
Certification: Salesforce Certified Data Architecture and Management Designer
Certification Full Name: Salesforce Certified Data Architecture and Management Designer
Certification Provider: Salesforce
Exam Code: Certified Data Architecture and Management Designer
Exam Name: Certified Data Architecture and Management Designer
Product Screenshots
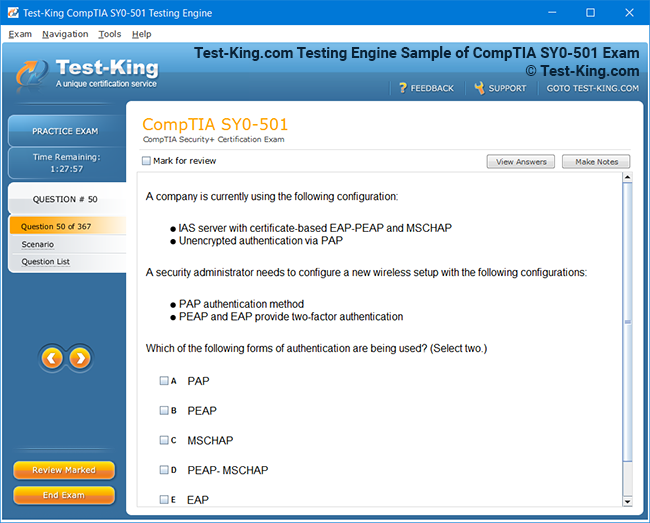
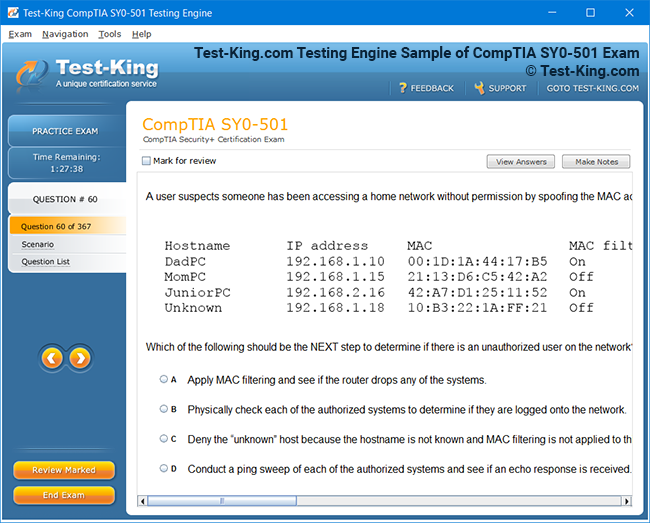
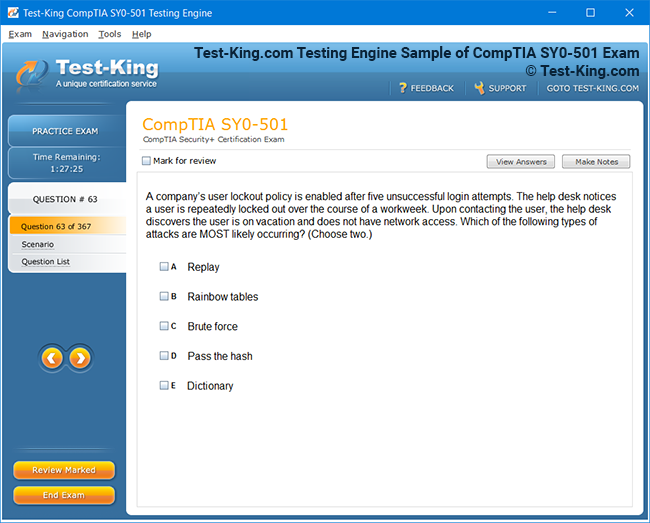
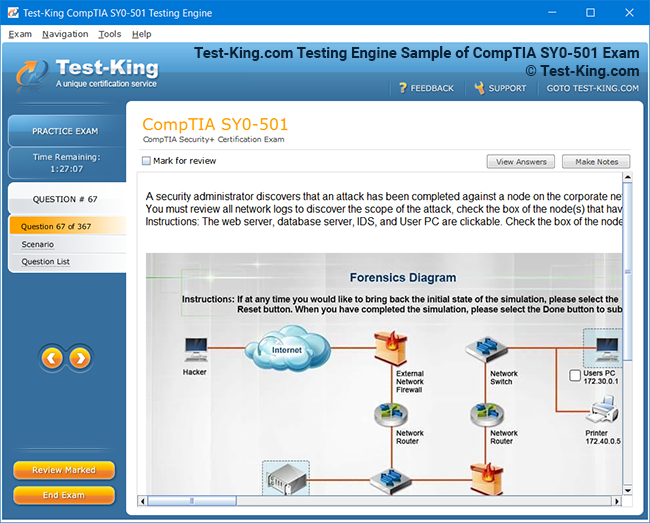
Understanding Salesforce Certified Data Architecture and Management Designer Certification
The Salesforce Data Architecture and Management Designer exam evaluates a candidate’s ability to design and implement data strategies on the Salesforce platform. It focuses on ensuring enterprise data management solutions are scalable, efficient, and aligned with organizational objectives. Candidates are expected to demonstrate a nuanced understanding of data modeling, database design, large data volume considerations, data governance, master data management, and migration strategies. Unlike typical exams, it not only tests theoretical knowledge but also gauges practical aptitude for solving real-world data management challenges in a Salesforce environment. A data architect, in this context, is responsible for creating resilient architectures that prevent performance bottlenecks, preserve data integrity, and ensure compliance with governance standards.
Overview of Salesforce Data Architecture and Management Designer Exam
The examination comprises sixty multiple-choice and multiple-select questions, to be completed within one hundred and five minutes. Although the passing score is fifty-eight percent, the test includes a few unscored items used to gauge future assessments. A registration fee of four hundred US dollars, plus applicable local taxes, applies. The exam does not require prerequisites, but it is advantageous for candidates to possess a solid foundation in Salesforce technology, coupled with extensive experience in data-centric initiatives. Ideal candidates typically have one to two years of hands-on Salesforce experience and five to eight years of involvement in projects requiring meticulous data management. They are familiar with assessing business requirements, proposing data solutions, and communicating trade-offs and design decisions to stakeholders with clarity.
A successful candidate is expected to understand how data interacts across the Salesforce ecosystem. This includes mastering the nuances of data models, appreciating the distinctions between standard, custom, and big objects, and recognizing how large datasets influence platform performance. They should also possess the acumen to identify scenarios where external data integration is preferable, optimize queries for efficiency, and design batch processes for asynchronous operations. Furthermore, candidates must be conversant with maintaining high data quality, implementing workflow rules, setting up dashboards for monitoring, and leveraging data enrichment tools to ensure accuracy and completeness.
Role and Responsibilities of a Salesforce Data Architect
A Salesforce Data Architect functions at the intersection of technology, business processes, and organizational strategy. Their primary responsibility is to orchestrate data structures that facilitate a single source of truth for enterprise data. In practice, this involves assessing the organization’s current data landscape, identifying inefficiencies or potential risks, and designing solutions that harmonize disparate data sources. They must understand both the technical intricacies of Salesforce and the business imperatives driving data requirements. This dual perspective allows them to recommend organizational changes that enhance data stewardship, ensuring records remain consistent, traceable, and compliant with regulatory obligations.
Data architects are frequently called upon to solve challenges related to large data volumes. For instance, improper management of record ownership and parent-child relationships can result in performance degradation due to record locking and sharing recalculations. They must also account for complex scenarios involving multiple Salesforce instances or integration with external systems, ensuring data consistency across platforms. The ability to communicate these solutions effectively to business stakeholders distinguishes exemplary candidates, as it bridges the gap between technical design and practical implementation. They must justify design decisions, explain potential trade-offs, and illustrate how their proposed architecture will sustain both operational efficiency and scalability.
Key Knowledge Areas for the Exam
The Salesforce Data Architecture and Management Designer exam emphasizes six main areas. Data modeling and database design constitute a substantial portion, requiring candidates to understand the creation of objects, fields, and relationships that support organizational objectives. Ownership skew, which occurs when a single user owns a large number of records, can cause sharing recalculation delays. Parenting skew, involving a single parent record with an excessive number of child records, can result in record locking and performance issues. Mitigating these scenarios often involves distributing records across multiple owners or parent records, utilizing assignment rules, and strategically leveraging external objects or picklist fields to optimize relationships.
Master data management, though comprising a smaller portion of the exam, is equally vital. It involves harmonizing and consolidating data from multiple sources to create a single source of truth. Techniques include establishing survivorship rules to determine authoritative records, leveraging canonical modeling for consistency, and using external reference data for enrichment. Candidates must be capable of recommending approaches to maintain data traceability and consistency, particularly when multiple systems interact with Salesforce. Creating a “golden record” in a single organizational context ensures that all operational decisions are based on accurate, complete, and reliable data.
Salesforce data management forms another significant domain. Candidates are expected to understand how to combine license types effectively to utilize standard and custom objects in alignment with business requirements. Techniques for ensuring consistent data persistence, consolidating records from multiple Salesforce instances, and representing a unified view of the customer are central to this knowledge area. Additionally, candidates should be aware of data lifecycle considerations, including archiving and purging strategies to optimize storage and maintain performance.
Data governance represents a smaller but critical component of the exam. It includes designing compliant models aligned with regulatory frameworks such as GDPR. Candidates must understand how to identify, classify, and protect sensitive information, as well as design enterprise-wide governance programs that ensure data integrity, security, and accessibility. Large data volume considerations account for a substantial portion of the test. Here, candidates must demonstrate the ability to design scalable models, optimize query performance, and recommend archiving or purging plans to prevent storage and retrieval bottlenecks. Techniques such as using external data objects, PK chunking, and batch processing are essential for maintaining performance with millions of records.
Data migration, while forming the final domain, requires candidates to be adept at moving data into Salesforce efficiently and accurately. Understanding the nuances of Bulk API 1.0 and 2.0, implementing strategies for high-quality data loads, and improving performance during large-scale imports are critical skills. Exporting data efficiently, consolidating multiple data sources, and ensuring the preservation of integrity during transfers also form part of the expected expertise.
Preparing for the Salesforce Data Architecture and Management Designer Exam
Preparation for the exam is multifaceted and requires both theoretical understanding and practical experience. Candidates should immerse themselves in Salesforce documentation, Trailhead modules, and other official study resources. Hands-on practice with Salesforce environments is indispensable, particularly in scenarios involving large datasets and complex object relationships. Engaging in exercises that involve batch processing, query optimization, and data integration from external sources strengthens one’s ability to navigate real-world challenges effectively.
A strong grasp of workflow rules, page layout customization, dashboards, and duplicate management tools is essential for maintaining high data quality. Understanding how to configure Data.com Clean or other enrichment tools is also important, as these mechanisms ensure that data remains current, accurate, and actionable. Familiarity with archiving strategies, including indexing and maintaining searchable records, prepares candidates to design long-term storage solutions without sacrificing performance or compliance.
Candidates should also focus on developing analytical skills to evaluate design trade-offs. This includes understanding when to use big objects versus custom or standard objects, how to distribute ownership to prevent skew, and how to implement external objects to handle large data volumes efficiently. Optimizing queries through indexing, minimizing joins, and leveraging batch processes further ensures that the platform remains responsive even under heavy data loads. Mastery of these principles enables a candidate to design data architectures that are not only functional but also resilient, scalable, and adaptable to evolving business requirements.
In addition to technical proficiency, successful candidates exhibit strong communication and problem-solving abilities. They must be capable of translating technical challenges into comprehensible recommendations for business stakeholders. This skill set allows them to advocate for data governance policies, propose improvements to data management processes, and justify architectural decisions with clarity. Effective communication ensures that stakeholders understand the rationale behind design choices and can support initiatives that enhance data quality and system performance.
Candidate Experience and Background
The ideal candidate has a blend of Salesforce expertise and broader data management experience. One to two years of Salesforce-specific experience equips them with knowledge of the platform’s capabilities and limitations. Coupled with five to eight years of experience in data-intensive projects, this background allows candidates to navigate complex requirements, design sophisticated solutions, and anticipate performance challenges before they arise. Their experience often includes assessing multiple business units’ data needs, harmonizing disparate datasets, and implementing governance programs that ensure compliance with organizational and regulatory standards.
A seasoned candidate also understands the strategic implications of data architecture decisions. They recognize that choices made at the design stage affect system performance, scalability, and user adoption. By evaluating the trade-offs between different modeling approaches, storage mechanisms, and integration methods, candidates demonstrate a capacity for foresight and prudence in decision-making. These qualities are critical in designing Salesforce environments that remain robust as organizational demands evolve and datasets grow exponentially.
Significance of Exam Domains in Practical Scenarios
Each domain within the exam reflects practical challenges encountered by data architects. Data modeling ensures that objects, fields, and relationships support business processes efficiently. Master data management consolidates data from multiple sources, creating authoritative records that guide decision-making. Salesforce data management focuses on how licenses and objects are leveraged to meet operational requirements. Data governance encompasses compliance and security, ensuring that sensitive data is protected. Large data volume considerations address performance, scalability, and query efficiency. Data migration emphasizes the proper movement of data into the Salesforce ecosystem without compromising quality or performance. Mastery of these domains ensures that candidates are equipped to handle both current and future data challenges.
Data architects who excel in these areas can foresee potential bottlenecks, design for resilience, and implement strategies that maintain system responsiveness. They ensure that queries, reporting, and integration operations are executed efficiently, even under the strain of millions of records. They can recommend archiving or purging strategies to optimize storage while maintaining accessibility and compliance. In migration scenarios, they can manage large-scale data transfers without introducing inconsistencies or performance degradation.
Understanding Data Modeling in Salesforce
Data modeling is the foundation of effective Salesforce architecture. It is the deliberate organization of objects, fields, relationships, and metadata to support both current and future business requirements. A robust data model ensures the platform can scale efficiently, accommodate increasing data volumes, and provide accurate reporting and analytics. Poor data modeling often leads to inefficiencies, sluggish performance, and difficulties in maintaining data integrity. Therefore, understanding the nuances of Salesforce objects, including standard, custom, and big objects, is essential for any data architect. Each object type serves a specific purpose, with standard objects providing built-in functionalities, custom objects offering flexibility, and big objects catering to massive datasets without compromising system performance.
A core principle in data modeling is establishing relationships between objects that mirror real-world business interactions. Master-detail and lookup relationships each carry unique implications for record ownership, security, and data accessibility. Master-detail relationships tightly couple child records to their parent, automatically inheriting sharing and security settings, whereas lookup relationships offer more flexibility but can introduce complexities in access control. Candidates preparing for the exam must comprehend these subtleties and determine which relationship type is most appropriate based on operational requirements and anticipated data volumes.
Ownership Skew and Its Implications
Ownership skew occurs when a single user owns an excessive number of records, often exceeding ten thousand. This scenario can trigger performance issues due to sharing recalculations whenever changes occur in the role hierarchy. For example, moving a user in the hierarchy necessitates recalculating access for all records owned by that user and any subordinate roles, potentially leading to significant system delays. Mitigating ownership skew involves distributing records across multiple users, leveraging lead and case assignment rules, and, when necessary, assigning records to isolated users at strategic points in the hierarchy to prevent performance bottlenecks.
Integrating ownership considerations into the data model requires foresight. Architects must anticipate user behavior, peak transaction volumes, and potential integration workflows to avoid skewed ownership patterns. In scenarios where integrations generate substantial records, avoiding assignment to a single integration user is crucial. Instead, splitting records among multiple users or external objects can alleviate strain on sharing calculations. Candidates must recognize these scenarios and understand the technical rationale for distributing ownership, as it directly impacts performance, data accessibility, and compliance.
Parenting Skew and Database Performance
Parenting skew arises when a single parent record is associated with an excessive number of child records, typically over ten thousand. This can cause implicit sharing calculations to slow dramatically and may result in record locking when multiple batches attempt to update children simultaneously. Parenting skew is particularly relevant when importing data in bulk or when automating processes that link child records to a single parent. Mitigating parenting skew requires careful distribution of child records across multiple parents, using external objects, or utilizing picklist fields where feasible for smaller lookup associations.
Understanding the impact of parenting skew extends beyond performance. Implicit sharing logic can introduce unexpected access issues, as Salesforce must evaluate all child records to determine continued parent access. This evaluation affects queries, reporting, and automated processes. Data architects must model relationships to minimize these risks, often employing partitioning strategies, batching, and asynchronous processing to ensure that large data sets do not compromise system integrity. These strategies are critical when designing scalable solutions for organizations with high transaction volumes and complex relational hierarchies.
Big Objects Versus Standard and Custom Objects
Big objects are a specialized Salesforce object type designed to store and manage massive datasets efficiently. Unlike standard and custom objects, big objects do not have the same limitations on data volume and can accommodate billions of records without impacting platform performance. However, they lack certain features such as triggers and workflows, requiring architects to design alternative processing mechanisms. Candidates must understand when to implement big objects versus leveraging standard or custom objects, taking into account performance, reporting needs, and integration requirements.
Choosing the correct object type necessitates a comprehensive assessment of data characteristics. Standard and custom objects are ideal for operational transactions and real-time interactions, while big objects excel in archiving, historical tracking, and analytics. Data architects should evaluate how frequently records will be accessed, queried, or modified and select the object type that balances performance with usability. Effective utilization of big objects often involves indexing strategies and carefully designed queries to maintain efficient retrieval times despite enormous data volumes.
Optimizing Relationships and Metadata Management
Relationship design is paramount in Salesforce data modeling. In addition to ownership and parenting considerations, architects must carefully manage metadata, such as field definitions, validation rules, and data types. Proper metadata management ensures consistency across objects, prevents redundancy, and facilitates governance. Field types must be chosen thoughtfully, with picklists standardizing input, date fields enabling temporal analysis, and currency fields maintaining financial accuracy. Custom metadata types can enhance flexibility, allowing reusable configuration data without creating additional records, thereby minimizing performance overhead.
Metadata management extends to capturing business definitions, lineage, and taxonomy. Understanding how data flows through the system, where transformations occur, and how records relate across multiple objects provides a framework for both governance and scalability. This approach is crucial for complex organizations with multiple business units, each maintaining its own operational data while contributing to a unified organizational dataset. Proper metadata design reduces ambiguity, ensures traceability, and supports long-term system maintainability.
Efficient Querying and Indexing
Query optimization is an indispensable element of Salesforce data modeling. Inefficient queries can slow system performance, particularly when dealing with millions of records. Using indexed fields in query filters improves retrieval times and reduces computational load. Avoiding negative filters, leading wildcards, and full table scans further enhances performance. Salesforce provides tools such as the query plan analyzer to assist in identifying costly queries and suggesting optimal indexing strategies. Candidates must understand both the technical mechanics and the practical implications of query design in large-scale environments.
Indexing strategies must be considered during data model design. Composite indexes, custom indexes, and selective filters allow queries to execute efficiently even as datasets expand. Architects must balance the desire for flexibility with performance considerations, ensuring that frequently queried fields are indexed while maintaining system manageability. Strategic indexing combined with proper relationship design prevents excessive resource consumption and improves both operational and analytical performance.
Batch Processing and Asynchronous Operations
Asynchronous processing is a cornerstone of managing large datasets within Salesforce. Batch Apex enables the processing of up to fifty million records asynchronously, allowing architects to design workflows and integrations that do not compromise real-time system performance. This capability is essential for operations such as bulk imports, mass updates, and data cleansing, particularly in organizations with substantial daily transaction volumes.
Designing batch processes requires careful attention to batch sizes, scheduling, and error handling. Architects must anticipate potential conflicts, such as record locking due to parenting skew, and implement strategies to mitigate failures. This planning ensures that large-scale operations proceed smoothly without interrupting user activity or delaying reporting. Understanding the nuances of asynchronous processing, combined with query optimization and batch sizing, forms a fundamental component of a data architect’s skill set.
Strategies for Avoiding Data Skew in Design
Preventing data skew is an ongoing consideration in database design. Ownership and parenting skew can be mitigated through deliberate allocation of records, judicious use of external objects, and intelligent partitioning strategies. For example, distributing contacts among multiple accounts or leveraging picklist fields instead of lookups for smaller sets of data reduces the likelihood of skew-related performance issues. Architects must anticipate patterns in data creation, ownership assignment, and integration workflows to maintain consistent performance.
Proactive skew management extends to reporting and analytics. Queries, dashboards, and aggregate calculations must be designed to accommodate the possibility of skewed datasets without introducing delays or inaccuracies. Partitioned reporting, selective indexing, and optimized query design ensure that even large datasets can be processed efficiently, delivering timely insights for business decision-making.
Data Migration Considerations in Database Design
Data migration is intimately linked to data modeling. The architecture must facilitate efficient transfer of records into Salesforce while maintaining quality and consistency. Bulk API 1.0 and 2.0 provide mechanisms for asynchronous data operations, each with unique characteristics. Bulk API 1.0 requires manual batch preparation, while Bulk API 2.0 handles batch processing automatically, simplifying large-scale data transfers. Candidates must understand these mechanisms, selecting the most suitable approach based on data volume, system performance, and operational requirements.
High-quality migration involves more than just moving records. Architects must ensure data is clean, deduplicated, and consistent with organizational rules. Sharing calculations and record ownership must be considered to avoid introducing skew or locking conflicts. Migration strategies should integrate with overall data architecture, leveraging batch processing, external objects, and indexing to minimize disruption and maintain system performance. Proper migration planning reduces the risk of data corruption and preserves the integrity of existing workflows.
Integrating Governance and Compliance into Data Models
Data modeling cannot be separated from governance considerations. Architects must design structures that ensure regulatory compliance, data protection, and operational transparency. This includes understanding how sensitive information is stored, classified, and accessed, as well as implementing mechanisms to enforce access control. GDPR compliance, for instance, requires architects to design models that can identify and protect personal data, provide traceability, and support data subject requests. Integrating governance into the data model ensures that security and compliance are inherent, rather than retrofitted, enhancing both operational reliability and stakeholder confidence.
Governance-oriented design also encompasses auditing, lineage tracking, and metadata management. Architects must capture and maintain information about data origin, transformations, and relationships to support both internal oversight and regulatory reporting. These practices prevent discrepancies, facilitate troubleshooting, and maintain organizational trust in the integrity of Salesforce data.
Advanced Techniques for Scalability and Resilience
Finally, advanced data modeling techniques focus on scalability and resilience. Partitioning, archiving, and the judicious use of external objects allow Salesforce to accommodate rapidly growing datasets without sacrificing performance. Architects must consider long-term storage, reporting needs, and access patterns when designing scalable solutions. By anticipating growth and designing for flexibility, data architects ensure that Salesforce remains performant, reliable, and aligned with evolving business objectives.
Integrating all these techniques—relationship management, skew avoidance, big object utilization, indexing, batch processing, and governance—forms the cornerstone of effective database design. Candidates must demonstrate the ability to synthesize these principles into cohesive, practical solutions, balancing technical constraints with organizational priorities and ensuring that the architecture supports both operational efficiency and strategic insights.
Understanding the Challenges of Large Data Volumes
Handling large data volumes in Salesforce presents unique challenges that require foresight, strategic planning, and technical acumen. As organizations grow, millions of records accumulate daily, spanning multiple objects, accounts, contacts, and transactional data. Without careful architectural design, this accumulation can severely impact system performance, slow queries, impede reporting, and complicate integrations with external systems. Large data volumes demand not just technical knowledge but also an appreciation of the underlying business processes, data flows, and user interactions that generate and consume this data.
Large data volumes affect both operational and analytical workloads. Operational tasks such as record creation, updates, and sharing recalculations can be delayed when ownership or parenting skew exists. Analytical processes, including complex reporting and dashboards, can experience latency if queries are not optimized. As a result, data architects must consider both the current state of the data and projected growth when designing solutions, ensuring that Salesforce remains responsive, resilient, and capable of supporting organizational objectives at scale.
Strategies to Prevent Data Skew
Data skew occurs when records are unevenly distributed among users or parents, leading to performance degradation and potential record locking. Ownership skew arises when a single user owns more than ten thousand records, triggering extensive sharing recalculations during role hierarchy changes. Parenting skew occurs when a parent record has a similarly high number of child records, causing implicit sharing calculations to slow and potentially generating record locking during bulk operations.
Mitigating data skew requires deliberate design decisions. Records should be distributed across multiple owners, leveraging assignment rules to ensure equitable ownership. When integration processes generate large volumes of records, assigning them to multiple integration users rather than a single account reduces performance bottlenecks. In scenarios where skew is unavoidable, isolating certain records under roles at strategic points in the hierarchy can prevent cascading recalculation delays. For parenting skew, distributing child records across multiple parent records or utilizing picklist fields for smaller lookup associations minimizes the likelihood of implicit sharing conflicts.
These considerations are crucial when designing Salesforce objects and relationships. By anticipating the distribution of records and the potential impact of business processes, data architects can preempt performance issues, maintain data integrity, and ensure that the system continues to operate efficiently even under heavy transactional loads.
Leveraging External Data Objects
External data objects provide a mechanism to manage extremely large datasets without storing them directly in Salesforce. By connecting to external repositories such as databases or cloud storage, architects can bring data into Salesforce on demand. This approach mitigates performance degradation associated with large data volumes, reduces storage consumption, and maintains flexibility for reporting and operational processes.
Designing solutions with external objects requires careful planning to maintain consistency and efficiency. Query optimization, selective field retrieval, and thoughtful integration patterns ensure that data is accessible without overwhelming the platform. External data objects are particularly valuable when historical or archival data is required for analytics but does not need to be operationally active on a daily basis. By strategically using external objects, data architects can balance the need for comprehensive information with system performance and scalability.
Query Optimization Techniques
Efficient querying is fundamental to maintaining performance in environments with large data volumes. Poorly designed queries can cause full table scans, excessive CPU usage, and long execution times. Optimizing queries involves using indexed fields in filters, minimizing joins, and avoiding negative filters, leading wildcards, or text comparisons with inequality operators. Salesforce provides tools such as the query plan analyzer to assess query cost and suggest optimization strategies, enabling architects to refine queries and improve response times.
In addition to indexing, architects must consider selectivity, filtering, and batch processing. Selective queries return a small percentage of the dataset, reducing system load. Filtering based on indexed fields or ranges ensures that only relevant records are retrieved. When queries must handle millions of records, splitting them into manageable batches via asynchronous processes such as batch Apex allows the system to maintain responsiveness while processing large datasets. These techniques collectively prevent performance degradation, improve user experience, and support timely data analysis.
Batch Processing with Apex
Batch Apex is an essential tool for managing large datasets within Salesforce. It allows the asynchronous processing of up to fifty million records, enabling bulk operations such as mass updates, data cleansing, or integration workflows without overwhelming the system. Designing batch processes requires attention to batch sizes, scheduling, error handling, and transaction control. Properly implemented batch processing prevents record locking, minimizes CPU usage, and ensures reliable data processing even under high transactional volumes.
Architects must also design batch processes to accommodate data dependencies and relationships. For instance, parent-child relationships must be considered to avoid conflicts during updates, while sharing calculations should be deferred when possible to reduce system load. Combining batch processing with query optimization and skew mitigation strategies ensures that large-scale operations execute efficiently, maintaining both system performance and data integrity.
Utilizing Skinny Tables
Skinny tables are specialized tables within Salesforce that contain a subset of frequently used fields from standard or custom objects. These tables reduce the need for resource-intensive joins and improve the performance of queries and reports. By storing commonly accessed fields in a streamlined format, skinny tables enable faster data retrieval and enhance the responsiveness of analytical and operational processes.
Creating skinny tables requires careful selection of fields, consideration of data access patterns, and maintenance of synchronization with the source objects. Only fields that are frequently queried or included in reports should be included, ensuring that the performance benefits outweigh the administrative overhead. Data architects must evaluate reporting needs, transaction patterns, and integration workflows to determine when skinny tables provide tangible improvements in efficiency.
Primary Key Chunking for Large Data Extracts
Primary Key Chunking is a strategy used to extract large datasets efficiently from Salesforce. It involves dividing records into smaller chunks based on indexed primary keys, allowing parallel or sequential processing without overwhelming the system. This technique is especially valuable for integrations, migrations, and analytical processing, where millions of records must be transferred or processed.
Implementing PK chunking requires understanding record distribution, index availability, and batch processing constraints. By splitting queries into manageable segments, architects can optimize system resources, prevent timeouts, and maintain consistent performance during data-intensive operations. PK chunking complements other optimization strategies, including indexing, batch processing, and external object utilization, creating a comprehensive approach to large data volume management.
Best Practices for Report Performance
Reports and dashboards are essential for decision-making, but their performance can be significantly affected by large data volumes. Optimizing report performance involves minimizing joins, ensuring filters reference indexed fields, and reducing the number of records returned where possible. Additionally, leveraging modern reporting tools and analytics platforms can further enhance responsiveness and provide actionable insights even with substantial datasets.
Architects must also consider report scheduling, caching, and aggregation strategies. Scheduled reports that process large volumes overnight or during low-usage periods prevent interference with operational tasks. Aggregating data at appropriate levels reduces the number of records processed during reporting, further enhancing performance. By combining thoughtful report design with query optimization and data partitioning, data architects can maintain a balance between analytical depth and system responsiveness.
Data Import Strategies for Large Volumes
Importing large volumes of data requires careful orchestration to maintain quality, consistency, and system performance. Before importing, duplicates should be removed, and data should be validated against organizational rules. Bulk API provides asynchronous processing capabilities, allowing for efficient handling of millions of records. Selection between Bulk API 1.0 and 2.0 depends on batch management needs, processing complexity, and desired operational control.
During imports, sharing rule calculations can be deferred to prevent performance bottlenecks. Deferring sharing recalculations temporarily suspends access computation, allowing records to be inserted or updated more efficiently. Once the import is complete, sharing rules are recalculated to restore appropriate access levels. This strategy, combined with batch processing, ensures that large imports proceed without compromising system performance or user experience.
Data Quality Considerations with Large Datasets
Maintaining data quality is particularly challenging with large volumes of records. Inaccurate, incomplete, or duplicate data can propagate errors, slow processing, and reduce trust in reports and dashboards. Workflow rules, validation rules, and automated data enrichment tools help ensure that data meets organizational standards. Duplicate management processes prevent the proliferation of redundant records, while custom field types and picklists enforce consistency in data entry.
Monitoring and ongoing cleansing are critical for long-term data quality. Tools like Data.com Clean or other enrichment platforms compare records against trusted external sources, flag discrepancies, and update records automatically. High-quality data supports analytical accuracy, operational efficiency, and regulatory compliance, making it an indispensable component of large data volume management.
Integrating Large Data Volume Strategies into Architecture
Effectively managing large data volumes requires integration of multiple strategies into the overall data architecture. Skew mitigation, external object utilization, query optimization, batch processing, skinny tables, PK chunking, and data quality processes must be orchestrated cohesively to create a performant, scalable environment. Architects must anticipate growth, design for flexibility, and implement monitoring and adjustment mechanisms to maintain performance over time.
In practice, this involves continuous evaluation of system behavior, proactive identification of potential bottlenecks, and iterative improvement of data structures and processes. By aligning architectural design with operational realities, data architects ensure that Salesforce supports both immediate business needs and long-term strategic objectives.
Understanding Data Migration in Salesforce
Data migration is a critical aspect of Salesforce architecture, requiring meticulous planning, technical precision, and a deep understanding of the platform’s mechanisms. It involves transferring data from legacy systems, external databases, or other Salesforce instances into a new environment while preserving integrity, consistency, and operational continuity. Large-scale migrations present unique challenges because any inefficiency or oversight can compromise system performance, create data duplication, or introduce inaccuracies that affect reporting and decision-making. A successful data migration strategy must integrate technical knowledge with organizational insight, anticipating the nuances of relationships, ownership, and historical records.
Migration projects typically begin with a thorough assessment of the source data. This includes identifying duplicates, validating data against business rules, and understanding dependencies among related objects. Salesforce’s Bulk API enables asynchronous processing of large datasets, allowing architects to move millions of records efficiently. Selecting between Bulk API 1.0 and 2.0 requires evaluating batch control needs, parallel processing requirements, and integration complexity. Bulk API 1.0 demands manual batch preparation and provides both serial and parallel processing, whereas Bulk API 2.0 handles batch management automatically and focuses on parallel execution. Understanding these differences is essential for designing a migration strategy that optimizes performance while ensuring data fidelity.
Data Preparation and Quality Assurance
The preparation phase of data migration is crucial for ensuring quality and consistency. Records must be deduplicated, standardized, and enriched to comply with organizational rules. Workflow rules and validation rules can enforce correct data formats during the migration, preventing erroneous entries. Tools like Data.com Clean or other enrichment solutions can compare records against trusted external references, flag inconsistencies, and automatically update inaccurate or incomplete data. Preparing data effectively reduces the risk of introducing errors into the Salesforce environment and ensures that the migrated data aligns with operational and reporting requirements.
Quality assurance also involves testing migration procedures in sandbox environments before executing production-level transfers. This step helps identify potential bottlenecks, such as record locking, sharing recalculations, or skewed ownership, and provides an opportunity to refine batch sizes, adjust query parameters, or modify relationships to prevent performance issues. By rigorously validating migration processes, data architects can avoid costly disruptions and ensure a smooth transition.
Bulk API and Asynchronous Processing
Bulk API is designed to handle large datasets efficiently, enabling asynchronous operations that prevent system overload. During migration, records can be inserted, updated, upserted, or deleted without requiring immediate real-time processing. This capability is particularly valuable for large organizations where millions of records must be transferred, and operational continuity cannot be compromised. Asynchronous processing allows the system to queue tasks and execute them in the background, minimizing disruptions to users and other processes.
Architects must carefully plan batch sizes and execution schedules to optimize Bulk API performance. Oversized batches may exceed governor limits or create locking conflicts, while undersized batches can increase total processing time unnecessarily. Incorporating strategies such as PK chunking, query optimization, and selective field retrieval enhances efficiency. By combining these approaches, migrations can proceed smoothly, even with extremely large datasets, while preserving both system responsiveness and data accuracy.
Managing Record Ownership and Sharing Rules
During migration, managing record ownership and sharing rules is critical to maintaining performance and data integrity. Ownership skew, where a single user owns a large volume of records, can lead to extensive recalculations when roles change. Parenting skew, where a single parent has an excessive number of child records, can cause record locking during batch operations. Both scenarios are exacerbated in large-scale migrations if not addressed proactively.
To mitigate these risks, architects should distribute records across multiple owners and use assignment rules to balance load. When integration users are involved, assigning records to multiple accounts rather than a single integration user reduces potential bottlenecks. Additionally, deferring sharing rule recalculations during migration allows records to be processed efficiently, with access calculations performed after the bulk operations are complete. These strategies ensure that system performance remains stable and that users can continue operational tasks without delays.
Optimizing Queries During Migration
Efficient querying is essential when migrating data, as retrieving millions of records can otherwise overwhelm system resources. Indexing fields used in filters, avoiding full table scans, and minimizing joins improve query performance significantly. Selective queries that target only necessary records reduce processing time and resource consumption. Tools such as the query plan analyzer help identify expensive queries and suggest optimizations, enabling architects to refine extraction strategies and enhance throughput.
For large datasets, combining optimized queries with batch processing and PK chunking allows records to be migrated in manageable portions. This approach reduces the risk of timeouts, minimizes locking conflicts, and maintains consistent system performance. Understanding the interplay between queries, indexing, and batch execution is critical for data architects to execute successful migrations at scale.
PK Chunking for Efficient Data Extraction
Primary Key Chunking is a method that divides large datasets into smaller segments based on primary key values, typically indexed IDs, to improve extraction performance. This technique allows parallel processing of multiple chunks or sequential execution, reducing the risk of overwhelming system resources. PK chunking is especially useful for migrating millions of records or integrating with external systems where real-time processing is impractical.
Implementing PK chunking requires careful assessment of record distribution, data dependencies, and batch sizes. By segmenting the data intelligently, architects can ensure that large-scale migrations proceed efficiently while avoiding common pitfalls such as record locking, failed batches, or prolonged execution times. PK chunking complements Bulk API, batch processing, and query optimization strategies to create a robust migration framework capable of handling enterprise-scale datasets.
Data Transformation and Harmonization
During migration, data often requires transformation to align with Salesforce object structures, field types, and business rules. This can include standardizing date formats, converting picklist values, normalizing currency fields, and reconciling inconsistencies between source systems. Harmonization ensures that migrated data is accurate, consistent, and usable for operational processes and reporting.
Data transformation should be incorporated into the migration workflow using automated tools or scripts, reducing manual intervention and minimizing errors. Architecting these processes requires a thorough understanding of both source and target systems, anticipated data volumes, and the relationships among objects. Properly implemented transformations maintain data integrity and enhance the utility of the Salesforce environment post-migration.
Maintaining Data Integrity and Auditability
Ensuring data integrity is paramount during migration. This involves preserving relationships, maintaining accurate field values, and validating constraints imposed by Salesforce, such as unique identifiers and required fields. Auditability is equally important, as organizations often need to track data lineage, changes, and migration activities for regulatory compliance and internal governance.
Data architects implement validation procedures, logging mechanisms, and reconciliation processes to monitor the migration progress and verify outcomes. By documenting the source, transformation, and destination of each record, organizations maintain transparency and can address discrepancies or errors efficiently. These practices ensure that the migrated environment reflects the intended structure, supports decision-making, and complies with governance standards.
Handling Large Volumes of Transactional Data
Transactional data, such as opportunities, cases, and service requests, often accumulates rapidly and presents unique challenges during migration. High-volume transactional objects may contain millions of records, requiring careful batch processing, query optimization, and skew mitigation. Migrating this type of data demands strategies that prevent locking conflicts, maintain sharing calculations, and ensure timely completion.
Architects often combine asynchronous processing with PK chunking and selective indexing to manage transactional data efficiently. By segmenting large tables, deferring sharing calculations, and prioritizing critical records, they can maintain operational continuity while ensuring that all data is migrated accurately. This approach minimizes disruption to ongoing business processes and preserves the reliability of transactional analytics.
Bulk API Error Handling and Monitoring
Effective management of the Bulk API includes robust error handling and monitoring procedures. During large migrations, failures may occur due to validation errors, exceeding governor limits, or data inconsistencies. Architects must implement mechanisms to capture errors, analyze root causes, and reprocess affected batches without compromising the remaining migration workflow.
Monitoring tools and logging frameworks allow real-time observation of batch execution, identifying slow queries, locked records, or system resource constraints. Proactive monitoring enables architects to intervene before issues escalate, adjust batch sizes, optimize queries, or reschedule operations to maintain overall performance. This vigilance ensures that migrations are reliable, efficient, and maintain data fidelity.
Integrating Data Governance in Migration
Data governance is integral to successful migrations. Architects must ensure that sensitive information is classified, protected, and compliant with regulatory requirements during transfer. Migration workflows should respect access controls, maintain audit trails, and preserve data lineage to support accountability and compliance. Governance considerations also involve standardizing field types, harmonizing picklists, and enforcing validation rules, ensuring that the new Salesforce environment reflects organizational policies and best practices.
Embedding governance into migration workflows prevents the introduction of inconsistencies, unauthorized access, or regulatory breaches. By integrating compliance measures, architects reinforce the integrity of the Salesforce environment and create a foundation for ongoing data management practices.
Leveraging External Tools for Migration
External ETL tools and middleware solutions can augment Salesforce migration capabilities, especially when dealing with complex transformations, cross-system integrations, or exceptionally large datasets. These tools facilitate data extraction, transformation, and loading while providing logging, error handling, and monitoring features that enhance reliability. Data architects should evaluate these tools based on scalability, compatibility, and operational requirements to ensure a seamless migration process.
By combining Bulk API, PK chunking, batch processing, and external tool integration, architects can create robust migration frameworks capable of handling enterprise-scale data efficiently. These combined strategies enable precise, controlled, and auditable data transfers that preserve system performance and maintain organizational trust in Salesforce as a central repository.
Ensuring Robust Data Governance
Data governance forms the bedrock of a resilient Salesforce architecture, encompassing policies, standards, and practices designed to maintain data quality, security, and compliance. It is the orchestrated management of data assets to ensure they are accurate, consistent, and reliable across the organization. Effective governance requires a holistic approach that integrates organizational policies with technical implementations, ensuring that data remains a trustworthy foundation for business operations and strategic decision-making.
In Salesforce, data governance involves defining clear ownership of data, establishing accountability, and setting rules for creation, modification, and access. Architects must ensure that sensitive information is appropriately classified, permissions are consistently enforced, and records are traceable throughout their lifecycle. By embedding governance within the platform, organizations can mitigate risks of inaccurate reporting, unauthorized access, and regulatory non-compliance.
Governance extends beyond security, encompassing data lineage and metadata management. Understanding how data flows between systems, transformations it undergoes, and the origin of each record provides transparency and enables organizations to maintain confidence in their analytics. Metadata, including field definitions, validation rules, and object relationships, forms the framework for governance, ensuring that data structures are consistent, maintainable, and aligned with organizational standards.
Master Data Management Principles
Master Data Management (MDM) is a critical practice for unifying and consolidating core business data, creating a single source of truth for entities such as customers, accounts, or products. MDM ensures that critical data is harmonized across multiple systems, reconciled for accuracy, and maintained according to defined business rules. Within Salesforce, architects employ MDM strategies to consolidate customer records, reconcile duplicates, and establish authoritative records that support operational and analytical processes.
Implementing MDM involves several key steps. First, data from multiple sources is collected and evaluated for quality, completeness, and consistency. Duplicate records are identified and resolved using deterministic or probabilistic matching algorithms. Harmonization rules are applied to standardize formats, align taxonomy, and reconcile conflicting values. Finally, authoritative records are established, often referred to as golden records, which serve as the definitive representation of an entity across the organization.
MDM also includes ongoing maintenance, ensuring that newly created or updated records adhere to the established rules. Workflow automation, validation rules, and duplicate management tools in Salesforce facilitate this continuous quality enforcement. By integrating MDM into the data architecture, organizations reduce operational inefficiencies, enhance reporting accuracy, and foster greater trust in their Salesforce environment.
Compliance with GDPR and Data Privacy Regulations
Regulatory compliance is a central concern for data architects, particularly with frameworks like GDPR that mandate strict handling of personal data. Compliance requires not only securing sensitive information but also maintaining traceability, supporting subject access requests, and ensuring that data is collected, processed, and stored lawfully. Architects must design Salesforce solutions that inherently support compliance rather than retrofitting controls after implementation.
This involves identifying personal and sensitive data within objects, applying appropriate encryption and access controls, and designing mechanisms for data anonymization or pseudonymization when necessary. Consent management and audit trails must be integrated to demonstrate accountability and facilitate regulatory reporting. By embedding these principles into the architecture, organizations can avoid penalties, protect customer trust, and ensure ethical use of data.
Data privacy considerations also affect reporting and analytics. Reports must respect access permissions, masking sensitive information where appropriate, and dashboards should aggregate data without exposing personally identifiable information unnecessarily. Architects must ensure that compliance measures do not impede operational workflows while maintaining stringent protections for sensitive data.
Duplicate Management Strategies
Duplicate records are a persistent challenge in Salesforce, particularly in environments with large data volumes and multiple sources. Effective duplicate management is essential for maintaining data integrity, operational efficiency, and reporting accuracy. Salesforce provides tools to prevent the creation of duplicate records and identify existing duplicates for remediation.
Architects design duplicate management strategies by defining matching rules and duplicate rules that govern how records are compared and flagged. These rules can include criteria based on names, email addresses, phone numbers, or other unique identifiers. Automated processes can merge duplicates, preserve critical data, and maintain relationships to other records. Regular monitoring and enrichment processes ensure that the data remains consistent over time, preventing proliferation of errors and ensuring reliable analytics.
Duplicate management also supports MDM efforts by ensuring that golden records remain authoritative and uncontested. By combining preventive measures with ongoing monitoring, organizations can maintain a high standard of data quality, reduce operational inefficiencies, and strengthen user trust in the Salesforce platform.
Data Quality Maintenance
Maintaining high data quality is a continuous endeavor that underpins governance, MDM, and compliance. Poor data quality manifests as missing, incomplete, or inaccurate records and can significantly impact operational productivity and analytical insights. Architects employ multiple strategies to ensure data quality, including validation rules, workflow automation, and periodic cleansing using external tools.
Validation rules enforce business standards during data entry, ensuring that required fields are completed, formats are correct, and values comply with organizational policies. Workflow automation supports consistent processing by routing records, triggering approvals, or updating fields based on predefined conditions. Data enrichment tools integrate external reference datasets to fill gaps, correct inaccuracies, and maintain alignment with trusted sources.
Dashboards and monitoring processes provide visibility into data quality metrics, enabling proactive intervention and remediation. By continuously evaluating and improving data quality, organizations sustain trust in their Salesforce environment, enhance decision-making, and ensure compliance with internal and external standards.
Data Security and Access Control
Protecting sensitive data is a fundamental component of governance and compliance. Salesforce architects design access control models that limit visibility and edit rights based on roles, profiles, and permission sets. Ownership hierarchies, sharing rules, and field-level security ensure that users access only the data they are authorized to view or modify.
Security considerations extend to integrations, external objects, and bulk operations. Architects must ensure that data moving between systems maintains appropriate protections, that external sources do not compromise internal controls, and that bulk processing respects access boundaries. By embedding security into the architecture, organizations protect confidential information, reduce exposure to risk, and align with regulatory mandates.
Data Archiving and Historical Data Management
Data archiving is an essential strategy for maintaining performance while preserving historical records. Archiving involves moving infrequently accessed or obsolete data to separate storage while keeping it accessible for compliance, reference, or analytical purposes. Well-implemented archiving reduces operational load, improves query and reporting performance, and ensures that primary objects remain lean and efficient.
Historical data in Salesforce can be stored in big objects, external repositories, or specialized archive systems. Architects must design archiving rules that define retention periods, criteria for selection, and retrieval mechanisms. Proper indexing, search capabilities, and integration with reporting tools ensure that archived data remains usable for audits, analysis, and strategic insights. By embedding archiving into the overall architecture, organizations maintain system agility and ensure long-term accessibility of critical information.
Reporting and Analytical Integrity
Accurate reporting is a natural extension of governance, MDM, and quality management. Reports and dashboards must provide insights without compromising security, performance, or compliance. Architects design reporting structures that optimize query efficiency, leverage indexed fields, and minimize computational overhead. Aggregation, filtering, and selective field retrieval are used to enhance performance, particularly with large datasets.
Ensuring analytical integrity involves harmonizing data across sources, reconciling discrepancies, and maintaining consistent definitions of key metrics. By embedding these practices into the architecture, organizations can generate reliable insights, monitor performance effectively, and support data-driven decision-making across the enterprise.
Integrating Governance, MDM, and Compliance into Architecture
A cohesive approach integrates governance, master data management, compliance, and quality into the Salesforce architecture. This integration ensures that data remains accurate, secure, and reliable while supporting operational processes and strategic objectives. Architects must balance technical constraints with organizational policies, embedding rules and controls at the design stage rather than applying them reactively.
Regular audits, monitoring, and continuous improvement are essential for sustaining these practices. By combining governance policies, data quality enforcement, duplicate management, archival strategies, and reporting integrity, organizations maintain a resilient Salesforce environment capable of supporting both immediate operational needs and long-term strategic goals.
Conclusion
Mastering governance, master data management, and compliance in Salesforce is essential for maintaining high-quality, secure, and actionable data. By integrating policies, technical controls, and operational practices, architects can create an environment that supports business efficiency, accurate reporting, and regulatory adherence. Effective data governance ensures accountability, transparency, and trust, while master data management harmonizes critical records to establish a single source of truth. Compliance strategies safeguard sensitive information and demonstrate organizational responsibility. Combined with ongoing data quality maintenance, duplicate management, and archiving, these practices provide a resilient foundation for Salesforce environments, enabling organizations to scale confidently, make informed decisions, and maintain a competitive advantage.
Frequently Asked Questions
How can I get the products after purchase?
All products are available for download immediately from your Member's Area. Once you have made the payment, you will be transferred to Member's Area where you can login and download the products you have purchased to your computer.
How long can I use my product? Will it be valid forever?
Test-King products have a validity of 90 days from the date of purchase. This means that any updates to the products, including but not limited to new questions, or updates and changes by our editing team, will be automatically downloaded on to computer to make sure that you get latest exam prep materials during those 90 days.
Can I renew my product if when it's expired?
Yes, when the 90 days of your product validity are over, you have the option of renewing your expired products with a 30% discount. This can be done in your Member's Area.
Please note that you will not be able to use the product after it has expired if you don't renew it.
How often are the questions updated?
We always try to provide the latest pool of questions, Updates in the questions depend on the changes in actual pool of questions by different vendors. As soon as we know about the change in the exam question pool we try our best to update the products as fast as possible.
How many computers I can download Test-King software on?
You can download the Test-King products on the maximum number of 2 (two) computers or devices. If you need to use the software on more than two machines, you can purchase this option separately. Please email support@test-king.com if you need to use more than 5 (five) computers.
What is a PDF Version?
PDF Version is a pdf document of Questions & Answers product. The document file has standart .pdf format, which can be easily read by any pdf reader application like Adobe Acrobat Reader, Foxit Reader, OpenOffice, Google Docs and many others.
Can I purchase PDF Version without the Testing Engine?
PDF Version cannot be purchased separately. It is only available as an add-on to main Question & Answer Testing Engine product.
What operating systems are supported by your Testing Engine software?
Our testing engine is supported by Windows. Andriod and IOS software is currently under development.
Top Salesforce Exams
- Certified Agentforce Specialist - Certified Agentforce Specialist
- Certified Data Cloud Consultant - Certified Data Cloud Consultant
- Certified Integration Architect - Certified Integration Architect
- ADM-201 - Administration Essentials for New Admins
- Certified Tableau Data Analyst - Certified Tableau Data Analyst
- Certified Platform Developer - Certified Platform Developer
- Certified Platform App Builder - Certified Platform App Builder
- Certified Sharing and Visibility Architect - Certified Sharing and Visibility Architect
- Certified Service Cloud Consultant - Salesforce Certified Service Cloud Consultant
- Certified Business Analyst - Certified Business Analyst
- Certified Platform Developer II - Certified Platform Developer II
- Public Sector Solutions Accredited Professional - Public Sector Solutions Accredited Professional
- Certified Development Lifecycle and Deployment Architect - Certified Development Lifecycle and Deployment Architect
- Certified Revenue Cloud Consultant - Certified Revenue Cloud Consultant
- Certified Platform Sharing and Visibility Architect - Certified Platform Sharing and Visibility Architect
- Certified CPQ Specialist - Certified CPQ Specialist
- Financial Services Cloud Accredited Professional - Financial Services Cloud Accredited Professional
- Certified OmniStudio Developer - Certified OmniStudio Developer
- Certified Platform Administrator II - Certified Platform Administrator II
- Certified Platform Identity and Access Management Architect - Certified Platform Identity and Access Management Architect
- DEV-450 - Salesforce Certified Platform Developer I (SU18)
- Certified OmniStudio Consultant - Certified OmniStudio Consultant
- Certified Marketing Cloud Developer - Certified Marketing Cloud Developer
- Certified Marketing Cloud Email Specialist - Certified Marketing Cloud Email Specialist
- Certified Advanced Administrator - Certified Advanced Administrator
- Certified MuleSoft Developer I - Certified MuleSoft Developer I
- Certified Marketing Cloud Account Engagement Specialist - Certified Marketing Cloud Account Engagement Specialist
- Certified Experience Cloud Consultant - Certified Experience Cloud Consultant
- Certified MuleSoft Integration Architect I - Salesforce Certified MuleSoft Integration Architect I
- Certified Tableau Desktop Foundations - Certified Tableau Desktop Foundations
- Field Service Consultant - Field Service Consultant
- Certified Industries CPQ Developer - Certified Industries CPQ Developer
- Certified MuleSoft Developer - Certified MuleSoft Developer
- Certified Platform Data Architect - Certified Platform Data Architect
- Certified Data 360 Consultant - Certified Data 360 Consultant
- Certified Data Architect - Certified Data Architect
Salesforce Certifications
- Certified JavaScript Developer I
- Certified Tableau CRM and Einstein Discovery Consultant
- Data Architect - Salesforce Certified Data Architect
- Field Service Consultant
- Salesforce AI Associate
- Salesforce Certified Advanced Administrator
- Salesforce Certified Agentforce Specialist
- Salesforce Certified Associate
- Salesforce Certified B2B Solution Architect
- Salesforce Certified B2C Commerce Developer
- Salesforce Certified Business Analyst
- Salesforce Certified Community Cloud Consultant
- Salesforce Certified CPQ Specialist
- Salesforce Certified Data Architecture and Management Designer
- Salesforce Certified Data Cloud Consultant
- Salesforce Certified Development Lifecycle and Deployment Designer
- Salesforce Certified Einstein Analytics and Discovery Consultant
- Salesforce Certified Field Service Lightning Cloud Consultant
- Salesforce Certified Heroku Architecture Designer
- Salesforce Certified Identity and Access Management Architect
- Salesforce Certified Identity and Access Management Designer
- Salesforce Certified Industries CPQ Developer
- Salesforce Certified Marketing Cloud Consultant
- Salesforce Certified Marketing Cloud Developer
- Salesforce Certified Marketing Cloud Email Specialist
- Salesforce Certified MuleSoft Developer I
- Salesforce Certified OmniStudio Consultant
- Salesforce Certified OmniStudio Developer
- Salesforce Certified Pardot Specialist
- Salesforce Certified Platform App Builder
- Salesforce Certified Platform Developer I
- Salesforce Certified Sales Cloud Consultant
- Salesforce Certified Service Cloud Consultant
- Salesforce Certified Sharing and Visibility Designer
- The Salesforce.com Certified Administrator
- The Salesforce.com Certified Advanced Administrator
- The Salesforce.com Certified Force.com Advanced Developer
- The Salesforce.com Certified Force.com Developer
