reduce latency, improve response times, and optimize resource utilization. Combined with monitoring and analytics, caching strategies contribute to a highly responsive and resilient storage environment. Veritas solutions allow administrators to configure, monitor, and adjust caching policies dynamically, ensuring that performance objectives are met without compromising availability or data integrity.
Administrators must also consider the interaction of storage solutions with network infrastructure. Network bandwidth, latency, and redundancy directly affect replication, failover, and virtualization performance. Configuring multiple paths, balancing loads, and monitoring connectivity ensures that data remains accessible under varying network conditions. Veritas solutions provide comprehensive insights into networked storage interactions, enabling administrators to maintain high availability and consistent performance across distributed UNIX environments.
Ultimately, advanced storage solutions in UNIX environments require a synthesis of technical knowledge, strategic planning, and operational discipline. Administrators must integrate volume management, snapshots, clones, replication, virtualization, performance tuning, and security into cohesive infrastructures that support high availability. The Veritas VCP credential equips professionals with the skills, analytical abilities, and practical experience needed to implement and maintain these solutions, enabling organizations to achieve resilient, scalable, and high-performance storage infrastructures capable of supporting critical enterprise operations.
Troubleshooting and Problem Resolution in UNIX Storage
Troubleshooting UNIX storage and high-availability environments requires a precise blend of analytical skills, practical experience, and methodical problem-solving approaches. Administrators tasked with maintaining complex storage infrastructures must navigate issues ranging from disk failures and logical volume inconsistencies to replication errors and cluster misconfigurations. Mastery of these problem-solving techniques is essential for professionals pursuing the Veritas Certified Professional credential, as it equips them with the ability to diagnose, remediate, and prevent failures that could compromise data integrity or service continuity.
One of the most common challenges in UNIX storage management involves identifying and addressing disk-related failures. Physical storage components, despite redundancy and fault tolerance measures, can suffer from wear, corruption, or controller malfunctions. Administrators must be adept at interpreting diagnostic information, recognizing early warning signs such as latency spikes, unusual I/O patterns, or error messages, and taking preemptive measures to prevent system-wide disruptions. Veritas tools provide utilities to monitor disk health, perform automated error detection, and execute controlled volume failover to maintain uninterrupted access.
Logical volume inconsistencies present another layer of complexity. When volumes are improperly configured, experience metadata corruption, or encounter allocation conflicts, administrators must reconcile these inconsistencies while preserving the integrity of the underlying data. Techniques such as volume verification, metadata repair, and re-synchronization are employed to restore normal operation. Professionals trained in Veritas solutions gain hands-on experience in these procedures, learning to navigate the intricate relationships between physical disks, logical volumes, and file systems to maintain system stability.
File system anomalies are a frequent source of operational disruption. Issues such as corruption, journal inconsistencies, or misaligned allocation units can impede access to data or degrade performance. Administrators must employ diagnostic utilities to identify the nature and location of the problem, determine whether it affects multiple volumes or nodes, and execute corrective actions such as fsck operations, remounting, or file system reconstruction. By mastering these techniques, professionals can mitigate the risk of data loss and maintain high-availability standards even under adverse conditions.
Replication and mirroring failures introduce additional complexity in high-availability UNIX environments. Synchronous and asynchronous replication processes can encounter network disruptions, misconfigurations, or device inconsistencies that compromise data redundancy. Administrators must investigate replication logs, validate consistency between primary and secondary volumes, and initiate resynchronization procedures when necessary. Veritas tools facilitate these operations by providing detailed reporting, automated recovery options, and monitoring of replication status, enabling administrators to restore resilient configurations efficiently.
Clustering issues are another critical domain of troubleshooting in high-availability UNIX systems. Cluster nodes may fail to communicate due to network problems, quorum misconfigurations, or software anomalies. Administrators must understand cluster architecture, node membership protocols, and failover sequences to diagnose and correct issues without causing service interruptions. Techniques such as rejoining nodes, resetting cluster configurations, and verifying resource dependencies ensure that workloads continue to operate seamlessly despite transient or persistent failures. Veritas solutions provide the necessary tools to monitor cluster health, coordinate failover, and maintain consistent operation across multiple nodes.
Performance degradation is a subtle but significant challenge in storage management. High I/O latency, uneven load distribution, or excessive caching delays can affect system responsiveness and user experience. Administrators must conduct in-depth performance analysis, examining throughput metrics, disk utilization, and network bandwidth utilization. Optimizations such as re-striping volumes, rebalancing workloads, adjusting caching policies, or reallocating storage resources may be required to restore optimal performance. Veritas solutions provide comprehensive monitoring and diagnostic capabilities, enabling administrators to identify bottlenecks and implement corrective measures with precision.
Networked storage introduces additional troubleshooting considerations, especially when dealing with SANs or NAS devices. Connectivity issues, path failures, and protocol mismatches can disrupt access to critical volumes. Administrators must verify cabling, check multipathing configurations, and ensure proper protocol alignment to restore consistent connectivity. Veritas utilities provide real-time monitoring and path redundancy features, allowing administrators to maintain uninterrupted access to storage resources even under adverse network conditions.
Security-related anomalies can also impact UNIX storage availability. Unauthorized access attempts, misconfigured permissions, or encryption failures can lead to inaccessible volumes or disrupted replication processes. Administrators must monitor access logs, audit changes, and verify encryption status to maintain both data integrity and service continuity. Veritas solutions integrate security monitoring with storage management, offering administrators the ability to enforce policies, detect irregularities, and remediate issues promptly.
Preventive maintenance is a cornerstone of effective problem resolution. By regularly monitoring system health, performing disk inspections, and updating firmware, administrators can reduce the likelihood of unexpected failures. Proactive measures such as scheduled consistency checks, volume scrubbing, and redundancy verification ensure that storage systems remain in optimal condition. Veritas tools automate many of these preventive tasks, allowing administrators to focus on strategic oversight and advanced troubleshooting when anomalies occur.
Root-cause analysis is an essential skill for UNIX storage administrators. When a failure occurs, it is not sufficient to restore operation temporarily; the underlying cause must be identified and addressed to prevent recurrence. Administrators examine error logs, system metrics, and historical trends to understand the sequence of events leading to failure. This analytical approach complements practical remediation skills, enabling administrators to implement long-term solutions that enhance system resilience. Veritas training emphasizes the development of these diagnostic capabilities, preparing professionals to manage complex, high-stakes environments effectively.
Scenario-based troubleshooting is a valuable method for honing problem-solving skills. Real-world situations may involve simultaneous hardware failures, network disruptions, and software anomalies, requiring administrators to prioritize actions and coordinate recovery efforts across multiple domains. Techniques such as isolating affected components, restoring critical services first, and incrementally addressing secondary issues allow administrators to maintain control under challenging circumstances. Veritas solutions provide tools for logging, alerting, and automating recovery sequences, enhancing the administrator’s ability to navigate complex operational scenarios efficiently.
Integration between storage management and high-availability mechanisms introduces further troubleshooting complexity. Failover events, volume migrations, and replication resynchronizations can interact in unexpected ways, requiring administrators to consider dependencies, sequencing, and resource allocation. Misaligned configurations or overlooked dependencies may result in partial failures or service interruptions. Professionals trained in Veritas solutions develop the skill to visualize system interdependencies, anticipate potential conflicts, and implement cohesive remediation strategies that maintain continuity across the entire infrastructure.
Capacity-related problems also impact storage performance and availability. Overutilized volumes, exhausted logical partitions, or imbalanced workload distribution can lead to latency, system errors, or replication delays. Administrators must continuously monitor utilization metrics, forecast growth, and adjust volume allocations dynamically to prevent these issues. Veritas tools provide comprehensive visibility into storage consumption patterns, enabling proactive interventions that sustain operational efficiency and prevent bottlenecks.
Documentation and knowledge management play a critical role in effective troubleshooting. Maintaining detailed records of configurations, error occurrences, remediation steps, and performance trends allows administrators to address recurring issues more efficiently. Historical insights facilitate root-cause analysis, reduce resolution times, and provide a basis for preventive strategies. Veritas training emphasizes disciplined documentation practices, equipping professionals with the organizational skills necessary to manage complex storage environments systematically.
Collaboration with other IT teams is often essential when resolving complex UNIX storage problems. Network engineers, system administrators, application developers, and security personnel may need to coordinate to address cross-domain issues. Effective communication, shared diagnostics, and aligned remediation strategies ensure that resolution is both timely and comprehensive. Veritas solutions enhance this collaborative approach by providing centralized monitoring, alerting, and reporting features that give all stakeholders visibility into system health and operational status.
Emergent issues, such as sudden hardware failures or unexpected application behavior, test the administrator’s ability to respond rapidly and decisively. Incident response protocols, predefined recovery procedures, and automated failover mechanisms reduce the time to resolution and minimize operational impact. Professionals trained in Veritas solutions learn to execute these procedures effectively, balancing immediate remediation with long-term stability and data integrity considerations.
Ultimately, troubleshooting UNIX storage and high-availability systems requires a synthesis of technical knowledge, analytical reasoning, operational discipline, and proactive planning. Administrators must navigate physical hardware issues, logical volume anomalies, file system inconsistencies, replication failures, cluster misconfigurations, and performance bottlenecks while maintaining continuous service. The Veritas VCP credential equips professionals with the skills, tools, and methodologies necessary to diagnose, remediate, and prevent these issues, ensuring that storage infrastructures remain resilient, performant, and capable of supporting critical enterprise operations.
Preparing for the Veritas VCP Certification Exam and Career Advancement
Achieving the Veritas Certified Professional credential in storage management and high availability for UNIX represents a significant milestone for IT professionals seeking to demonstrate expertise in resilient and scalable infrastructure management. Preparation for this certification requires a comprehensive understanding of storage architecture, logical volume management, clustering, replication, high-availability techniques, and performance optimization. Beyond technical knowledge, candidates must cultivate analytical reasoning, practical problem-solving skills, and an awareness of operational best practices to excel in real-world UNIX environments.
Understanding the exam structure is critical to effective preparation. The assessment evaluates both theoretical knowledge and practical application of Veritas storage solutions. Candidates are expected to demonstrate proficiency in configuring and managing logical volumes, orchestrating failover and replication mechanisms, tuning system performance, and resolving complex issues that may arise in enterprise UNIX environments. Veritas emphasizes the integration of storage management with high-availability strategies, ensuring that professionals can maintain uninterrupted service while optimizing resource utilization. Preparation therefore involves not only mastering commands and procedures but also understanding the interplay between storage components, applications, and clustering architectures.
A systematic study approach is recommended for candidates pursuing the credential. The first step involves gaining a thorough grounding in UNIX storage fundamentals, including physical and logical storage concepts, file system structures, volume management techniques, and RAID configurations. Administrators must become comfortable with abstraction mechanisms that decouple storage management from hardware constraints, enabling dynamic resizing, migration, and mirroring of volumes. Veritas tools provide a practical interface for these operations, and hands-on experience is invaluable for internalizing these concepts. Understanding these foundational elements allows candidates to tackle more advanced topics with confidence and precision.
High availability forms a central theme in the certification curriculum. Candidates must understand clustering principles, node communication protocols, quorum policies, and failover mechanisms. Mastery of these concepts enables administrators to design infrastructures that remain operational despite hardware or software failures. Practical scenarios in the exam may involve configuring redundant paths, orchestrating node failovers, or troubleshooting cluster inconsistencies. Familiarity with Veritas utilities that automate failover, monitor system health, and maintain resource consistency is crucial for demonstrating competency in these areas.
Replication strategies, both synchronous and asynchronous, are also emphasized in preparation for the certification. Candidates must understand the trade-offs between immediate consistency and geographical dispersion, the impact of network latency, and methods to ensure data integrity across primary and secondary systems. Replication failures and recovery processes are frequently tested in practical scenarios, requiring administrators to verify consistency, resynchronize volumes, and maintain high availability during recovery operations. Veritas tools simplify these procedures by providing monitoring, reporting, and automated resynchronization capabilities, which candidates must be adept at utilizing.
Performance optimization is another key focus area. Administrators must be capable of analyzing I/O patterns, latency, throughput, and cache efficiency to identify bottlenecks and implement solutions that enhance responsiveness. Techniques such as tiered storage allocation, load balancing, and intelligent caching improve system efficiency while maintaining redundancy and availability. Candidates are expected to apply these techniques to both theoretical scenarios and practical exercises, demonstrating the ability to optimize complex UNIX storage environments effectively.
Troubleshooting skills are integral to the certification, reflecting the real-world challenges faced by UNIX administrators. Candidates must diagnose disk failures, logical volume inconsistencies, file system anomalies, replication issues, cluster misconfigurations, and performance degradation. Proficiency in root-cause analysis, preventive maintenance, and scenario-based problem-solving is tested to ensure that professionals can maintain operational continuity in complex environments. Veritas solutions provide monitoring, alerting, and automated recovery tools, and candidates must demonstrate their ability to leverage these features for timely and effective resolution.
Effective preparation also involves simulating real-world scenarios, including maintenance operations, disaster recovery drills, and emergency failover situations. Administrators must plan and execute volume migrations, firmware updates, cluster expansions, and replication adjustments without compromising availability. Hands-on experience in these scenarios builds confidence, reinforces conceptual knowledge, and cultivates the decision-making skills necessary to respond to unexpected events. Candidates are evaluated on their ability to maintain seamless operations while executing complex procedures, reflecting the practical demands of enterprise UNIX environments.
Resource management is another aspect assessed in the certification. Candidates must demonstrate the ability to forecast storage requirements, manage capacity dynamically, and align infrastructure with organizational growth and workload fluctuations. Monitoring tools provided by Veritas allow administrators to analyze utilization trends, predict potential bottlenecks, and implement proactive adjustments. Candidates are expected to integrate these insights into their strategies for high availability, ensuring that performance and redundancy are sustained even as storage demands evolve.
Security considerations are intertwined with high availability and storage management. Candidates must understand access control, encryption, auditing, and policy enforcement, and how these elements interact with replication, clustering, and volume management. UNIX administrators are tasked with safeguarding sensitive data while ensuring continuous accessibility, a challenge that requires both technical acumen and strategic foresight. Veritas tools provide integrated monitoring and policy management features, which candidates must be proficient in using to maintain secure, resilient storage infrastructures.
Documentation and procedural discipline are critical components of preparation. Maintaining detailed records of configurations, troubleshooting steps, performance trends, and recovery procedures supports efficient problem resolution, compliance, and operational continuity. Candidates must demonstrate awareness of best practices for documenting complex storage and high-availability environments, reflecting the professionalism expected of Veritas-certified administrators. These habits not only aid in passing the exam but also cultivate skills that enhance long-term career success.
Study resources for the certification include official Veritas guides, hands-on labs, online tutorials, and practice assessments. Candidates benefit from iterative learning cycles, combining theoretical review with practical application. Emphasis is placed on understanding the underlying principles behind commands, configurations, and recovery procedures rather than rote memorization. This approach ensures that administrators are equipped to handle diverse scenarios encountered in real-world UNIX environments, aligning exam preparation with professional competence.
Mentorship and collaborative learning also play a role in effective preparation. Engaging with experienced administrators, participating in discussion forums, and reviewing case studies provide insights into practical challenges and nuanced problem-solving techniques. Candidates can gain perspective on strategies for high availability, storage optimization, and disaster recovery that may not be fully captured in formal study materials. Sharing experiences and solutions fosters a deeper understanding and prepares candidates for the complex scenarios presented in the certification assessment.
Time management during the exam is another critical consideration. Candidates must allocate sufficient attention to both practical exercises and conceptual questions, ensuring that they demonstrate proficiency across all domains of storage management and high availability. Practicing under timed conditions, reviewing sample scenarios, and familiarizing oneself with the Veritas interface enhances performance and reduces exam-day stress. Successful candidates combine preparation, practical skill, and analytical reasoning to navigate the assessment efficiently and accurately.
Career advancement following the achievement of the Veritas certification is substantial. Certified professionals are recognized as experts in UNIX storage management and high-availability practices, opening opportunities for roles such as system architect, storage engineer, enterprise infrastructure consultant, and high-availability specialist. Employers value candidates who can design resilient infrastructures, troubleshoot complex storage environments, and ensure uninterrupted operations. The credential also enhances professional credibility, provides a competitive edge in the job market, and serves as a foundation for continued growth in enterprise IT infrastructure management.
Continuous learning and skill enhancement are encouraged even after certification. Technology evolves rapidly, and administrators must remain conversant with emerging storage solutions, clustering techniques, virtualization strategies, and high-availability best practices. Engagement with professional communities, ongoing training, and hands-on experimentation ensure that certified professionals maintain proficiency and adapt to evolving enterprise requirements. Veritas-certified administrators are positioned to contribute strategically to organizational resilience, performance optimization, and long-term infrastructure planning.
Ultimately, the Veritas Certified Professional credential is both a benchmark of technical mastery and a catalyst for professional development. By preparing diligently, mastering practical skills, and cultivating analytical and strategic thinking, candidates position themselves to excel in the management of UNIX storage and high-availability environments. The preparation process integrates theoretical knowledge, hands-on experience, troubleshooting, performance tuning, and strategic planning, reflecting the multifaceted nature of modern enterprise infrastructure management.
Conclusion
Achieving this certification validates not only technical competence but also a commitment to operational excellence, resilience, and continuous professional growth. It signifies that an administrator can design, implement, and maintain complex storage and high-availability infrastructures while anticipating challenges, mitigating risks, and ensuring seamless service delivery. As organizations increasingly rely on resilient UNIX environments for mission-critical operations, Veritas-certified professionals are uniquely positioned to deliver reliability, performance, and strategic value, cementing their role as indispensable contributors to enterprise success.
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Veritas Certifications
- VCP Storage Management and High Availability for UNIX - Veritas Certified Professional Storage Management and High Availability for UNIX
- VCS - Veritas Certified Specialist
- VCS Backup Exec - Veritas Certified Specialist Backup Exec
- VCS Enterprise Vault - Veritas Certified Specialist Enterprise Vault
- VCS InfoScale - Veritas Certified Specialist InfoScale
- VCS NetBackup - Veritas Certified Specialist NetBackup
- VCS Storage Foundation - Veritas Certified Specialist Storage Foundation
